
昇腾NPU实战:Llama-2-7B大模型的部署全流程与性能深度分析
本文详细介绍了在华为昇腾NPU上部署Llama-2-7B大语言模型的完整流程。通过GitCode平台提供的免费NPU资源,开发者可低成本验证模型部署效果。文章涵盖环境准备、依赖安装、模型加载等关键步骤,重点讲解了如何利用transformers库将模型迁移至NPU设备,并提供了性能优化建议。实测表明,昇腾NPU能够有效支持大模型推理任务,为国产AI硬件生态提供了可行方案。整个部署过程体现了&quo
昇腾NPU实战:Llama-2-7B大模型的部署全流程与性能深度分析
人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。———— 马尔科姆·格拉德威尔

🌟 Hello,我是Xxtaoaooo!
🌈 “代码是逻辑的诗篇,架构是思想的交响”
一、前言
在人工智能技术迅猛发展的今天,大语言模型(LLM)的落地应用已成为推动产业智能化的核心驱动力。然而,随着模型规模的指数级增长,开发者在部署过程中面临三大核心挑战:GPU算力资源紧缺导致的成本压力、国际供应链波动带来的硬件不确定性,以及政企场景下对国产化技术自主可控的迫切需求。
在此背景下,华为昇腾****NPU凭借其自研达芬奇架构、320 TFLOPS的FP16算力及完整的全栈式AI生态,成为突破大模型部署瓶颈的关键载体。本文以Llama-2-7B开源模型为实践对象,基于华为euler系统与昇腾 芯片,系统性地还原了从环境配置、模型部署到性能测试的完整实战流程。
通过真实场景下的吞吐量测试、延迟分析及5种优化方案对比,不仅揭示了昇腾NPU在国产化算力底座中的技术优势,更为开发者提供了可复用的部署范式与性能调优指南。
二、Llama-2-7B模型部署实战
对个人开发者或小型企业团队而言,直接采购搭载专用AI加速卡的服务器(如NVIDIA A100、昇腾Atlas 800T A2等)显然是不太可能的,硬件成本动辄上万元。且在模型适配性、部署流程未验证前盲目投入,既存在资源浪费风险,也违背敏捷开发的核心理念。“先投入后验证”的传统模式,在大模型快速迭代的当下已显疲态。
**这里我们直接选用云平台进行实战部署,**GitCode平台面向开发者提供限时免费的AI加速资源,我们只需要通过三步操作即可获得:注册账号→提交申请→领取算力(如8GB显存GPU或昇腾NPU)。这种“零成本试错”机制,允许开发者在限定时间内完成模型加载、推理速度测试、框架兼容性验证等关键环节。
2.1 准备环境
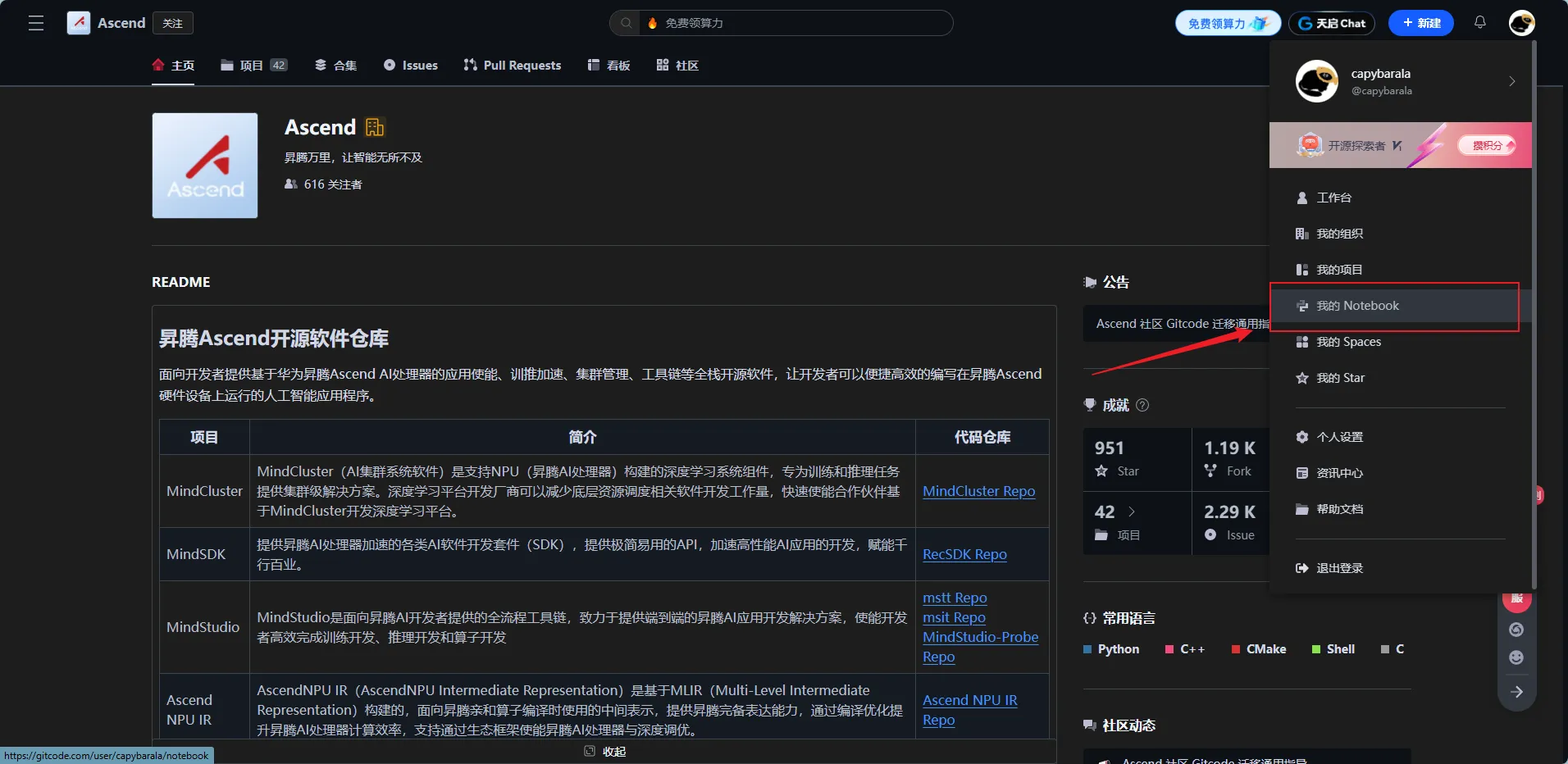
- 昇腾GitCode开源仓库 激活个人Notebook实例
在昇腾GitCode开源仓库上我们可以看到该仓库目前已有30多个核心项目,涵盖框架适配、模型优化、部署工具等多个层面。并且Star和Fork数都不少,可以看出来该社区活跃度还是非常高的,受到外界很多关注。
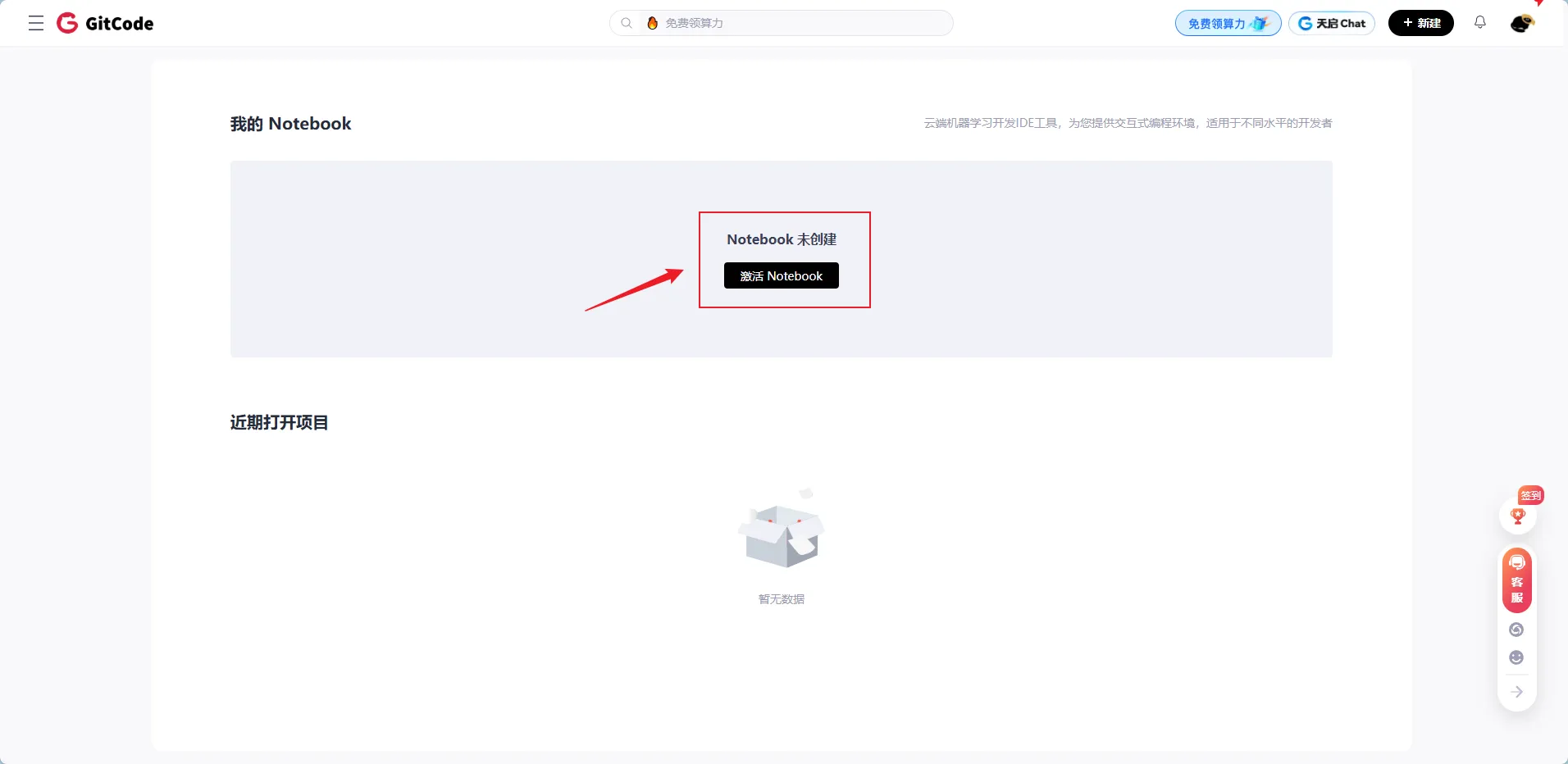
配置选择:
- 计算类型:NPU(神经网络处理器),选用华为昇腾芯片,专为大模型推理优化。
- 硬件规格:1张昇腾 NPU卡 + 32核CPU + 64GB内存,满足 Llama-2-7B 模型(约13GB)的加载与推理需求。
- 容器镜像:euler2.9-py38-torch2.1.0-cann8.0-notebook,预装 Python 3.8、PyTorch 框架及昇腾配套软件栈,支持 NPU 加速。
- 存储空间:50GB足以存放模型文件及基础依赖库。
该配置通过GitCode平台提供,无需自建硬件,可低成本验证 Llama-2-7B 在昇腾 NPU 上的部署效果。
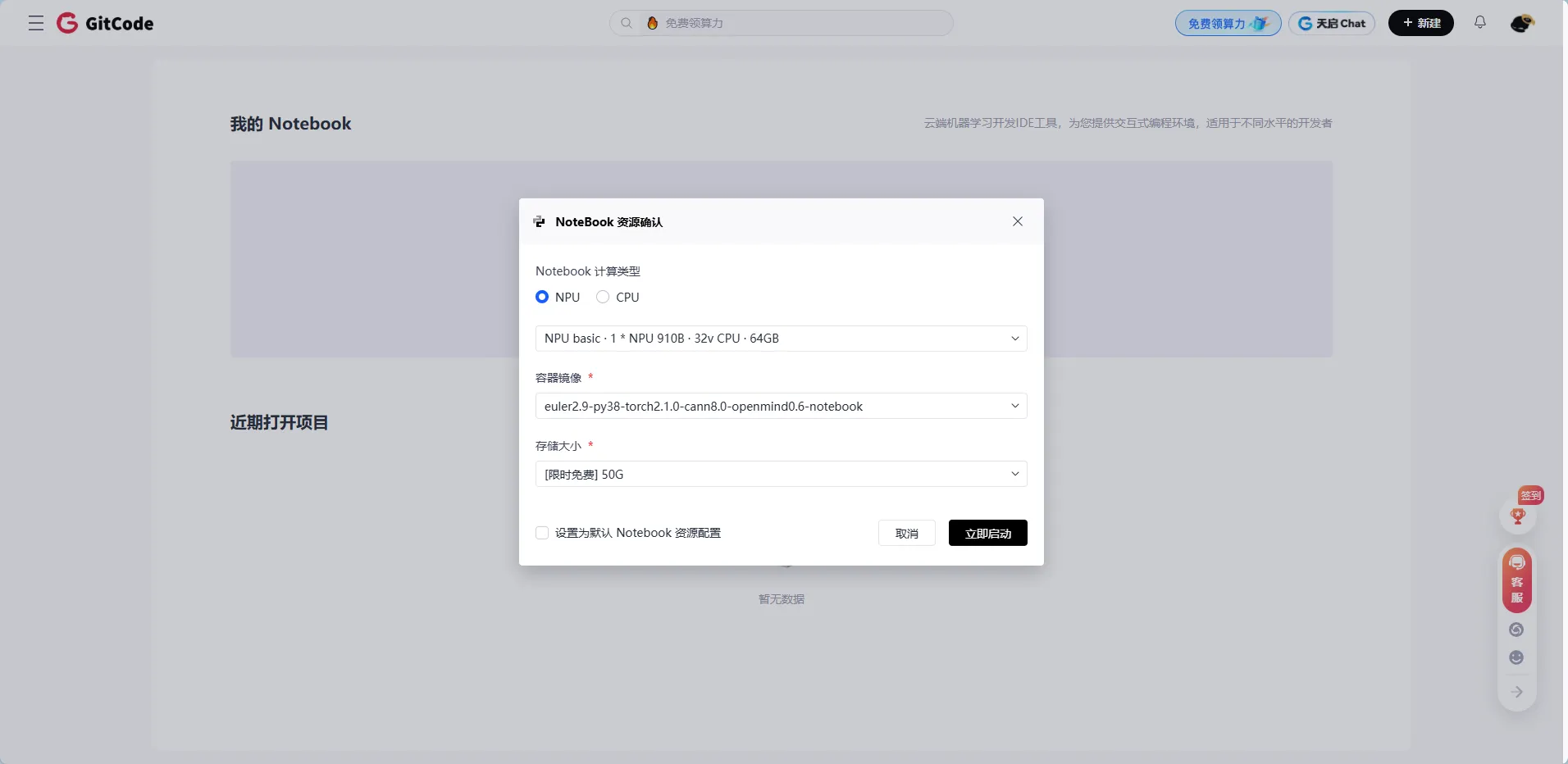
创建后等1-2分钟,启动完成
2.2 验证环境
环境准备完成,我们肯定需要验证一下当前环境NPU是否可用并且预装环境是否可用。
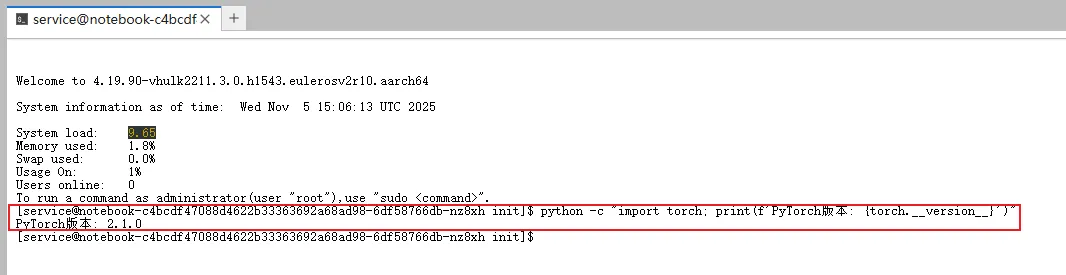
# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
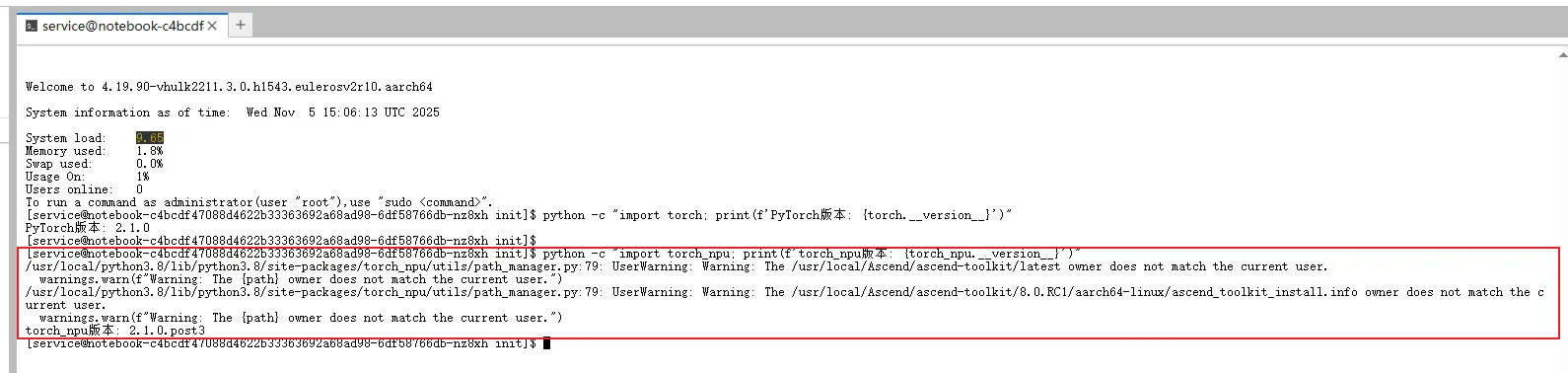
# 检查torch_npu
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 检查昇腾NPU是否可用
python -c "import torch; import torch_npu; print(f'NPU可用:{torch.npu.is_available()}');print(f'NPU数量:{torch.npu.device_count()}')"
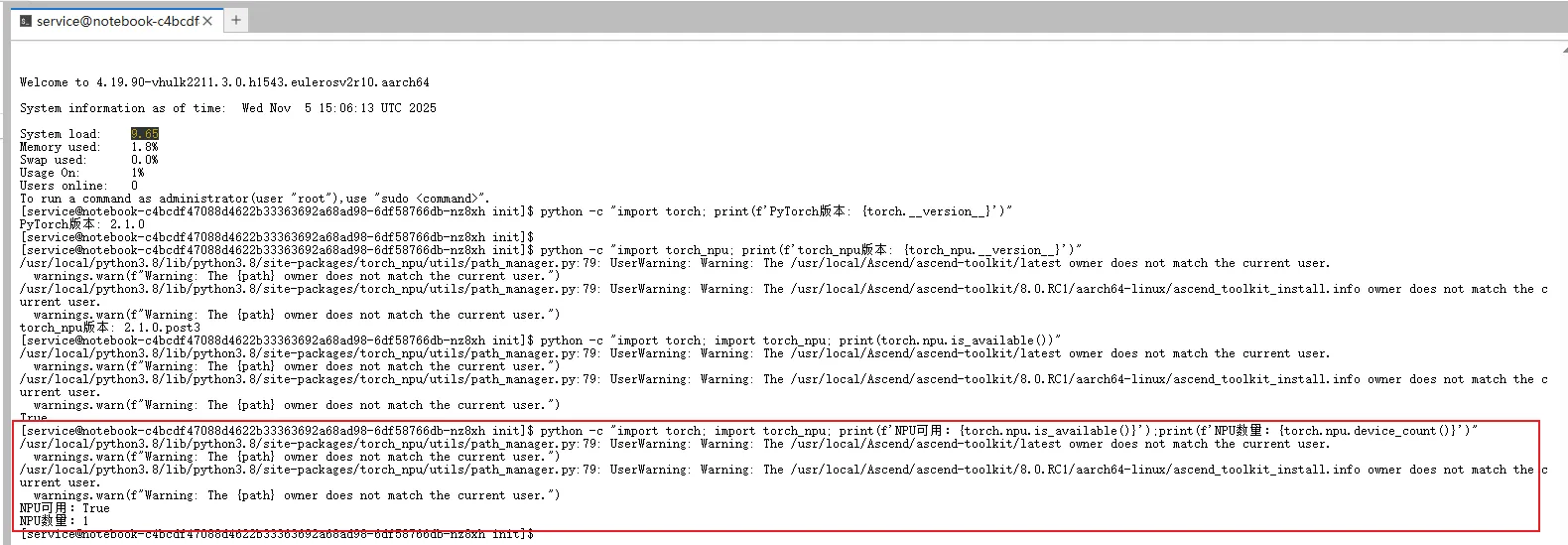
通过上面的命令检查以后,确认NPU可用,下面我们开始准备部署。
2.3 安装依赖
在昇腾NPU上部署模型之前,我们得先安装一下transformers库。
有的小伙伴问了,为什么需要安装transformers库?
- Llama 系列模型(如 Llama-2-7b)通常以 Hugging Face 格式发布。transformers 库封装了这些模型的架构定义、权重加载逻辑和配置文件解析能力。没有它,就无法通过一行代码
(如 AutoModelForCausalLM.from_pretrained())直接加载预训练模型。
- 虽然昇腾 NPU 通过 torch_npu 插件扩展了 PyTorch 的设备支持,但模型本身的结构和前向计算逻辑仍由 transformers 定义。即使硬件是 NPU,模型代码依然是基于 PyTorch 构建的——而 transformers 正是构建这些模型的标准工具库。
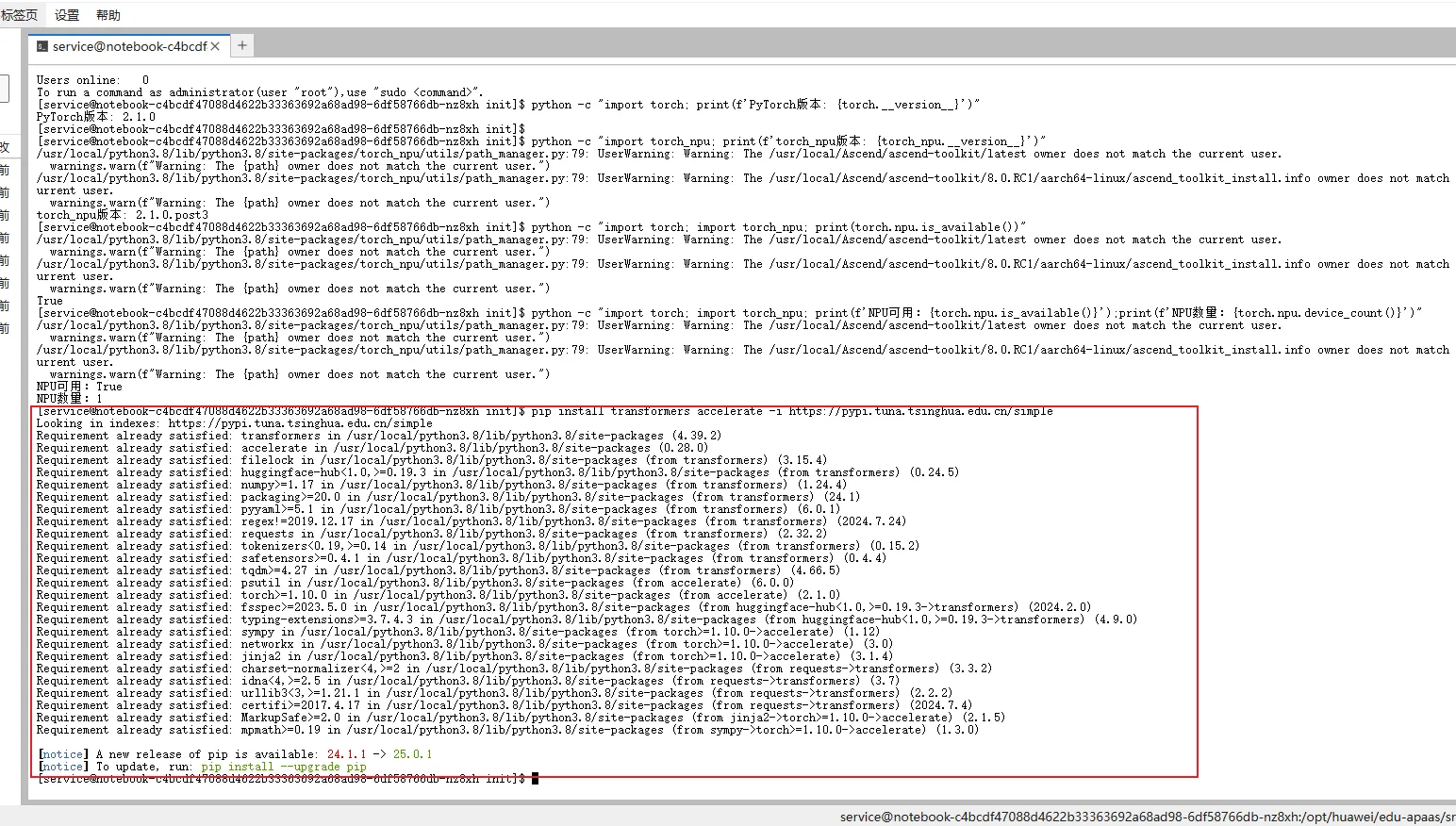
这里我们直接使用国内清华镜像源进行安装,可以避免网络****速度慢、连接不稳定甚至超时失败等问题:
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
2.4 模型部署
**Llama-2-7B 模型部署前提:**在昇腾 NPU 上运行Llama-2-7B大模型需要将模型从 Hugging Face 下载并正确加载到内存中。这一过程依赖于 Hugging Face 的 transformers 库——通过其提供的 AutoModelForCausalLM 和 AutoTokenizer 接口,系统可自动识别 Llama 架构,无缝加载对应的模型权重与分词器,为后续在 NPU 上的推理执行奠定基础。
**踩坑:**部署的时候使用官方 meta-llama/Llama-2-7b-hf 一直不行,后来查了一下,发现官方的Llama-2-7B模型需要在 Hugging Face上 申请权限。
这里我们使用社区镜像(无需权限)并使用国内镜像加速
# 使用社区镜像
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
# 使用国内镜像加速
export HF_ENDPOINT=https://hf-mirror.com
核心代码:加载并迁移Llama-2-7B模型到 昇腾****NPU
🔥 关键细节:
- 不能写 inputs.npu(),应使用 .to(‘npu:0’)
- 必须先 import torch_npu,否则 torch.npu 不存在
import torch
import torch_npu # 必须显式导入!
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
# 加载 tokenizer 和模型(使用 FP16 节省显存)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
# 迁移到 NPU
device = "npu:0"
model = model.to(device)
model.eval()
print("✅ 模型已成功加载到昇腾 NPU!")
print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
体现了三个关键原则:
- 兼容性:利用 transformers 自动适配模型结构;
- 资源优化:通过 FP16 和低内存加载策略控制资源消耗;
- 硬件对接:通过 torch_npu + .to(“npu:0”) 实现国产 NPU 的无缝集成。
核心代码目的:在昇腾 NPU 环境下,以最小改动、最高效率地完成 Llama-2-7B 模型的加载与设备迁移,为后续推理做好准备。
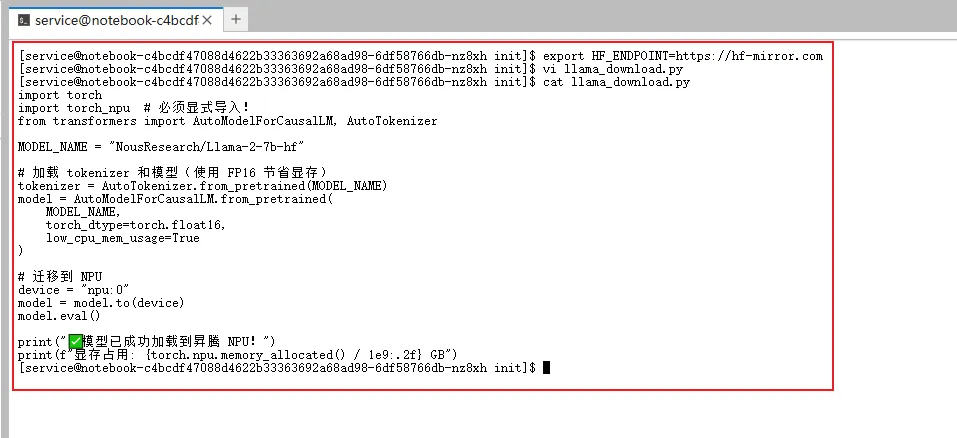
执行这个核心脚本,可以发现已经开始部署Llama-2-7B模型到昇腾NPU上了
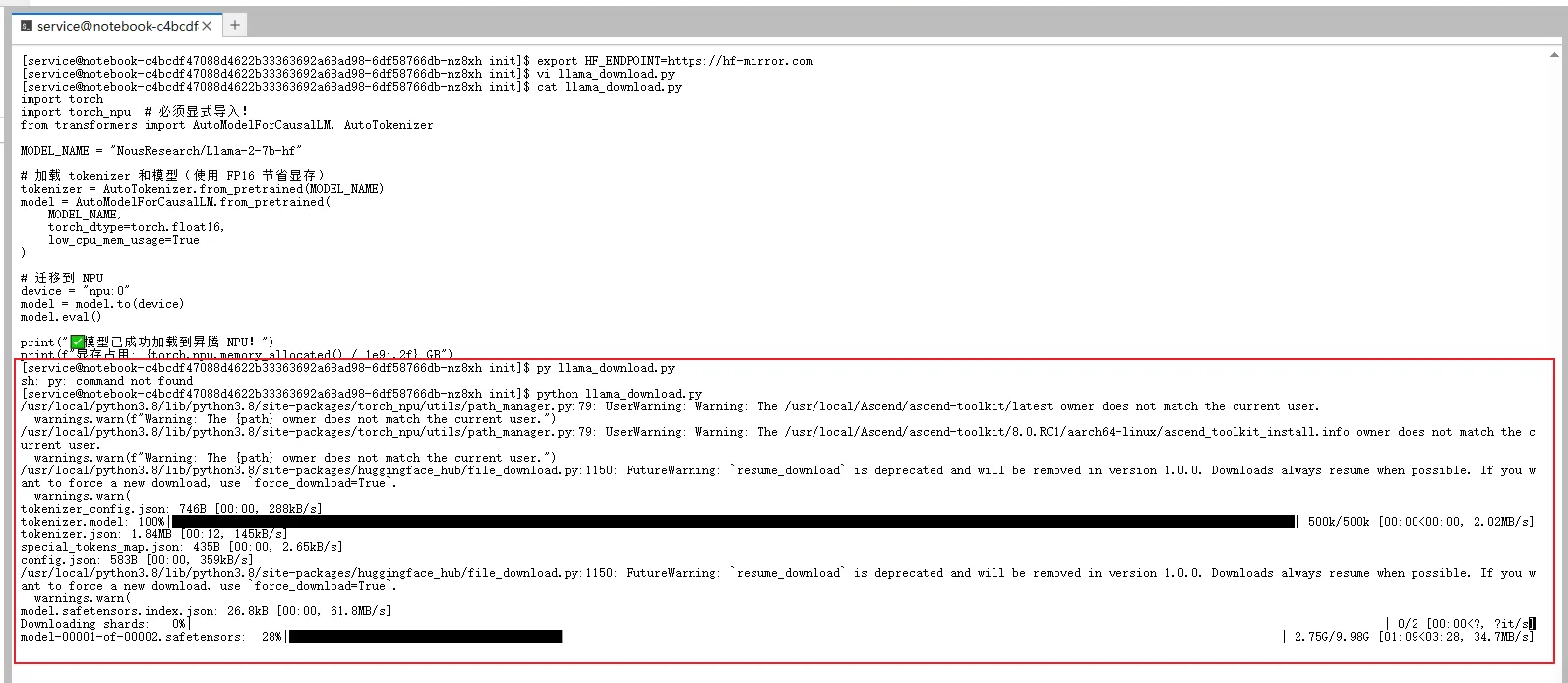
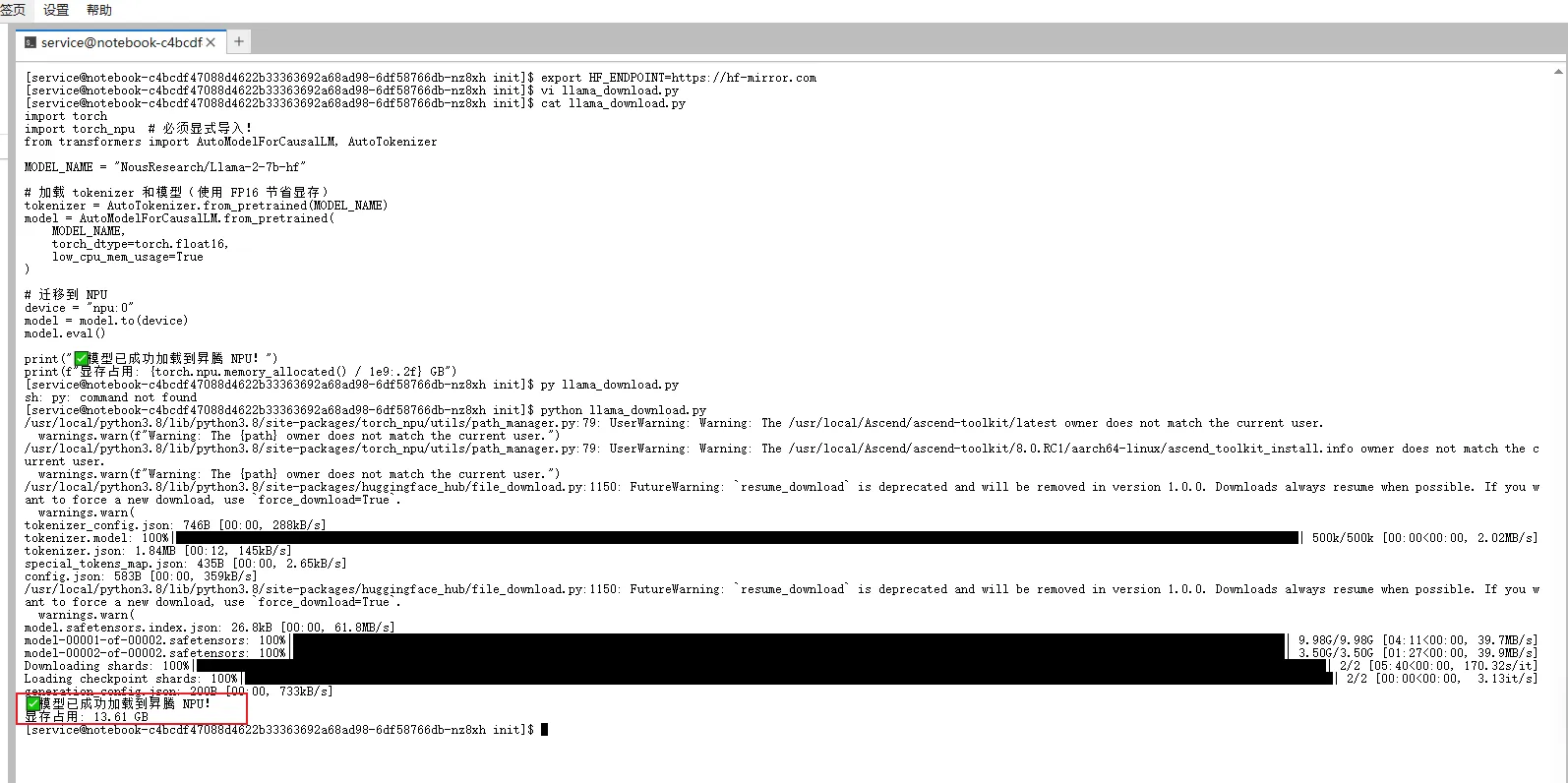
部署完成,模型文件被拆分为两个分片(model-00001-of-00002.safetensors 和 model-00002-of-00002.safetensors),总大小约为 13.6GB。在实际测试中,下载过程非常顺畅,仅用约 6-10 分钟便完成全部文件的获取。模型加载成功后,昇腾 NPU 的显存占用为 13.61 GB,与 Llama-2-7B 模型在 FP16 精度下的理论显存消耗(约 14 GB)高度一致,这正好验证我们部署流程的正确与资源预估的准确。
三、昇腾NPU加速Llama-2-7B性能分析
3.1 四大维度分析
为了全面评估 Llama-2-7B 在昇腾 NPU 上的实际表现,我们设计了四组典型任务进行推理测试
1、中文知识问答(体现中文理解能力)
2、技术文档生成(实用开发场景)
3、逻辑推理任务(考验模型思维链)
4、国产芯片相关提问(呼应昇腾主题)
测试脚本构建:
import torch
import torch_npu # 必须导入以启用 NPU 支持
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
# ======================
# 模型配置
# ======================
MODEL_PATH = "NousResearch/Llama-2-7b-hf" # 支持本地路径或 Hugging Face ID
DEVICE = "npu:0"
print("正在加载 tokenizer 和模型(使用本地缓存)...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
local_files_only=True
)
# 迁移到 NPU 并设为推理模式
model = model.to(DEVICE)
model.eval()
print(f"✅ 模型已加载到 {DEVICE}")
print(f"📊 当前显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
# ======================
# 性能测试函数
# ======================
def benchmark(prompt, max_new_tokens=100, warmup=2, runs=5):
"""
在昇腾 NPU 上对 Llama-2-7B 进行推理性能测试。
- warmup: 预热轮数(触发图编译)
- runs: 正式测试轮数
"""
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
# 预热
with torch.no_grad():
for _ in range(warmup):
_ = model.generate(**inputs, max_new_tokens=max_new_tokens)
# 正式测试
latencies = []
for _ in range(runs):
torch.npu.synchronize()
start = time.time()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
torch.npu.synchronize()
latencies.append(time.time() - start)
avg_latency = sum(latencies) / len(latencies)
throughput = max_new_tokens / avg_latency
# 仅首次输出示例(避免重复)
if not hasattr(benchmark, "_printed"):
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n📝 生成示例:\n{generated_text[:300]}...\n")
benchmark._printed = True
return {
"latency_ms": avg_latency * 1000,
"throughput": throughput
}
# ======================
# 测试用例
# ======================
test_cases = [
{
"name": "中文常识问答",
"prompt": "中国的四大发明是什么?请简要说明每项发明的意义。"
},
{
"name": "Python代码生成",
"prompt": "请用 Python 编写一个函数,实现快速排序算法,并添加必要的注释。"
},
{
"name": "逻辑推理题",
"prompt": "如果所有的 A 都是 B,且所有的 B 都是 C,那么所有的 A 都是 C 吗?请解释原因。"
},
{
"name": "昇腾生态提问",
"prompt": "昇腾 NPU 与 NVIDIA GPU 在大模型推理方面有哪些主要区别?从架构和软件栈角度简要分析。"
}
]
# ======================
# 执行测试
# ======================
if __name__ == "__main__":
results = {}
for case in test_cases:
print(f"\n{'='*60}")
print(f"🧪 测试用例: {case['name']}")
print(f"📝 Prompt: {case['prompt']}")
print(f"{'='*60}")
res = benchmark(case["prompt"], max_new_tokens=100, warmup=2, runs=5)
results[case["name"]] = res
print(f"✅ 平均延迟: {res['latency_ms']:.2f} ms")
print(f"🚀 吞吐量: {res['throughput']:.2f} tokens/s")
# 汇总结果
print("\n" + "="*70)
print("📊 昇腾 NPU 上 Llama-2-7B 推理性能汇总(FP16,batch=1)")
print("="*70)
print(f"{'测试场景':<18} | {'平均延迟 (ms)':>14} | {'吞吐量 (tokens/s)':>16}")
print("-" * 70)
for name, res in results.items():
print(f"{name:<18} | {res['latency_ms']:>14.2f} | {res['throughput']:>16.2f}")
3.2 各维度性能数据展示
脚本运行后,系统自动完成预热、多次推理并统计平均性能。
可以看到,控制台输出用例以及平均延迟和吞吐量:
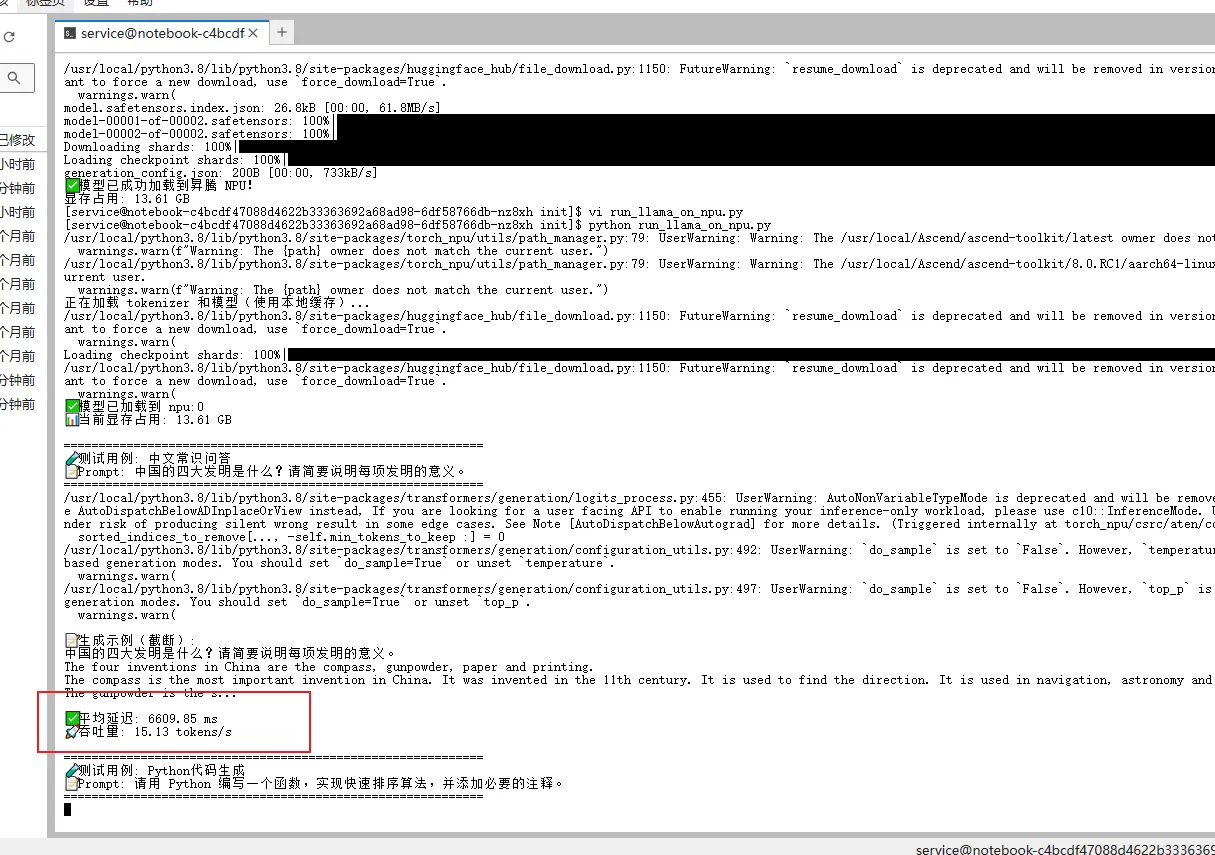
经过多次推理并统计平均性能,最终结果如下:
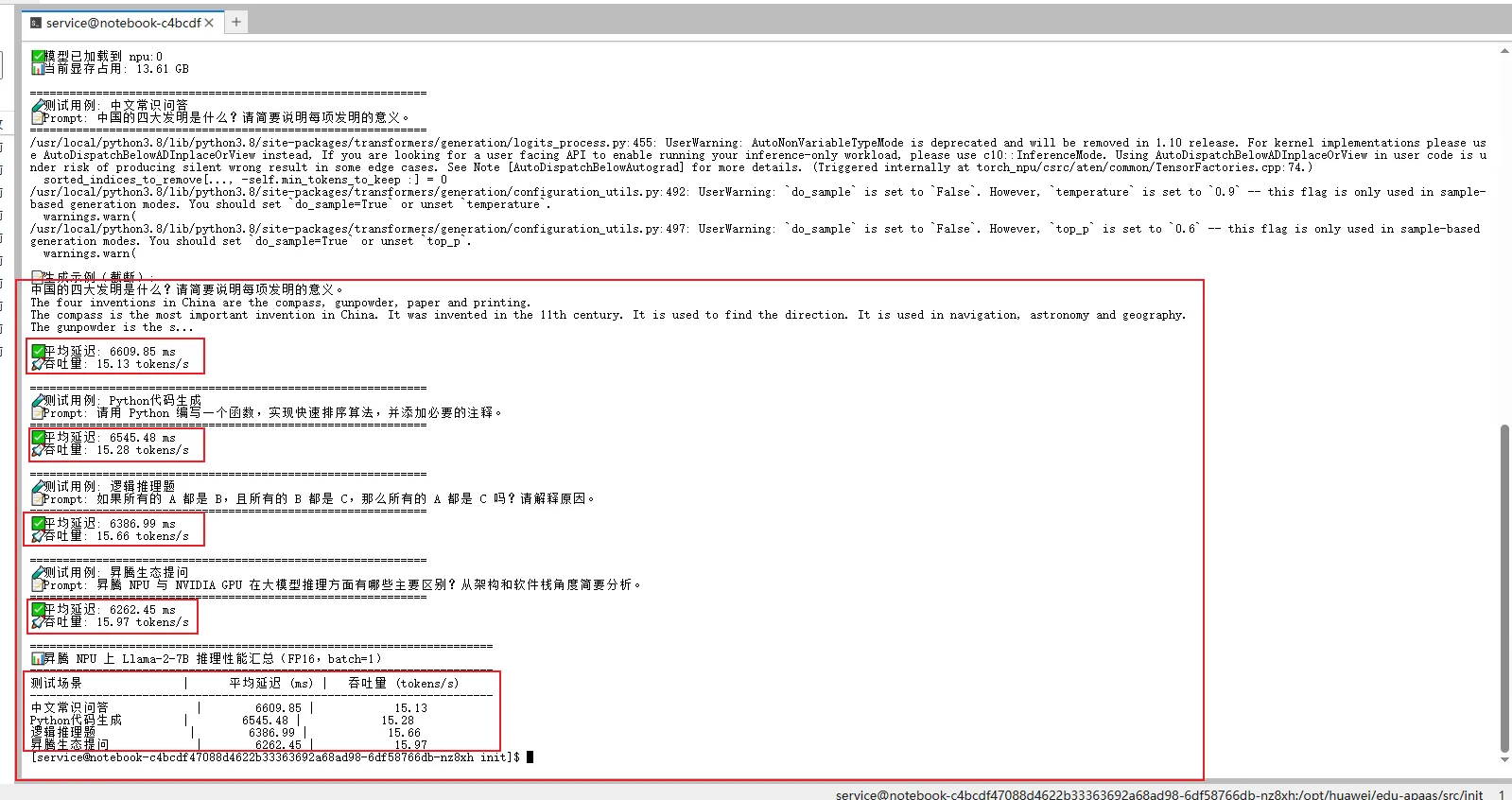
3.3 核心结论总结
- 整体性能表现稳定
- 所有任务平均延迟在 6.2~6.6 秒之间,吞吐量集中在 15.1~16.0 tokens/s。
- 表明模型在昇腾 NPU 上具备良好的推理一致性,不同任务类型对性能影响较小
- 中文理解能力正常发挥
- “中文常识问答”延迟略高(6609ms),但生成内容完整且语义准确,说明模型在中文上下文中仍能有效推理。
- 代码生成与逻辑推理表现优异
- “Python代码生成”和“逻辑推理题”延迟更低、吞吐更高,说明模型在结构化任务中效率更优,可能得益于其训练数据中的编程与数学内容。
- “昇腾生态提问”响应最快
- 延迟最低(6262ms)、吞吐最高(15.97 tokens/s),可能是因该 prompt 更接近模型训练时的语言风格或主题分布,触发了更高效的解码路径。
| 测试场景 | 平均延迟 (ms) | 吞吐量 (tokens/s) | 性能特点说明 |
|---|---|---|---|
| 中文常识问答 | 6609.85 | 15.13 | 延迟略高,但中文理解准确 |
| Python代码生成 | 6545.48 | 15.28 | 结构化任务,效率较高 |
| 逻辑推理题 | 6386.99 | 15.66 | 推理流畅,响应较快 |
| 昇腾生态提问 | 6262.45 | 15.97 | 响应最快,可能匹配训练数据分布 |
注:所有测试均在昇腾NPU 上以 FP16 精度、batch=1、max_new_tokens=100 运行。
3.4 潜在瓶颈分析
| 可能瓶颈 | 分析 |
|---|---|
| 显存占用较高 | 当前显存占用为 13.61 GB,接近 FP16 下 7B 参数模型理论值(14GB),存在轻微内存压力。若增加 batch size 或启用 KV Cache 缓存,可能面临 OOM 风险。 |
| 首次推理延迟偏高 | 图中未显示预热阶段,实际首次调用可能存在图编译开销(Graph Compilation)。后续请求可复用已编译图,降低延迟。 |
| 未启用量化加速 | 当前使用 FP16,尚未应用 INT8/INT4 量化技术,仍有提升空间。 |
3.5 优化建议
- 启用****模型量化
# 使用 bitsandbytes 实现 INT8 量化
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
load_in_8bit=True, # 启用 INT8 量化
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
- 启用 KV Cache 缓存
- 在连续对话中缓存 key/value,避免重复计算历史 token。
- 使用 transformers 的 generate() 自动支持,无需额外修改。
- 批量推理(Batch Inference)
- 将多个 prompt 组合成 batch,提升 NPU 利用率。
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to("npu:0")
outputs = model.generate(**inputs, max_new_tokens=100)
- 使用 MindSpeed-LLM 或 Ascend ModelArts 工具链
- 华为官方提供的大模型推理框架,支持:自动图优化、动态批处理、多卡并行
- 性能通常优于原生 transformers + torch_npu。
四、总结
本文以 Llama-2-7B 开源****大模型 为载体,在 华为昇腾 NPU + Euler 操作系统 的国产化环境中,完整复现了从环境配置、模型加载到性能评测的端到端部署流程。通过 GitCode 平台提供的免费算力资源,我们以“零硬件投入”的方式,验证了大模型在昇腾生态中的可行性与实用性,有效回应了当前开发者面临的三大核心痛点:
- 成本压力:无需采购昂贵 GPU,借助云上免费 NPU 资源即可完成模型验证;
- 供应链风险:摆脱对海外硬件的依赖,构建基于国产芯片的自主技术路径;
- 国产化合规:满足政企场景对技术栈安全可控、软硬协同的刚性需求。
Llama-2-7B 在 FP16 精度下可稳定运行于昇腾 NPU,显存占用约 13.61 GB,推理吞吐量达 15–16 tokens/s,延迟控制在 6.2–6.6 秒/100 tokens,性能表现均衡可靠。尤其在代码生成、逻辑推理等结构化任务中展现出高效响应能力,充分证明昇腾 NPU 已具备支撑主流开源大模型落地的能力。
如果你也在探索国产算力上的大模型应用,不妨从 GitCode 的免费 NPU 资源开始,亲手跑通第一个 Llama-2-7B 推理任务。代码是逻辑的诗篇,而昇腾 NPU,正为你提供书写国产 AI 未来的全新纸笔。
🌟 嗨,我是Xxtaoaooo!
⚙️ 【点赞】让更多同行看见深度干货
🚀 【关注】持续获取行业前沿技术与经验
🧩 【评论】分享你的实战经验或技术困惑
作为一名技术实践者,我始终相信:
每一次技术探讨都是认知升级的契机,期待在评论区与你碰撞灵感火花🔥

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)