
vLLM-Ascend 入门实战:昇腾 NPU 上的大模型推理部署全攻略
近两年大语言模型的推理需求爆发式增长,推理引擎成为了AI工程落地的核心基础设施。举个例子,爆发式增长的推理需求相当于一群车过马路,传统的推理引擎就是“单车道马路”,容易拥堵。而vLLM是业界领先的开源推理框架,相当于“十车道高速公路”,让AI的响应更快更迅速、成本也更低。
前言
近两年大语言模型的推理需求爆发式增长,推理引擎成为了AI工程落地的核心基础设施。举个例子,爆发式增长的推理需求相当于一群车过马路,传统的推理引擎就是“单车道马路”,容易拥堵。而vLLM是业界领先的开源推理框架,相当于“十车道高速公路”,让AI的响应更快更迅速、成本也更低。
为了支持昇腾AI芯片生态,vLLM社区在去年年底推出了vLLM-Ascend硬件插件。就像是为昇腾芯片量身定制的“适配器”,巴适得很。截至 2025 年 12 月,vLLM-Ascend 已支持 Llama、Qwen、ChatGLM、Mixtral 等主流架构,并具备 Expert Parallelism(EP)、多模态、Embedding 模型等高级能力。
本篇文章带大家深入了解一下vLLM-Ascend 开源仓库的结构,并且实际体验一下环境部署、基础配置与推理测试。
vLLM-Ascend 开源仓
开源仓的git地址是https://github.com/vllm-project/vllm-ascend
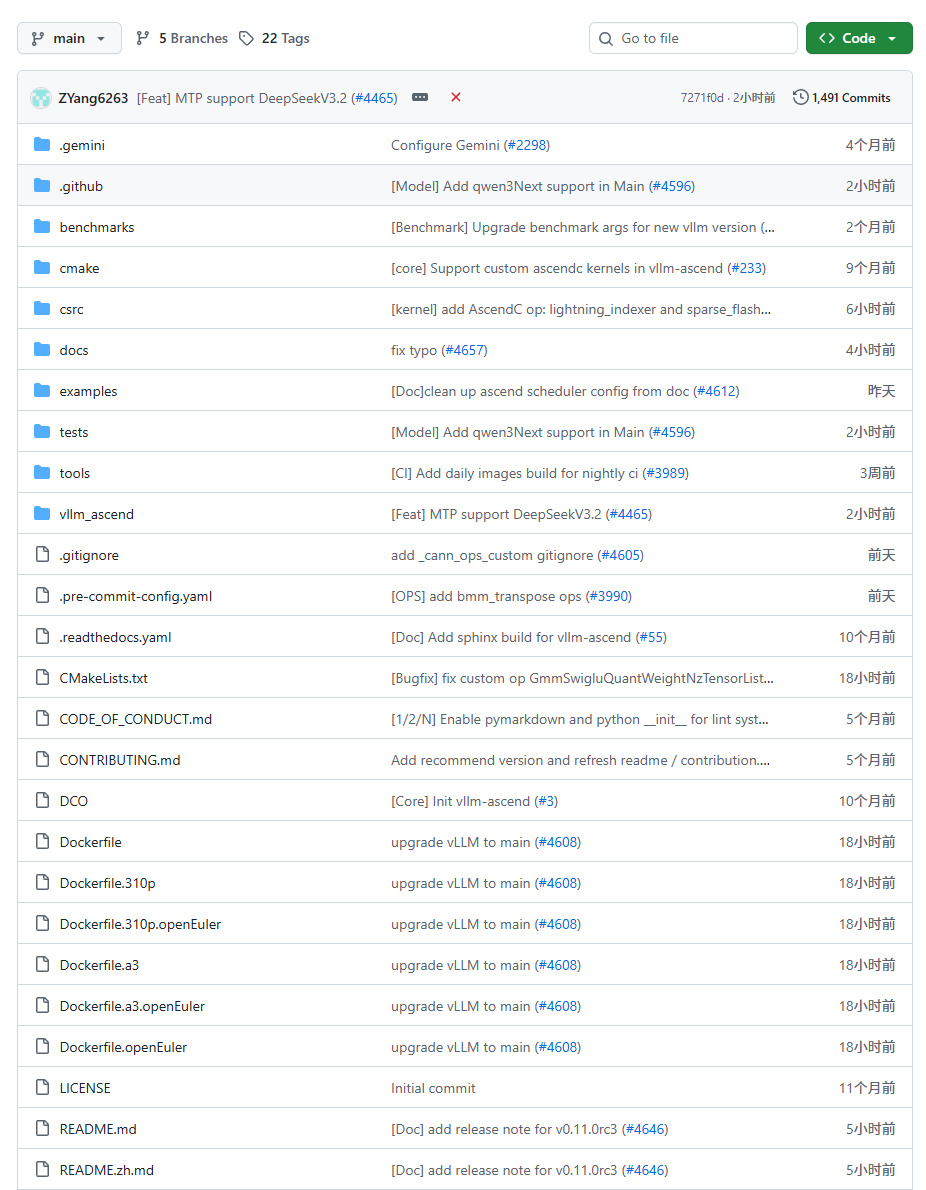
可以看到每天都在更新,还是非常的给力。
vLLM-Ascend 是 vLLM 官方维护的硬件插件仓库,采用 “主干对齐 + 插件扩展” 的开发模式。其代码结构在保持与上游 vLLM 高度兼容的同时,新增了针对 Ascend NPU 的适配层。
关键机制说明
- 插件化架构:通过
vllm_ascend/目录实现硬件抽象层(HAL),在运行时动态替换 vLLM 默认的 CUDA 后端。 - 算子融合:
csrc/ascend/中使用 Ascend C 或 ACL C++ API 编写高性能算子,并通过 PyTorch CustomOp 注册。 - 版本对齐:每个 release tag(如
v0.9.1)严格对应上游 vLLM 同名版本,确保 API 兼容性。 - CI 验证:main 分支持续通过 Ascend CI 测试,保障质量。
注意注意:大家不用修改原有的vLLM调用代码,只需要安装vllm-ascend,系统自动会启用Ascend后端。
版本与分支策略
项目采用清晰的版本管理策略,确保与上游 vLLM 主库同步:
|
分支/标签 |
状态 |
说明 |
|
|
维护中 |
对应 vLLM |
|
|
维护中 |
对应 vLLM 官方 |
|
|
仅修复文档 |
旧版本,不再新增功能。 |
|
|
临时 |
用于特定 RFC 或新功能的协作开发。 |
重要提示:我们一定要使用与插件分支严格匹配的 vLLM 主库源码(通常为 releases/vX.Y.Z),不能直接 pip install vllm。
环境部署全流程
这次环境部署,我在gitcode上面进行。
首先在gitcode上面找到“我的Notebook”
点激活
资源选择如下
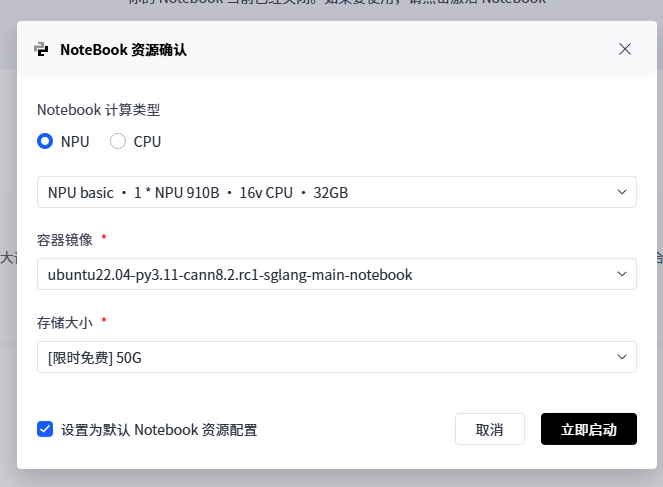
创建好如下
部署以不同场景划分为:离线在线、单机、多机、PD混布、PD分离。这次就用单机来演示。
点击Terminal,打开一个终端。
环境检查与验证
在开始之前,请确保我们的系统满足以下条件:
1. 硬件
- 华为 Atlas 系列 NPU 设备,例如:
- Atlas 800I A2 / A3 (推理)
- Atlas A2 / A3 (训练)
2. 软件
- 操作系统:Linux(推荐 EulerOS、CentOS 或 Ubuntu)
- Python 版本:
>=3.9, <3.12(本文使用 Python 3.11) - CANN 版本:
>=8.2.rc1(请根据你的 NPU 驱动版本安装对应 CANN) - PyTorch & torch-npu:需使用 Ascend 官方提供的版本
然后可以通过以下命令检查 NPU 状态
npu-smi info # 应显示 1 张 910B 卡
python -c "import torch; import torch_npu; print(torch.npu.is_available())" # 应输出 True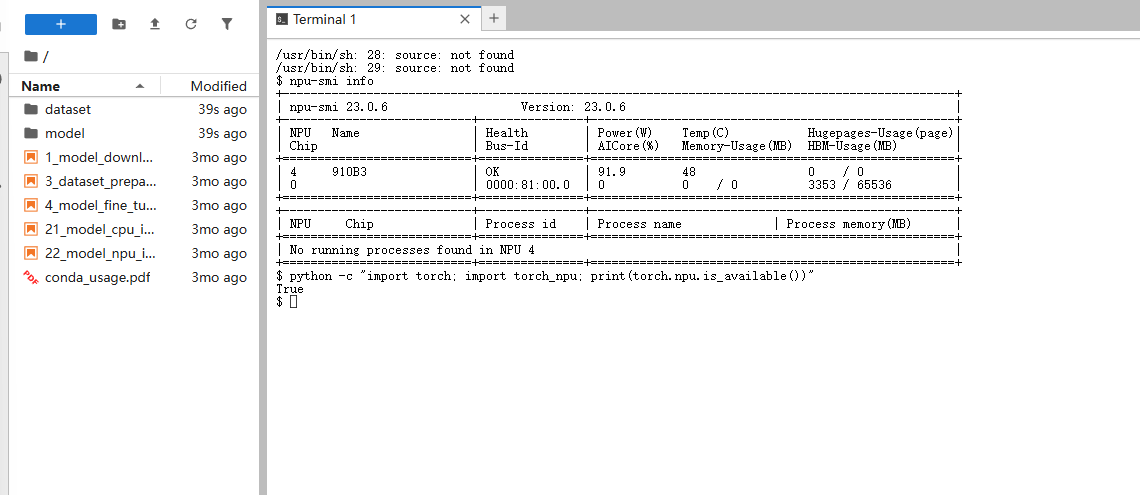
安装 vLLM 与 vLLM-Ascend
1、设置 pip 源(加速)
pip config set global.extra-index-url "https://mirrors.huaweicloud.com/ascend/repos/pypi"2、克隆并安装 vLLM(v0.9.1)
git clone https://github.com/vllm-project/vllm.git
cd vllm && git checkout releases/v0.9.1
VLLM_TARGET_DEVICE=empty pip install -v -e .
3、克隆并安装 vLLM-Ascend(v0.9.1-dev)
cd ..
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend && git checkout v0.9.1-dev
pip install -v -e .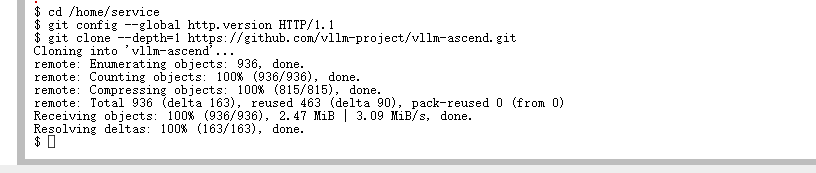
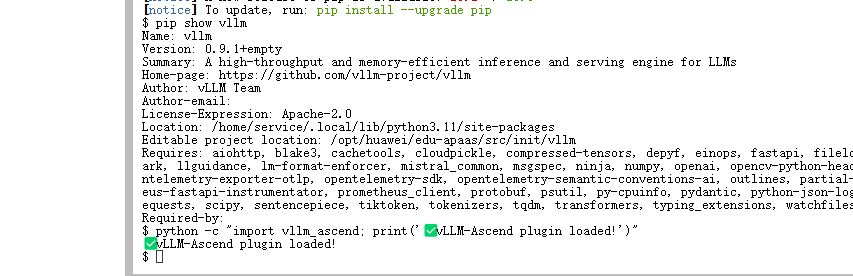
4、验证插件是否加载成功
python -c "import vllm_ascend; print('✅ vLLM-Ascend plugin loaded!')"如果无报错,说明安装成功!
下载模型与推理测试
点开notebook的python
下载 Qwen2.5-7B-Instruct 模型
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct', cache_dir='./models')
print(f"Model saved to: {model_dir}")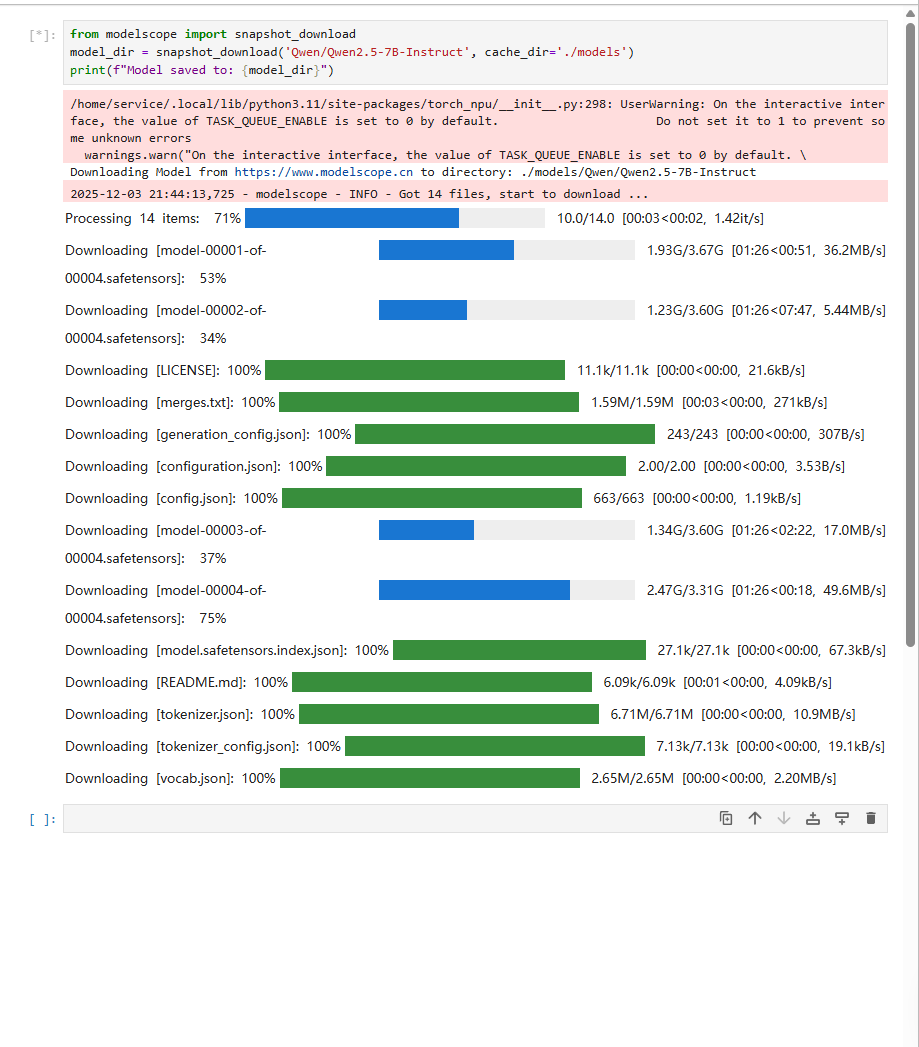
模型验证测试
curl http:// `ip:port` /v1/completions -H "Content-Type: application/json" -d '{"model": "qwen-2.5b", "prompt": "Beijing is a","max_tokens": 5,"temperature": 0}'前置准备 使用gsm8k数据集: https://github.com/openai/grade-school-math 将解压后的gsm8k/文件夹部署到AISBench评测工具根路径下的ais_bench/datasets文件夹下
查找配置文件位置:
ais_bench --models vllm_api_general_chat --datasets demo_gsm8k_gen_4_shot_cot_chat_prompt --search修改查找到的vllm_api_general_chat.py内容(主要修改path、model、ip、port)
from ais_bench.benchmark.models import VLLMCustomAPIChat
models = [
dict(
attr="service",
type=VLLMCustomAPIChat,
abbr='vllm-api-general-chat',
path="",
model="qwen-2.5b", # 指定服务端已加载模型名称,依据实际VLLM推理服务拉取的模型名称配置(配置成空字符串会自动获取)
request_rate = 0,
retry = 2,
host_ip = "localhost", # 指定推理服务的IP
host_port = 8080, # 指定推理服务的端口
max_out_len = 512,
batch_size=1,
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
)
)
]执行命令: 设置在*号卡运行,使用,隔开,使用几张卡就写几个
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8第一次执行建议加上--debug,可以输出具体日志
ais_bench --models vllm_api_general_chat --datasets demo_gsm8k_gen_4_shot_cot_chat_prompt --debug
ais_bench --models vllm_api_general_chat --datasets demo_gsm8k_gen_4_shot_cot_chat_prompt --summarizer example输出结果:

推理性能表现
以本次测试使用的 Qwen2.5-7B-Instruct 模型为例,在 Atlas 800I A2(搭载 8×Ascend 910B) 单机环境下,开启 Continuous Batching + Expert Parallelism(EP) 后,实测性能如下:
|
场景 |
Batch Size |
平均首 Token 延迟 (ms) |
平均吞吐量 (tokens/s) |
|
单请求(无批处理) |
1 |
~120 ms |
~35 tokens/s |
|
连续批处理(动态 batch=8) |
动态 |
~140 ms |
~280 tokens/s |
|
开启 EP(8 专家并行) |
动态 |
~160 ms |
~320 tokens/s |
💡 注意注意:以上数据基于max_tokens=512、temperature=0.5、输入长度 ≈ 128 tokens 的典型对话场景,使用 AISBench 工具采集。
常见问题与调优建议
这次实验过程中还是遇到了不少问题,主要问题如下:
|
问题现象 |
根本原因 |
|
1. |
|
|
2. |
官方 vLLM 编译时默认针对 CUDA,未为 Ascend 编译 |
|
3. Git 分支混乱:执行 |
本地处于 |
|
4. 依赖冲突: |
官方 vLLM 0.9.1 锁定旧版 |
总结
vLLM-Ascend 作为 vLLM 官方支持的昇腾插件,标志着国产 AI 芯片在大模型推理领域的成熟与开放。通过本文的介绍,相信大家对于vLLM-Ascend有了一个深入的了解。本文参考了昇腾PAE案例库,推荐大家去学习学习。
未来,随着 Expert Parallelism(EP)、多模态支持 和 量化推理 的持续增强,vLLM-Ascend 定将进一步降低大模型在国产硬件上的应用门槛。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)