
在昇腾平台上跑通DanceGRPO多模态强化学习的实战之旅
本文分享了将DanceGRPO框架迁移至昇腾平台并成功微调FLUX模型的全过程。DanceGRPO作为首个统一视觉生成强化学习框架,通过多图像生成、组内评分和策略优化三阶段提升生成质量。作者详细介绍了环境搭建、分阶段精度对齐策略(包括推理、Reward和训练阶段)以及关键性能优化点(如算子优化、通信调优等)。最终在昇腾平台实现了与GPU相当的生成效果,性能提升达25%。文章还总结了迁移过程中的常见
最近在做图像生成相关的项目时,偶然接触到了DanceGRPO这个多模态强化学习框架。作为一个在AI领域摸爬滚打的开发者,看到这个号称"首个统一视觉生成模型强化学习解决方案"的框架时,心里还是有点小激动的——毕竟能用强化学习来优化图像生成质量,这听起来就很酷。
今天就来分享一下我是如何在昇腾平台上完成DanceGRPO框架迁移,并成功跑通FLUX模型微调的全过程。这其中既有技术细节,也有不少实战经验,希望能给同样想尝试的朋友们一些参考。
一、初识DanceGRPO
在正式动手之前,我先花了点时间研究了DanceGRPO的原理,传统的GRPO(Group Relative Policy Optimization)主要用于语言模型优化,而DanceGRPO则把这套方法创新性地应用到了视觉生成领域。
它的核心思路其实挺直观的:对同一个文本提示词,让模型生成一组图像(默认12张),然后用reward模型给这些图像打分,接着通过强化学习让模型学会生成高分图像的策略。听起来简单,但实现起来涉及三个关键阶段:
推理阶段:模型对输入文本生成多张候选图像,这个过程会经历多步去噪迭代(FLUX模型默认16步),每一步都在逐渐将初始噪声转化为清晰的图像,就像雕刻家从石头中凿出雕像一样。
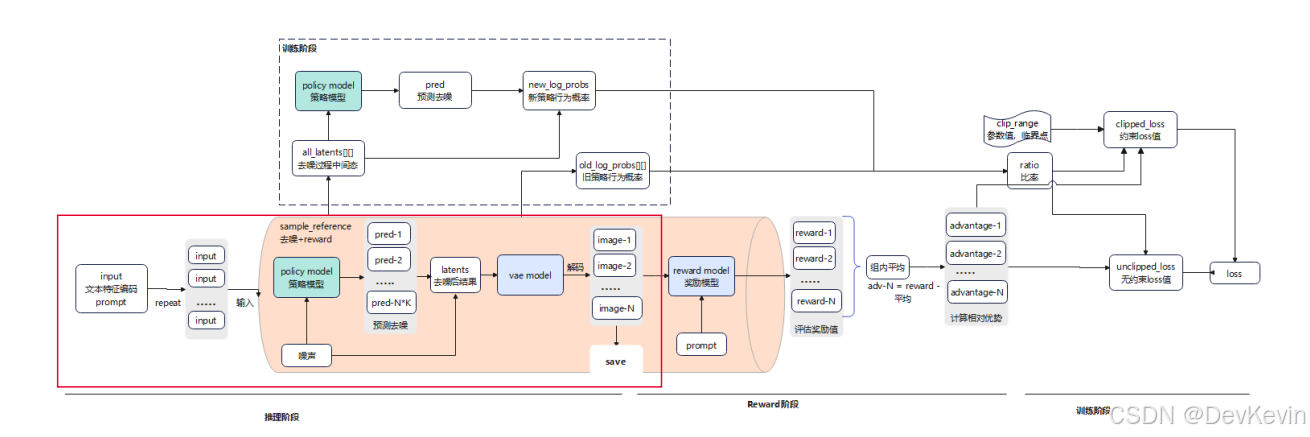
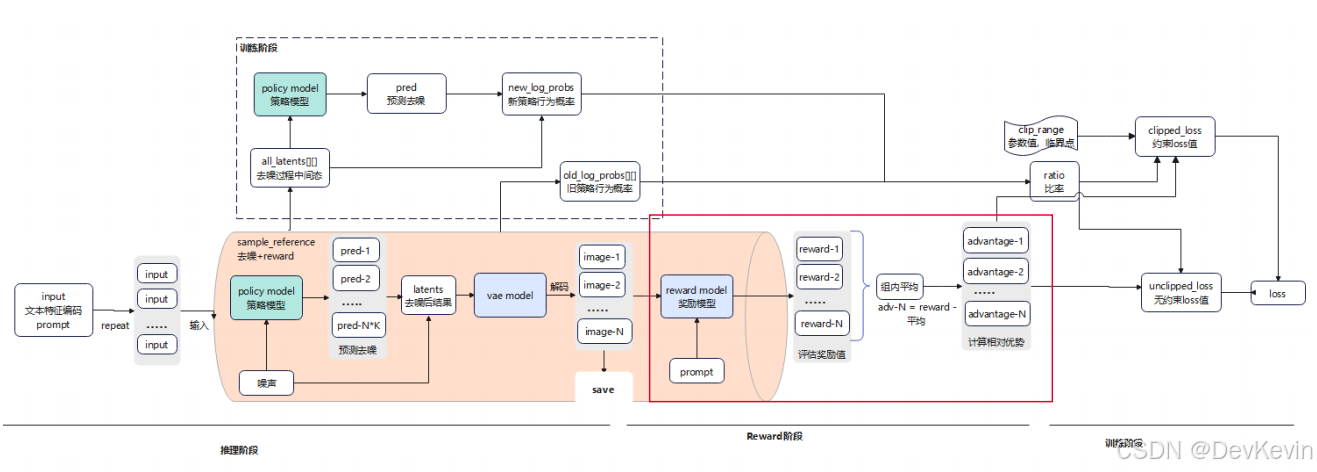
Reward阶段:使用CLIP等reward模型对生成的图像进行评分,计算每张图像与文本描述的匹配程度。这里有个巧妙的设计——不是简单地给绝对分数,而是计算组内的相对优势值(advantage),这样可以让模型明确知道哪些生成策略更好。
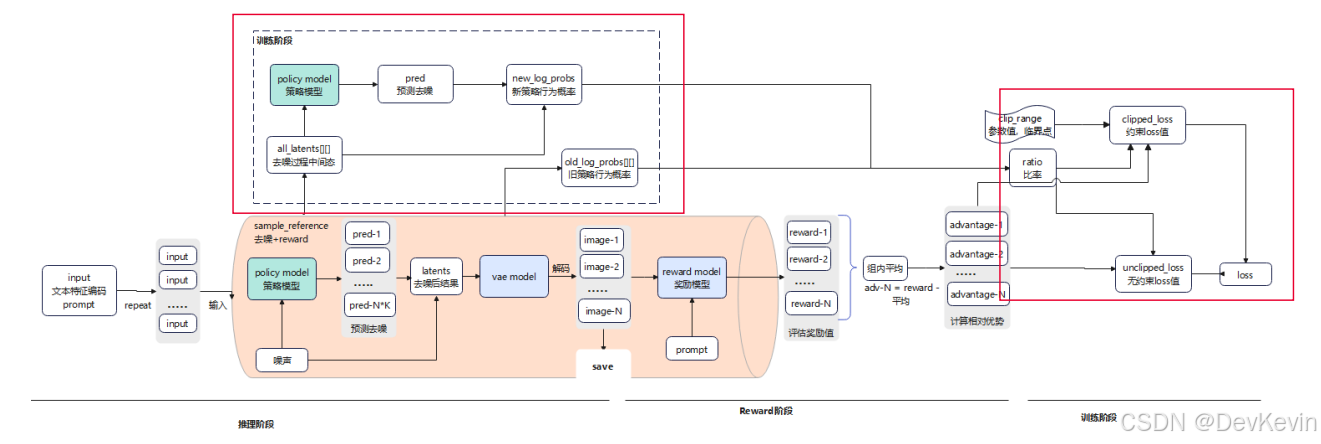
训练阶段:基于advantage值和策略比率(ratio)计算loss,更新模型参数。这里的ratio代表新旧策略下某个动作的概率比,通过限制ratio的变化范围,可以防止模型优化过度导致崩溃。
二、环境搭建
理论搞清楚后,我开始搭建环境,这里要特别注意版本配套关系,因为昇腾平台对软件栈的版本要求比较严格。
我采用的配置是:
- CANN 8.2.RC1
- PyTorch 2.6.0 + torch_npu 2.6.0
- Python 3.10
- Transformers 4.53.0
创建conda环境:
conda create -n dancegrpo python=3.10
conda activate dancegrpo
安装基础依赖:
pip install torch-2.6.0-cp310-cp310-manylinux_2_28_aarch64.whl
pip install torch_npu-2.6.0-cp310-cp310-manylinux_2_28_aarch64.whl
安装MindSpeed加速库:
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
pip install -e .
安装过程中可能会遇到一些依赖库冲突,建议使用pip install --no-deps先跳过依赖检查,后续再逐个补齐缺失的包。
由于DanceGRPO仓库没有使用懒加载优化,很多依赖库在实际运行中并不会用到,可以选择性安装来节省时间。
三、精度对齐
环境搭建完成后,接下来就是精度对齐——这是整个迁移过程中最核心也最耗时的环节。对于强化学习这种涉及多模型、多流程融合的训练方式,精度对齐不能只看最终loss,而要关注每个阶段的数据流。
我采用的策略是分阶段对齐,需要把所有随机因素固定住:
from msprobe.pytorch import seed_all
# 固定全局随机性
seed_all(mode=True)
# 固定通信随机性
export HCCL_DETERMINISTIC=TRUE
# 固定数据加载顺序
sampler = DistributedSampler(
train_dataset,
rank=rank,
num_replicas=world_size,
shuffle=False, # 关键:关闭shuffle
seed=args.sampler_seed
)
# 固定初始噪声(在CPU上生成后传到NPU)
if args.init_same_noise:
input_latents = torch.randn(
(1, IN_CHANNELS, latent_h, latent_w),
dtype=torch.bfloat16,
device="cpu"
).to(device)
推理阶段的对齐比较直观——直接对比生成的图像。
我在代码中加入了保存逻辑,每个训练step都保存GPU和NPU生成的所有图像:
# 保存每个generation的图像用于对比
for gen_idx in range(args.num_generations):
save_path = f"./comparison/step_{step}_gen_{gen_idx}_rank_{rank}.png"
save_image(images[gen_idx], save_path)
通过肉眼对比,我发现初期NPU和GPU生成的图像基本一致,这说明推理阶段的迁移是成功的。
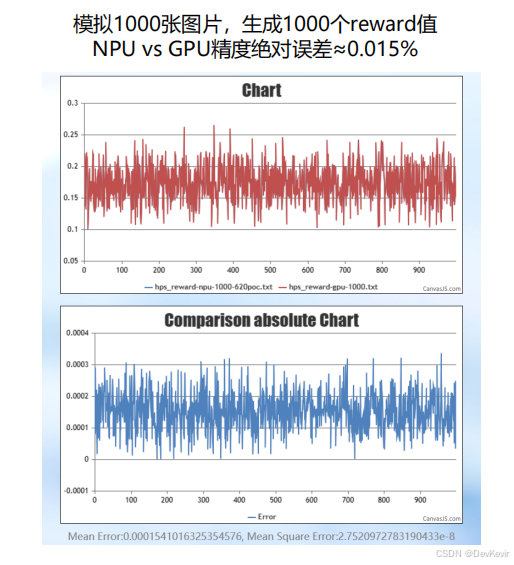
Reward阶段我采用了单独测试的方法——把CLIP模型抽出来,模拟1000张图像的打分过程:
for step in range(1, 1001):
image = torch.load(f"./save/images/image_{step}_{rank}.pt")
text = torch.load(f"./save/texts/text_{step}_{rank}.pt")
with torch.no_grad():
outputs = reward_model(image, text)
image_features = outputs["image_features"]
text_features = outputs["text_features"]
logits_per_image = image_features @ text_features.T
hps_score = torch.diagonal(logits_per_image)
最终统计显示,NPU vs GPU的reward值绝对误差约为0.015%,完全在可接受范围内。
训练阶段的对齐需要关注多个维度:
- Loss曲线:虽然生成模型的loss绝对值很小(数量级在1e-4左右),但曲线趋势应该一致。
- Reward scores:长训24小时后,200步的误差应在5%以内。
- 生成效果:固定随机性,训练相同步数后,使用相同prompt推理,对比生成图像。
我在实际测试中发现,训练120步后,NPU和GPU生成的图像在整体构图、细节呈现上都非常接近,只有极细微的差异(比如某些纹理的随机性),这证明精度对齐是成功的。
精度对齐后,接下来就是性能优化了。初始开箱性能是419秒/step,经过一系列优化后提升到315秒/step,提升幅度约25%。
这里分享几个关键优化点:
1. Repeat_interleave算子优化
FLUX模型的ROPE位置编码部分会调用repeat_interleave算子,但昇腾对非首轴repeat的支持不够高效,会前后调用Transpose导致耗时飙升。
优化方法很简单,修改diffusers/models/embeddings.py:
# 原代码:在dim=0上repeat,效率低
freqs = freqs.repeat_interleave(2, dim=0)
# 优化后:先unsqueeze再reshape,避免Transpose
freqs = freqs.unsqueeze(-1).repeat(1, 2).reshape(-1)
这一改动带来了惊人的收益:A+X性能从419s提升到335s,A+K从395s提升到365s。
2. 通信带宽调优
通过调整HCCL_BUFFSIZE增大通信缓冲区,可以提升AllGather和ReduceScatter的效率:
export HCCL_BUFFSIZE=800 # 默认200M,增大到800M
这个优化使A+K性能从365s提升到352s,效果立竿见影。
3. FSDP前反向预取
FSDP(Fully Sharded Data Parallel)的一个痛点是通信和计算串行执行。
启用反向预取后,可以在当前ReduceScatter之前发起下一个AllGather,实现通信计算掩盖:
from torch.distributed.fsdp import BackwardPrefetch
fsdp_kwargs = {
"backward_prefetch": BackwardPrefetch.BACKWARD_PRE,
"forward_prefetch": True,
}
这个优化使A+X性能从335s提升到325s,收益主要来自前向预取,因为模型大部分时间都在走前向(推理阶段+GRPO step)。
4. 推理阶段batch size增大
昇腾硬件特性适合大kernel计算,我尝试将推理阶段的batch size从1增加到4(一次前向生成4张图):
# 原代码:逐个generation推理
for gen_idx in range(args.num_generations):
latents = pipeline(prompt, ...)
# 优化后:批量推理
batch_size = 4
for batch_start in range(0, args.num_generations, batch_size):
latents = pipeline(prompt, batch_size=batch_size, ...)
这个改动使A+X性能从325s提升到315s,最终突破了性能瓶颈,batch size不是越大越好,需要根据显存容量和模型特性权衡。
我测试发现batch=4是当前配置下的最优解,再增大反而会因为显存不足导致性能下降。
四、实战效果
经过精度对齐和性能优化,我在昇腾平台上成功跑通了FLUX模型的GRPO微调。
下面是一些实测数据:
精度方面:
- 推理阶段生成图像与GPU基本一致
- Reward值误差0.015%
- 训练200步后,下游任务推理效果主观对齐
性能方面:
- A+X平台:419s/step → 315s/step(提升25%)
- A+K平台:395s/step → 352s/step(提升11%)
- 与业界GPU标卡相比,A+X达到1.0x,A+K达到0.8x
效果方面:
使用相同prompt"An old looking bathroom with a sink and towel holder",对比初始权重、120步权重、200步权重生成的图像,可以明显看到细节质量的提升——120步后浴室的瓷砖纹理更清晰,200步后光影效果更自然。
回顾整个迁移过程,有几个坑值得特别提醒:
- 三方库兼容性:部分依赖库(如flashattn)在NPU上不支持,但如果模型实际没调用相关接口,可以注释掉导入语句规避。
- 精度对齐要分阶段:不要一上来就跑完整流程,推理、reward、训练三个阶段要逐个击破。
- Cast算子泛滥:初始版本中cast算子占总耗时34%,需要仔细分析来源并消除冗余转换。
- 保存操作要异步:训练过程中保存图像如果用同步方式,会导致NPU空闲,改用异步保存可节省3秒/step。
从环境搭建到精度对齐,再到性能优化,整个迁移过程大概花了我一周时间。虽然中间遇到不少挑战,但看到最终在昇腾平台上跑出和GPU相当的效果时,那种成就感还是很爽的。
DanceGRPO作为视觉生成领域的强化学习框架,确实有其独到之处——统一的算法框架、灵活的模型支持、完善的评估体系。
而昇腾平台在算力、生态工具链方面也在快速成熟,两者结合完全可以胜任工业级的多模态生成任务。
如果你也在做类似的工作,希望这篇文章能给你一些启发。记住,迁移适配没有捷径,唯有步步为营、逐个击破。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)