
昇腾MindSpeed RL的transfer-dock特性代码解析
在LLM后训练过程中,各个计算任务之间存在较多数据依赖。为此,提供一个数据管理系统用于管理后训练中的数据流程。本方案在LLM后训练系统中连接了推理框架与训练框架,扮演了转运港口的角色:1、数据生产者将生成数据写入到数据系统中;2、数据系统将数据存储至预先分配的缓存区,并更新数据状态;3、数据消费者向数据系统发送请求,若存在足量数据,则将对应数据组织为Batch,返回给数据消费者。在该架构中,推理框
在LLM后训练过程中,各个计算任务之间存在较多数据依赖。为此,提供一个数据管理系统用于管理后训练中的数据流程。
本方案在LLM后训练系统中连接了推理框架与训练框架,扮演了转运港口的角色:
1、数据生产者将生成数据写入到数据系统中;
2、数据系统将数据存储至预先分配的缓存区,并更新数据状态;
3、数据消费者向数据系统发送请求,若存在足量数据,则将对应数据组织为Batch,返回给数据消费者。
在该架构中,推理框架、训练框架中的各个实例数据均存放至数据调度模块,由其统一调度,从而避免了各个实例之间的绑定,提高了整体计算资源的利用率。
详细实现原理请参考:transfer-dock,下面我们对transfer_dock的代码实现做详细的介绍。
相关代码
- transfer_dock实现: mindspeed_rl/trainer/utils/transfer_dock.py
- 辅助函数: mindspeed_rl/utils/pad_process.py
- 调用transfer_dock的实现:
- mindspeed_rl/workers/base_worker.py
- mindspeed_rl/workers/actor_hybrid_worker.py
- mindspeed_rl/trainer/utils/compute_utils.py
Transfer Dock实现简介
相关代码
mindspeed_rl/trainer/utils/transfer_dock.py
mindspeed_rl/utils/pad_process.py
实现介绍
transfer_dock实现了基类TransferDock,对于GRPO实现了GRPOTransferDock来继承TransferDock。
TransferDock介绍
重要数据结构
experience_columns:
List类型,存放列名,即训练过程中产生的重要中间经验数据的名称
experience_data:
字典类型,key为experience_columns中的列名,value为prompts_num * n_samples_per_prompt长度的列表。用于存放经验数据。
experience_data_status:
字典类型,key为experience_columns中的列名,value为prompts_num * n_samples_per_prompt长度的zero tensor。用于存放经验数据是否ready的状态,1表示ready,0未ready。
|
class TransferDock(ABC): def __init__(...): ... #prompts_num:推理prompt数 #n_samples_per_prompt: 每个prompt做几次推理 self.max_len = prompts_num * n_samples_per_prompt
self.experience_columns = ( experience_columns if experience_columns is not None else [] ) #训练过程中产生的重要中间经验数据的名称 self.experience_data = { key: [None for _ in range(self.max_len)] for key in self.experience_columns } #记录数据类型、数据index、数据内容 self.experience_data_status = { key: torch.zeros(self.max_len, dtype=torch.int32) for key in self.experience_columns } #记录数据是否ready可用 |
重要方法
_put:
- 参数:experience_columns(列)、experience(数据)、indexes(行)
- 存放数据时会将对应行列对应索引的experience_data_status置为1(ready)。
- _put要求的输入格式
|
experience_columns: Columns to put data in. ['prompts', 'attention_mask'] experience: Data for the corresponding columns. [ [ tensor([1, 1, 1, 1]), tensor([2, 2, 2, 2]), tensor([3, 3, 3, 3]), tensor([4, 4, 4, 4]) ], [ tensor([1]), tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4]) ] ] indexes: Rows to put data in. [0, 1, 2, 4] |
_get:
- 参数:experience_columns(取哪些列)、indexes(取哪些行)
- 从指定行列获取数据,获取前会调用_wait_for_data判断数据是否就绪。
- _get的输入输出格式:
|
experience_columns: Columns from which to get data. ['prompts', 'attention_mask'] indexes: Rows to get data from. [0, 2] Returns: Data list. [ [ tensor([1, 1, 1, 1]), tensor([2, 2, 2, 2]), tensor([3, 3, 3, 3]), tensor([4, 4, 4, 4]) ], [ tensor([1]), tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4]) ] ] |
_wait_for_data:
根据experience_data_status判断数据是否就绪,用于_get数据前判断数据是否就绪
_clear_experience_data_and_status:
清空数据和状态。支持整体数据清空和清空指定index
GRPOTransferDock介绍
重要数据结构
experience_columns:
列表类型,定义了grpo所需要的列名(即中间需要存放和流转的数据)
experience_consumers:
列表类型,定义了消费者(即训练过程需要消费和存放数据的阶段)
experience_consumer_status:
- 记录消费者对每个数据位置的消费情况,1表示已经消费。
- 字典类型,key为experience_consumer,value为prompts_num * n_samples_per_prompt长度的zero tensor。
- 通过experience_consumer_status实现了不同consumer数据消费状态的跟踪,避免了不同consumer消费之间读数据的冲突
- 通过consumer+indexes可以避免同consumer不同DP组的写冲突
consumer_sampling_lock
数据采样是带锁的操作 consumer_sampling_lock[consumer],避免同一个consumer不同DP组之间的冲突,详见_sample_ready_index_n_samples代码
|
class GRPOTransferDock(TransferDock): def __init__(...): self.experience_consumers = [ "trainer", "actor_rollout", #prompts推理,生成responses "actor_log_prob", "ref_log_prob", "actor_train", #actor训练 "compute_advantage", "rule_reward", "reward_scores", "grpo_metrics" ] #代表RL训练的不同任务阶段 self.experience_consumer_status = { key: torch.zeros(self.max_len, dtype=torch.int32) for key in self.experience_consumers } #记录数据是否被某个consumer消费过 self.consumer_sampling_lock = { key: threading.Lock() for key in self.experience_consumers } #consumer锁 self.experience_columns = [ "prompts", "prompt_length", "responses", "response_length", "attention_mask", "labels", "input_ids", "input_ids_length", "actor_rollout", "rm_scores", "token_level_rewards", "old_log_prob", "ref_log_prob", "advantages", "returns" ] #grpo所需要的列名(即中间需要存放和流转的数据) |
重要方法
get_experience:
- 参数:consumer(谁在取)、experience_columns(取哪些列)、experience_count(取多少条)、indexes(取哪些索引,可选)
- 逻辑:
- 如果提供indexes,直接通过indexes、experience_columns调用_get取数据
- 如果没有提供indexes,调用_sample_ready_index_n_samples或者_sample_ready_index来自动选一批对当前消费者可用的数据索引。
- _sample_ready_index_n_samples或者_sample_ready_index生成indexes的时候,会结合experience_consumer_status和experience_data_status一起判断哪些indexes可用且未被消费过。
- 选完索引会对experience_consumer_status对应consumer、indexes位置状态置1(表示已经消费,标记完马上会用)。
- 生成indexes之后,也是通过调用_get取数据
- 最后将_get()得到的list类型的数据,经过padding、torch.stack等操作,最后打包成字典TensorDict,返回TensorDict, indexes(实际调用padding_dict_to_tensor_dict实现)
- 输出格式
|
output: TensorDict格式 output["prompt"] = tensor([1,1,1,0], [2,2,2,2]) output["origtinal_length"] = tensor([3,4]) |
- 代码
|
def get_experience( self, consumer: str, experience_columns: List[str], experience_count: int = None, dp_size: int = 1, indexes: List[int] = None, get_n_samples: bool = True, use_batch_seqlen_balance: bool = False #使用DP Batch Balance ): ...... if indexes is None: #没有提供数据indexes,需要通过一定算法采样出indexes ...... if get_n_samples: ...... indexes = self._sample_ready_index_n_samples( consumer, experience_count, experience_columns, use_batch_seqlen_balance=use_batch_seqlen_balance ) ...... if not indexes: return None, None #读取数据 experience = self._get(experience_columns, indexes) else: #提供数据indexes,先设置数据消费状态,再读取数据 self.experience_consumer_status[consumer][indexes] = 1 experience = self._get(experience_columns, indexes) ...... #数据格式处理 experience_batch = {} for i, experience_column in enumerate(experience_columns): experience_batch[experience_column] = experience[i] experience_batch = padding_dict_to_tensor_dict(experience_batch) return experience_batch, indexes |
|
def _sample_ready_index_n_samples( self, consumer: str, experience_count: int, experience_columns: List[str], ... ) -> Optional[List[int]]: experience_count_n_samples = experience_count // self.n_samples_per_prompt with self.consumer_sampling_lock[consumer]: #带锁操作 #根据experience_consumer_status计算not_consumed_indexes experience_consumer_status_n_samples = ( 1 - torch.all( torch.tensor( torch.reshape( self.experience_consumer_status[consumer], (self.prompts_num, self.n_samples_per_prompt), ) == 0 ), dim=1, ).int() ) not_consumed_indexes = experience_consumer_status_n_samples == 0 #根据experience_data_status计算data_ready_indexes experience_data_status_n_samples = {} for key, value in self.experience_data_status.items(): experience_data_status_n_samples[key] = torch.all( torch.tensor( torch.reshape(value, (self.prompts_num, self.n_samples_per_prompt)) == 1 ), dim=1, ).int() data_ready_indexes = torch.all( torch.stack( [experience_data_status_n_samples.get(single_column) == 1 \ for single_column in experience_columns]), dim=0, ) ...... #根据not_consumed_indexes和data_ready_indexes计算usable_indexes usable_indexes = (not_consumed_indexes & data_ready_indexes).nonzero(as_tuple=True)[0]
if len(usable_indexes) < experience_count_n_samples: return None if self.enable_partial_rollout: sampled_indexes_n_sample = [int(i) for i in \ usable_indexes[:experience_count_n_samples]] elif consumer in self.batch_seqlen_balance_mapper and \ use_batch_seqlen_balance and \ len(usable_indexes) % experience_count_n_samples == 0: sampled_indexes_n_sample = self.batch_seqlen_balance_sampler( consumer, usable_indexes, experience_count_n_samples, get_n_samples=True) if not sampled_indexes_n_sample: return None else: sampled_indexes_n_sample = self.batch_balencing_sampler( experience_columns, usable_indexes, experience_count_n_samples, target_seq_len, ) sampled_indexes = [] for n_sample_index in sampled_indexes_n_sample: index_list = [] for index in range( n_sample_index * self.n_samples_per_prompt, (n_sample_index + 1) * self.n_samples_per_prompt ): index_list.append(index) sampled_indexes += index_list #设置消费状态 self.experience_consumer_status[consumer][sampled_indexes] = 1 return sampled_indexes |
put_experience:
- 参数:data_dict(要存的数据)、indexes(存放位置row)
- 逻辑:
- 调用remove_padding_tensor_dict_to_dict,做padding_dict_to_tensor_dict的逆操作,恢复data_dict
- 调用trans_input_to_experience将data_dict转换为experience_columns, experience两个列表
- 调用_get将数据放入experience_data,并标记experience_data_status
- 输入数据格式
|
input: TensorDict格式 output["prompt"] = tensor([1,1,1,0], [2,2,2,2]) output["origtinal_length"] = tensor([3,4]) |
all_consumed:
通过下面语句判断consumer的数据是否消费完:experience_consumer_status[consumer].sum() == self.max_len
clear:
清空experience_consumer_status、experience_data、experience_data_status
辅助函数
pad_experience
把list[tensor]的字典,通过padding和合并,转换成一个batched的tensor字典,用于喂给模型。输入输出格数如下:
|
experience_batch: Dict { 'prompts': [ tensor([1, 1, 1, 1]), tensor([2, 2, 2, 2]), tensor([3, 3, 3, 3]), tensor([4, 4, 4, 4])], 'attention_mask': [ tensor([1]), tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4])], } pad_id: Pad token. 0.0 multiple: The multiple of TP to pad. 1 Returns: Merged and padded data dict. { "prompts": tensor( [[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]]), "attention_mask": tensor( [[1, 0, 0, 0], [2, 2, 0, 0], [3, 3, 3, 0], [4, 4, 4, 4]]), } |
pack_experience_columns
把多个变长tensor首尾相连成一个一维的长tensor,并记录每个原始tensor的长度。用于传输前压缩,减少通信开销。输入输出格式:
|
from experience_dict { 'prompts': [ tensor([1, 1, 1]), tensor([2, 2, 2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4])], 'attention_mask': [ tensor([1]), tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4])], } To batch_data { 'prompts': tensor([1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4]), 'attention_mask': tensor([1, 2, 2, 3, 3, 3, 4, 4, 4, 4]) } batch_data_length { 'prompts': tensor([3, 4, 3, 4]), 'attention_mask': tensor([1, 2, 3, 4]) } |
unpack_pad_experience
pack_experience_columns的逆操作。
- 先恢复到pack_experience_columns前的样子
- 再进行pad_experience操作
- 输入输出格数如下:
|
from batch_data { 'prompts': tensor([1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4]), 'attention_mask': tensor([1, 2, 2, 3, 3, 3, 4, 4, 4, 4]) } batch_data_length { 'prompts': tensor([3, 4, 3, 4]), 'attention_mask': tensor([1, 2, 3, 4]) } To padded_batch_data (multiple=2) { "prompts": tensor( [[1, 1, 1, -1, -1, -1, -1, -1], [2, 2, 2, 2, -1, -1, -1, -1], [3, 3, 3, -1, -1, -1, -1, -1], [4, 4, 4, 4, -1, -1, -1, -1]]), "attention_mask": tensor( [[1, -1, -1, -1, -1, -1, -1, -1], [2, 2, -1, -1, -1, -1, -1, -1], [3, 3, 3, -1, -1, -1, -1, -1], [4, 4, 4, 4, -1, -1, -1, -1]]), } |
put_prompts_experience
RayGRPOTrainer.fit中使用,将原始的数据集中的batch转换为n_sample_per_prompt份,放入transferDock前的准备
trans_input_to_experience
- 将tensor字典转换为列名、数据列表
- put_experience中调用trans_input_to_experience
- 输入输出格式
|
experience_dict: Data dict. { "prompts": tensor( [[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]]), "attention_mask": [ tensor([1]), tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4])] } num_responses: The number of data to put in each row. 2 Returns: Columns and data list. ['prompts', 'attention_mask'] [ [ tensor([1, 1, 1, 1]), tensor([2, 2, 2, 2]), tensor([3, 3, 3, 3]), tensor([4, 4, 4, 4]) ], [ tensor([1)], tensor([2, 2]), tensor([3, 3, 3]), tensor([4, 4, 4, 4]) ] ] |
remove_padding_tensor_dict_to_dict
- 将一个已经填充的TensorDict转换回包含原始Tensor列表的字典。
- get_experience用以后马上做remove_padding_tensor_dict_to_dict(再细看)
- 输入输出数据格式
|
input: TensorDict格式 output["prompt"] = tensor([1,1,1,0], [2,2,2,2]) output["origtinal_length"] = tensor([3,4]) output: { 'prompt': [tensor([1,1,1]), tensor([2,2,2,2])], 'attention_mask': [tensor([1]), tensor([2,2])] } |
padding_dict_to_tensor_dict
- 把一个dict[str,List[Tensor]] 格式的experience_data转换为一个TensorDict; 并对每个列表中的Tensor进行填充,使其长度一致
- put_experience之前要配合做padding_dict_to_tensor_dict
- 输入输出数据格式
|
input: { 'prompt': [tensor([1,1,1]), tensor([2,2,2,2])], 'attention_mask': [tensor([1]), tensor([2,2])] } output: TensorDict格式 output["prompt"] = tensor([1,1,1,0], [2,2,2,2]) output["origtinal_length"] = tensor([3,4]) |
BaseWorker实现简介
相关代码:
mindspeed_rl/workers/base_worker.py
实现介绍
在BaseWorker中实现了下面三个重要方法,主要是针对分布式计算又做了一些额外处理,具体对TransferDock的操作还是调用TransferDock中的方法来实现。
all_consumed
- 输入experience_consumer_stage,判断并行组中数据是不是消费完了(使用ReduceOP.Max).
- 0表示消费完
|
def all_consumed(self, experience_consumer_stage, sorted_indexes, use_vllm=False): ...... status = torch.tensor(0, device=current_device) #判断当前worker是否在TP、PP、CP(vllm没有)并行组中rank均为0 if not use_vllm: rank_flg = (get_tensor_model_parallel_rank(self.parallel_state, use_vllm) == 0 \ and get_context_parallel_rank(self.parallel_state, use_vllm) == 0 \ and get_pipeline_model_parallel_rank(self.parallel_state, use_vllm) \ == 0) else: rank_flg = (get_tensor_model_parallel_rank(self.parallel_state, use_vllm) == 0 \ and get_pipeline_model_parallel_rank(self.parallel_state, use_vllm) \ == 0) #只在各个并行组中rank为0的这个work来判断数据是否都消费完(True为消费完),即1个DP组内判断一次即可 if rank_flg: ...... status = torch.tensor( int(not ray.get(self.td.all_consumed.remote(experience_consumer_stage))), device=current_device) #在并行组中同步status torch.distributed.all_reduce(status, group=get_model_parallel_group(self.parallel_state, use_vllm), op=torch.distributed.ReduceOp.MAX) if not use_vllm: torch.distributed.all_reduce(status, group=get_context_parallel_group(self.parallel_state, use_vllm), op=torch.distributed.ReduceOp.MAX) #read code: status=0 消费完了; status=1 没消费完 return status |
dispatch_transfer_dock_data
在并行组的rank0从TransferDock存储中读取数据,并通过广播分发到并行组中其他rank,主要有以下几个步骤:
- 调用self.td.get_experience读取数据
- 然后调用remove_padding_tensor_dict_to_dict
|
batch_data, index = ray.get( self.td.get_experience.remote(experience_consumer_stage, experience_columns, experience_count, indexes=indexes, get_n_samples=get_n_samples, use_batch_seqlen_balance=self.rl_config.use_dp_batch_balance)) batch_data = remove_padding_tensor_dict_to_dict(batch_data) |
- 数据广播前,通过调用pack_experience_columns,把多个变长tensor首尾相连成一个一维的长tensor,并记录每个原始tensor的长度。用于传输前压缩,减少通信开销
|
if rank_flg: batch_data, batch_data_length = pack_experience_columns(experience_consumer_stage, batch_data, experience_count, enable_partial_rollout=enable_partial_rollout, ) |
- 数据广播后,调用unpack_pad_experience,做pack_experience_columns的逆操作。
- 先将数据恢复到pack_experience_columns前的样子
- 再进行pad_experience操作,把数据转换成适合模型输入的格式
|
padded_batch_data = unpack_pad_experience(batch_data, batch_data_length, pad_id, tp_size * cp_size) |
collect_transfer_dock_data
- 调用padding_dict_to_tensor_dict
- 调用self.td.put_experience将数据写入TransferDock
|
def collect_transfer_dock_data(self, output, index, use_vllm=False): if is_pipeline_last_stage(self.parallel_state, use_vllm) and \ get_tensor_model_parallel_rank(self.parallel_state, use_vllm) == 0: output = {key: value.cpu() if not isinstance(value, List) else value for key, value in output.items()} output = padding_dict_to_tensor_dict(output) ...... self.td.put_experience.remote(data_dict=output, indexes=index) |
get_dp_range_indexes
获取当前dp组对应的数据indexes
使用逻辑
初始化
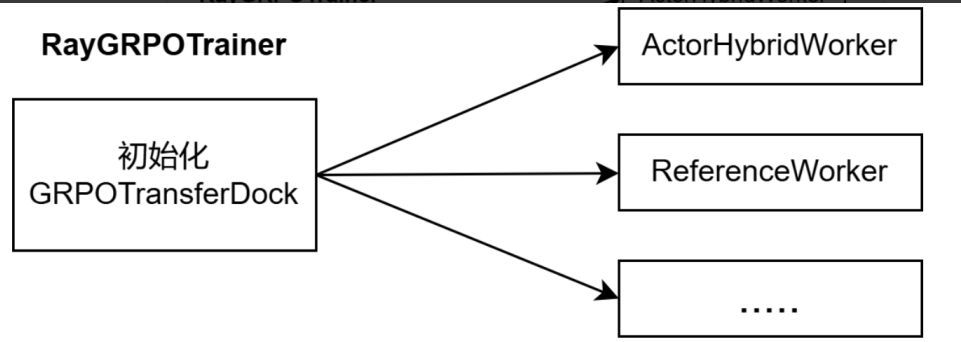
RayGRPOTrainer 初始化的时候调用了self.transfer_dock_init()来初始化transfer_dock:
- 首先在RayGRPOTrainer 中实例化GRPOTransferDock
- 然后将实例化后的对象transfer_dock作为参数传给各worker
|
# mindspeed_rl.trainer.grpo_trainer_hybrid.RayGRPOTrainer class RayGRPOTrainer(RayBaseTrainer): def __init__( self, actor_worker: RayActorGroup, ref_worker: RayActorGroup, reward_list: List[Union[RayActorGroup, RuleReward]], ... ): ...... self.transfer_dock = None self.mm_transfer_dock = None self.transfer_dock_init() def transfer_dock_init(self): #实例化GRPOTransferDock self.transfer_dock = GRPOTransferDock.remote( prompts_num=self.td_max_len, # max sample num n_samples_per_prompt=self.n_samples_per_prompt, metrics=self.metrics, max_age=self.partial_rollout_max_split, GBS_train=self.global_batch_size, # GBS_train addition_columns=self.dataset_additional_keys ) if is_multimodal(): self.mm_transfer_dock = MMGRPOTransferDock.remote(self.global_batch_size, self.n_samples_per_prompt) #将self.transfer_dock传给各个worker self.actor_worker.sync_init_transfer_dock(self.transfer_dock, self.mm_transfer_dock) self.ref_worker.sync_init_transfer_dock(self.transfer_dock, self.mm_transfer_dock) for reward in self.reward_list: if hasattr(reward, 'sync_init_transfer_dock'): reward.sync_init_transfer_dock(self.transfer_dock, self.mm_transfer_dock) else: reward.init_transfer_dock.remote(self.transfer_dock, self.mm_transfer_dock) |
actor_worker、ref_worker是RayActorGroup类型,reward为RayActorGroup或者RuleReward。
- RayActorGroup实现了sync_init_transfer_dock,而RuleReward都实现了init_transfer_dock
- RayActorGroup.sync_init_transfer_dock则调用每个actor(worker)的init_transfer_dock初始化具体actor_worker
|
#mindspeed_rl.workers.rule_reward.RuleReward.init_transfer_dock def init_transfer_dock(self, td, mm_td=None, sampling_transfer_dock=None): self.td = td self.mm_td = mm_td self.sampling_transfer_dock = sampling_transfer_dock |
|
#mindspeed_rl.workers.scheduler.launcher.RayActorGroup.sync_init_transfer_dock def sync_init_transfer_dock(self, transfer_dock, mm_transfer_dock=None, sampling_transfer_dock=None): for actor in self.actor_handlers: ray.get(actor.init_transfer_dock.remote(transfer_dock, mm_transfer_dock, sampling_transfer_dock)) #mindspeed_rl.workers.actor_hybrid_worker.ActorHybridWorkerBase.init_transfer_dock #IntegratedWorker继承了ActorHybridWorkerBase的init_transfer_dock方法 def init_transfer_dock(self, td, mm_td, sampling_transfer_dock=None): self.td = td self.mm_td = mm_td self.sampling_transfer_dock = sampling_transfer_dock self.empty_cache() |
worker读写数据
使用方法一: 分布式计算
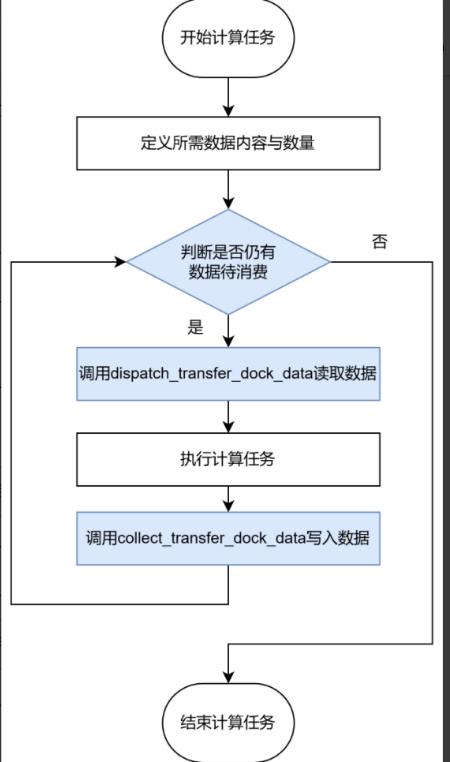
在Worker的计算任务中:
- 首先需指定所需要读写的列名与每次读取的数据量
- 如果使能了rl_config.guarantee_order参数,会调用get_dp_range_indexes获取当前dp对应的数据indexes。
- 之后每个循环,都将依照self.all_consumed()状态确定是否要继续读取数据
- 若本GBS仍有数据未处理完,则调用dispatch_transfer_dock_data()函数从数据系统中读取数据
- 在完成计算任务后通过collect_transfer_dock_data()函数将对应结果写回数据系统。
|
#mindspeed_rl.workers.reference_woker.ReferenceWorkerBase.compute_ref_log_prob def compute_ref_log_prob(self): experience_consumer_stage = 'ref_log_prob' experience_columns = ['input_ids', 'responses', 'response_length', 'prompt_length'] ...... experience_count = self.rl_config.ref_dispatch_size ...... while self.all_consumed(experience_consumer_stage, sorted_indexes) > 0: batch_data, index = self.dispatch_transfer_dock_data(experience_consumer_stage, experience_columns, experience_count, tp_size=self.megatron_config.tensor_model_parallel_size, cp_size=self.megatron_config.context_parallel_size, cp_algo=self.megatron_config.context_parallel_algo, indexes=sorted_indexes.pop(0) if self.rl_config.guarantee_order else None, get_n_samples=self.rl_config.partial_rollout_max_split > 1)
if batch_data and index: output, batch = self.reference.compute_log_prob(batch_data) if self.parallel_state.is_pipeline_last_stage(ignore_virtual=True): # only on last rank. It should be on every tp rank log_probs = torch.cat(output, dim=0) # (bs, seq_size) log_probs = log_probs.to(torch.float32) log_probs = truncate_rows(log_probs, batch['response_length']) output = {'ref_log_prob': log_probs} self.collect_transfer_dock_data(output, index) |
使用方法二:非分布式计算
直接调用GRPOTransferDock中的方法,里面主要调用逻辑:
- cur_td.all_consumed
- cur_td.get_experience
- 紧接着要调用remove_padding_tensor_dict_to_dict
- 调用pad_experience,将数据转换成适合模型输入的格式
- 做分数计算:compute_verifier_score
- 调用cur_td.put_experience
- 在这之前要调用padding_dict_to_tensor_dict
|
#mindspeed_rl.workers.rule_reward.RuleReward.compute_rm_score def compute_rm_score(self): experience_consumer_stage = 'rule_reward' experience_columns = ['prompts', 'responses', 'response_length', *self.megatron_config.dataset_additional_keys] experience_count = self.rl_config.reward_dispatch_size assign_batch_size = self.megatron_config.global_batch_size * self.rl_config.n_samples_per_prompt sorted_indexes = get_current_dp_range_indexes(experience_count=experience_count, assign_batch_size=assign_batch_size) if self.rl_config.guarantee_order else None pad_token_id = self.tokenizer.pad if self.tokenizer.pad else self.tokenizer.eod cur_td = self.sampling_transfer_dock if self.sampling_transfer_dock else self.td while not ray.get(cur_td.all_consumed.remote(experience_consumer_stage)): batch_data, index = ray.get( cur_td.get_experience.remote( experience_consumer_stage, experience_columns, experience_count, indexes=sorted_indexes.pop(0) if self.rl_config.guarantee_order else None, get_n_samples=True ) ) # cpu数据 batch_data = remove_padding_tensor_dict_to_dict(batch_data) if batch_data and index: batch_data = pad_experience(batch_data, pad_token_id) # multiple, tp_size if not is_multimodal(): ...... rm_scores, metrics = compute_verifier_score( batch_data, self.megatron_config, self.rl_config, self.hf_tokenizer, ignore_token ) output = {"rm_scores": rm_scores} output = padding_dict_to_tensor_dict(output) cur_td.put_experience.remote(data_dict=output, indexes=index) |

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)