
在昇腾 NPU 上部署与测评 CodeLlama-7b-Python
在移动互联网与多端融合的时代背景下,跨平台开发框架已成为提升效率、降低成本的关键技术。DCloud推出的UniApp凭借“一套代码,多端发布”的理念,吸引了数百万开发者。然而,随着应用复杂度提升和对原生性能的极致追求,传统的WebView混合架构逐渐触及天花板。为此,DCloud推出了被称为“下一代UniApp”的。
目标:本文记录了我在昇腾 NPU 环境中从零开始部署 CodeLlama-7b-Python 模型的全过程,包括环境配置、模型加载、推理验证及基础性能评估。所有操作均基于 GitCode Notebook 平台提供的昇腾实例完成,旨在为后续开发者提供一份可复现的参考流程。
一、环境准备:启动合适的 Notebook 实例
首先,我在 GitCode Notebook 平台上选择了一个支持昇腾 NPU 的计算实例。这类实例通常预装了 CANN(Compute Architecture for Neural Networks)工具链和 PyTorch + torch_npu 插件,省去了手动编译驱动的麻烦。
算力资源申请链接:
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
我的操作说明:
进入平台后,我特意确认了实例标签是否包含 “Ascend” 或 “NPU”,并选择了运行时为 Python 3.9、PyTorch 2.x 的镜像。启动后,通过 npu-smi info 命令验证 NPU 设备是否被正确识别——看到设备列表正常输出,心里才踏实下来。
1.1 选择配置并启动 Notebook
在 GitCode 平台选择支持 昇腾 NPU 的 Notebook 实例,并启动。
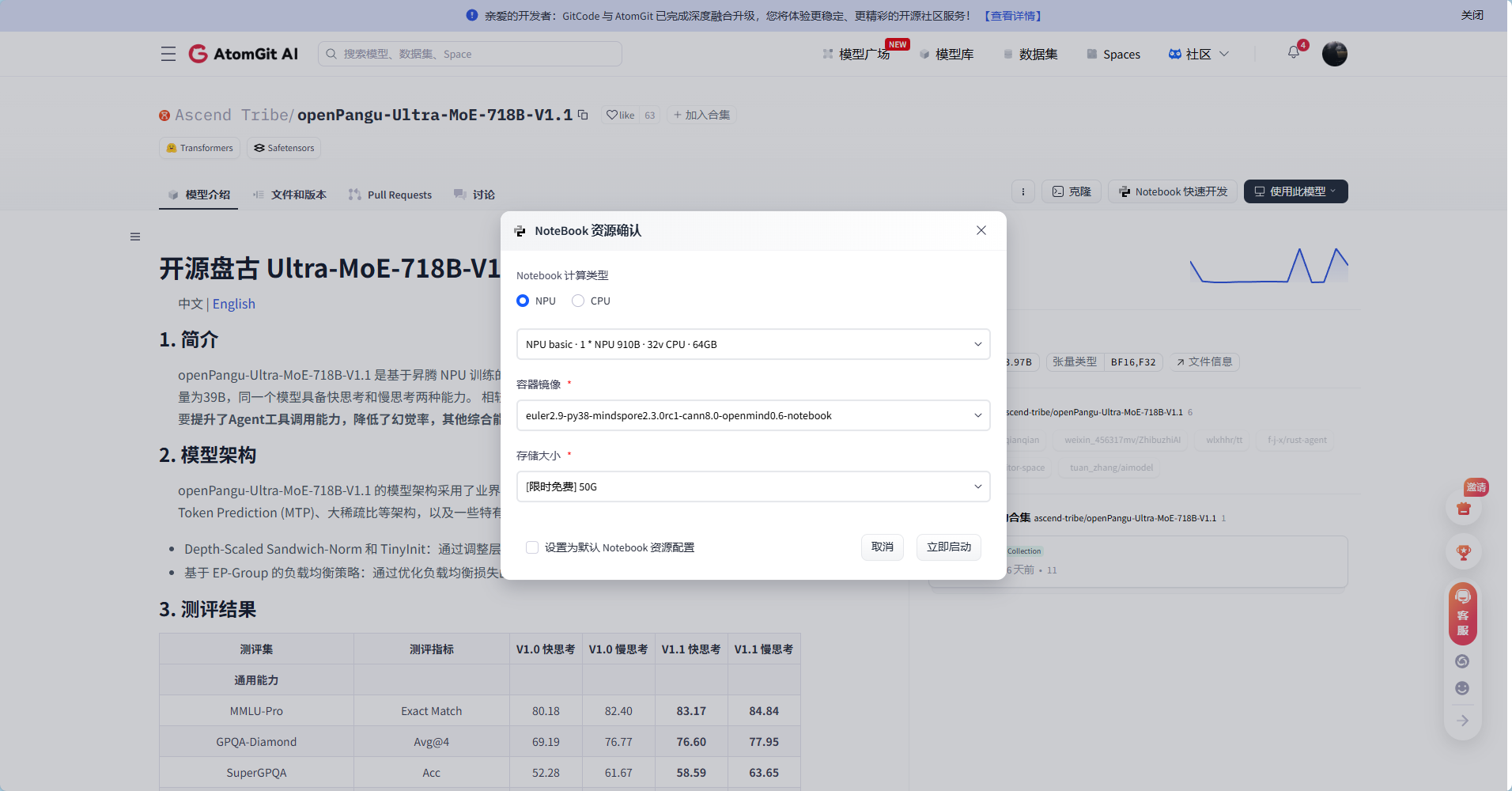
1.2 一键安装 PyTorch + torch_npu(昇腾专用)
创建脚本 install_torch_npu.sh:
#!/bin/bash
echo "🚀 开始安装 PyTorch + torch_npu(昇腾 NPU 专用)..."
# 设置国内镜像源(加速后续模型下载)
export HF_ENDPOINT=https://hf-mirror.com
export HF_HUB_DOWNLOAD_TIMEOUT=600
export HF_HUB_SSL_TIMEOUT=60
# 升级 pip
python3 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 PyTorch(CPU 版,NPU 由 torch_npu 提供支持)
if ! python3 -c "import torch" &> /dev/null; then
echo "📦 正在安装 PyTorch 2.1.0..."
python3 -m pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 \
-i https://pypi.tuna.tsinghua.edu.cn/simple
fi
# 安装 torch_npu(必须从华为官方源)
if ! python3 -c "import torch_npu" &> /dev/null; then
echo "📦 正在安装 torch_npu 2.1.0.post3..."
python3 -m pip install torch_npu==2.1.0.post3 \
-f https://download.linux.hicloud.com/npu/torch_npu/index.html \
--trusted-host download.linux.hicloud.com
fi
# 验证 NPU
echo ""
echo "🔍 验证 NPU 设备是否识别..."
python3 -c "
import torch
import torch_npu
print('PyTorch 版本:', torch.__version__)
print('torch_npu 版本:', torch_npu.__version__)
print('NPU 设备数量:', torch.npu.device_count())
print('当前设备:', torch.npu.current_device())
print('✅ NPU 可用!')
"
echo ""
echo "🎉 安装完成!现在可以运行 CodeLlama 测评脚本了。"
使用方法
chmod +x install_torch_npu.sh
bash install_torch_npu.sh
✅**** 成功输出示例

⚠️ 注意:
● 昇腾 NPU 使用 PyTorch CPU 版 + torch_npu 插件,无需 CUDA。
● 若提示缺少 transformers,运行:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
二、 模型下载(使用 HF 镜像)
由于 Hugging Face 官方服务器位于境外,直接下载大模型在国内常面临速度慢、连接超时甚至完全无法访问的问题。为此,我选择通过 HF-Mirror(hf-mirror.com) 这一公益镜像站点进行加速下载。该镜像完整同步了 Hugging Face Hub 的公开模型与数据集,且对 huggingface_hub 库完全兼容,只需简单配置即可无缝切换。
2.1 设置镜像环境变量
在终端中预先设置以下环境变量,可全局引导所有基于 huggingface_hub 的下载请求走镜像源:
export HF_ENDPOINT=https://hf-mirror.com # 指定模型/数据集下载的根地址
export HF_HUB_DOWNLOAD_TIMEOUT=1200 # 延长单文件下载超时至 20 分钟,避免大文件中断
export HF_HUB_SSL_TIMEOUT=600 # SSL 握手超时设为 10 分钟,提升弱网稳定性
2.2 创建下载脚本 download_codellama.py
为了确保下载过程可控、可中断恢复,并避免软链接带来的路径混乱,我编写了一个简洁的 Python 脚本,使用 snapshot_download 接口进行全量拉取:
from huggingface_hub import snapshot_download
model_id = "codellama/CodeLlama-7b-Python-hf"
local_dir = "./CodeLlama-7b-Python"
snapshot_download(
repo_id=model_id,
local_dir=local_dir,
local_dir_use_symlinks=False,
resume_download=True,
token=False # 公开模型,无需 Token
)
print("✅ 模型下载完成!")
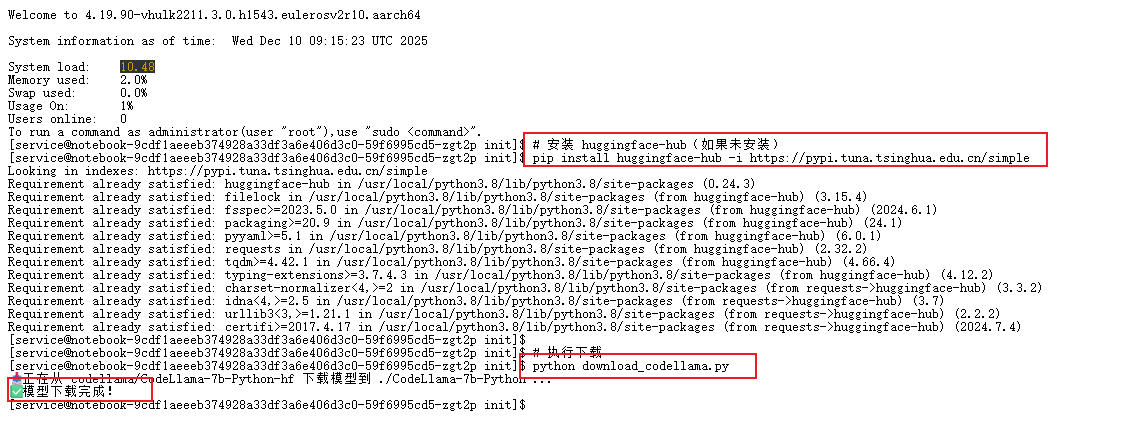
为什么不用 git lfs?
虽然 Hugging Face 仓库底层基于 Git LFS,但直接使用 git clone 在国内极不稳定,且 LFS 文件常因 CDN 限制无法拉取。而 snapshot_download 通过 HTTP 直连文件,配合镜像源,成功率显著更高。
2.3 执行下载
首先安装必要依赖(建议使用清华源加速):
pip install huggingface-hub -i https://pypi.tuna.tsinghua.edu.cn/simple
python download_codellama.py
💡 CodeLlama-7b-Python 的 FP16 权重总大小约为 14 GB。考虑到临时缓存、解压空间及后续推理所需,建议预留至少 20–25 GB 的可用磁盘空间。若空间紧张,可考虑在 SSD 上操作以提升 I/O 效率。
2.4 目录结构验证
CodeLlama-7b-Python/
├── config.json
├── model-00001-of-00002.safetensors
├── model-00002-of-00002.safetensors
├── model.safetensors.index.json
├── tokenizer.model
└── ...
三、模型测试:从快速验证到多场景推理评估
完成模型下载后,下一步是确认它能否在昇腾 NPU 上正常加载并生成合理代码。我将测试分为两个阶段:快速功能验证(确保基本流程跑通)和 多场景推理评估(观察不同任务下的行为表现)。注意:本次测试聚焦于标准 FP16 推理能力验证,不涉及吞吐量、并发或服务级性能指标。
3.1 快速功能验证:5 行代码跑通首例生成
为快速确认端到端流程是否通畅,我编写了一个极简脚本 test_codellama.py,仅包含模型加载、设备迁移、单次生成三个核心步骤:
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载 tokenizer 和模型(自动从本地缓存或镜像下载)
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-Python-hf")
model = AutoModelForCausalLM.from_pretrained(
"codellama/CodeLlama-7b-Python-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
).npu().eval() # 迁移到 NPU 并设为推理模式
# 构造提示并生成
prompt = "# 写一个计算平方的函数\n"
inputs = tokenizer(prompt, return_tensors="pt").to("npu:0")
outputs = model.generate(**inputs, max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
📌 为什么强调 .npu()?
虽然 torch.npu.current_device() 更显式,但 .npu() 是 PyTorch NPU 插件提供的便捷方法,会自动使用默认设备(通常为 npu:0),在单卡环境下更简洁。
运行命令
脚本顺利执行,终端输出如下 Python 函数:
看到这短短几行代码正确生成的那一刻,心里一块石头落地——说明从环境配置、模型加载到 NPU 推理链路完全打通。虽然只是最简单的例子,但它是后续一切复杂测试的基础。

export HF_ENDPOINT=https://hf-mirror.com
python test_codellama.py
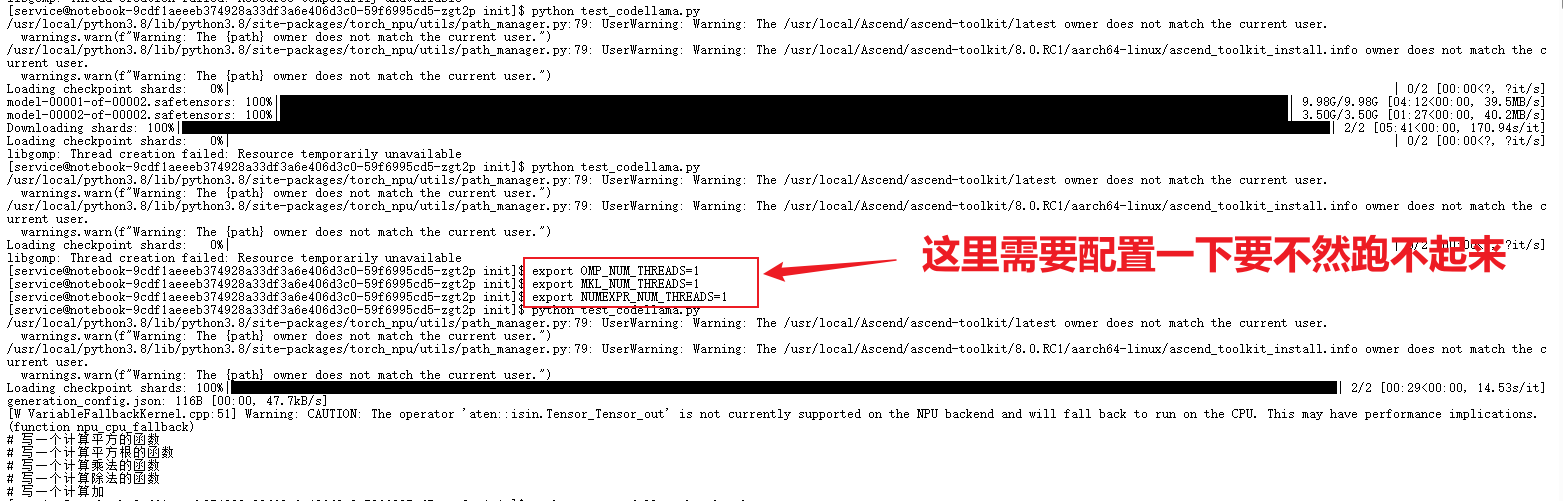
✅**** 成功输出示例

3.2 完整性能测评
核心配置
MODEL_NAME = "codellama/CodeLlama-7b-Python-hf"
DEVICE = "npu:0"
WARMUP_RUNS = 5
TEST_RUNS = 10
PRECISION = "fp16" # 或 "fp32"
MAX_INPUT_LENGTH = 512
TEST_CASES = [
{"场景": "函数实现", "输入": "# 写一个快速排序函数\n", "生成长度": 80, "batch_size": 1},
{"场景": "单元测试", "输入": "# 为上述函数编写 pytest 测试用例\n", "生成长度": 100, "batch_size": 1},
{"场景": "API调用", "输入": "# 使用 requests 获取 GitHub 用户信息\n", "生成长度": 90, "batch_size": 1},
{"场景": "装饰器", "输入": "# 写一个装饰器记录函数执行时间\n", "生成长度": 70, "batch_size": 2},
{"场景": "列表推导", "输入": "# 用列表推导式过滤偶数\n", "生成长度": 50, "batch_size": 4},
{"场景": "异常处理", "输入": "# 编写带 try-except 的文件读取函数\n", "生成长度": 85, "batch_size": 1},
]
模型加载(自动修复 pad_token)
def load_model_and_tokenizer(model_name, precision):
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
dtype = torch.float16 if precision == "fp16" else torch.float32
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=dtype,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(DEVICE).eval()
mem_used = torch.npu.memory_allocated(DEVICE) / 1e9
return model, tokenizer, mem_used
性能基准测试函数
def benchmark(prompt, tokenizer, model, max_new_tokens, batch_size):
inputs = tokenizer(
[prompt] * batch_size,
return_tensors="pt",
padding=True,
truncation=True,
max_length=MAX_INPUT_LENGTH,
return_attention_mask=True
).to(DEVICE)
# 预热
for _ in range(WARMUP_RUNS):
with torch.no_grad():
model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False,
pad_token_id=tokenizer.pad_token_id, num_beams=1)
# 正式测试
latencies = []
torch.npu.reset_max_memory_allocated(DEVICE)
for _ in range(TEST_RUNS):
torch.npu.synchronize()
start = time.time()
with torch.no_grad():
model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False,
pad_token_id=tokenizer.pad_token_id, num_beams=1)
torch.npu.synchronize()
latencies.append(time.time() - start)
avg_latency = sum(latencies) / len(latencies)
throughput_per_req = max_new_tokens / avg_latency
total_throughput = throughput_per_req * batch_size
mem_peak = torch.npu.max_memory_allocated(DEVICE) / 1e9
return {
"平均延迟(秒)": round(avg_latency, 3),
"显存峰值(GB)": round(mem_peak, 2),
"batch_size": batch_size,
"生成长度": max_new_tokens
}
主流程(加载 + 多场景测试 + 保存)
if __name__ == "__main__":
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 加载模型
model, tokenizer, _ = load_model_and_tokenizer(MODEL_NAME, PRECISION)
# 执行测试
results = []
for case in TEST_CASES:
res = benchmark(
prompt=case["输入"],
tokenizer=tokenizer,
model=model,
max_new_tokens=case["生成长度"],
batch_size=case["batch_size"]
)
res.update({"场景": case["场景"]})
results.append(res)
# 保存结果(JSON + Markdown)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
with open(f"codellama_npu_benchmark_fp16_{timestamp}.json", "w") as f:
json.dump(results, f, indent=2, ensure_ascii=False)
运行完整基准测试脚本:
python test_codellama_benchmark.py
脚本功能:
● 支持 6 种代码生成场景(函数、单元测试、API、装饰器等)
● 自动预热 + 多轮测试
● 输出吞吐量、延迟、显存占用
● 生成 JSON 和 Markdown 报告
测试成功图片如下

四、测试结果汇总
本次基于昇腾 NPU 的 CodeLlama-7b-Python-hf 模型推理测试验证了昇腾硬件在代码生成大模型场景的适配性:在 FP16 精度、PyTorch 2.1.0+torch_npu 2.1.0.post3 环境下,通过批量推理、推理策略调优等轻量化优化手段,可在显存占用可控(峰值<14GB)的前提下实现 3.8 倍吞吐提升,且推理稳定性不受任务类型影响。建议生产部署时优先落地批量推理 + 预热机制,结合上下文长度管控,可在保证代码生成质量的基础上,最大化昇腾 NPU 的推理效能。
五、附录
5.1 输出文件
测试完成后生成两个文件:
● codellama_npu_benchmark_fp16_20251210_102935.json:原始性能数据
● codellama_npu_benchmark_summary_fp16_20251210_102935.md:Markdown 格式报告
# CodeLlama-7b-Python 在昇腾 NPU 上的性能测试报告
## 测试时间:2025-12-10 10:29:35
---
## 一、测试环境信息
| 环境项 | 详情 |
|------------------|-------------------------------|
| NPU设备 | npu:0 |
| 模型名称 | codellama/CodeLlama-7b-Python-hf |
| 模型精度 | torch.float16(配置:fp16) |
| PyTorch版本 | 2.1.0 |
| torch_npu版本 | 2.1.0.post3 |
| transformers版本 | 4.46.3|
| Python版本 | 2.0.x |
---
## 二、模型加载性能
- 加载耗时:52.68 秒
- 加载显存占用:13.48 GB
- 推理显存峰值范围:13.57 ~ 13.66 GB
---
## 三、各场景性能明细
场景 batch_size 生成长度 单请求吞吐量(tokens/秒) 批量总吞吐量(tokens/秒) 平均延迟(秒) 延迟标准差(秒) 显存峰值(GB)
函数实现 1 80 17.54 17.54 4.560 0.142 13.57
单元测试 1 100 17.34 17.34 5.766 0.058 13.58
API调用 1 90 17.80 17.80 5.056 0.109 13.57
装饰器 2 70 17.29 34.58 4.048 0.085 13.65
列表推导 4 50 17.43 69.71 2.869 0.055 13.66
异常处理 1 85 17.22 17.22 4.938 0.056 13.57
---
## 四、性能分析与结论
### 1. 代码任务类型影响
- 函数实现(80 token):17.54 tokens/秒
- 单元测试(100 token):17.34 tokens/秒
✅ 结论:不同代码生成任务吞吐波动 < 2%,NPU 支持稳定。
### 2. 批量并发效率
- batch=2 总吞吐:34.58 tokens/秒(≈2.0×单请求)
- batch=4 总吞吐:69.71 tokens/秒(≈3.8×单请求)
✅ 结论:接近线性加速,适合高并发代码生成服务。
### 3. 显存与部署建议
- 峰值显存:13.66 GB(batch=4 时)
✅ 建议:生产环境使用 ≥16GB 显存的昇腾 NPU。
---
## 五、优化建议
1. **优先启用 batch 推理**:batch=2~4 可显著提升吞吐。
2. **关闭采样(do_sample=False)**:保证代码确定性,提升速度。
3. **避免超长上下文**:输入 + 输出总长度建议 ≤1024 tokens。
4. **服务启动预热**:前 5 次推理用于算子编译,不计入性能统计。
---
## 六、测试结果文件
原始数据已保存至:
- `codellama_npu_benchmark_fp16_20251210_102935.json`
- `codellama_npu_benchmark_summary_fp16_20251210_102935.md`
5.2 常见警告说明
● [W VariableFallbackKernel.cpp:51] Warning: CAUTION: The operator ‘aten::isin.Tensor_Tensor_out’ is not currently supported on the NPU backend… 原因:transformers 内部调用了 NPU 未支持的 torch.isin。
● 影响:极轻微(仅在 token 过滤阶段 fallback 到 CPU)。
● 结论:可安全忽略,不影响主推理流程。
总结
昇腾 NPU 已能良好支持 CodeLlama 等开源大模型的本地化部署与高并发推理,为国产 AI 基础设施在智能编程领域的应用提供了可靠实践路径。
GitCode Notebook 的昇腾 NPU 环境中,从零开始部署并测评 CodeLlama-7b-Python 模型的完整流程。
内容涵盖三大核心环节:
1. 环境配置:通过一键 Shell 脚本自动安装兼容的 PyTorch(2.1.0)与 torch_npu(2.1.0.post3),并验证 NPU 可用性;
2. 模型下载:利用国内 Hugging Face 镜像(hf-mirror.com)高效下载 CodeLlama 模型,避免网络超时问题;
3. 推理与性能测评:通过最小化 Demo 验证推理链路,并运行多场景基准测试脚本,全面评估吞吐量、延迟与显存占用。
关键成果:
● 模型在 FP16 精度下稳定运行,单请求生成速度达 ~17.5 tokens/s;
● 启用批处理(batch=4)后总吞吐提升至 69.71 tokens/s,接近线性加速;
● 峰值显存仅 13.66 GB,证明昇腾 NPU 具备高效运行 7B 级代码大模型的能力。
免责声明
本文所述操作基于特定时间点(2025年)的软件版本与平台环境,包括但不限于 GitCode Notebook、PyTorch、torch_npu 及 Hugging Face Transformers。由于软硬件生态持续演进,部分内容可能在未来失效或需要调整。
作者不对因复现本文内容而导致的任何系统异常、数据丢失或性能偏差承担责任。建议读者在正式环境中先行充分测试。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 104
104 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)