
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
作者:昇腾实战派 x 哒妮滋T5模型,是 Transfer Text-to-Text Transformer 的简写;Transfer 来自 Transfer Learning,预训练模型大体在这范畴,Transformer 也不必多说,Text-to-Text 是作者在这提出的一个统一训练框架,将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。英德翻译:只需将训练数据集
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
作者:昇腾实战派 x 哒妮滋
1 概述
1.1 模型简介
T5模型,是 Transfer Text-to-Text Transformer 的简写;Transfer 来自 Transfer Learning,预训练模型大体在这范畴,Transformer 也不必多说,Text-to-Text 是作者在这提出的一个统一训练框架,将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。
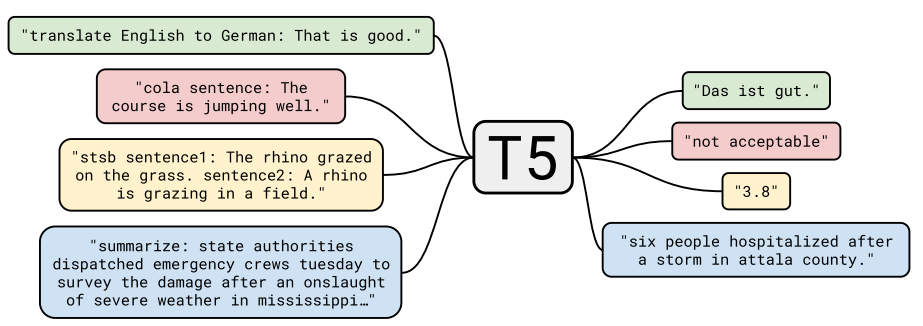
1.2 举例
-
英德翻译:只需将训练数据集的输入部分前加上“translate English to German(给我从英语翻译成德语)” 就行。假设需要翻译"That is good",那么先转换成 “translate English to German:That is good.” 输入模型,之后就可以直接输出德语翻译 “Das ist gut.”
-
情感分类任务,输入"sentiment:This movie is terrible!",前面直接加上 “sentiment:”,然后就能输出结果“negative(负面)”。
-
最神奇的是,对于需要输出连续值的 STS-B(文本语义相似度任务),居然也是直接输出文本,而不是加个连续值输出头。以每 0.2 为间隔,从 1 到 5 分之间分成 21 个值作为输出分类任务。比如上图中,输出 3.8 其实不是数值,而是一串文本,之所以能进行这样的操作,应该完全赖于 T5 模型强大的容量。
通过这样的方式就能将 NLP 任务都转换成 Text-to-Text 形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
2 T5模型的选型
2.1 Architecture
首先作者们先对预训练模型中的多种模型架构(Transformer)进行了比对,最主要的模型架构可以分成下面三种。
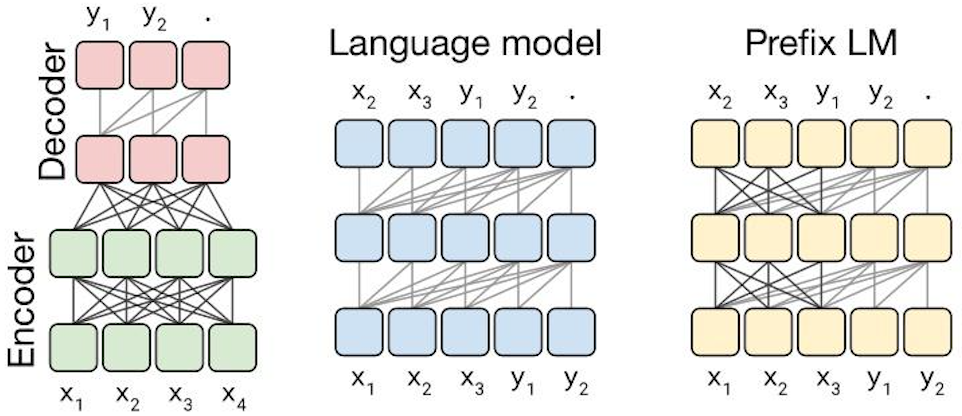
第一种,Encoder-Decoder 型,即 Seq2Seq 常用模型,分成 Encoder 和 Decoder 两部分,对于 Encoder 部分,输入可以看到全体,之后结果输给 Decoder,而 Decoder 因为输出方式只能看到之前的。此架构代表是 MASS(今年WMT的胜者),而 BERT 可以看作是其中 Encoder 部分。
第二种, 相当于上面的 Decoder 部分,当前时间步只能看到之前时间步信息。典型代表是 GPT2 还有最近 CTRL 这样的。
第三种,Prefix LM(Language Model) 型,可看作是上面 Encoder 和 Decoder 的融合体,一部分如 Encoder 一样能看到全体信息,一部分如 Decoder 一样只能看到过去信息。最近开源的 UniLM 便是此结构。
上面这些模型架构都是 Transformer 构成,之所以有这些变换,主要是对其中注意力机制的 Mask 操作。

通过实验作者们发现,在提出的这个 Text-to-Text 架构中,Encoder-Decoder 模型效果最好。于是乎,就把它定为 T5 模型,因此所谓的 T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型。
位置编码方式
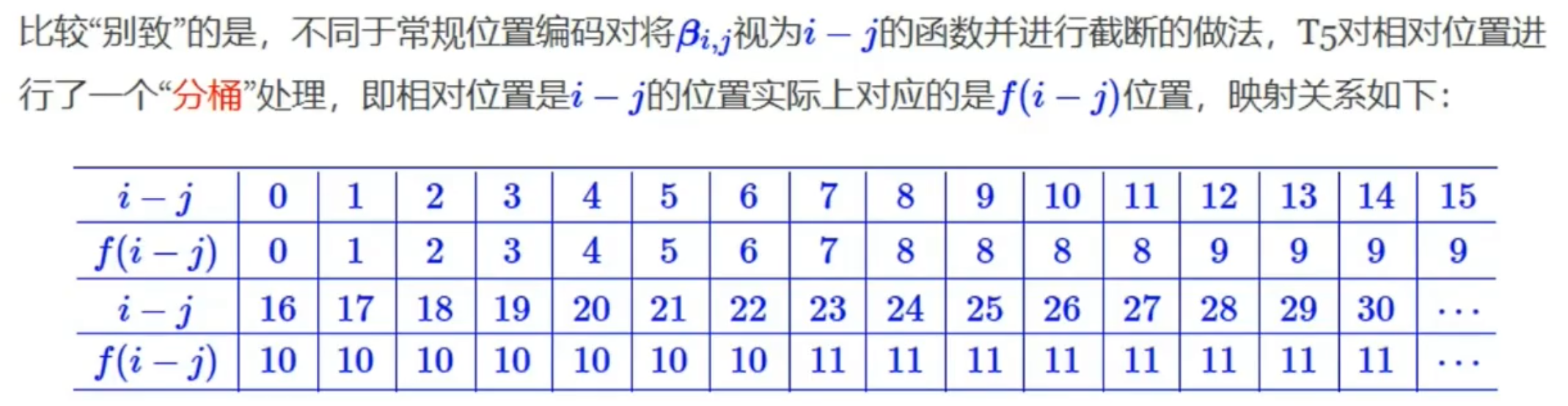
T5采用了一个长距离不敏感的相对位置编码,这一设计师考虑到远距离的单词依赖往往比较稀疏且不精细,因此我们需要对周围单词的位置坐精确的区分,而远距离的位置变化则相对缓慢。
因此T5模型对相对位置进行了一个“分桶”处理,将原始的relative_position当成一个个小方块放置在顺序排列的桶中,最后用方块所属的桶号来代替相对距离。
在T5模型中num_buckets=32,max_distance=128。源码中将num_buckets/2的距离定义为远近的分割线(对于双向attention是8,对于单向attention是16),低于这个数值的距离被任务是近的,高于这个数值的距离被认为是远的。
T5虽然同样使用了Encoder-Decorder结构,但T5并没有在输入的input embedding,而是在Encoder的第一层的self-attention计算Q和K乘积之后加入了一个relative position embedding,也就是计算softmax之前。即:
e ^ i j h = e i j h + r i j \widehat{e} _{ij}^{h} =e _{ij}^{h} + r _{ij} e
ijh=eijh+rij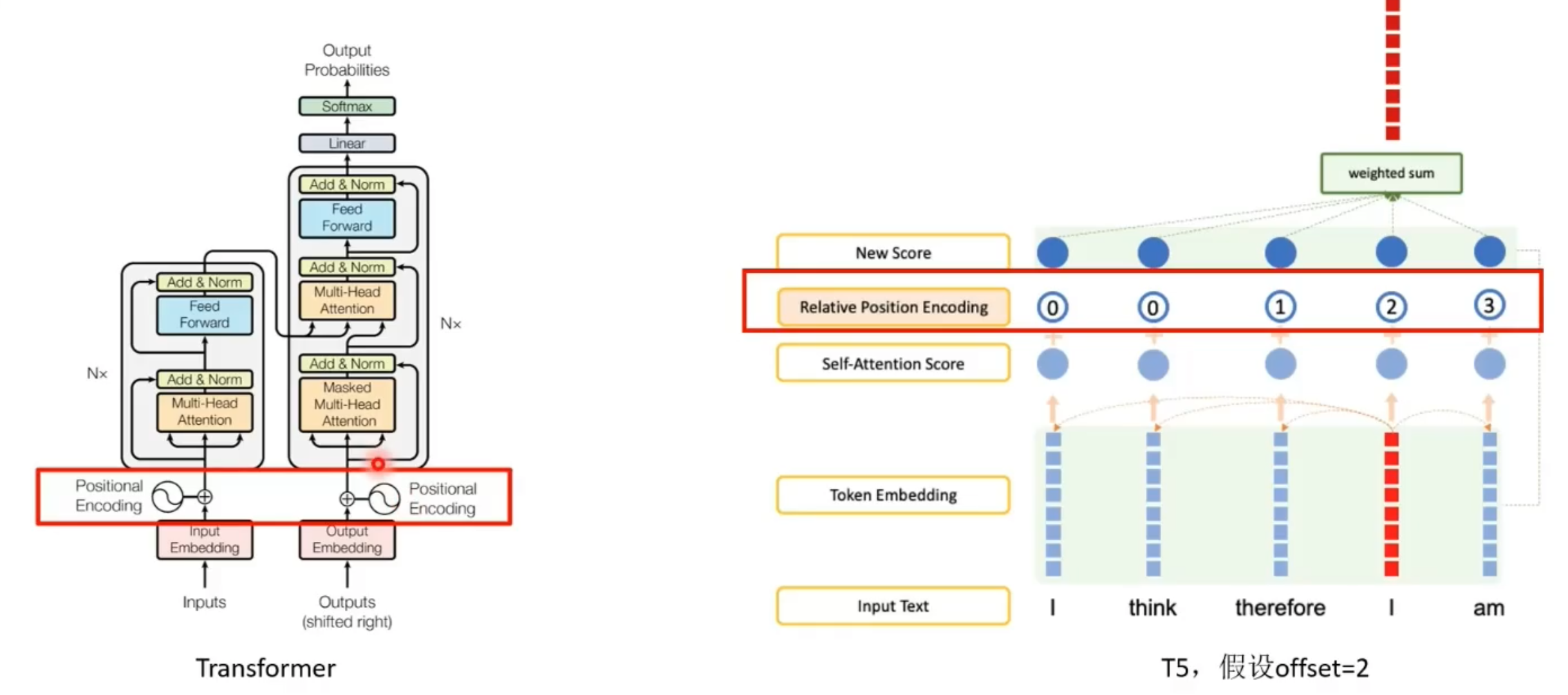
2.2 Data
作者从 Common Crawl(一个公开的网页存档数据集,每个月大概抓取 20TB 文本数据) 里清出了 750 GB 的训练数据,然后取名为 ” Colossal Clean Crawled Corpus (超大型干净爬取数据)“,简称 C4。
大概清理过程如下:
- 只保留结尾是正常符号的行;
- 删除任何包含不好的词的页面,具体词表参考**List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words**库;
- 包含 Javascript 词的行全去掉;
- 包含编程语言中常用大括号的页面;
- 任何包含”lorem ipsum(用于排版测试)“的页面;
- 连续三句话重复出现情况,保留一个。
2.3 Objectives
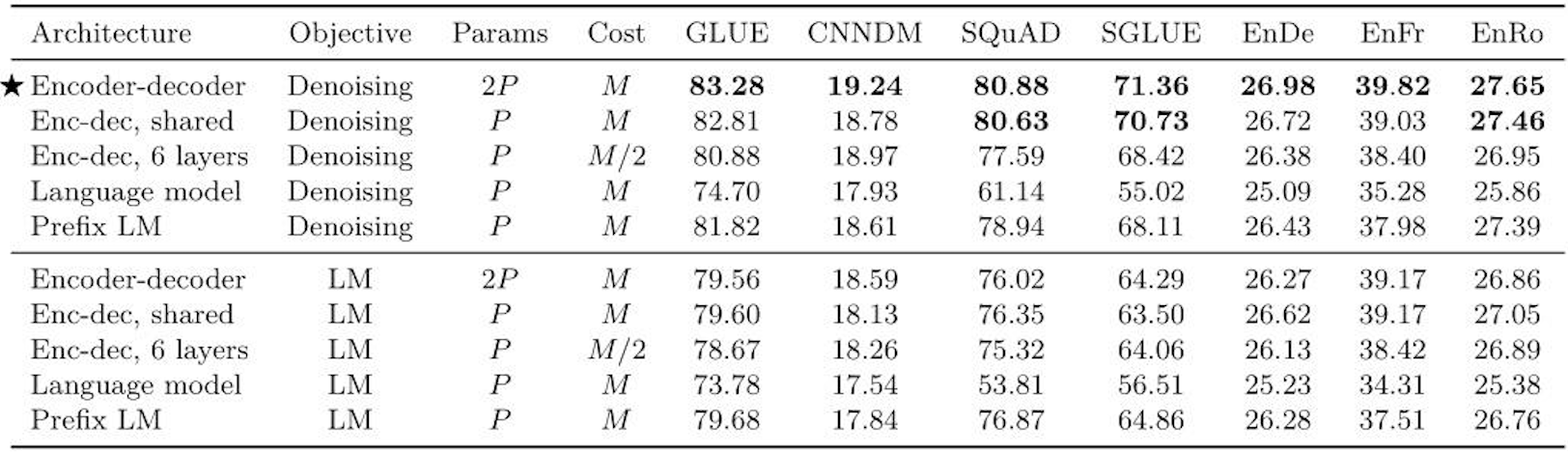
之后是对预训练目标的大范围探索,具体做了哪些实验,下面这张图就能一目了然。
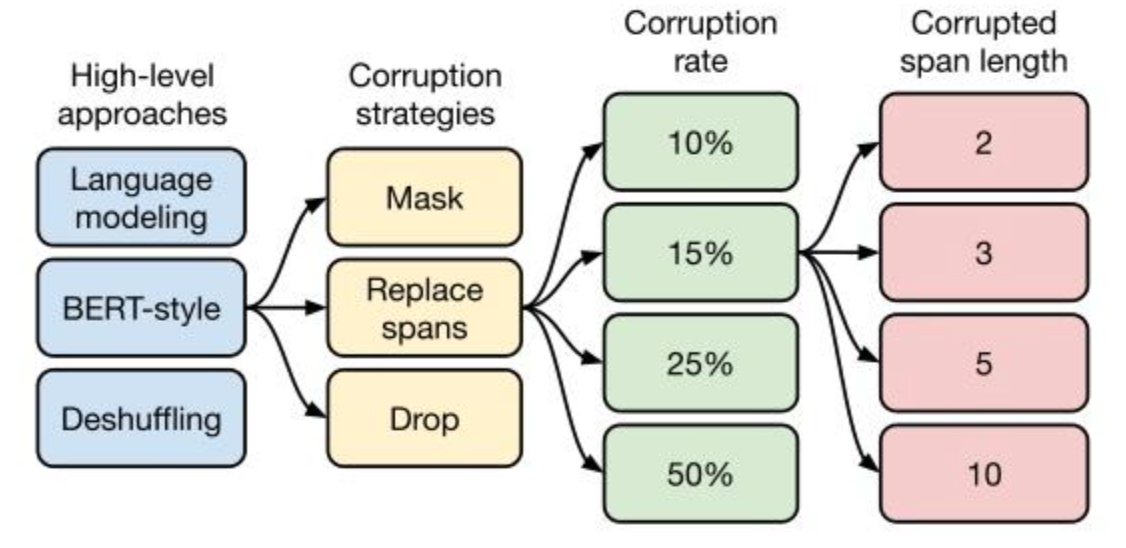
总共从四方面来进行比较。
2.3.1 高层次方法(自监督的预训练方法)对比
- 语言模型式,就是 GPT-2 那种方式,从左到右预测;
- BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来;
- Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来。

- 其中发现 Bert-style 最好,进入下一轮。
2.3.2 文本破坏策略
- Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
- replace span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;
- Drop 法,没有替换操作,直接随机丢弃一些字符。
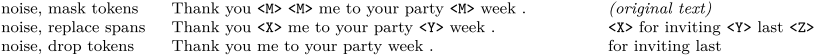
此轮获胜的是 Replace Span 法,进入下一轮。
2.3.3 文本破坏率
作者挑了 4 个值,10%,15%,25%,50%,最后发现 BERT 的 15% 就很 ok了。

2.3.4 文本破坏半径
第四方面,因为 Replace Span 需要决定对大概多长的小段进行破坏,于是对不同长度进行探索,2,3,5,10 这四个值,最后发现 3 结果最好。
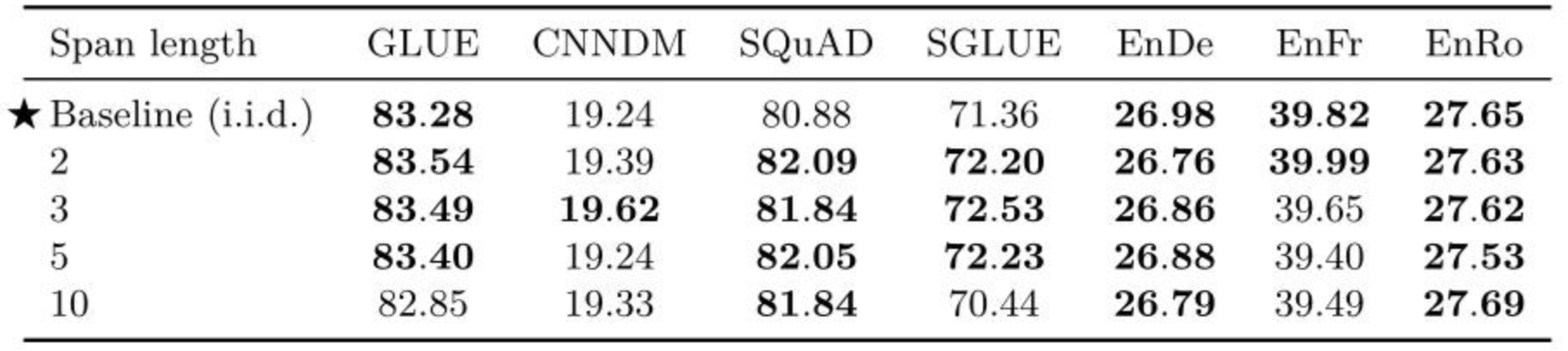
至此,终于获得了完整的 T5 模型,还有它的训练方法。
- Transformer Encoder-Decoder 模型;
- BERT-style 式的破坏方法;
- Replace Span 的破坏策略;
- 15 %的破坏比;
- 3 的破坏时小段长度。
2.4 微调策略
微调模型的所有参数可能会导致结果欠佳,尤其是在资源匮乏的情况下。作战专注于两种替代的微调方式,这些方法仅更新编码器-解码器模型的子集。
- **Adapter layers:**在预训练好的模型中插入一些adapter layers,这些adapter layers是一个或多个dense-ReLU-dense结构的block,插入位置一般在预训练模型中Transformer结构的FFN网络的后面,同时保证adapter layer的输入和输出shape一样,即插入adapter layer后不改变插入点原来的Tensor(中间计算结果)的shape。做fine-tuning训练时预训练模型中大部分权重不做更新,而只更新adapter layer和layer norm中的权重。
- **gradual unfreezing:**即一开始freeze大部分模型权重,随后逐渐unfreeze越来越多的权重让它们在fine-tuning训练中得到更新。此外,由于T5模型中input embedding矩阵(token to embedding)和output classification矩阵(embedding to token)的权重是共享的,需要让这部分权重在整个fine-tuning过程中一直更新。具体如何对模型权重逐渐解冻需要有一个schedule,作者这里直接用了一个简单粗暴的schedule: 由于encoder和decoder各有12个layers,把总训练步数2^18除以12得到12个小阶段(episode),每个小阶段在encoder和decoder同时unfreeze一个layer。
2.5 多任务学习
多任务学习可以是multi-task training(不做预训练而直接做多个下游任务的有监督训练),也可以是multi-task pre-training(使用无监督训练数据集和有监督训练数据集混合起来做预训练,随后还可以做或不做fine-tuning)。
多任务学习的一个重要的考虑因素是如何对多个数据集做mixing,即从各个数据集中分别选取多少比例的数据,作者探索(explore)了三种策略:
(1) Examples-proportional mixing
设任务的数据集大小是 e n , n ∈ 1 , 2 , . . . , N e_{n},n\in 1,2,...,N en,n∈1,2,...,N,采样时,采样自第 m m m个任务数据的概率为
r m = m i n ( e n , K ) ∑ m i n ( e n , K ) r_{m} =\frac{min\left ( e_{n},K \right ) }{\sum min\left ( e_{n},K \right ) } rm=∑min(en,K)min(en,K)
这里的 K K K是提前设定的参数。
(2) Temperature-scaled mixing
在第一个实验的基础上,对求得的 r m r_{m} rm再求 T T T次方根,当 T = 1 T=1 T=1时,即Examples-proportional mixing; T T T越大,各个任务数据集采样越均衡。
(3) Equal mixing
各个任务数据采样概率相同。
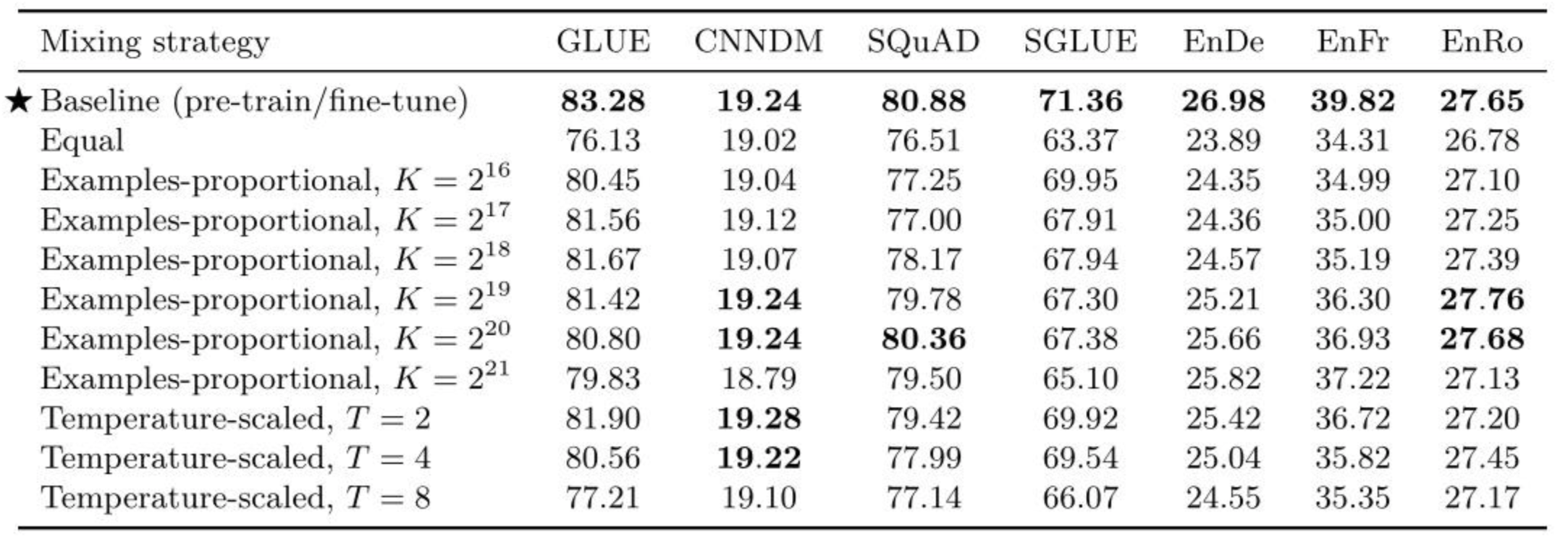
结论:
1、多任务学习的性能是不如传统的预训练+微调的;
2、多任务学习中使用Equal mixing策略其实并不好,因为很容易发生过拟合与欠拟合;
3、对于Examples-proportional mixing来说,对于大多数任务,都有一个K的甜点值,过大或过小都回导致性能劣化;
4、对于Temperature-scaled mixing来说,T=2貌似是一个比较好的选择。
2.6 多任务学习+微调
先用多个任务进行预训练,再对具体任务进行微调。
**实验一:**在Examples-proportional mixing人工混合数据集上预训练模型,然后在每个单独的下游任务上对其进行微调;
**实验二:**在相同的混合数据集上对模型进行预训练,只是从该预训练混合物中省略了一项下游任务。然后,我们在预训练中遗漏的任务上对模型进行微调。对于考虑的每个任务,都会重复此步骤。这种方法为“leave-one-out”多任务训练;
**实验三:**把无监督目标(即baseline的预训练目标)剔除,对所有考虑的监督任务进行预训练、


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)