
从零到一,基于昇腾平台的多模态视频生成实战之旅
这个过程重复成千上万次,模型就学会了"什么样的噪声对应什么样的图像"。中间层是加速算法,包括高性能算子(RoPE、RMSNorm、FlashAttention)、并行策略(Ulysses、Ring、CFG)、近似算法(DiTCache、序列压缩)和量化技术(W8A8、FA量化)。扩散模型的火爆让AI视频生成成为了当下最热门的技术方向之一。但当我第一次尝试在昇腾NPU上部署Wan2.1视频生成模型时
但当我第一次尝试在昇腾NPU上部署Wan2.1视频生成模型时,却遇到了性能瓶颈——单卡推理一个5秒视频竟然要等上几分钟。
后来通过MindIE SD推理加速套件的深度优化,推理速度提升了3倍以上。今天就来聊聊这个过程中踩过的坑和总结的经验。
1 扩散模型不是玄学,理解原理才能优化到位
很多开发者把扩散模型当成黑盒使用,但要做推理优化,必须理解它的工作机制。扩散模型本质上是个"加噪-去噪"的循环游戏。
训练阶段就像教AI"认识噪声":随机选一张图片,按照预设的时间步t加入高斯噪声,然后让模型预测这个噪声长什么样。通过计算真实噪声和预测噪声的差距,不断调整模型参数。这个过程重复成千上万次,模型就学会了"什么样的噪声对应什么样的图像"。
推理阶段则是反向操作:从一团随机噪声出发,设定50步或100步去噪步数,每一步都让模型预测当前的噪声分布,然后减去这个噪声,图像就逐渐变得清晰起来。这就像雕刻家从石头里凿出雕像——石头是噪声,每凿一刀就是一次去噪。
大家可以看一个总结好的例子,生动形象的描述扩散模型的定义:
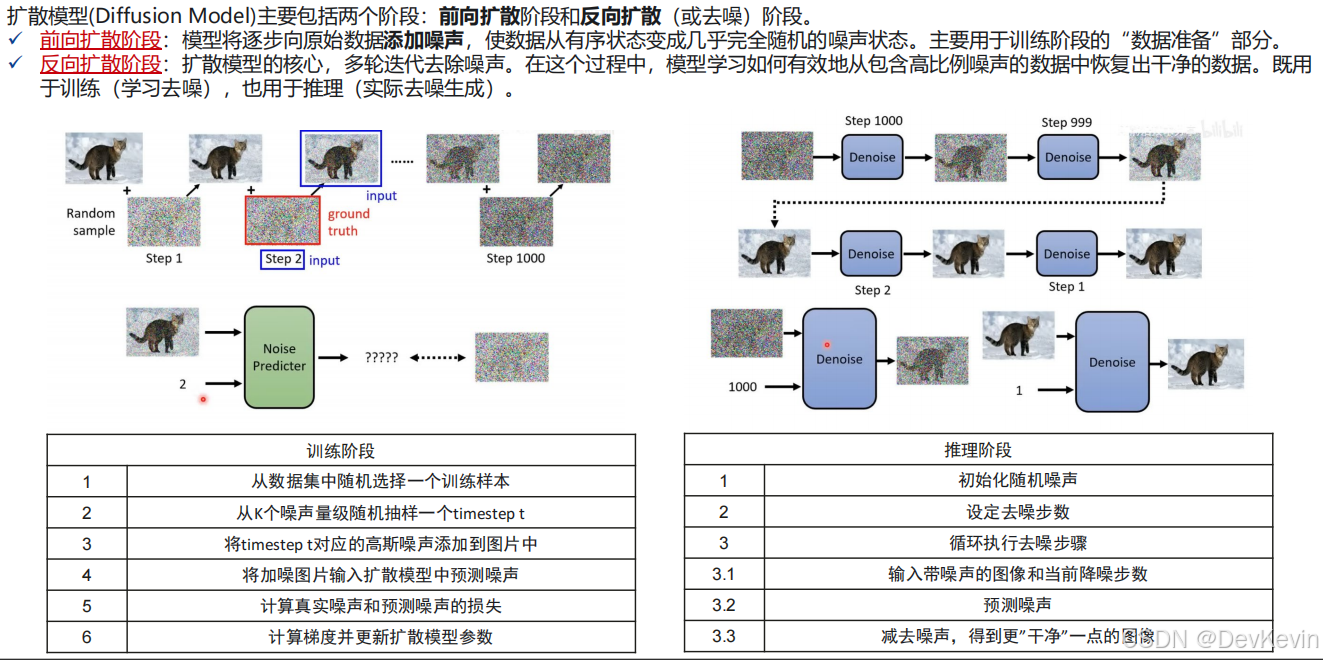
记住推理步数越多生成质量越好,但计算量也呈线性增长。在实际部署时需要在质量和速度间找平衡点,我的经验是50步是个不错的起点。
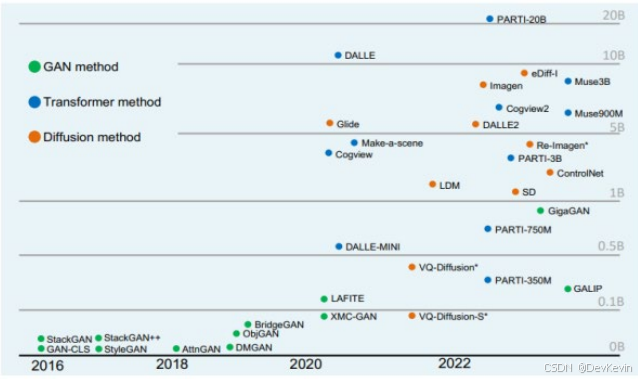
2 从UNet到Transformer,架构演进带来的性能挑战
早期的Stable Diffusion 1.5/2.1采用UNet架构——这种U型网络通过编码器逐步压缩分辨率提取特征,再通过解码器逐步恢复分辨率生成图像,中间还有跳跃连接保留细节。这套架构在图像生成上很成熟,但扩展到视频领域就力不从心了。
2024年后,以Stable Diffusion 3和Wan系列为代表的DiT(Diffusion Transformer)架构成为主流。DiT用Transformer Block替代了UNet,最大的优势是:
1. 可扩展性强:可以无缝扩展到视频生成,只需要把2D Attention改成3D Attention。
2. 并行效率高:Transformer的自注意力机制天然支持并行计算。
3. 继承LLM红利:可以直接借鉴大语言模型的优化技术,比如FlashAttention、RoPE位置编码等。
但这种架构转变也带来了新问题——长序列成为性能瓶颈。
一个1280x720分辨率、5秒25帧的视频,转成latent patches后序列长度可能达到几十万,Attention的计算复杂度是O(n²),这意味着序列长度翻倍,计算量就要翻四倍。
我在部署Wan2.1-T2V-14B模型时就遇到了这个问题。单卡A800 GPU显存直接爆了,不得不降低分辨率或减少帧数。后来迁移到昇腾910B后,通过MindIE SD的序列并行和DiTCache技术才解决。
3 MindIE SD,不只是推理引擎,更是优化工具箱
MindIE SD是昇腾专门为视频生成模型打造的推理加速套件。它不是简单地把模型搬到NPU上跑,而是提供了从算子层到系统层的全栈优化能力。
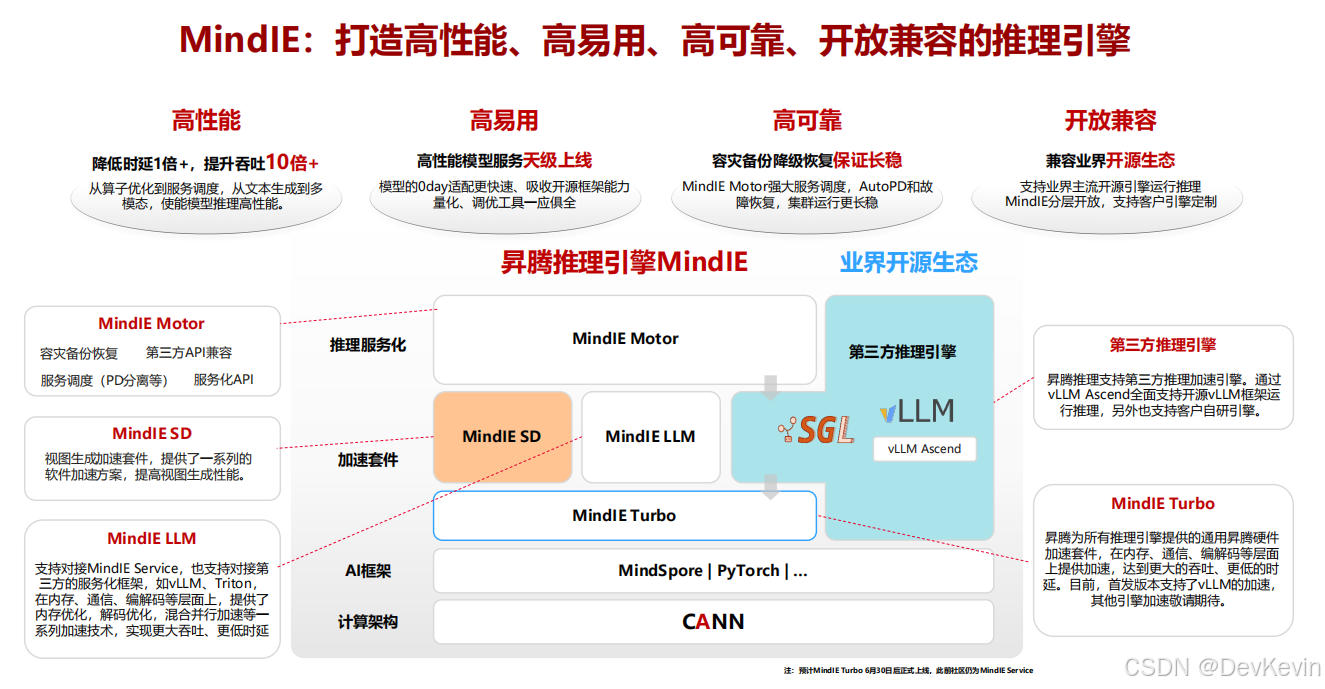
整个优化体系分为三层:
底层是CANN计算架构,这是昇腾NPU的"操作系统",负责算子调度、内存管理、通信原语等基础能力。
中间层是加速算法,包括高性能算子(RoPE、RMSNorm、FlashAttention)、并行策略(Ulysses、Ring、CFG)、近似算法(DiTCache、序列压缩)和量化技术(W8A8、FA量化)。
上层是易用性封装,提供ComfyUI插件、服务化API、自动性能调优工具等,让开发者不需要深入NPU底层就能用上优化技术。
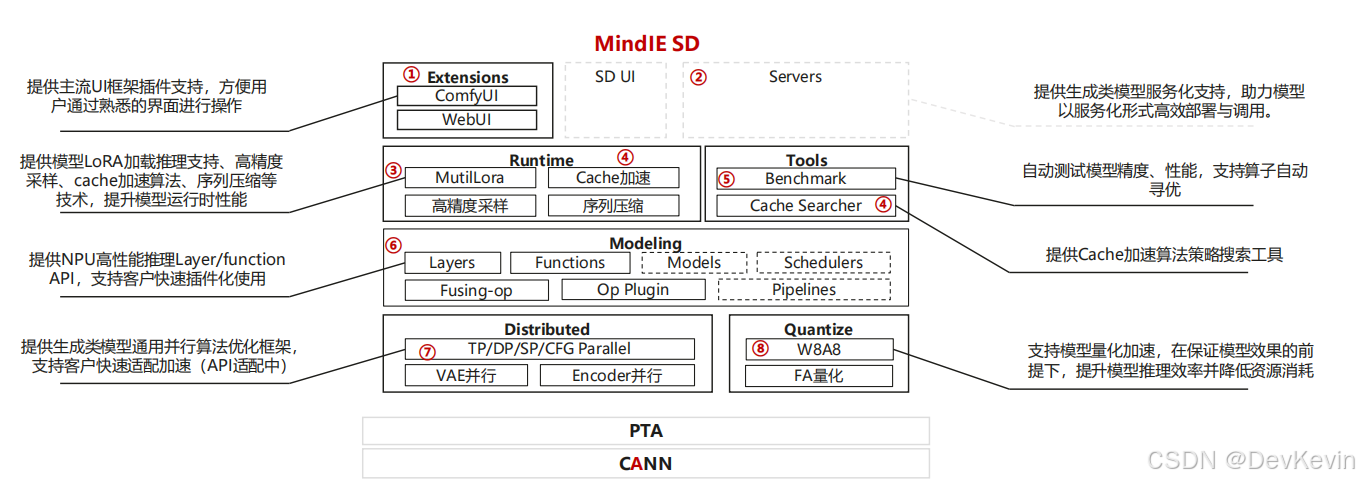
这种分层设计的好处是灵活度高。如果只是想快速上手,可以直接用提供的Pipeline接口;如果要深度定制,可以调用Layer层API自己组装;如果是算法研究者,甚至可以插入自定义的CANN算子。
4 部署Wan2.1模型的完整流程
接下来分享一下我部署Wan2.1-T2V-1.3B模型的过程。这个模型可以根据文本提示词生成832x480分辨率的5秒视频,参数量虽然只有1.3B,但生成质量已经相当不错。
- 环境准备
首先要安装昇腾的软件栈。这里要注意版本匹配关系——CANN、PyTorch、MindIE三者必须配套,否则会遇到各种奇怪的报错。
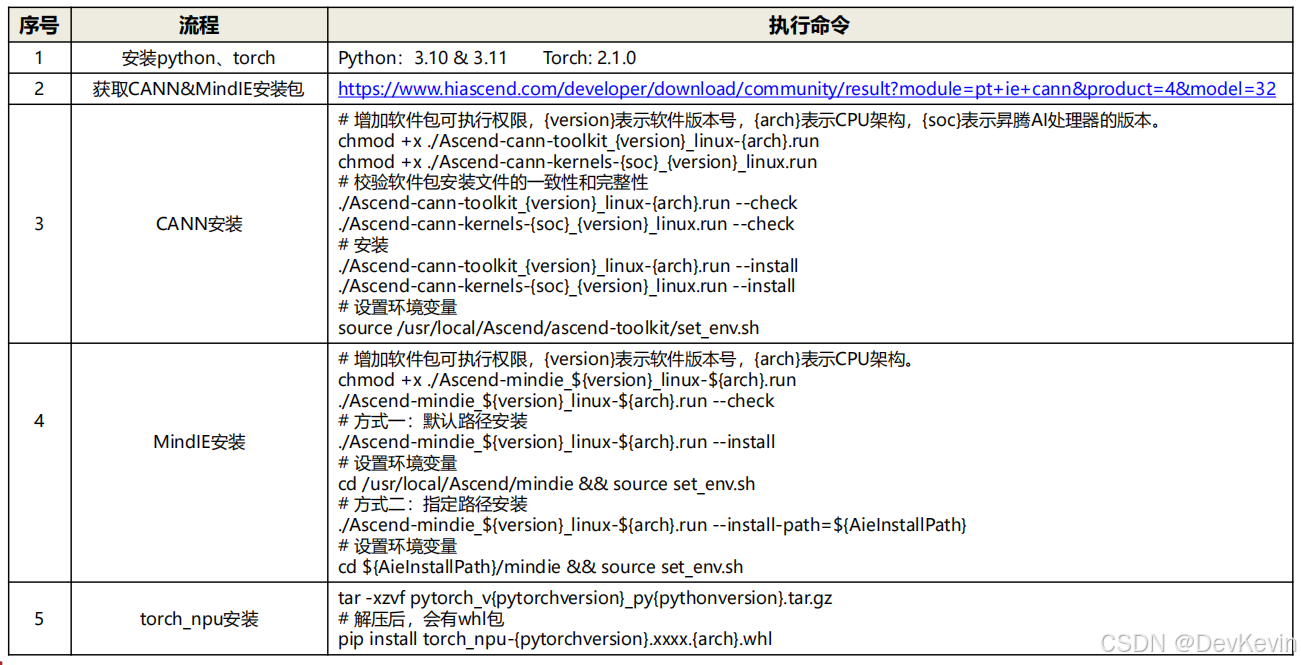
(1)安装CANN工具链
chmod +x Ascend-cann-toolkit_8.0.0_linux-aarch64.run
./Ascend-cann-toolkit_8.0.0_linux-aarch64.run --install
(2)安装算子库(根据芯片型号选择)
chmod +x Ascend-cann-kernels-910b_8.0.0_linux.run
./Ascend-cann-kernels-910b_8.0.0_linux.run --install
(3)设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
(4)安装MindIE
chmod +x Ascend-mindie_1.0.0_linux-aarch64.run
./Ascend-mindie_1.0.0_linux-aarch64.run --install
cd /usr/local/Ascend/mindie && source set_env.sh
(5)安装PyTorch NPU版本
pip install torch_npu-2.1.0-cp310-cp310-linux_aarch64.whl
如果遇到ImportError: cannot import name 'xxx' from 'torch_npu'这类错误,99%是版本不匹配导致的,务必检查CANN和torch_npu的对应关系。
- 下载模型权重
Wan2.1系列模型托管在HuggingFace和ModelScope上,国内访问ModelScope更快。这里以1.3B的文生视频模型为例:
(1)克隆模型代码仓库
git clone https://modelers.cn/MindIE/Wan2.1.git
cd Wan2.1
(2)安装Python依赖
pip install -r requirements.txt
(3)下载模型权重(约5GB)
(4)可以手动从https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B下载
(5)也可以用huggingface-cli工具
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir ./Wan2.1-T2V-1.3B
- 单卡基线推理
先跑一个最简单的版本,建立性能基线:
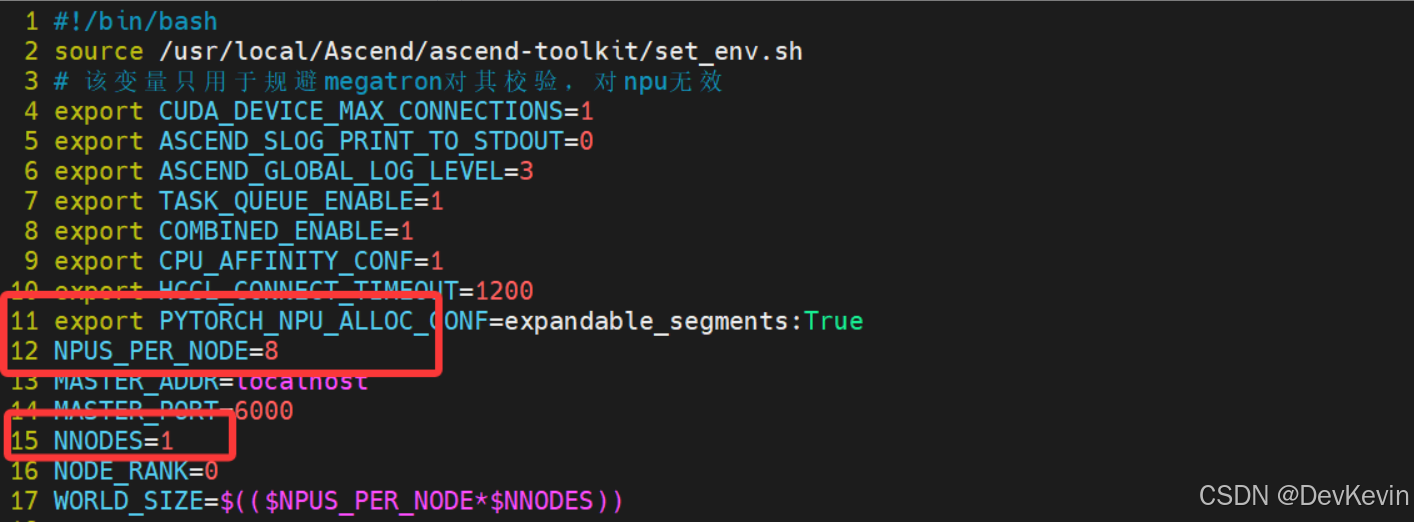
(1)设置环境变量
export PYTORCH_NPU_ALLOC_CONF='expandable_segments:True'
export TASK_QUEUE_ENABLE=2
export CPU_AFFINITY_CONF=1
export TOKENIZERS_PARALLELISM=false
(2)运行推理
python generate.py \
--task t2v-1.3B \
--size 832*480 \
--ckpt_dir ./Wan2.1-T2V-1.3B \
--sample_steps 50 \
--prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
--base_seed 0
这个命令会生成一段两只拟人化的猫在拳击台上打拳的视频。
在单卡910B上,这个过程大约需要120秒。虽然能跑通,但离实用还有距离。
- DiTCache加速,用存储换计算
观察推理过程的特征图,会发现一个有趣现象——连续的去噪步骤之间,DiT Block的激活值高度相似。
前20步变化较大,但20-47步的相似度能达到90%以上,这意味着大量计算是冗余的。
DiTCache的思路很直接:既然后面步骤的激活值和前一步差不多,那就直接复用前一步的cache,只在输入上加个小的偏置量来修正。这样就把完整的DiT计算变成了轻量级的偏置计算。
from mindiesd import CacheConfig, CacheAgent
# 配置AttentionCache策略
config = CacheConfig(
method="attention_cache",
blocks_count=len(transformer.single_blocks), # 对所有block启用cache
steps_count=50, # 总共50步
step_start=20, # 从第20步开始cache
step_interval=2, # 每2步强制重新计算一次
step_end=47 # 第47步停止cache
)
# 初始化CacheAgent并绑定到模型
cache_agent = CacheAgent(config)
for block in transformer.single_blocks:
block.cache = cache_agent
实际运行时,只需要在推理命令中加入cache参数:
python generate.py \
--task t2v-1.3B \
--size 832*480 \
--ckpt_dir ./Wan2.1-T2V-1.3B \
--sample_steps 50 \
--prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
--base_seed 0 \
--use_attentioncache \
--start_step 20 \
--attentioncache_interval 2 \
--end_step 47
这个优化让推理时间从120秒降到了75秒,提速60%!而且生成质量几乎无损——通过PSNR、SSIM等指标对比,差异小于0.5%。
cache策略需要针对不同模型调优。
step_start太早会影响质量,太晚收益不明显;step_interval太大可能导致累积误差,太小又失去了加速效果。
我的经验是先用默认参数跑,然后逐步调整观察质量曲线。
- 多卡并行,突破单卡瓶颈
对于更大的14B模型或更高分辨率(1280x720),单卡已经力不从心,这时就需要用到序列并行技术。
MindIE SD实现了Ulysses序列并行——把输入序列按长度切分到多张卡上,每张卡计算部分序列的全部注意力头,具体流程是:
(1)序列切分:假设4卡并行,序列长度10000,每张卡分到2500个token。
(2)All2All通信:每张卡和其他卡交换数据,变成拥有全部10000 token但只有1/4注意力头。
(3)并行Attention:每张卡独立计算自己负责的那几个头。
(4)再次All2All:把结果换回来,恢复到原始的序列分布。
(5)MLP计算:由于MLP是逐token计算,每张卡独立完成。
4卡Ulysses并行的操作:
torchrun --nproc_per_node=4 generate.py \
--task t2v-1.3B \
--size 832*480 \
--ckpt_dir ./Wan2.1-T2V-1.3B \
--ulysses_size 4 \
--prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
--base_seed 0 \
--use_attentioncache \
--start_step 20 \
--attentioncache_interval 2 \
--end_step 47
4卡并行把推理时间进一步压缩到25秒左右,相比单卡基线快了近5倍。通信开销被计算时间掩盖,扩展效率达到80%以上。
5 从算子层到系统层的优化经验
除了上面提到的Cache和并行,MindIE SD还有很多值得深挖的优化点:
(1) RoPE位置编码优化
旋转位置编码(RoPE)是DiT中每个Attention之前都要执行的操作,用于给token注入位置信息。
原始实现是用PyTorch算子拼接,涉及大量的split、concat、乘法操作:
def apply_rotary_emb(x, freqs_cis):
x_r, x_i = x.chunk(2, dim=-1)
freqs_cos, freqs_sin = freqs_cis
x_out_r = x_r * freqs_cos - x_i * freqs_sin
x_out_i = x_r * freqs_sin + x_i * freqs_cos
return torch.cat([x_out_r, x_out_i], dim=-1)
MindIE SD提供了融合算子rotary_position_embedding,把整个计算过程封装成一个kernel,减少了中间tensor的创建和读写:
from mindiesd import rotary_position_embedding
cos, sin = freqs_cis
query = rotary_position_embedding(
query, cos, sin,
rotated_mode="rotated_half",
head_first=False,
fused=True
)
这个优化看似微小,但在50步推理、28个DiT Block的累积下,能节省5-8%的总时间。
(2)Attention算子自动选择
不同的输入shape和硬件配置,最优的Attention实现是不同的。MindIE SD提供了attention_forward接口,支持运行时自动选择最优算子:
from mindiesd import attention_forward
hidden_states = attention_forward(
query, key, value,
attn_mask=attention_mask,
fused=True,
opt_mode="runtime"
)
在我的测试中,对于832x480的输入,自动选择的是prompt_flash_attn;而对于1280x720,则切换到了ascend_laser_attention,这个智能选择能额外带来10-15%的性能提升。
(3)CFG并行,充分利用生成特性
扩散模型通常使用Classifier-Free Guidance(CFG)来提升生成质量——同时生成有条件和无条件两个版本,然后加权组合。这两路计算是完全独立的,天然适合并行。
CFG并行配置:
torchrun --nproc_per_node=2 generate.py \
--cfg_size 2 \
--other_params...
CFG并行度固定为2,可以和Ulysses/Ring并行叠加使用。比如8卡可以配置为cfg_size=2, ulysses_size=4,效率最优。
从扩散模型的原理到昇腾平台的工程实践,这条路并不轻松。但当看到生成的视频从模糊到清晰、从卡顿到流畅,那种成就感是无可替代的。
MindIE SD这套工具链给了我很大启发——好的框架不应该只是封装算子,而要提供从理论到实践的完整路径。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)