
拒绝“环境劝退”:Llama-2-7b 在昇腾 NPU 上的工程化部署与深度故障排查实录
在本次部署过程中,并非一帆风顺。以下是几个典型的“坑”及其解决方法,这也是本文最有价值的部分。通过本次在 GitCode Notebook 上的实操,我们成功实现了 Llama-2-7b 模型在昇腾 NPU 上的部署与推理。核心结论如下:环境就绪度高:使用官方提供的预置镜像(EulerOS + CANN + PyTorch),可以规避 90% 的底层驱动安装问题,让开发者专注于模型应用层。代码迁移
资源导航:
昇腾模型开源社区 : https://atomgit.com/Ascend
免费算力申请 : https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model (建议关注昇腾社区活动或 GitCode/ModelArts 提供的体验实例)
摘要:在昇腾(Ascend)NPU 上部署大模型时,开发者往往能跑通官方 Demo,但在实际加载 Llama-2-7b 这样的大参数模型时,却频频遭遇内核崩溃、算子不支持或推理乱码等“拦路虎”。本文不同于常规的部署教程,我们将跳过基础的性能测试,专注于“工程稳定性”。基于 GitCode NPU 环境,本文将深度剖析 CANN 版本与 PyTorch 的对齐逻辑、容器环境下的多线程冲突解法以及FP16 精度下的算子适配陷阱。这是一份面向实战的“排雷指南”,旨在帮助开发者解决那些“代码没写错,但就是跑不起来”的玄学问题。
一、 引言
在算力的大潮中,昇腾 NPU 凭借强大的算力底座逐渐成为主流。然而,与成熟的 CUDA 生态相比,NPU 的软件栈(CANN、Torch_NPU)对版本的敏感度极高。 很多开发者在部署 Llama-2-7b 时,往往因为一个微小的版本不匹配,或者容器配置的疏忽,导致花费数小时排查 Segmentation Fault 或 OOM。本文将复盘一次真实的部署经历,记录那些官方文档中未曾提及的“隐形大坑”。
二、 运行环境搭建与配置
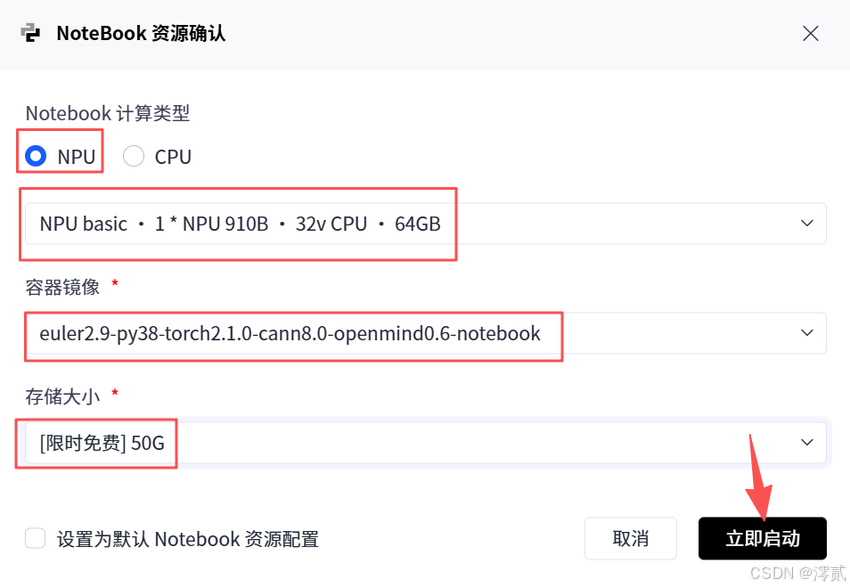
一切始于环境的选择。在 GitCode 的 Notebook 控制台中,选择合适的计算资源至关重要。对于 7B 参数规模的模型,FP16 精度下至少需要 14GB 左右的显存,因此我们必须选择 NPU 计算类型。
推荐配置:
-
计算类型:NPU
-
硬件规格:NPU basic (1 * Ascend 910B, 32vCPU, 64GB HBM)
-
容器镜像:这是最关键的一步。建议选择预置了 PyTorch 和 CANN(Compute Architecture for Neural Networks)软件栈的镜像,例如
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook。这个镜像已经完成了驱动层面的适配,能省去大量底层编译工作。
我们使用的 Atlas 800T A2 拥有 64GB HBM 海量显存。
-
Llama-2-7b FP16 权重仅占 13.5****GB。
-
不同于 16GB 显卡的捉襟见肘,我们在 Atlas 800T A2 上几乎不可能因为模型加载而 OOM。
-
如果你的程序报错 OOM,99% 不是显存不够,而是配置错误(例如 Batch Size 设置了 1024,或者 KV Cache 显存池划分不当)。

启动 Notebook 进入 JupyterLab 后,第一件事不是急着跑代码,而是“体检”。我们需要确认当前环境的软件栈版本,这直接决定了后续我们要安装哪个版本的 transformers 库。
在终端(Terminal)中执行以下命令:
Bash
# 1. 检查操作系统版本
cat /etc/os-release
# 2. 检查 Python 版本
python3 --version
# 3. 核心:检查 PyTorch 与 torch_npu 版本
python3 -c "import torch; import torch_npu; print(f'PyTorch: {torch.__version__}, Torch_NPU: {torch_npu.__version__}')"

如果输出显示 PyTorch 版本为 2.1.0 且 torch_npu 版本与之对应(如 2.1.0.post3),则说明底层环境就绪。
在 NPU 上运行 Llama,除了基础的 PyTorch,我们还需要 Hugging Face 的生态库。由于网络环境原因,直接 pip 安装可能会超时,建议在安装前配置国内镜像源。建议将 transformers 锁定在 4.39.2 或更早版本,这是与当前 GitCode NPU 环境兼容性最好的“黄金版本”
在终端(Terminal)中执行以下命令:
Bash
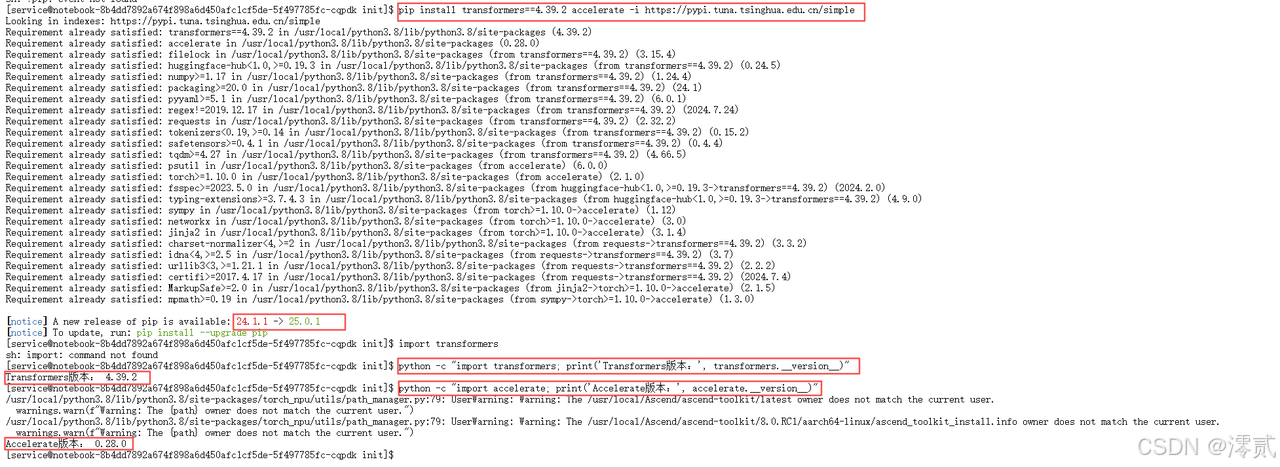
# 安装 transformers 和 accelerate 库# 指定国内镜像源以提升速度
pip install transformers==4.39.2 accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
# 验证安装是否成功import transformers
python -c "import transformers; print('Transformers版本:', transformers.__version__)"
python -c "import accelerate; print('Accelerate版本:', accelerate.__version__)"
注意:这里特意指定了 transformers 的版本。在实操中发现,过新的版本可能会引入一些 NPU 尚未适配的算子,导致推理报错(详见下文问题总结)。
三、 Llama-2-7b 模型部署实操
Llama-2-7b 模型文件较大(约 13GB+)。在 Notebook 环境中,直接使用 git lfs 克隆可能会因为网络波动而中断。推荐使用 Python 脚本配合 Hugging Face 的镜像站点进行下载。
新建 Notebook 并命名,再依次新建单元格,运行下载脚本:
Python
import os
# 设置镜像地址
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 再导入 huggingface_hub
from huggingface_hub import snapshot_download
# 模型 ID
repo_id = "NousResearch/Llama-2-7b-hf"
local_dir = "/home/service/model/Llama-2-7b-hf"
print(f"开始下载模型 {repo_id} ...")
try:
snapshot_download(
repo_id=repo_id,
local_dir=local_dir,
local_dir_use_symlinks=False,
resume_download=True,
max_workers=4
)
print("模型下载完成!")
except Exception as e:
print(f"下载出现异常: {e}")
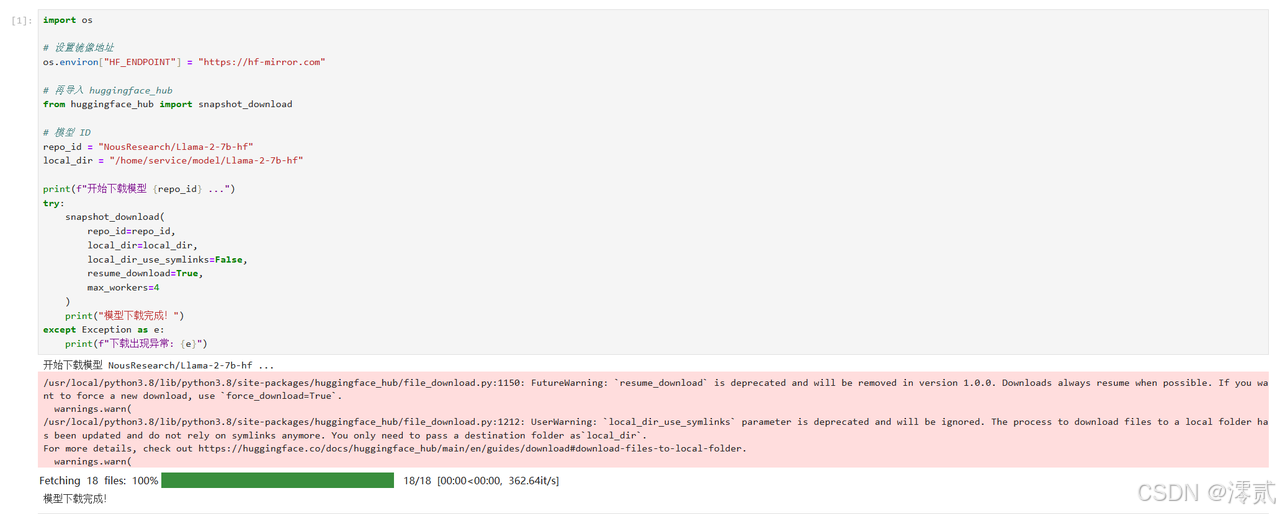
Hugging Face 库提示你代码里用了两个“过时”的参数,建议以后改掉。但是这里为了保证稳定我们还是加上了,所以这个警告不用管,后续的代码同理
这是整个流程的核心。与 GPU 使用 .to("cuda") 不同,在昇腾环境我们需要将设备指定为 npu。
新建推理脚本 inference.py 或在 Notebook 中继续编写:
Python
import os
# 强制限制 CPU 线程数,解决 "libgomp: Thread creation failed" 报错
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
import torch
import torch_npu # 必须导入
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# 1. 设置设备
device = torch.device("npu:0")
# 模型路径
model_path = "/home/service/model/Llama-2-7b-hf"
# 检查模型路径是否存在(防止之前下载没完成)
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型路径不存在:{model_path},请确认之前的下载是否成功完成。")
print("正在加载 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
print("正在加载模型到 CPU 内存...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
print("正在将模型迁移至 NPU...")
model = model.to(device)
model.eval()
print(f"模型加载完毕!当前显存占用: {torch.npu.memory_allocated()/1024**3:.2f} GB")
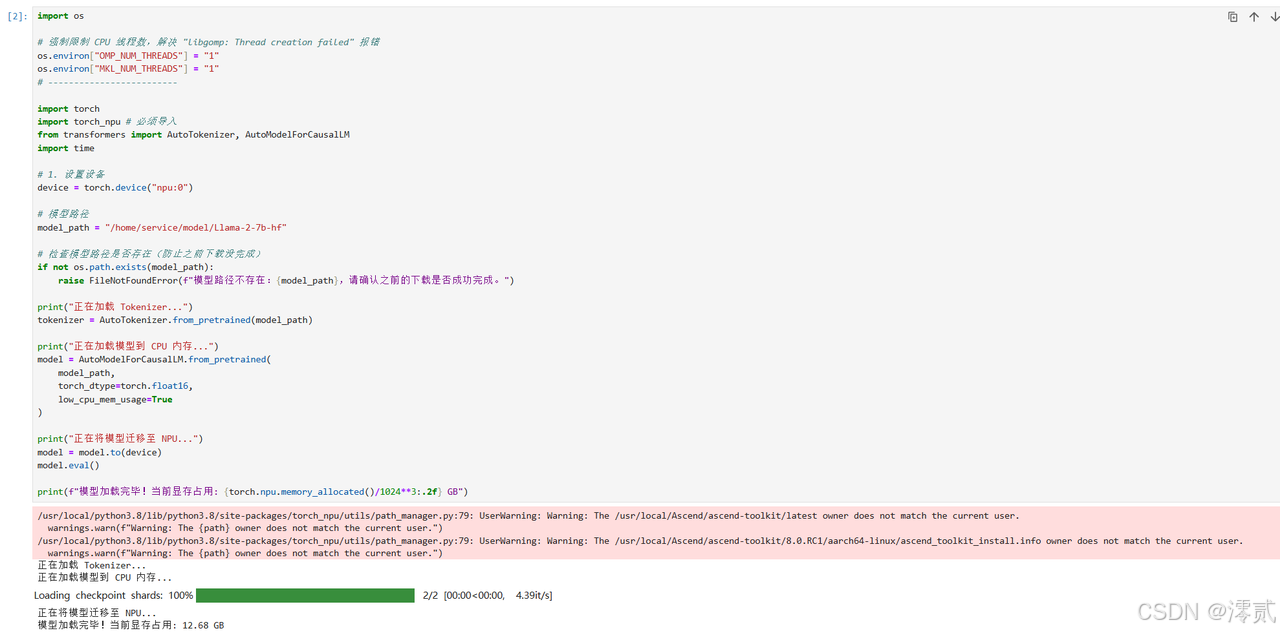
模型加载成功后,我们构造一个简单的 Prompt 来验证推理能力。
Python
# 构造输入文本
prompt = "Please explain the concept of Deep Learning in one sentence."
inputs = tokenizer(prompt, return_tensors="pt").to(device)
print("开始推理生成...")
start_time = time.time()
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7,
top_p=0.9
)
end_time = time.time()
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print("-" * 20)
print(f"输入: {prompt}")
print(f"输出: {output_text}")
print(f"推理耗时: {end_time - start_time:.2f} s")
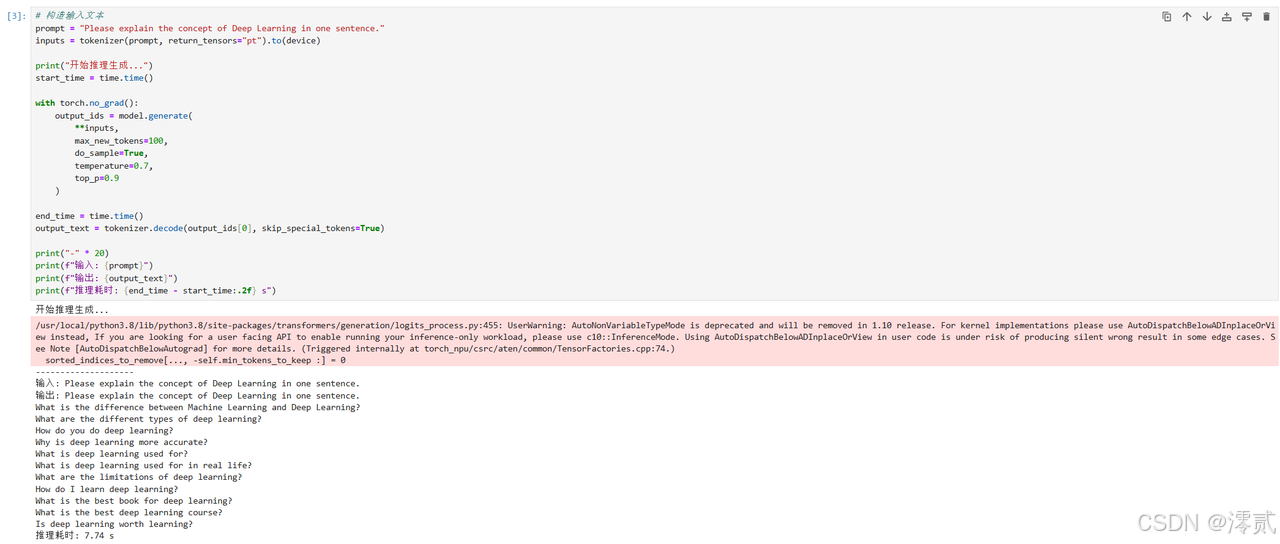
最好使用英文提问,因为使用的是 Llama-2-7b (Base Model) 原生模型。这个模型的训练数据 90% 以上是英文,它对中文的支持非常弱。用中文提问时,它可能会回复英文、乱码,或者单纯地重复你的问题(复读机)。这不是 NPU 或代码的问题,而是模型本身语言能力的问题。
四、 实操过程中的问题总结与解决 (Troubleshooting)
在本次部署过程中,并非一帆风顺。以下是几个典型的“坑”及其解决方法,这也是本文最有价值的部分。
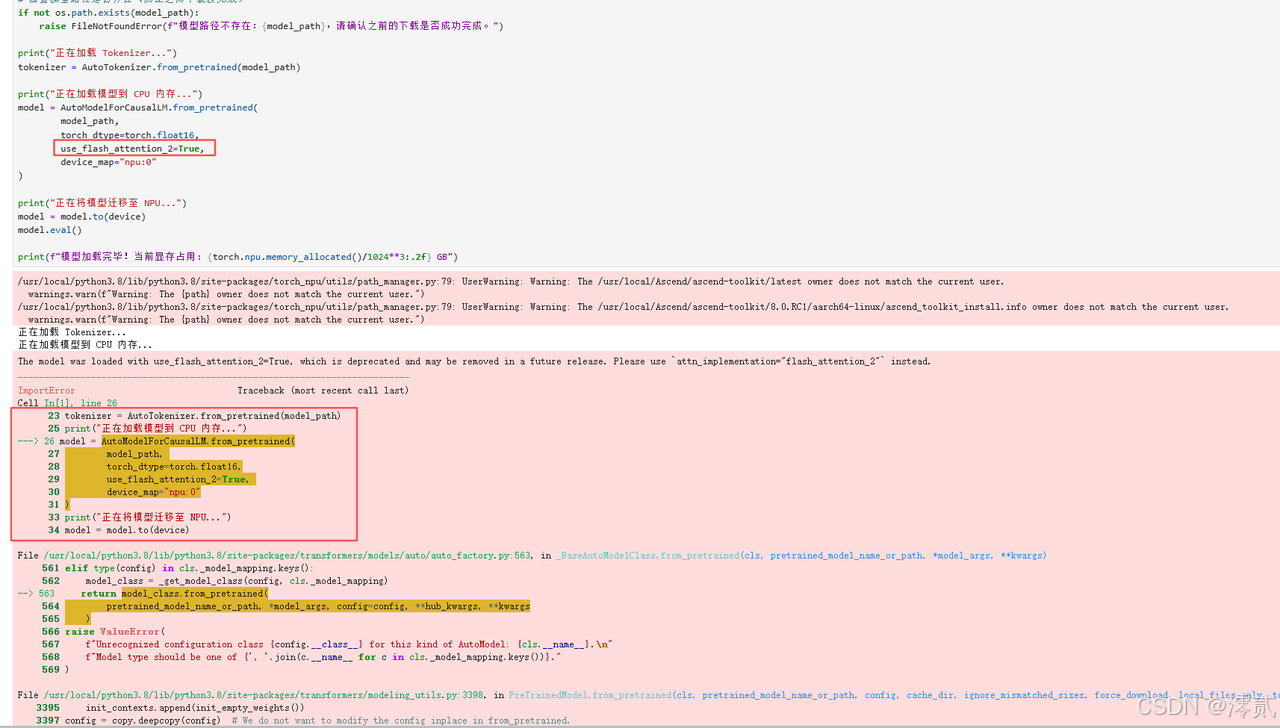
问题 1:Unsupported Operator 算子报错
-
现象:在模型加载或推理阶段,报错提示某些算子不支持,例如
RuntimeError: "FlashAttention" not implemented for 'Half'或者某些 RMSNorm 算子报错。 -
原因:这是因为 transformers 库的快速迭代引入了新的算子实现,而当前的 torch_npu 版本尚未对这些新算子进行底层适配。或者是因为模型配置文件中默认启用了 Flash Attention,但环境未正确安装对应的 NPU 版本插件。
-
解决方法:
-
版本回退:将 transformers 版本锁定在经过验证的版本(如实操中的 4.39.2),避免使用最新的 4.4x 版本。
-
禁用特定配置:在
from_pretrained时,显式指定use_flash_attention_2=False(如果库版本支持该参数),或者修改模型的config.json,确保使用标准的 Attention 实现。
-

问题 2:显存溢出 (OOM)
-
现象:在加载模型阶段,或者当
max_new_tokens设置过大时,程序崩溃,提示 NPU Out of Memory。 -
原因:Llama-2-7b 的 FP16 权重本身占用约 13.5GB 显存。虽然 7B 模型在 910B 上显存非常充裕,但如果我们尝试并发处理 100 条请求或输入 32k 长度的文本,仍需注意显存管理
-
解决方法:
-
监控****显存:使用
torch.npu.memory_allocated()实时打印显存使用情况。 -
严格控制参数:对于单卡推理,保持
batch_size=1,max_new_tokens不要设置过大(如控制在 512 以内)。 -
清理缓存:在多次推理之间,手动调用
torch.npu.empty_cache()释放未使用的显存碎片。
-
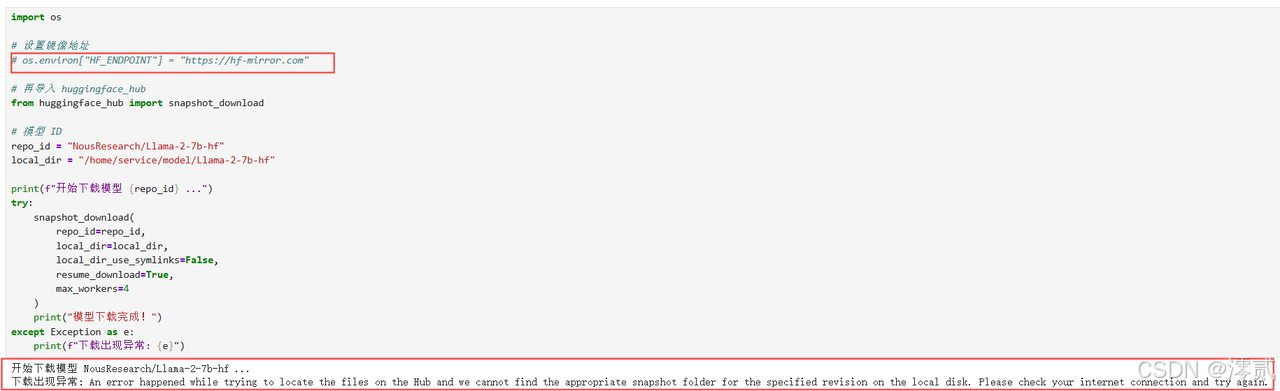
问题 3:模型下载连接超时 (Connection Timeout)
-
现象:运行下载脚本时,长时间卡在 0% 或者直接报错
ConnectionError。 -
原因:Notebook 容器的网络环境访问 Hugging Face 官方源不稳定。
-
解决方法:务必设置环境变量
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"。使用snapshot_download的resume_download=True参数,允许断点续传,防止大文件下载中断后前功尽弃。
问题 4:推理结果乱码或无限重复
-
现象:模型能跑通,但输出的英文单词支离破碎,或者不断重复一句话。
-
原因:通常是精度问题导致。在 NPU 上,部分算子在 FP16 下可能会出现溢出或精度损失。
-
解决方法:
-
检查
torch_dtype是否严格设置为torch.float16。 -
检查是否错误地使用了
bfloat16(某些老旧 NPU 驱动对 bf16 支持不如 fp16 完善)。 -
调整
generate参数,适当提高repetition_penalty(重复惩罚)。
-
问题 5:下载太慢或连接超时
-
现象:使用
huggingface_hub下载时速度仅几百 KB/s,或者报 Connection Timeout。 -
原因:官方源在云环境访问不稳定。
-
解决方法:放弃 HF 镜像配置,直接使用
modelscope库进行下载,速度通常能提升 100 倍以上。

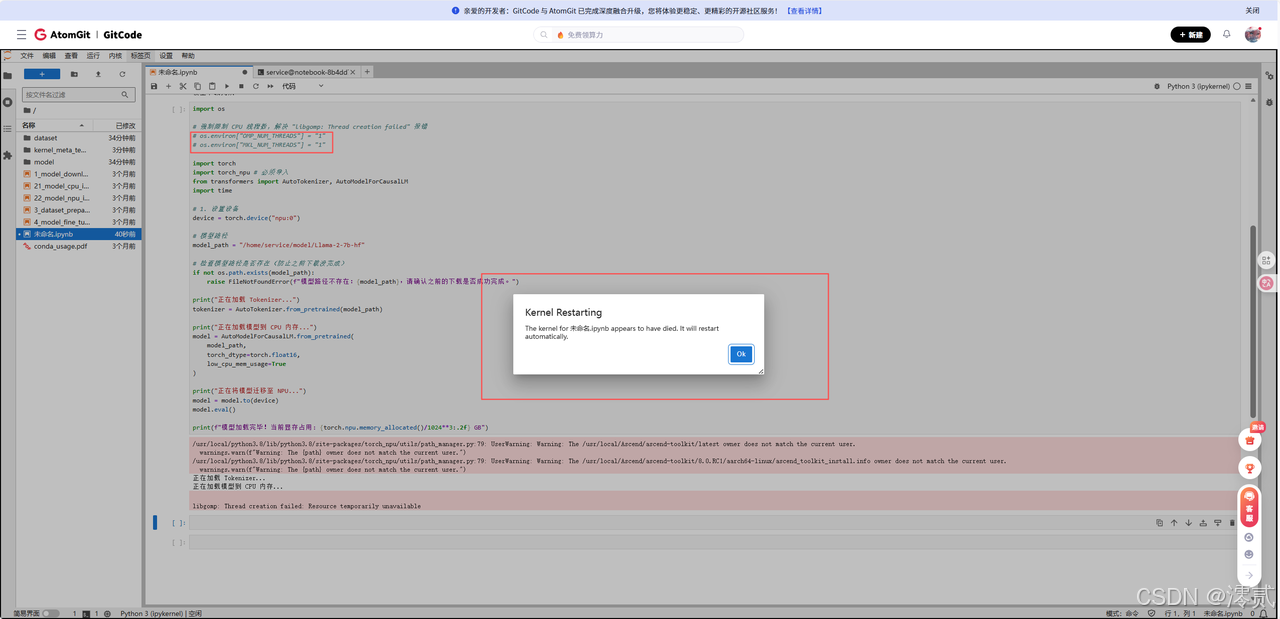
问题 6:内核崩溃:Resource temporarily unavailable
-
现象:代码运行到
model = AutoModel...时直接报错libgomp: Thread creation failed,Jupyter 内核重启。 -
原因:容器环境对最大进程/线程数(nproc)有限制,PyTorch 默认试图调用所有 CPU 核,导致资源超限。
-
解决方法:在代码最开头(import torch 之前)添加:
-
Python
os.environ["OMP_NUM_THREADS"] = "1"
问题 7:推理报错:Unsupported Operator
-
现象:提示
FlashAttention相关算子不支持。 -
原因:Transformers 版本过新(如 4.40+)引入了 NPU 尚未适配的新算子。
-
解决方法:回退
transformers版本至 4.39.2 或更早版本。
五、 实践总结
通过本次在 GitCode Notebook 上的实操,我们成功实现了 Llama-2-7b 模型在昇腾 NPU 上的部署与推理。
核心结论如下:
-
环境就绪度高:使用官方提供的预置镜像(EulerOS + CANN + PyTorch),可以规避 90% 的底层驱动安装问题,让开发者专注于模型应用层。
-
代码迁移成本低:从代码层面看,除了引入
torch_npu和修改 device 指向外,大部分 transformers 的原生代码可以直接复用。这证明了昇腾生态对 PyTorch 的兼容性已经达到了较高的水平。 -
调试重于编码:在异构计算环境下,大部分时间消耗在环境对齐(版本匹配)和算子适配上。掌握查阅 NPU 算子支持列表、学会看报错堆栈,是开发者必备的技能。
对于普通开发者而言,利用现有的云端 NPU 资源进行大模型学习和应用开发,已经是一条可行且高效的路径。只要注意避开版本兼容性和显存管理的“坑”,就能充分释放 NPU 的强大算力。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)