
Qwen3vl-8B基于veRL的强化学习训练适配流程
摘要: 本文介绍了在昇腾AI环境下,将多模态大模型Qwen3-VL-8B的强化学习训练框架从SWIFT迁移至VeRL的适配过程。重点包括环境搭建(CANN、vLLM、VeRL安装)、数据集处理(Geo3k)、模型优化(代码修改)及训练脚本配置。实验使用GRPO算法进行RLHF训练,并对比了性能优化效果,为多模态大模型的强化学习任务提供了实践参考。
多模态体系知识地图
关注公众号:AI 模力圈
作者:昇腾实战派 x 安佐
一、背景
自DeepSeek模型发布之后,类GRPO的RLHF训练方法已经逐渐成为大模型后训练的范式,而VeRL作为大模型RL领域泛用性最强的框架,受到社区广泛关注。
出于强化学习性能考虑,考虑将多模态大模型的强化学习任务从SWIFT切换至VeRL框架。模型选型为Qwenvl系列最新的Qwen3vl-8B。
本文记录在VeRL上穿刺Qwen3vl-8B的适配流程与精度对比数据。
Qwen3vl-8B模型介绍
Qwen3-VL-8B 是阿里通义千问系列推出的多模态模型,具备强大的视觉理解和文本生成能力,适用于复杂场景下的图像识别、图文对话和视觉推理等任务。
GRPO算法介绍
GRPO算法流程不再赘述,示意图与损失函数如下: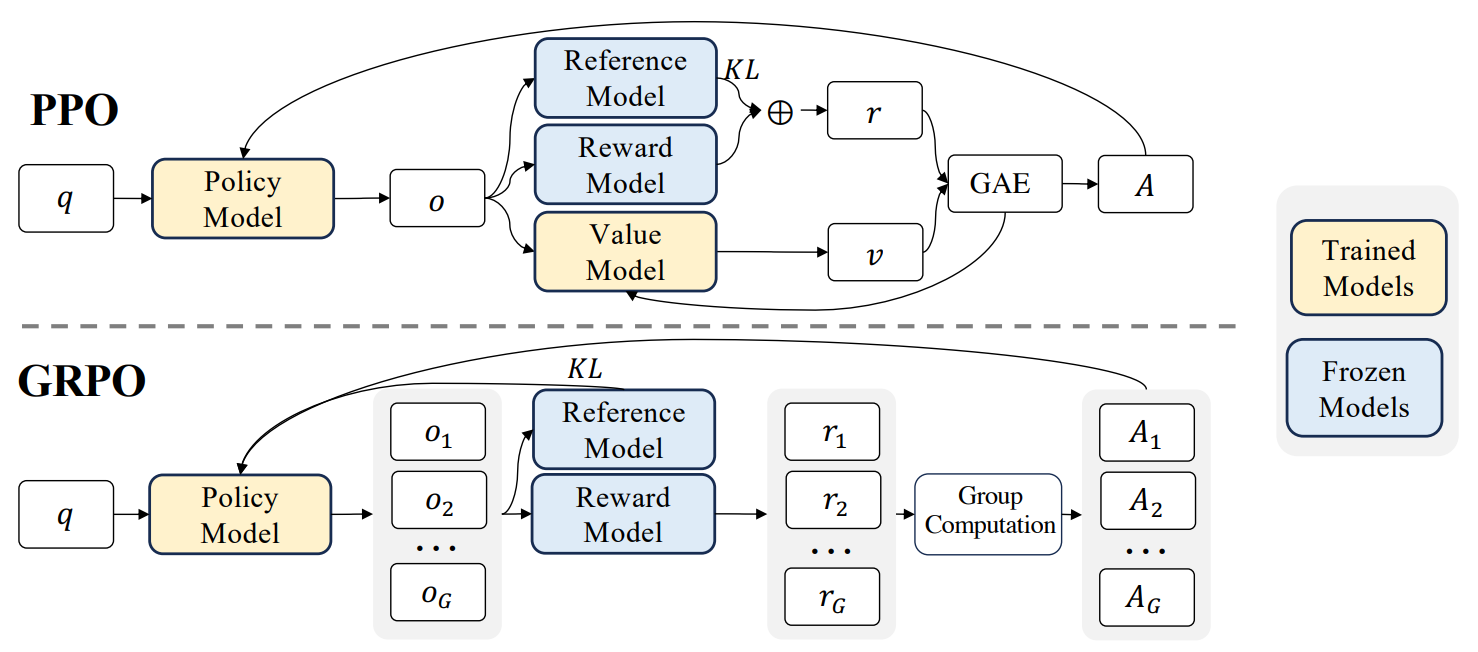
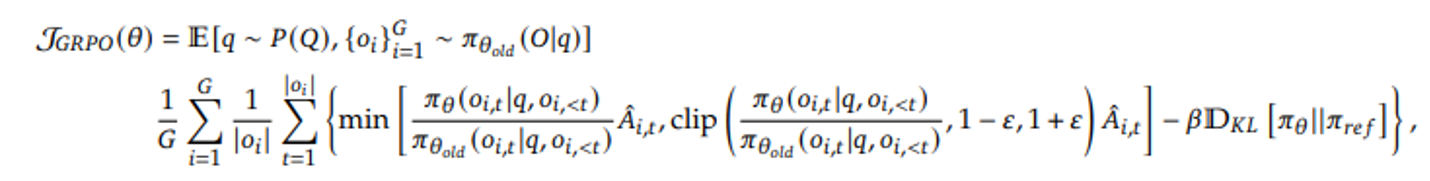
需注意,在当前VeRL的实现中,损失函数在默认情况下已使用DAPO中的token-mean形式,而非原始GRPO中的seq-mean-token-mean。
二、环境版本信息
软件依赖版本
| 组件 | 版本 | 备注 |
|---|---|---|
| CANN | 8.2.RC1 | |
| torch | 2.7.1+cpu | |
| torch_npu | 2.7.1.dev20250724 | |
| vLLM | 0.11.0 | 可选择pip安装或本地编译安装 |
| vLLM-ascend | 0.11.rc0 | 可选择pip安装或本地编译安装 |
| veRL | 0.7.0.dev0 | commit id: 65eb019a81012317b98afc17ce8fd36342a5e786 |
Qwen3vl-dense模型的VeRL版本依赖于https://github.com/volcengine/verl/pull/3838 等PR,所以直接选择了较新版本。
三、环境搭建
1. 容器环境配置
- 如果不是以root身份登录设备,在登录后先切换到root
sudo su - root
- 在home下面创建个人目录
mkdir /home/<name>
- 创建容器
docker_start.sh:
CONTAIN_NAME=$1
IMAGES_NAME=$2
docker run -it -u root --ipc=host --net=host --privileged=True \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /usr/lib/jvm/:/usr/lib/jvm \
-v /home/:/home/ \
--name $CONTAIN_NAME $IMAGES_NAME /bin/bash
启动命令:
bash docker_start.sh contain_name image_name:version
- 进入容器
docker exec -it contain_name bash
2. 软件安装流程
(1)安装CANN
- CANN下载路径:社区版资源下载-资源下载中心-昇腾社区 (hiascend.com)
- 下载并安装对应系统的run文件:Ascend-cann-toolkit_.run(toolkit开发套件包)、Ascend-cann-kernels-.run(kernels算子包)、Ascend-cann-nnal_*.run(nnal神经网络加速库)。
(2)安装vLLM和vLLM-ascend
用git下载并安装vLLM和vLLM-ascend。
# 安装vllm
cd ../
git clone https://github.com/vllm-project/vllm.git
cd vllm
git checkout v0.11.0
VLLM_TARGET_DEVICE=empty pip install -v -e .
# 安装vllm-ascend
cd ../
git clone https://github.com/vllm-project/vllm-ascend
cd vllm-ascend
git checkout v0.11.0rc0
pip install -v -e .
(3)下载VeRL与安装相关依赖
cd ../
git clone https://github.com/volcengine/verl.git
cd verl
git checkout 65eb019a81012317b98afc17ce8fd36342a5e786
pip install -r requirements-npu.txt
四、模型适配流程
1. 数据集处理
本次实验使用Geo3k训练数据集,数据集下载地址:https://huggingface.co/datasets/hiyouga/geometry3k
原始数据需数据处理后使用,数据处理脚本见:verl/examples/data_preprocess/geo3k.py
python examples/data_preprocess/geo3k.py --local_dir=""
默认处理后数据集保存位置为~/data/geo3k
数据集格式为:
$~/data/geo3k
├── train.parquet
├── test.parquet
2. 源代码修改项
由于qwen3vl系列模型优化暂未合入veRL主线,部分优化需要手动添加:
verl/models/transformers/npu_patch.py
line 25:
-from transformers.modeling_utils import PretrainedConfig, PreTrainedModel
+from transformers.configuration_utils import PretrainedConfig
+from transformers.modeling_utils import PreTrainedModel
+from transformers.models.qwen3_vl import modeling_qwen3_vl
+from transformers.models.qwen3_vl_moe import modeling_qwen3_vl_moe
line 205:
+modeling_qwen3_vl_moe.Qwen3VLMoeTextRMSNorm.forward = rms_norm_forward
+modeling_qwen3_vl_moe.apply_rotary_pos_emb = apply_rotary_pos_emb_qwen3_npu
+modeling_qwen3_vl.Qwen3VLTextRMSNorm.forward = rms_norm_forward
+modeling_qwen3_vl.Qwen3VLTextMLP.forward = silu_forward
verl/workers/fsdp_workers.py (用于vllm_ascend部分特性启用)
line 92:
+import vllm
+import vllm_ascend.patch.worker
3. 环境变量与训练脚本
verl/trainer/runtime_env.yaml
working_dir: ./
excludes: ["/.git/"]
env_vars:
TASK_QUEUE_ENABLE: "1"
HCCL_EXEC_TIMEOUT: "3600"
HCCL_CONNECT_TIMEOUT: "3600"
VLLM_ASCEND_ENABLE_MATMUL_ALLREDUCE: "1"
训练脚本:
MODEL_PATH=/data/weight/Qwen3-VL-8B-Instruct
time=$(date +"%m%d")
WORKING_DIR=${WORKING_DIR:-"${PWD}"}
RUNTIME_ENV=${RUNTIME_ENV:-"${WORKING_DIR}/verl/trainer/runtime_env.yaml"}
RAY_API_SERVER_ADDRESS='http://127.0.0.1:8260' ray job submit --no-wait --runtime-env="${RUNTIME_ENV}" \
--working-dir "${WORKING_DIR}" \
-- python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=/data/l00906151/geo3k/dataset/train.parquet \
data.val_files=/data/l00906151/geo3k/dataset/test.parquet \
data.train_batch_size=512 \
data.max_prompt_length=1024 \
data.max_response_length=2048 \
data.filter_overlong_prompts=True \
data.truncation='error' \
data.image_key=images \
actor_rollout_ref.model.path=${MODEL_PATH} \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=32 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.01 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.actor.use_torch_compile=False \
actor_rollout_ref.actor.loss_agg_mode='seq-mean-token-mean' \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=2 \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.actor.fsdp_config.forward_prefetch=False \
actor_rollout_ref.ref.fsdp_config.forward_prefetch=False \
actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
actor_rollout_ref.rollout.name=$ENGINE \
+actor_rollout_ref.rollout.engine_kwargs.vllm.disable_mm_preprocessor_cache=True \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.enable_chunked_prefill=True \
actor_rollout_ref.rollout.enforce_eager=True \
actor_rollout_ref.rollout.free_cache_engine=True \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger=console \
trainer.project_name='verl_grpo_example_geo3k' \
trainer.experiment_name='qwen3_vl_8b_function_rm' \
trainer.n_gpus_per_node=8 \
trainer.nnodes=1 \
trainer.save_freq=25 \
trainer.test_freq=10 \
trainer.total_epochs=1 \
trainer.device=npu $@ 2>&1 | tee qwen3_${time}.log
五、适配过程问题与解决方案
1. 端口占用导致ray job submit失败
启动ray进程,提交ray job过程中出现报错,打屏信息包括"No available agent to submit job, please try again later."。实际是因为残留进程导致的端口占用
查询下述日志可确定具体冲突的端口
vim /tmp/ray/session_xxxxxx/logs/dashboard_agent.log

附linux 端口查询命令:
lsof -i:8000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nodejs 26993 root 10u IPv4 37999514 0t0 TCP *:8000 (LISTEN)
2. 内存申请失败
拉起过程中报错"Failed to apply for memory"。安装jemalloc2后解决。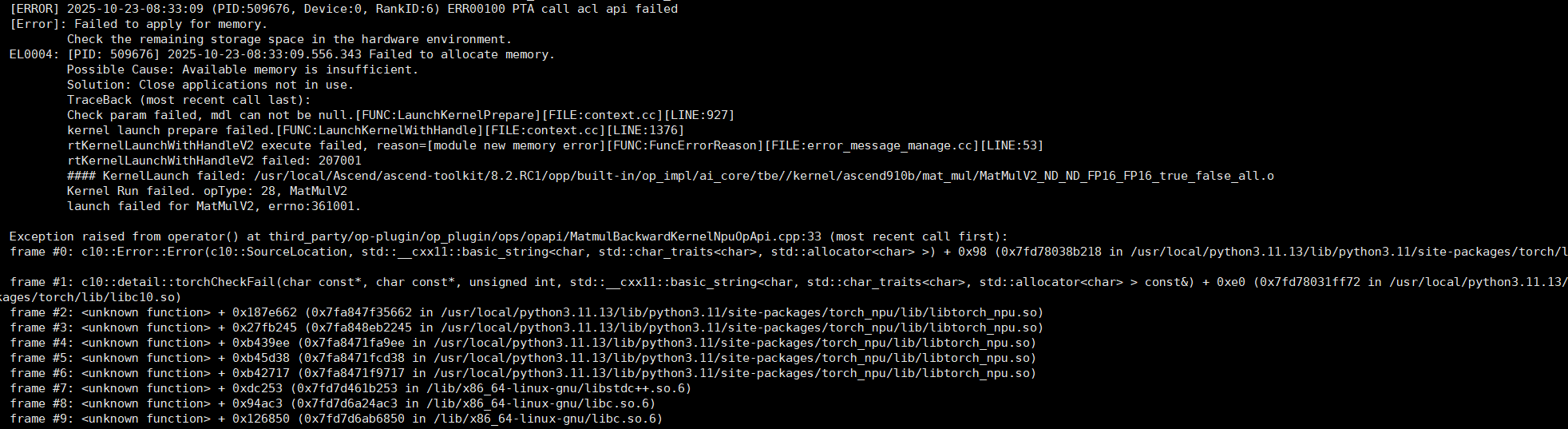
操作系统源安装jemalloc:
Ubuntu:
sudo apt install libjemalloc2
OpenEuler:
yum install jemalloc
安装完成后通过命令 find /usr -name libjemalloc.so.2 确认动态链接库位置。
环境变量导入jemalloc:
export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libjemalloc.so.2 # arm默认路径
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2 # x86默认路径
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)