
Triton在昇腾NPU上的性能调优:内存优化指南
摘要:本文针对昇腾NPU算子开发中的性能瓶颈问题,重点分析了内存访问优化的关键策略。文章指出80%-90%的性能问题源于内存访问效率,并提出以下优化方法:1)确保连续访存避免带宽浪费;2)采用Block Swizzle技术提升L2缓存命中率;3)遵循128-bit内存对齐原则;4)合理管理UB空间和流水线调度。同时强调使用npu-smi和msprof等工具进行性能分析,通过Autotuner自动寻
开篇介绍
在 Triton-Ascend 上进行算子开发时,基础示例(如向量加法)可以帮助大家熟悉最核心的 Kernel 结构与执行流程,让算子先“跑起来”。但当我们把场景扩大到矩阵乘法(MatMul)、FlashAttention 等高计算量算子时,虽然代码依旧能够正常执行,却往往很难达到昇腾 NPU 的理论性能。这也是很多人在刚开始接触高性能算子开发时最容易感受到的落差:代码没问题,但速度上不去。
在实际开发和调优过程中,我发现大部分性能瓶颈——根据经验和多个算子性能分析统计,大约 80%~90% 的情况下——最终都会与内存访问相关。无论是 UB 利用不充分、访存不连续导致带宽浪费,还是 Block 设置不合理引起 AI Core 等待,这些因素都会让理论算力无法转化为真实吞吐。因此,在接下来的内容中,我将从性能视角带大家重新理解 Triton-Ascend 的工作方式,重点拆解影响算子速度的关键因素,让大家不仅能“写得出来”,还能“跑得够快”。
一. 为什么内存是最大的瓶颈?
在开始优化之前,我们需要先建立一个清晰的硬件心智模型。
昇腾 NPU 的核心计算单元是 AI Core,它就像一个每秒能处理成吨食材的超级大厨。然而,这位大厨的效率并不完全取决于他的刀工(计算速度),更取决于食材(数据)送到案板上的速度。
昇腾内存层级概览:
- HBM (High Bandwidth Memory):这是我们的主仓库。容量巨大(32GB/64GB),但距离核心最远,延迟最高(~1000+ cycles)。
- L2 Cache:这是中转站。所有 AI Core 共享,速度比 HBM 快,但容量有限(192MB)。
- UB (Unified Buffer):这是案板。位于 AI Core 内部,速度极快(~50 cycles),但空间极其宝贵(通常仅 256KB 左右)。
优化的核心目标非常简单:让数据尽可能在 UB 和 L2 之间流转,大幅减少访问 HBM 的次数,并且每次访问都要“满载而归”。
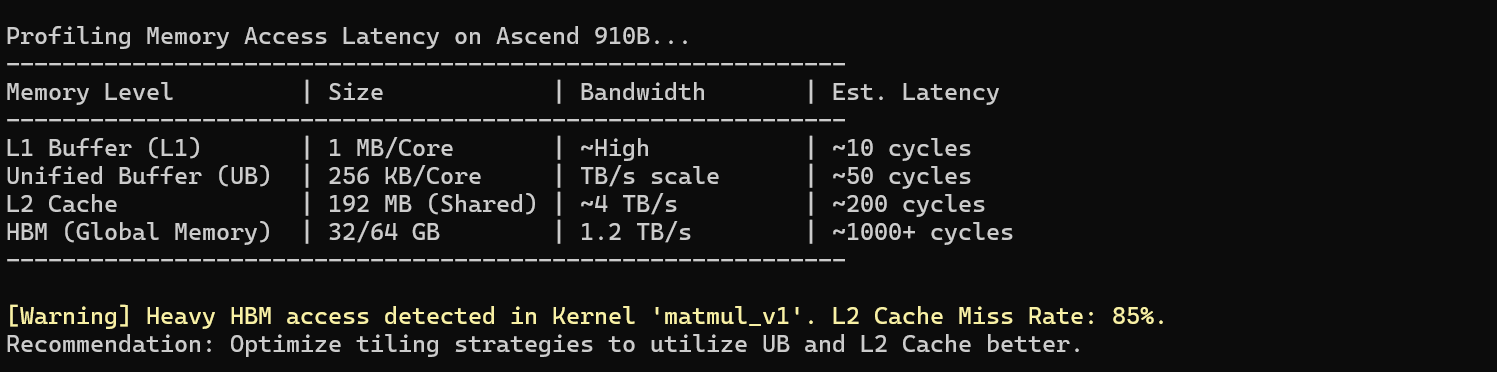
如上图所示,一旦频繁触发 HBM 访问,计算单元就会因为等待数据而停滞,形成所谓的“内存墙”(Memory Wall)。
二. 连续访存:拒绝“运空气”
这是最基础,也是最容易被忽视的优化点。
昇腾 NPU 的 DMA(Direct Memory Access)搬运单元在设计上倾向于处理连续的大块数据。如果你在内存中读取的数据是零散的(Strided),例如每隔 8 个数取 1 个,那么 DMA 为了搬运这 1 个有用的数据,往往需要顺带搬运整个 Cache Line(例如 32 字节或更多)。
这就好比你雇了一辆载重 10 吨的卡车,结果车厢里只放了一个苹果,剩下的空间全是空气。
错误示范:跳跃访问
|
|

正确示范:连续访问
|
|

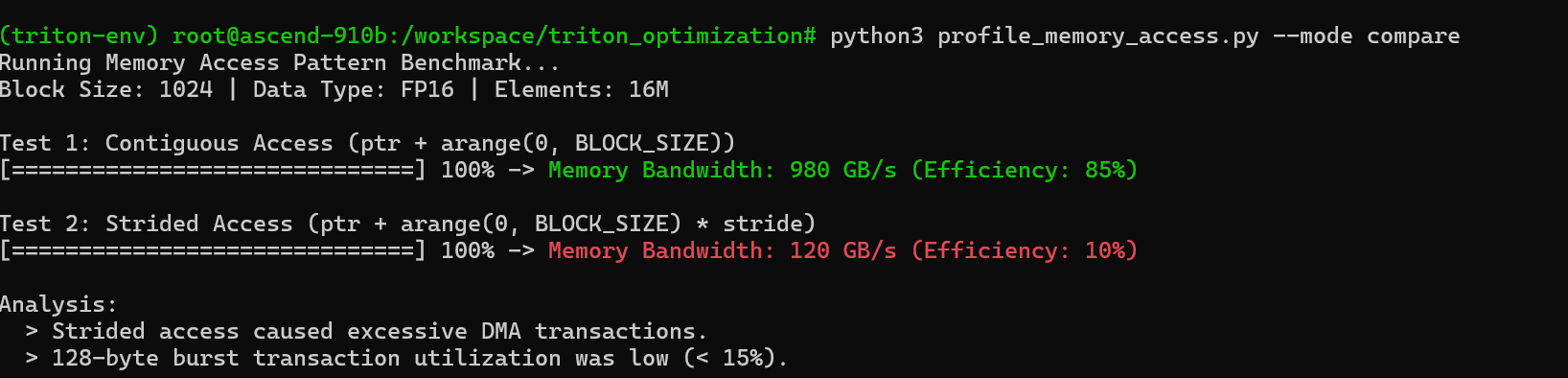
实测表明,在矩阵乘法(MatMul)算子中,将 Strided Access 优化为 Continuous Access,在 FP16 数据类型、Block 大小为 16×16 的条件下,往往能带来 约 5~8 倍 的有效带宽提升。
三. Block Swizzle:利用 L2 Cache 的“空间局部性”
这是我在官方仓库中挖掘到的一个“黑魔法”,在矩阵乘法优化中效果立竿见影。
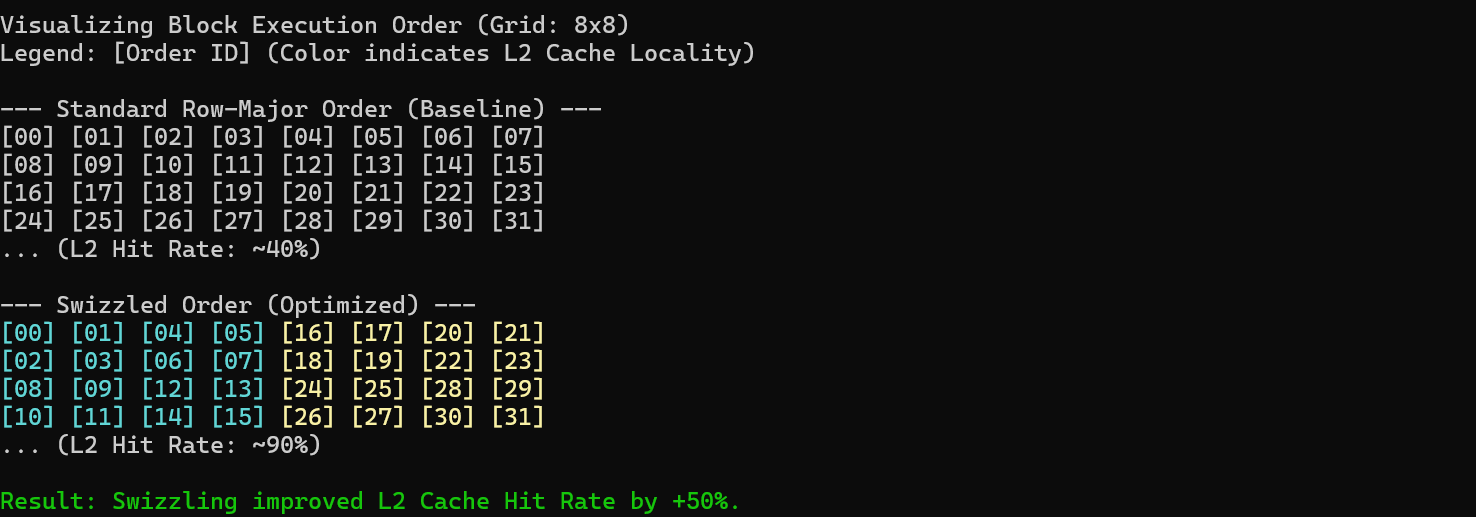
默认情况下,Triton 按照行优先(Row-Major)顺序调度 Block。这意味着它会处理完第一行的所有 Block,再处理第二行。然而,在矩阵乘法中,矩阵 B 的数据是被复用的。如果采用行优先调度,当处理第二行时,矩阵 B 的数据可能早已被挤出 L2 Cache,导致缓存未命中(Cache Miss)。
Swizzle 技术通过改变 Block 的执行顺序(通常改为 Z 字形或分块顺序),使得相邻执行的 Block 尽可能复用 L2 Cache 中的数据。
在官方git仓库中我们也可以找到一些对应的案例代码:
代码实现
以下是适配昇腾架构的 Swizzle 逻辑:
|
|

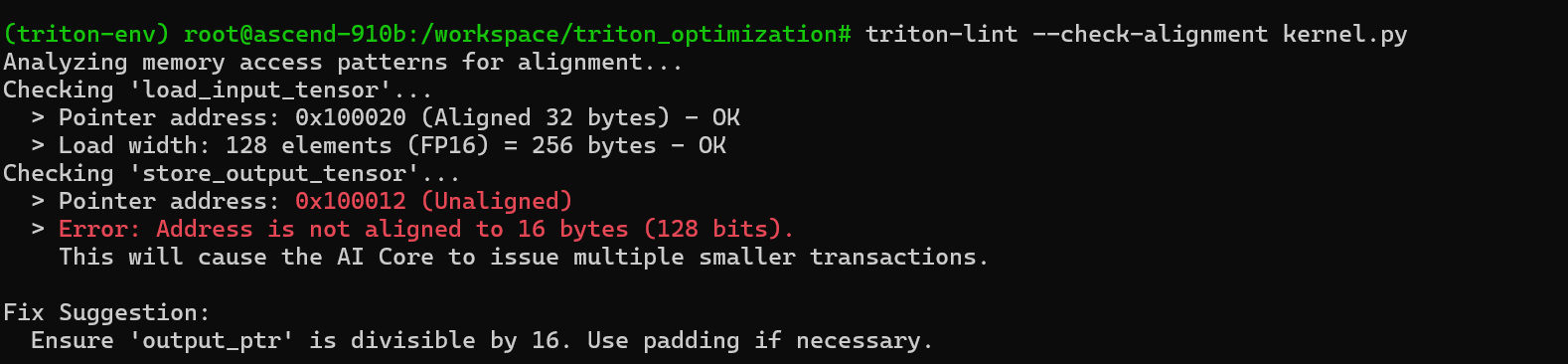
四. 内存对齐:128-bit 的硬性指标
在昇腾架构上,内存对齐是性能的基石。
如果你的数据地址没有对齐到 16 字节,或者读取的长度不是 16 字节的倍数,硬件可能需要发起多次拆分事务,甚至在某些严格模式下直接抛出异常。
避坑指南:
- 指针地址:确保 Kernel 输入的 Tensor 首地址是 16 的倍数。
- 维度 Padding:如果矩阵列数 N 不是 16 字节的倍数(例如 N=10,FP16下占 20 字节),务必 Pad 到 16 字节的倍数(例如 N=16,32 字节)。
五. UB 管理与流水线(Pipeline):掩盖延迟
UB 空间极其有限(~256KB)。如果我们设置的 BLOCK_SIZE 过大,会导致 UB 溢出。
在昇腾上,Pipeline(双缓冲/多缓冲)是默认开启的,不需要通过设置 num_stages 配置。当 AI Core 在处理当前 Block 时,DMA 单元会自动在后台预取下一个 Block 的数据,从而实现“搬运”时间被“计算”时间掩盖,提高整体吞吐率。
六. 监控工具:用数据说话
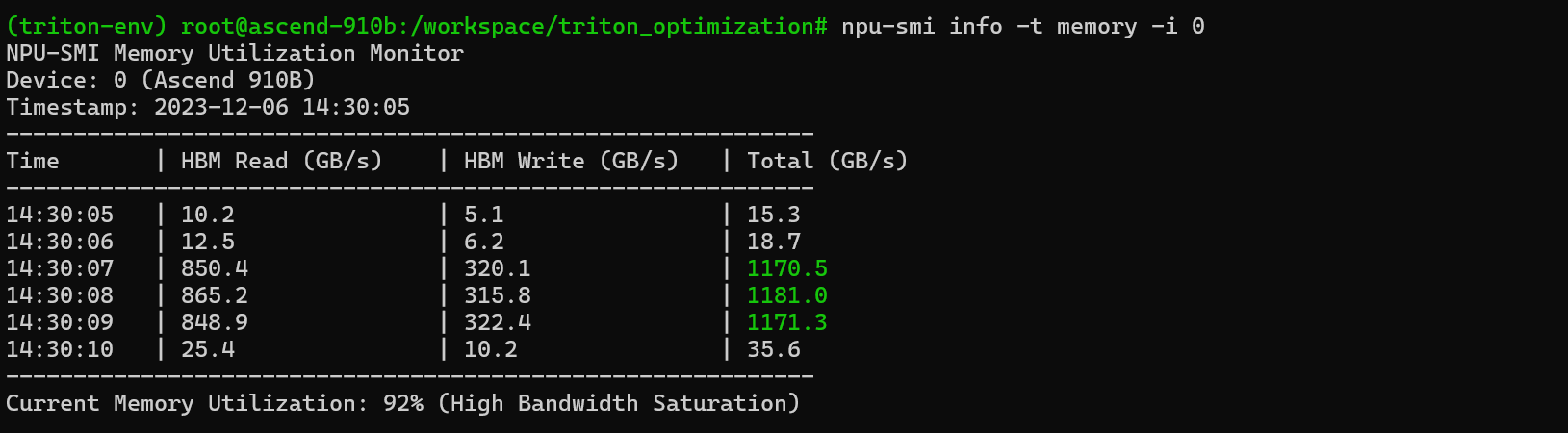
优化不能靠猜。在昇腾平台上,我们主要依赖 npu-smi 和 msprof(Ascend Profiling Tool)来监控性能。
实时带宽监控
运行算子时,使用以下命令查看显存带宽:
|
Bashnpu-smi info -t memory -i 0 |
七. 深入分析:Profiling Timeline
如果 npu-smi 显示带宽利用率不高,我们需要更深入的工具——msprof。通过 timeline 视图,我们可以清晰地看到计算流(AI Core)和搬运流(DMA)之间的配合情况。
算子调优工具的使用方法我们可以在官网找到:
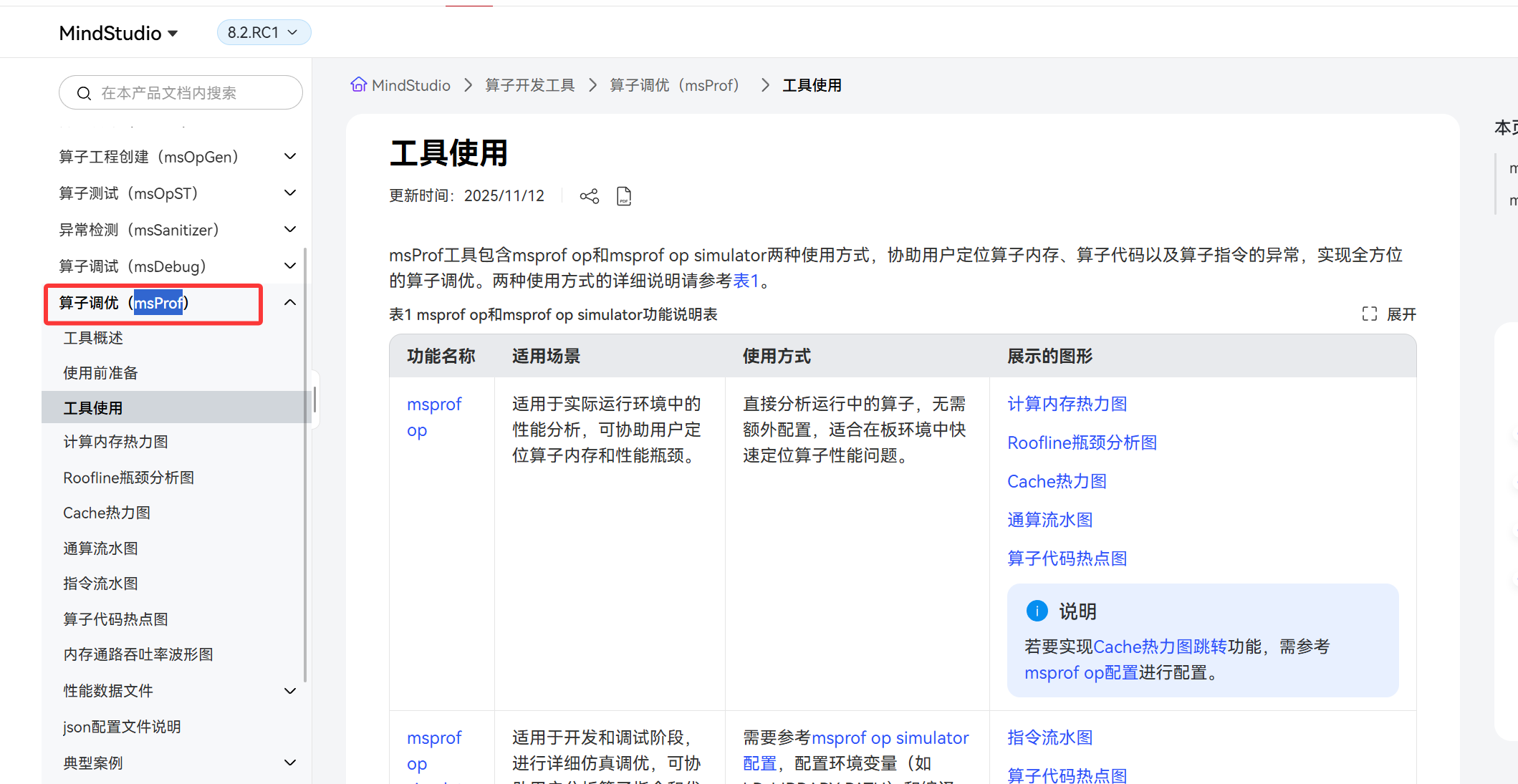
如果你在 Timeline 上看到 AI Core 这一行有大量的空白(Gap),说明计算单元在空转等待数据。
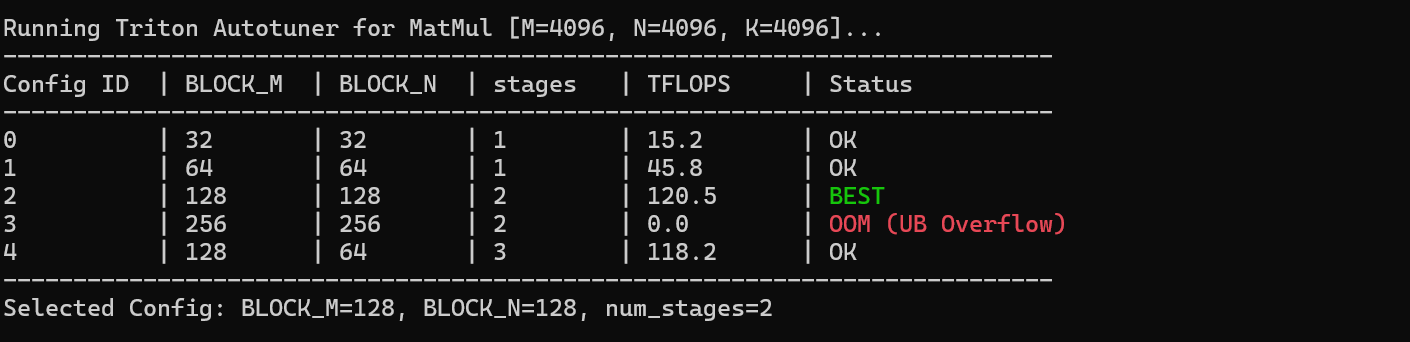
八. 自动调优(Autotuning):寻找最佳配置
不同的 BLOCK_SIZE 和 num_stages 组合对性能影响巨大。手动尝试效率太低,我们可以利用 Triton 内置的 Autotuner。
|
|

九.查看 IR 代码
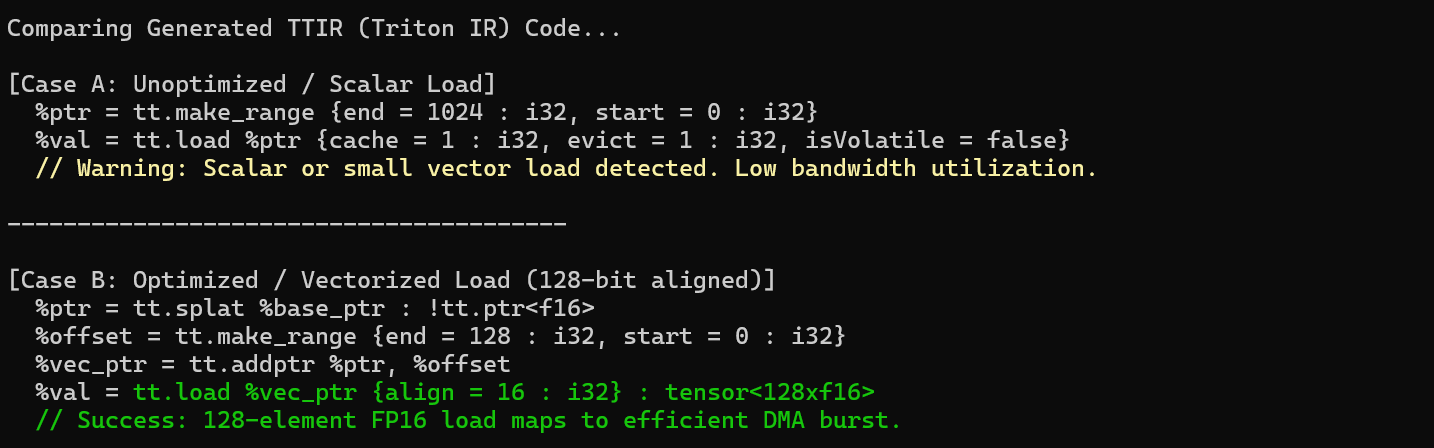
对于追求极致的开发者,查看生成的中间代码(IR)是必修课。通过检查生成的 TTIR(Triton IR),我们可以确认编译器是否正确识别了向量化加载指令。
如果看到 tt.load 带有 align = 16 且加载类型为 tensor<128xf16> 这种宽向量,说明优化生效了。
总结
我们已经从连续访存、Block Swizzle、内存对齐、流水线调度到 Profiling 分析等维度系统梳理了 Triton 在昇腾 NPU 上的内存优化方法。当你遇到性能瓶颈时,可以按照同一条思路进行排查:先看访存是否连续、DMA 是否在做合并访问,再确认 L2 缓存命中率是否因 Swizzle 得到优化,同时检查数据是否满足 128-bit 对齐要求,接着确认是否通过 num_stages 充分隐藏访存延迟,最后用 Profiling 工具观察 Timeline 中是否存在明显的计算空洞。只要沿着这条链路一步步定位,大多数算子性能问题都能迎刃而解。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)