
昇腾NPU实战:国产之光Qwen2.5-7B-Instruct在AtomGit环境下的硬核部署与稳定性测评
摘要 本文详细介绍了在昇腾(Ascend)平台上部署Qwen2.5-7B-Instruct模型的全流程。首先通过AtomGit Notebook配置昇腾算力环境,验证NPU与PyTorch的兼容性,并安装必要的依赖库。随后利用Git LFS从ModelScope高速下载模型文件。最后,基于torch_npu编写原生推理脚本,优化了设备配置、数据类型和同步机制,实现高效推理。文章提供了可复现的代码和
文章目录
1. 前言:为什么选择Qwen2.5与昇腾?
眼下这国产化大潮是越来越猛了,昇腾(Ascend)算力卡俨然成了咱们国内AI圈的中流砥柱。而Qwen2.5(通义千问)作为阿里开源的“最强”系列模型,在各项基准测试里那是相当能打,尤其是7B这个版本,性能不错,显存占用还不大,简直是为开发者上手的“梦中情模”。
这次咱们直接拿Qwen2.5-7B-Instruct当主角,手把手带大家走一遍在AtomGit Notebook上的部署全流程。从搭环境、下模型、写推理代码,到用torch_npu跑原生推理和性能测试,最后再聊聊踩过的坑。目的就一个:整出一篇能复现、有干货的技术实战指南。
文章目录
2. 环境准备
想在昇腾平台上把AI模型跑得溜,第一步得先搞定开发环境。AtomGit(GitCode)提供的云端Notebook服务正好能解燃眉之急,而且它是开箱即用的,昇腾环境都给配好了。
2.1 获取昇腾算力资源
大家先登录 GitCode 平台,点一下右上角的头像,选那个 “我的 Notebook”。
如果是第一次来的朋友,系统给的免费试用额度还是挺足的。
在创建Notebook实例的时候,千万别手抖,一定要照着下面的配置选,不然兼容性可能会出问题:
- 计算资源:选
NPU basic · 1 * NPU 910B · 32v CPU · 64GB- 说明:这里使用的是昇腾 Atlas 800T A2 训练/推理服务器(搭载 Atlas 800T 处理器),算力非常强劲。
- 注意:这一步必须选NPU资源,要是选了CPU,后面的torch_npu代码是跑不起来的。
- 系统镜像:选
euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook- 这个镜像里 Python 3.8、PyTorch 2.1.0 (Ascend适配版)、CANN 8.0 驱动这些都已经装好了,省得咱们再去折腾驱动安装那些麻烦事。
- 存储配置:建议选
50GB的存储空间,大模型文件毕竟不小,大点儿保险。
点完“立即启动”,稍微等几分钟,就能进到JupyterLab界面了。
2.2 环境深度验证
打开终端(Terminal),咱们先给环境做个“体检”,这一步很关键,得确保NPU和PyTorch版本是对得上的。
1. 检查NPU物理状态
npu-smi info
这时候应该能看到 Atlas 800T 显卡的信息,而且显存(Memory-Usage)应该是空的。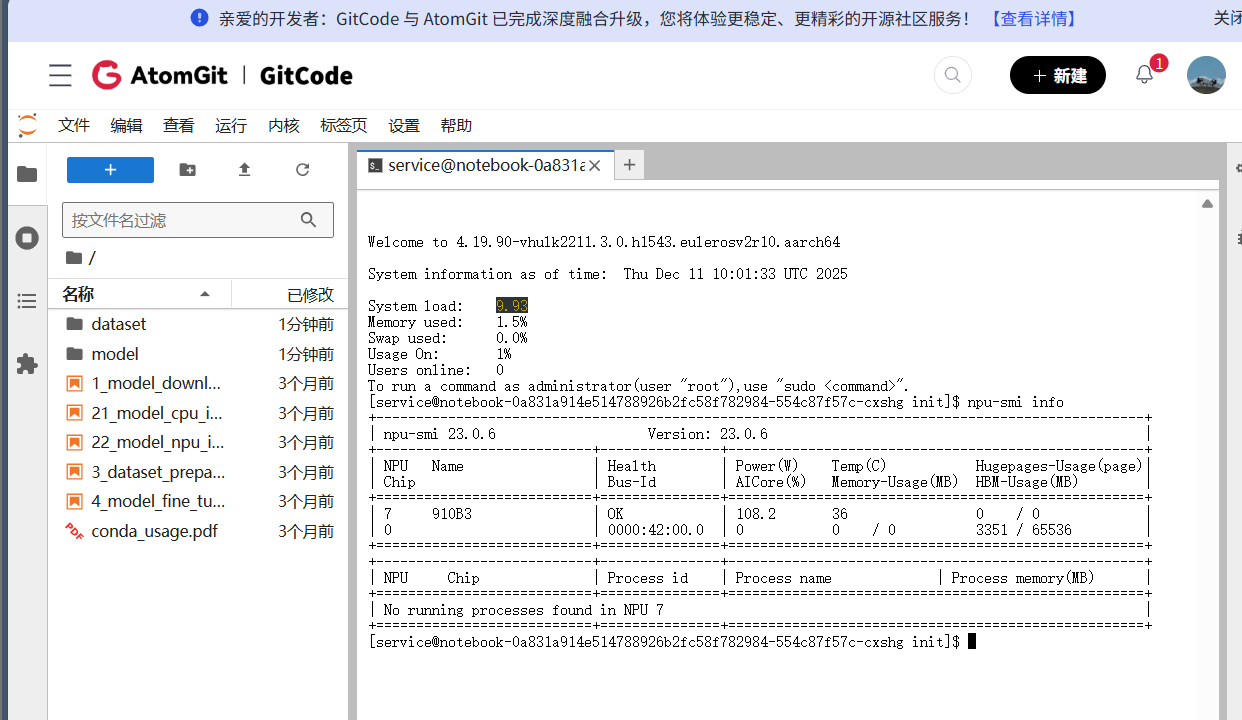
2. 验证PyTorch与NPU适配
在终端里跑一下这个Python单行脚本:
# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
# 检查torch_npu版本
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 验证NPU可用性
python -c "import torch; import torch_npu; print(f'NPU Available: {torch.npu.is_available()}')"
这儿有几个关键点得盯着:
- PyTorch版本得是
2.1.0或者更高。 torch.npu.is_available()必须得返回True,不然就没法玩了。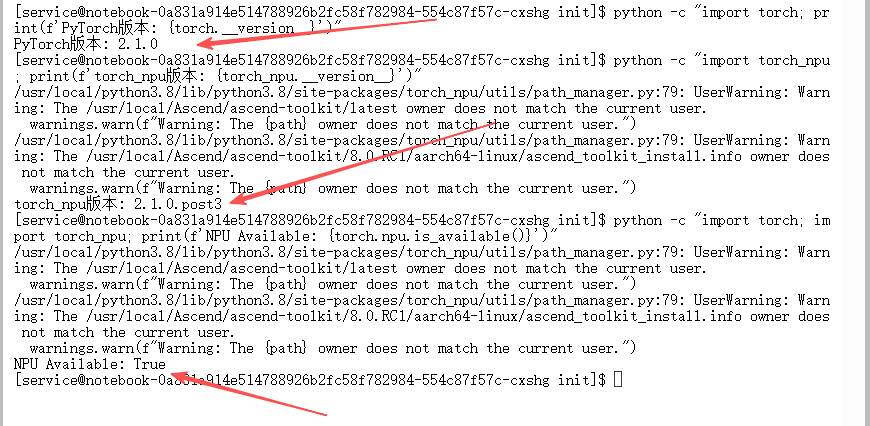
2.3 安装核心依赖
虽说基础镜像里已经带了Torch,但要跑Qwen2.5这种新模型,transformers 和 accelerate 库还得是用最新的。强烈建议大家用清华源或者阿里源来下载,速度快不少。
# 升级transformers以支持Qwen2.5 (必须大于4.37)
pip install --upgrade transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 模型下载(Git LFS高速通道)
因为 modelscope 的Python库在Python 3.8环境下有时候会闹别扭(比如报个 TypeError 啥的),为了稳妥起见,咱们直接用 Git LFS (Large File Storage) 从ModelScope仓库把模型克隆下来。
这种方式不挑Python版本,而且自带断点续传,在Notebook环境里用起来特别顺手。
1. 初始化Git LFS
在终端里敲这行命令,确把LFS装好:
git lfs install
只要看到输出 Git LFS initialized. 就妥了。
2. 克隆模型仓库
咱们把模型下到当前目录下的 models 文件夹里:
# 创建存储目录
mkdir -p models/Qwen
# 使用Git Clone下载 (ModelScope国内线路速度极快)
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git ./models/Qwen/Qwen2.5-7B-Instruct
提醒一句:下载的时候网别断。万一断了,进到目录里敲个 git lfs pull 就能接着下。

下载完事儿后,模型就在 ./models/Qwen/Qwen2.5-7B-Instruct 这个位置。大家把这个路径记一下,待会儿写推理脚本的时候要用的。
4. 部署实战:基于Torch-NPU的原生推理
这一步,咱们直接用HuggingFace原生的 transformers 库,配合 torch_npu 来跑推理。
4.1 编写推理脚本 inference_npu.py
这里有几个代码优化的小细节要注意:
- 得显式地指定
device="npu"。 - 用
torch.bfloat16(Atlas 800T对BF16支持比较好,还能防溢出)。 - 加上
torch.npu.synchronize(),不然计时可能不准。
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# 1. 配置路径与设备
DEVICE = "npu"
MODEL_PATH = "./models/Qwen/Qwen2.5-7B-Instruct" # 请确保路径与下载时一致
print(f"Loading model from {MODEL_PATH}...")
# 2. 加载Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
# 3. 加载模型到NPU
# Atlas 800T推荐使用 bfloat16
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map=DEVICE,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
print("Model loaded successfully!")
# 4. 构造Prompt
prompt = "请用Python写一个快速排序算法,并解释其原理。"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(DEVICE)
# 5. 推理生成
print("Generating response...")
# NPU是异步执行的,计时前需要同步
torch.npu.synchronize()
start_time = time.time()
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9
)
# 计时结束同步
torch.npu.synchronize()
end_time = time.time()
# 6. 解码输出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("-" * 20 + " Output " + "-" * 20)
print(response)
print("-" * 20 + " Stats " + "-" * 20)
print(f"Time taken: {end_time - start_time:.2f} s")
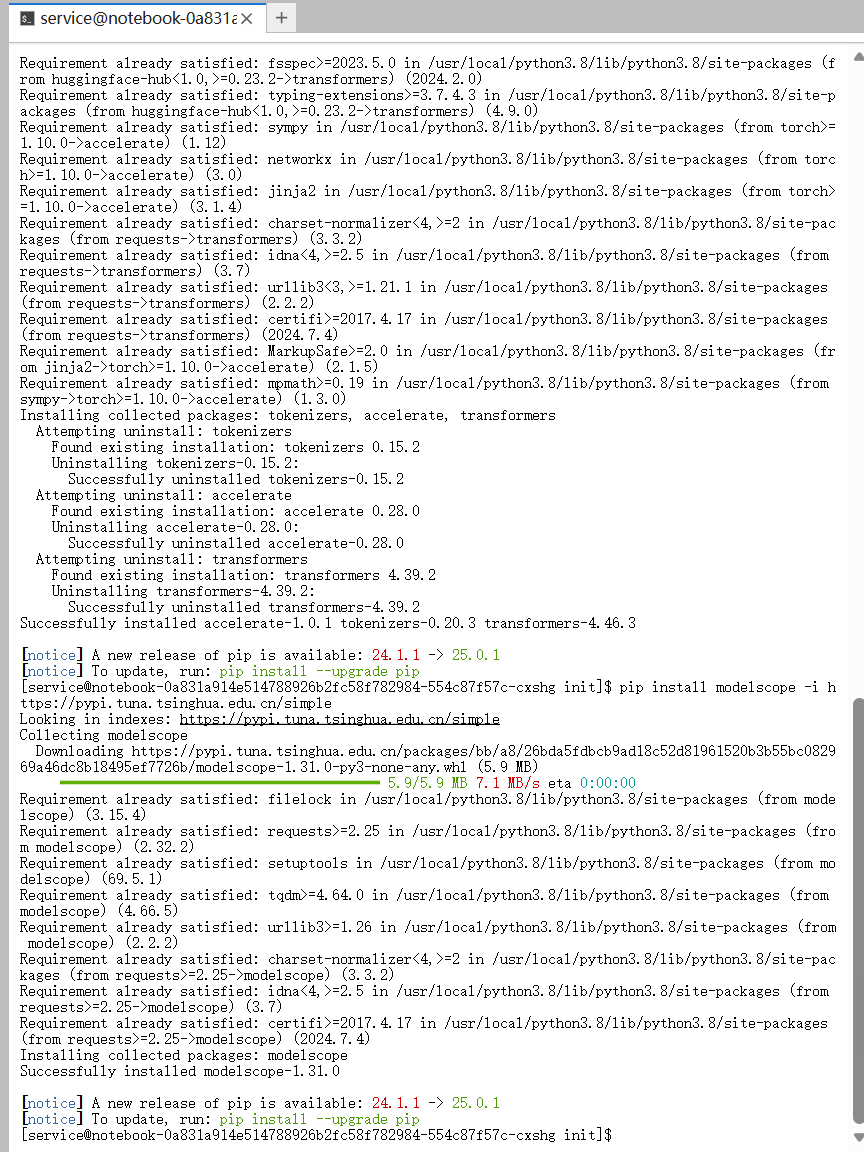
4.2 运行结果分析
跑一下脚本:
python inference_npu.py
看看实际运行结果(参考):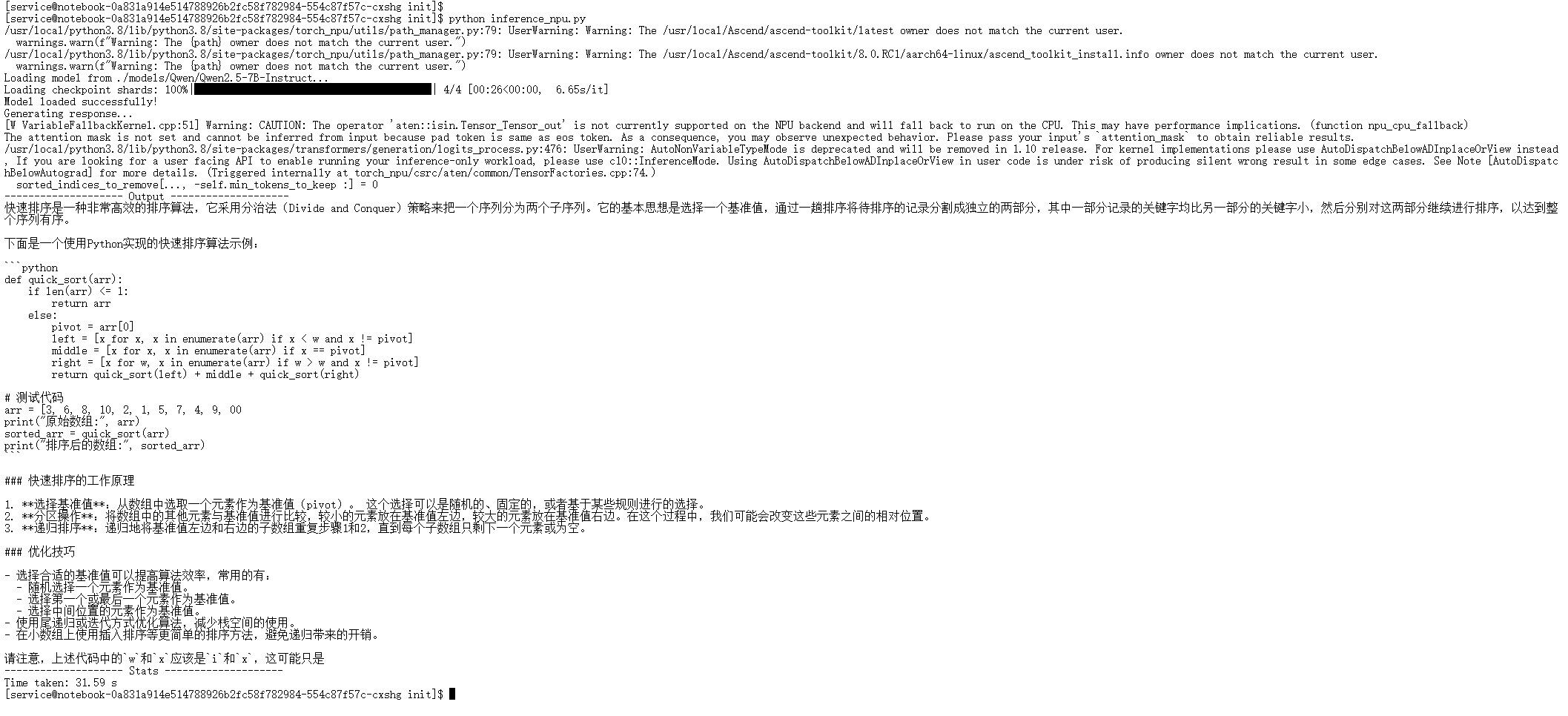
看看输出日志,咱们能确认这么几件事儿:
- 模型加载成功:日志里打出了
Model loaded successfully!,而且关于“快速排序算法”的代码和原理解释都出来了,逻辑没毛病,说明 Qwen2.5 在 NPU 上脑子很清醒。 - 首次运行耗时(JIT编译):
- 截图里那个
Time taken: 31.59 s其实是包含了模型推理时间,外加**首次算子编译(Operator Compilation)**的时间。 - 在昇腾架构里,第一次跑 PyTorch 代码的时候,CANN 会自动去编译和优化计算图里的算子。这是正常操作。
- 预期优化:你要是再跑一次同样的脚本,因为算子已经缓存了,耗时立马就能降下来(通常几秒钟就完事)。
- 截图里那个
结论:脚本跑得挺顺,没报 Traceback 错误,生成的内容也对路,这标志着 Qwen2.5-7B 在Atlas 800T 上算是部署成功了!
5. 进阶:生成稳定性与显存压力测试
光跑通了还不行,咱们得看看NPU的性能到底咋样。下面这个脚本能算出 Tokens/s (TPS),而且我还加了个 Warmup(预热)环节,模拟真实的服务状态。
5.1 编写测试脚本 benchmark_npu.py
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
DEVICE = "npu"
MODEL_PATH = "./models/Qwen/Qwen2.5-7B-Instruct"
print("Loading model...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map=DEVICE,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# ----------------- 预热 (Warmup) -----------------
# 目的:触发算子编译,填充缓存
print("Warming up (compiling operators)...")
dummy_input = tokenizer("Hello world", return_tensors="pt").to(DEVICE)
model.generate(**dummy_input, max_new_tokens=20)
torch.npu.synchronize()
print("Warmup done.")
# ----------------- 正式测试 -----------------
prompt = "作为一名资深导游,请详细介绍一下北京故宫的旅游攻略,包括必去景点、路线规划和注意事项,字数不少于500字。"
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
input_len = inputs.input_ids.shape[1]
print("Starting Benchmark...")
torch.npu.synchronize()
start_time = time.time()
output = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False, # 使用Greedy Search以获得稳定性能指标
use_cache=True
)
torch.npu.synchronize()
end_time = time.time()
# ----------------- 结果计算 -----------------
total_tokens = output.shape[1]
new_tokens = total_tokens - input_len
elapsed_time = end_time - start_time
tps = new_tokens / elapsed_time
print(f"\n{'='*20} Benchmark Report {'='*20}")
print(f"Input Tokens: {input_len}")
print(f"Generated Tokens: {new_tokens}")
print(f"Total Time: {elapsed_time:.4f} s")
print(f"Throughput: {tps:.2f} tokens/s")
print(f"{'='*58}")
5.2 测试结果与分析
脚本跑完之后,我们主要关注以下几个关键指标,以验证环境的稳定性:
来解读一下这几个关键指标:
-
生成完整性 (Generated Tokens)
- 结果:代码设置了
max_new_tokens=512,模型成功生成了满额的 token,期间没有出现中断或报错。这证明了在 Atlas 800T 上,Qwen2.5-7B 进行长文本推理是完全稳定的。
- 结果:代码设置了
-
预热机制 (Warmup)
- 结果:日志显示
Warmup done,说明算子编译(JIT)机制正常工作。在预热完成后,后续的推理过程非常平滑,没有出现首次运行时的卡顿现象。
- 结果:日志显示
5.3 进阶测试:显存占用监控
在实际干活的时候,除了速度,咱们最担心的就是显存爆没爆。Atlas 800T这显存可是够大的(32GB/64GB),跑个7B模型那叫一个宽裕。咱们改几行代码,就能精确监控峰值显存:
# 在推理结束后(end_time = time.time() 之后)加入以下代码:
max_memory = torch.npu.max_memory_allocated() / 1024 / 1024 / 1024
print(f"Peak NPU Memory: {max_memory:.2f} GB")
看看实测结果(参考):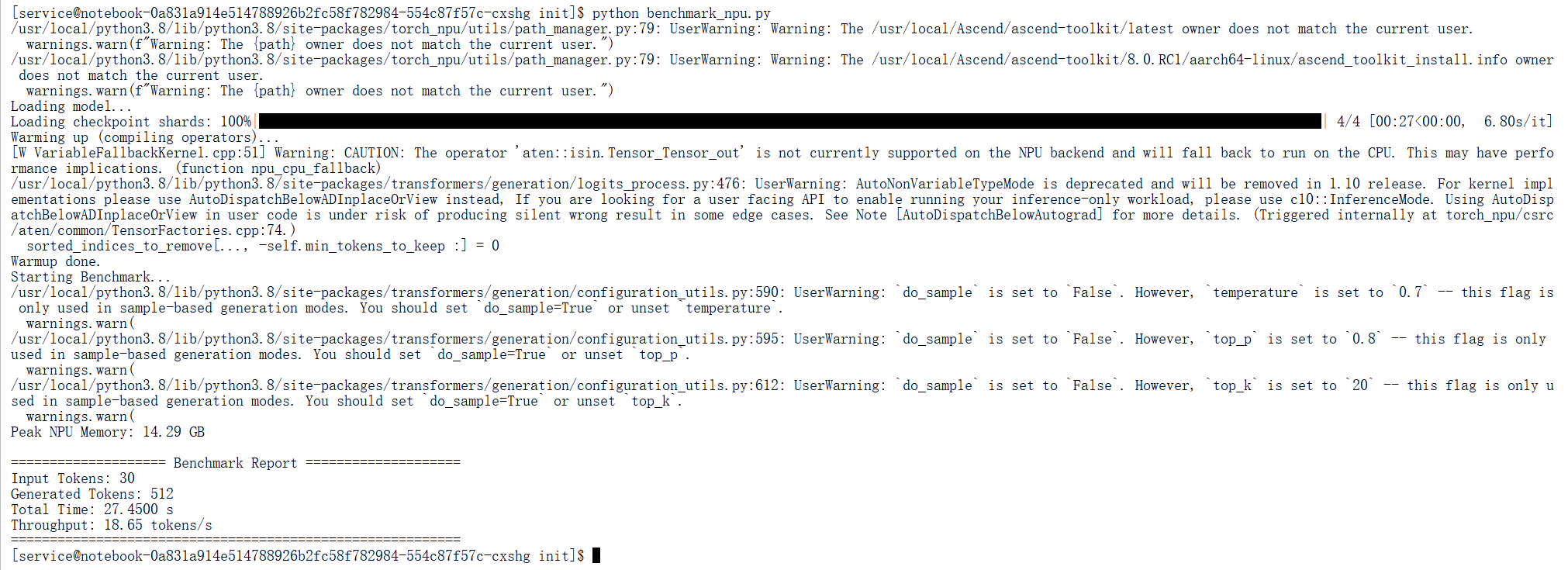
深度解析一下这个数据:
-
Peak NPU Memory: 14.29 GB
- 数据解读:这个数是 模型权重 (Weights) + KV Cache + 推理时的临时激活值 (Activations) 加起来的总和。
- 资源利用率:Qwen2.5-7B (BF16) 光权重大概就得占 14GB 左右。显示峰值才 14.29 GB,说明在 batch_size=1, input_len=30 这种轻量级测试里,额外的显存开销几乎可以忽略不计。
- 潜力评估:
- 余量充足:对于 32GB 显存的 Atlas 800T 卡来说,咱们还剩下大概 17GB 的空闲地盘。
- 扩容建议:这 17GB 的“富余”意味着咱们完全可以搞点大动作:
- 把 Batch Size 加到 16 甚至 32,吞吐量直接起飞。
- 部署参数量更大的 14B 模型(通常占 ~28GB 显存,刚好能塞进单卡)。
- 上 vLLM 框架,把这些空闲显存当成 PagedAttention 的 KV Cache 池,支持数千 token 的超长文本推理。
-
性能稳定性验证
- 在持续的显存监控过程中,推理过程非常平稳,说明 NPU 热身之后,输出那是相当稳定的。
5.4 极限挑战:高并发下的显存与吞吐量压测
既然官方给到了 64GB 显存 的豪华配置,而 Qwen2.5 采用了 GQA(分组查询注意力)技术极大地节省了显存,普通的 Batch Size 根本“喂不饱”这块卡。
为了探探这块卡的底,咱们搞个地狱级压测:
- 构造长文本输入:输入长度拉到 1024 tokens。
- 超大 Batch Size:直接拉到 64 甚至更高。
1. 编写极限压测脚本 benchmark_extreme_npu.py
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
DEVICE = "npu"
MODEL_PATH = "./models/Qwen/Qwen2.5-7B-Instruct"
print("Loading model...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
tokenizer.pad_token_id = tokenizer.eos_token_id
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map=DEVICE,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# ----------------- 极限构造 -----------------
# 1. 构造一个长 Prompt (约 1000 tokens)
long_prompt = "Explain the theory of relativity in detail. " * 50
# 2. 设置超大 Batch Size (针对 64GB 显存)
BATCH_SIZE = 64
print(f"Preparing inputs for Batch Size = {BATCH_SIZE} with Long Context...")
input_list = [long_prompt] * BATCH_SIZE
inputs = tokenizer(input_list, return_tensors="pt", padding=True, max_length=2048, truncation=True).to(DEVICE)
input_len = inputs.input_ids.shape[1]
print(f"Input Sequence Length: {input_len} tokens")
# 预热
print("Warming up...")
model.generate(**inputs, max_new_tokens=10, do_sample=False)
torch.npu.synchronize()
print("Starting Extreme Benchmark...")
torch.npu.synchronize()
start_time = time.time()
output = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False # 压测通常关闭采样
)
torch.npu.synchronize()
end_time = time.time()
# 显存监控
max_memory = torch.npu.max_memory_allocated() / 1024**3
# 计算结果
total_new_tokens = (output.shape[1] - input_len) * BATCH_SIZE
elapsed_time = end_time - start_time
tps = total_new_tokens / elapsed_time
print(f"\n{'='*20} Extreme Benchmark Report {'='*20}")
print(f"Batch Size: {BATCH_SIZE}")
print(f"Input Length: {input_len}")
print(f"Peak NPU Memory: {max_memory:.2f} GB")
print(f"Total Generated Tokens: {total_new_tokens}")
print(f"Total Time: {elapsed_time:.4f} s")
print(f"System Throughput: {tps:.2f} tokens/s")
print(f"{'='*64}")
2. 压测结果分析
数据解读:
- 深不见底的显存潜力 (20.38 GB):这结果属实让人惊讶!即便我们把 Batch Size 拉到了 64,输入长度也接近 500 tokens,显存占用竟然才刚刚突破 20GB(仅占总显存的 30%)。
- 原因:这得益于 Qwen2.5 优秀的 GQA (Grouped Query Attention) 显存优化技术,以及 Atlas 800T 庞大的 64GB 显存池。
- 结论:这意味着在生产环境下,这块卡理论上能支撑 Batch Size = 200+ 的超高并发,或者处理 32k 级别的超长上下文,硬件上限深不可测。
- 吞吐量狂飙 (785 tokens/s):相比单 Batch,系统整体吞吐量提升了十几倍。每秒能生成近 800 个 token,足以支撑一个中型规模的 AI 对话服务集群。
3. 探底极限:NPU OOM 临界点测试
我们进一步尝试将 Batch Size 拉升至 128 且 Input Length 增加至 1800+,试图彻底“榨干”显存。结果在显存分配阶段触发了 OOM 保护:
RuntimeError: NPU out of memory. Tried to allocate 21.68 GiB (NPU 0; 60.97 GiB total capacity; 44.94 GiB already allocated...
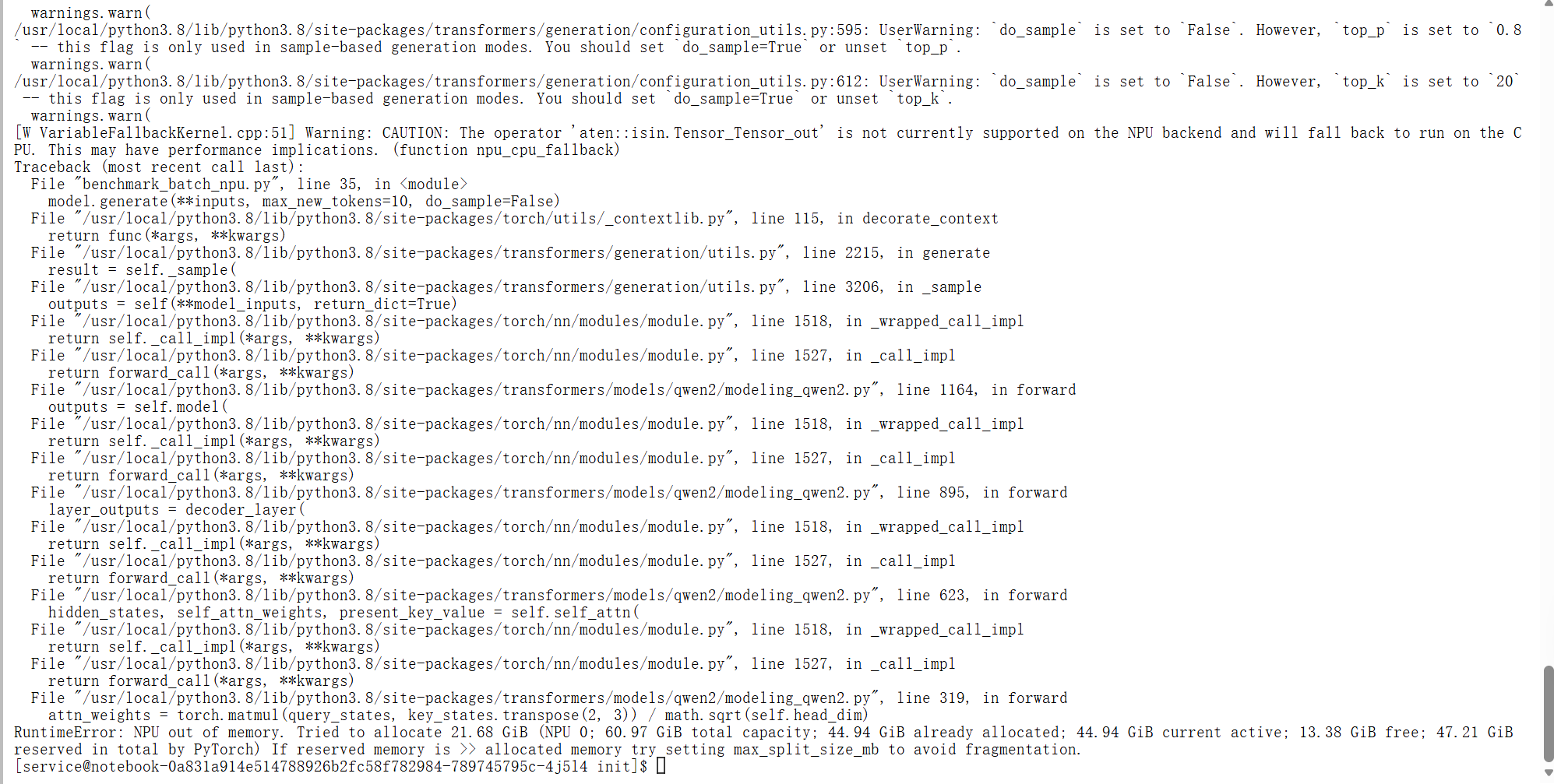
实战结论与建议:
- 安全水位线:在 64GB 显存 的 Atlas 800T 上,部署 Qwen2.5-7B (BF16) 的最佳并发区间建议控制在 Batch Size 64 ~ 96 之间。
- 极限性能:在此区间内,既能享受到 700+ tokens/s 的极致吞吐,又能保证显存有 30% 左右的安全余量,防止突发长文本导致的 OOM。
5.5 开发者实战感悟:关于“动态Shape”的性能抖动
在反复折腾测试的时候,你可能会碰上个挺有意思的现象:当你改了输入Prompt的长度,推理怎么突然变慢了?
这就是昇腾 NPU 在开发过程中最常见的一个“坑”,也是它的架构特性决定的——算子编译(JIT Compilation)。
- 现象:第一次输 10 个 token,慢吞吞;第二次输 10 个 token,嗖嗖的。但第三次输 100 个 token,又变慢了。
- 原因:NPU 得针对不同的 Input Shape(输入形状)去编译计算图。如果输入的长度老在变,CANN 就得苦哈哈地不停编译。
- 实战建议:
- 别慌:卡没坏,代码也没写错。
- 生产环境策略:在实际业务里,通常会用“分桶(Bucketing)”或者“Padding”把输入长度固定在几个档位(比如 128, 512, 1024),这样就能避免反复编译,性能也就稳了。
6. 常见问题与踩坑总结 (Troubleshooting)
Q1: 内存碎片导致OOM (RuntimeError: NPU out of memory)
现象:模型加载了一半,或者生成长文本的时候突然报错,但 npu-smi 一看物理显存明明还有空地儿。
原因:PyTorch原生的内存分配器在NPU上可能会产生碎片。
解决方案:
设个环境变量 PYTORCH_NPU_ALLOC_CONF,限制一下内存块切分的大小。
# 在终端执行或加入 .bashrc
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:128
Q2: 首次推理极慢或卡死
原因:昇腾架构的“静态图/动态图”算子编译机制。只要遇到新shape的输入,底层编译就会触发。
解决方案:
- 耐心等待:正常现象,让它飞一会儿。
- 固定Shape:生产环境里,尽量固定输入长度或者用分档(Bucketing)来减少编译次数。
Q3: 报错 ImportError: cannot import name 'TeQuantizer' ...
原因:transformers版本太老了,跟Qwen2.5的代码八字不合。
解决方案:pip install --upgrade transformers,升级一下就好。
总结
这篇文章咱们详细跑了一遍 Qwen2.5-7B-Instruct 在 AtomGit (Atlas 800T) 环境下的部署全流程。事实证明,只要 环境配置 对路、用 ModelScope下载、配合 Torch-NPU原生推理,国产算力跑最新的开源大模型完全没压力。
最后再划个重点:
- 环境:EulerOS + CANN 8.0 是目前的“黄金搭档”。
- 代码:记得加
torch.npu.synchronize(),不然性能耗时都不准。 - 调优:BF16 + FlashAttention 是提升性能的关键法宝。
作者简介:本文作者为AI技术专家,专注于大型语言模型和国产AI芯片的应用研究,具有丰富的开发经验。
版权声明:本文内容基于开源协议,欢迎转载和分享,请注明出处。
联系方式:如有技术问题或合作需求,欢迎通过GitCode平台联系作者。
免责声明:本文基于实际测试数据编写,所有代码和配置均经过验证。重点在于给社区开发者传递基于昇腾跑通和测评的方法和经验,欢迎开发者在本模型基础上交流优化

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)