
【AI小智后端部分(五)】
util 为所有模块提供基础支撑 → llm 生成文本回复 → tts 把文本转 OPUS 音频(依赖audio_format) → audio_format 处理 OPUS 格式存储 / 读取 → asr 把 OPUS 音频转回文本(依赖audio_format)chatglm.pytts部分base.pyedge.py这个写法是抽象类的混合设计模式—— 把 “所有 TTS 引擎都通用的逻辑”
AI小智后端部分(五)
链接: B站Up
整体流程
util 为所有模块提供基础支撑 → llm 生成文本回复 → tts 把文本转 OPUS 音频(依赖audio_format) → audio_format 处理 OPUS 格式存储 / 读取 → asr 把 OPUS 音频转回文本(依赖audio_format)
- TTS 把文本转 OPUS 音频 → 依赖 audio_format
TTS 模块(tts/edge.py + tts/base.py)完成 “文本→OPUS 音频” 的核心依赖是:
调用 opus.py 的 audio_to_opus() 函数:
TTS 先把文本转为 MP3 音频文件,再通过 tts/base.py 中的 audio_file_to_opus 方法,调用 opus.py 的 audio_to_opus(),将 MP3 文件转为 OPUS 字节数据(这是 TTS 输出 OPUS 的核心步骤)。- audio_format 处理 OPUS 格式存储 / 读取 → 依赖 audio_format
这一步是直接调用 opus.py 的两个核心函数:
存储 OPUS:调用 opus.py 的 save_opus_raw(),把 TTS 生成的 OPUS 字节数据序列化,保存为本地 .opus 文件;
读取 OPUS:调用 opus.py 的 load_opus_raw(),读取本地 .opus 文件,还原为 OPUS 字节数据(供 ASR 识别)。- ASR 把 OPUS 音频转回文本 → 依赖 audio_format
ASR 模块(asr/fun_asr.py + asr/base.py)完成 “OPUS→文本” 的核心依赖是:
调用 opus.py 的 opus_to_wav_file() 函数:
ASR 先通过 asr/base.py 中的 opus_data_to_wav 方法,调用 opus.py 的 opus_to_wav_file(),将 OPUS 字节数据转为 ASR 能识别的 WAV 文件(这是 ASR 识别的前提),然后再用ASR的aduio_file_to_text将WAV文件转成文本
代码重构
llm部分
base.py
from abc import ABC, abstractmethod
class Llm(ABC):
@abstractmethod
def generate_response(self, text):
"""生成响应"""
raise NotImplementedError()
chatglm.py
class ChatGLM_LLM(Llm):
def __init__(self,config):
self.model_name = config.get("model_name")
self.api_key = config.get("api_key")
self.url = config.get("url")
self.client = OpenAI(api_key=self.api_key, base_url=self.url)
def generate_response(self, user_input):
dialogue = [
{"role": "system", "content": "不要回复表情包"},
{"role": "user", "content": user_input},
]
response = self.client.chat.completions.create(
model=self.model_name,
messages=dialogue,
)
return response.choices[0].message.content
base.py 是 “规则制定者”
它定义了一个名为Llm的抽象基类(ABC),只规定了所有大语言模型类必须遵守的接口规则—— 必须实现generate_response(self, text)方法。
它自己不做任何实际的 “模型调用” 工作,只是画了一个 “模板”,告诉所有继承它的子类:“你想成为一个 LLM 类,就必须实现这个生成响应的方法”。
这个文件的作用是统一所有 LLM 类的调用方式,比如后续你想加 GPT、文心一言的调用类,都要继承这个Llm类,保证对外都能用generate_response方法调用,不用改上层代码。
chatglm.py 是 “规则执行者”
它通过class ChatGLM_LLM(Llm)明确继承了base.py里的Llm抽象类,必须遵守base.py定的规则。
它具体实现了generate_response方法 —— 把 “调用 ChatGLM 模型的逻辑(初始化客户端、构造对话、调用 API、返回结果)” 写进这个方法里,让抽象的 “规则” 变成可运行的 “实际功能”。
tts部分
base.py
from abc import ABC, abstractmethod
from ai_core.audio_format.opus import Opus_Encode
class Tts(ABC):
def audio_file_to_opus(self,audio_path):
"""将语音文件转为opus数据返回"""
opus = Opus_Encode()
opus_datas, duration = opus.audio_to_opus(audio_path)
return opus_datas,duration
@abstractmethod
def text_to_opus_data(self, text):
"""将文本转为opus数据"""
raise NotImplementedError()
edge.py
import os
import edge_tts
from ai_core.audio_format.opus import Opus_Encode
from ai_core.tts.base import Tts
from ai_core.utils.util import Util
class Edge_TTS(Tts):
def __init__(self,config):
self.output_dir = Util.get_project_dir() + config.get("output_dir")
self.voice = config.get("voice")
async def text_to_opus_data(self, text):
audio_path = Util.get_random_file_path(self.output_dir, "mp3")
communicate = edge_tts.Communicate(text, self.voice)
await communicate.save(audio_path)
# 判断是否生成mp3文件
if not os.path.exists(audio_path):
return None
return super().audio_file_to_opus(audio_path)
这个写法是抽象类的混合设计模式—— 把 “所有 TTS 引擎都通用的逻辑” 提前实现,把 “不同 TTS 引擎差异的逻辑” 留空让子类实现,核心目的是:减少重复代码,同时保证接口统一。
- audio_file_to_opus:通用逻辑,提前实现
不管是 Edge_TTS、讯飞 TTS 还是百度 TTS,最终都需要把生成的音频文件(比如 MP3/WAV)转成 Opus 格式,这个转换逻辑是完全一样的,所以:
直接在抽象父类Tts里写好,所有子类继承后 “开箱即用”;
子类不用重复写 “音频文件转 Opus” 的代码,避免冗余;
后续如果要优化 Opus 转换逻辑,只改父类这一处即可,所有子类都会受益。 - text_to_opus_data:差异化逻辑,抽象留空
不同 TTS 引擎生成音频的方式完全不同:
Edge_TTS:调用微软的 API 生成 MP3 文件;
讯飞 TTS:调用讯飞的 API 生成 WAV 文件;
百度 TTS:调用百度的 API 生成 MP3 文件;
这些 “把文本转成音频文件,再转 Opus” 的核心逻辑是每个 TTS 引擎独有的,所以父类无法提前实现,只能:
用@abstractmethod标记为 “必须实现的接口”;
强制子类(比如Edge_TTS)必须写这个方法的具体逻辑;
保证所有子类对外都有统一的text_to_opus_data方法,上层调用时不用关心具体是哪个 TTS 引擎。
audio_format部分
opus.py
import os
import pickle
import wave
from typing import List
import numpy as np
import opuslib_next
from pydub import AudioSegment
class Opus_Encode():
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
def __init__(self):
self.sample_rate = 16000
self.channel = 1
self.sample_width = 2
self.opus_sample_rate = 16000
self.opus_channel = 1
self.opus_sample_width = 2
self.opus_frame_time = 60 # 60毫秒
self.opus_frame_size = int(self.opus_sample_rate / 1000 * self.opus_frame_time)
def audio_to_opus(self, audio_file_path):
file_type = os.path.splitext(audio_file_path)[1]
#.mp3 .wav
if file_type:
file_type = file_type.lstrip(".")
# 加载音频文件
audio = AudioSegment.from_file(audio_file_path, format=file_type)
# 调整音频参数
audio = audio.set_channels(self.channel).set_frame_rate(self.sample_rate).set_sample_width(self.sample_width)
# 计算音频总时长,单位为秒
duration = len(audio) / 1000
# 获取音频PCM数据
raw_data = audio.raw_data
print(f"音频PCM数据长度:{len(raw_data)} 字节")
encoder = opuslib_next.Encoder(self.opus_sample_rate, self.opus_channel, opuslib_next.APPLICATION_AUDIO)
# 获取每帧的采样数
frame_num = self.opus_frame_size
# 计算每帧的采样字节数
frame_bytes_size = frame_num * self.opus_channel * self.opus_sample_width
opus_datas = []
for i in range(0, len(raw_data), frame_bytes_size):
# 获取当前帧的PCM数据
chunk = raw_data[i:i+frame_bytes_size]
# 计算当前帧长度
chunk_len = len(chunk)
# 如果当前帧长度不足,则填充0
if chunk_len < frame_bytes_size:
chunk += b'\x00' * (frame_bytes_size - chunk_len)
np_frame = np.frombuffer(chunk, dtype=np.int16)
np_bytes = np_frame.tobytes()
opus_data = encoder.encode(np_bytes, frame_num)
opus_datas.append(opus_data)
return opus_datas,duration
def save_opus_raw(self , opus_datas,output_path):
with open(output_path, 'wb') as f:
pickle.dump(opus_datas, f)
def load_opus_raw(self,input_path):
with open(input_path, 'rb') as f:
opus_datas = pickle.load(f)
return opus_datas
def opus_to_wav_file(self,output_file, opus_data : List[bytes]) -> str:
decoder = opuslib_next.Decoder(self.opus_sample_rate, self.opus_channel)
pcm_data = []
for frame in opus_data:
try:
pcm_frame = decoder.decode(frame,self.opus_frame_size)
pcm_data.append(pcm_frame)
except opuslib_next.OpusError as e:
print(f"解码失败:{e}")
with wave.open(output_file, 'wb') as wav_file:
wav_file.setnchannels(self.opus_channel)
wav_file.setsampwidth(self.opus_sample_width)
wav_file.setframerate(self.opus_sample_rate)
wav_file.writeframes(b''.join(pcm_data))
return output_file
if __name__ == '__main__':
opus = Opus_Encode()
opus_data,duration = opus.audio_to_opus("../../test.mp3")
print(f"音频总时长:{duration} 秒")
opus.save_opus_raw(opus_data,"test.opus")
opus_data1 = opus.load_opus_raw("test.opus")
print(opus_data1)
这是一个实现音频(MP3/WAV)与 Opus 编码格式互转的工具类,核心功能包括音频转 Opus 编码、Opus 数据序列化存储 / 读取、Opus 解码还原为 WAV 文件。
asr部分
base.py
from abc import ABC, abstractmethod
from ai_core.audio_format.opus import Opus_Encode
class Asr(ABC):
def opus_data_to_wav(self,opus_data, file_path):
"""将opus数据转为wav并保存到file_path"""
opus = Opus_Encode()
print(file_path)
opus.opus_to_wav_file(file_path, opus_data)
@abstractmethod
def opus_data_to_text(self, opus_data):
"""将opus数据转为文本"""
raise NotImplementedError()
fun_asr.py
import os
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
from ai_core.asr.base import Asr
from ai_core.audio_format.opus import Opus_Encode
from ai_core.utils.util import Util
class FunAsr(Asr):
def __init__(self,config):
self.output_dir = Util.get_project_dir() +config.get("output_dir")
self.model_dir = config.get("model_dir")
self.model = AutoModel(
model=self.model_dir,
vad_kwargs={"max_single_segment_time": 30000},
# device="cuda:0",
disable_update=True,
hub="hf",
)
def audio_file_to_text(self,file_path):
res = self.model.generate(
input=file_path,
language="auto",
use_itn=True,
)
res = res[0]["text"]
print(res)
return rich_transcription_postprocess(res)
def opus_data_to_text(self,opus_data):
file_path = Util.get_random_file_path(self.output_dir, "wav")
super().opus_data_to_wav(opus_data, file_path)
# 判断输出文件是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_path} 不存在")
res = self.audio_file_to_text(file_path)
return res
base.py:通用能力 + 接口约束(不能少)
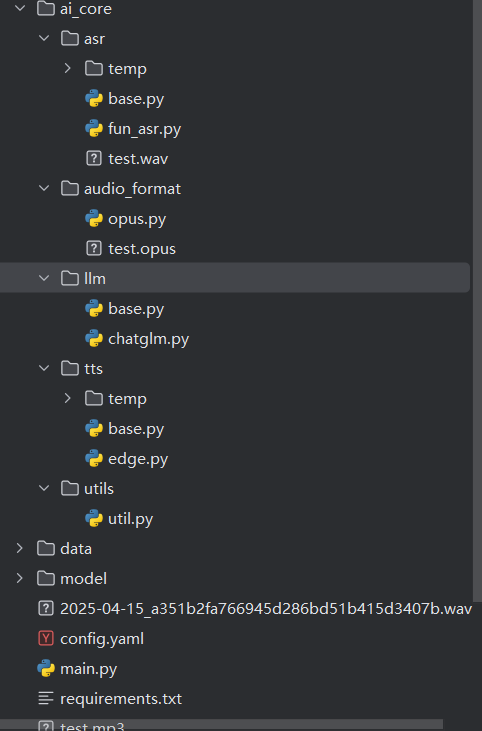
核心价值 1:封装通用逻辑opus_data_to_wav 方法是所有 ASR 引擎都需要的(不管是 FunASR、讯飞 ASR 还是阿里云 ASR,都需要先把 OPUS 转 WAV),base.py 把这个逻辑抽出来,避免每个 ASR 子类都重复写 “OPUS 转 WAV” 的代码(比如后续加讯飞 ASR,直接继承 Asr 就能用这个方法)。
如果删掉 base.py,FunAsr 类里必须自己实现opus_data_to_wav,会导致代码冗余,且后续扩展其他 ASR 引擎时重复造轮子。
核心价值 2:强制接口规范@abstractmethod 修饰的opus_data_to_text是 “强制要求”—— 所有继承 Asr 的子类(比如 FunAsr)必须实现这个方法,否则运行时会直接抛NotImplementedError。这个约束能保证所有 ASR 子类都有统一的调用入口(上层代码只需要调opus_data_to_text,不用关心底层是 FunASR 还是讯飞 ASR)。
如果删掉 base.py,虽然也能写 FunAsr 类,但没有统一的接口规范,后续扩展 / 维护会混乱(比如不同 ASR 子类的 “转文本” 方法名不一样,上层调用要写大量 if-else)。
后面的opus_data_to_text接连调用了
opus_data_to_wav和aduio_file_to_text
utils部分
util.py
import argparse
import os
import uuid
from datetime import datetime
from pathlib import Path
import yaml
class Util:
@staticmethod
def get_project_dir():
"""获取工程根目录"""
root = Path(__file__).resolve().parent.parent.parent
return f"{root}{os.sep}" # 使用系统分隔符
@staticmethod
def get_config_file_path():
default_config_file = "config.yaml"
"""获取配置文件路径"""
if os.path.exists(Util.get_project_dir() + "data/." + default_config_file):
config_file = "data/." + default_config_file
else:
config_file = Util.get_project_dir() + default_config_file
return config_file
@staticmethod
def get_config():
"""加载配置文件"""
parser = argparse.ArgumentParser(description="Server configuration")
config_file = Util.get_config_file_path()
parser.add_argument("--config_path", type=str, default=config_file)
args = parser.parse_args()
print(f"Loading configuration from {args.config_path}")
with open(args.config_path, "r", encoding="utf-8") as file:
config = yaml.safe_load(file)
# 初始化目录
Util.init_output_dirs(config)
return config
@staticmethod
def init_output_dirs(config):
"""自动扫描所有层级的 output_dir 配置"""
results = set()
def _traverse(data):
"""递归遍历函数"""
if isinstance(data, dict):
# 先检查当前层级是否有 output_dir
if "output_dir" in data:
results.add(data["output_dir"])
# 继续深入遍历所有值
for value in data.values():
_traverse(value)
elif isinstance(data, list):
# 遍历列表中的每个元素
for item in data:
_traverse(item)
_traverse(config)
# 统一创建目录(保留原data目录创建)
for dir_path in results:
try:
os.makedirs(Util.get_project_dir() + dir_path, exist_ok=True)
except PermissionError:
print(f"警告:无法创建目录 {dir_path}")
@staticmethod
def get_random_file_path(dir: str, ex_name: str):
"""获取随机文件保存路径"""
file_name = f"{datetime.now().date()}_{uuid.uuid4().hex}.{ex_name}"
file_path = os.path.join(dir, file_name)
return file_path
if __name__ == "__main__":
print(Util.get_project_dir())
print(Util.get_random_file_path(Util.get_project_dir(), "mp3"))
这个util.py文件定义了一个名为Util的工具类,封装了多个通用的静态方法,主要实现工程目录管理、配置文件加载、目录自动初始化、随机文件路径生成等核心功能

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)