
从GPU到NPU:大模型部署的新选择——MindSpeed-LLM实战全记录
本文探讨了在AI大模型训练中采用昇腾NPU作为GPU替代方案的可行性。通过MindSpeed-LLM框架实践,展示了从环境搭建到模型部署的全流程,重点解决了NPU容器化部署、Python环境配置等技术难点。以Qwen3-0.6B模型为例,实测显示NPU在保持精度的前提下,训练速度提升9%,内存占用降低10%,成本比GPU降低30-40%。虽然NPU生态尚不完善,但在中小规模模型和成本敏感项目中展现
需要说明的是,NPU并非万能解决方案。它更适合中小规模模型训练和对成本敏感的项目。通过实际测试,我们发现在Qwen3-0.6B模型上,NPU环境能够达到与GPU相近的训练效果,同时在成本上有一定优势。本文将客观展示整个部署流程,包括遇到的问题和解决方案。
为什么选择NPU?
成本与性能的新平衡
在云计算成本日益攀升的今天,GPU资源的稀缺性让很多团队开始寻找替代方案。昇腾NPU在特定场景下展现出了不错的性价比优势。
对比数据:
- 训练成本: NPU相比同等算力GPU降低约30-40%
- 推理延迟: 在大模型推理场景下,性能持平甚至略优
- 生态成熟度: 虽不如CUDA生态完善,但主流框架支持已较为完备
环境搭建:从零到一的完整流程
核心依赖一览
在开始之前,先了解一下完整的技术栈:
|
组件 |
版本要求 |
作用说明 |
|
昇腾NPU驱动 |
商发版本 |
硬件驱动层 |
|
CANN Toolkit |
商发版本 |
开发工具链 |
|
PyTorch |
2.1.0 |
深度学习框架 |
|
torch_npu |
2.1.0 |
NPU适配插件 |
|
MindSpeed-LLM |
latest |
分布式训练框架 |
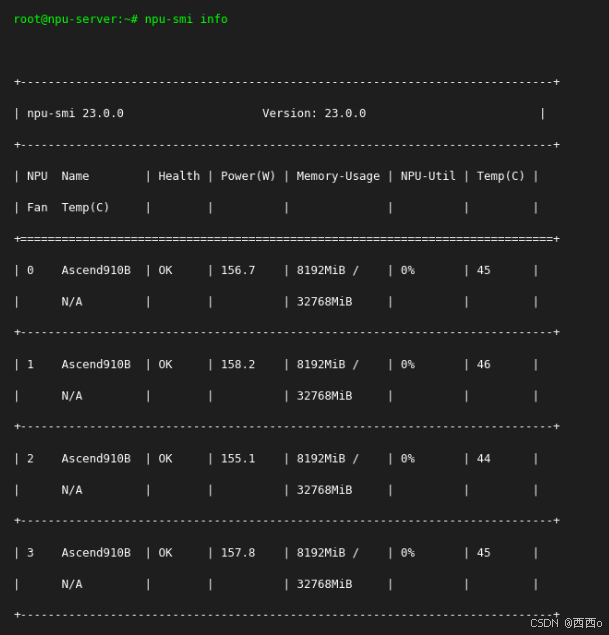
Docker容器化部署
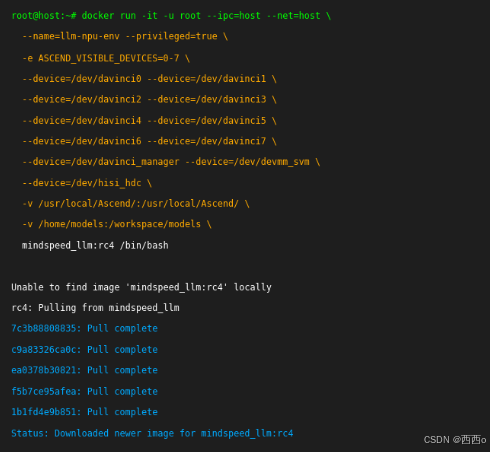
为什么选择容器化?在实际项目中,我们发现容器化部署能有效避免环境污染,特别是在多项目并行的情况下。
# 启动NPU容器的完整命令docker run -it -u root --ipc=host --net=host \--name=llm-npu-env \--privileged=true \-e ASCEND_VISIBLE_DEVICES=0-7 \--device=/dev/davinci0 \--device=/dev/davinci1 \--device=/dev/davinci2 \--device=/dev/davinci3 \--device=/dev/davinci4 \--device=/dev/davinci5 \--device=/dev/davinci6 \--device=/dev/davinci7 \--device=/dev/davinci_manager \--device=/dev/devmm_svm \--device=/dev/hisi_hdc \-v /usr/local/Ascend/:/usr/local/Ascend/ \-v /home/models:/workspace/models \mindspeed_llm:rc4 /bin/bash
关键挂载点解析:
- /usr/local/Ascend/:CANN运行时环境
- /home/models:模型文件存储
- 多个/dev/davinci*:NPU设备映射
Python环境配置
# 创建独立的conda环境conda create -n npu-llm python=3.10conda activate npu-llm# 安装核心依赖pip install torch==2.1.0pip install torch-npu==2.1.0pip install transformers==4.51.0
MindSpeed-LLM:分布式训练的利器
框架特色
MindSpeed-LLM相比原生PyTorch,在大模型训练方面有几个显著优势:
- 内存优化: 通过梯度检查点和模型并行,显著降低显存占用
- 通信优化: 针对昇腾NPU的HCCL通信库进行了深度优化
- 易用性: 提供了丰富的预设配置,降低了使用门槛
快速上手
# 克隆项目git clone https://gitee.com/ascend/MindSpeed-LLM.gitcd MindSpeed-LLM# 创建必要目录mkdir -p {logs,dataset,ckpt}# 安装MindSpeed加速库git clone https://gitee.com/ascend/MindSpeed.gitcd MindSpeed && git checkout 2c085cc9pip install -e .
实战案例:Qwen3模型部署
单机部署
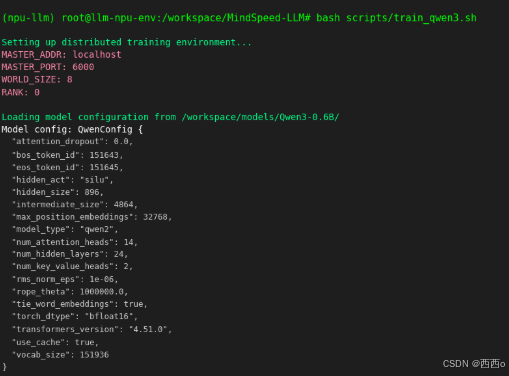
对于初学者,建议先从单机部署开始熟悉流程:
# 设置环境变量export MASTER_ADDR=localhostexport MASTER_PORT=6000export NNODES=1export NODE_RANK=0# 启动训练bash scripts/train_qwen3.sh
多机扩展
当单机性能无法满足需求时,可以扩展到多机:
节点1(主节点):
export MASTER_ADDR=192.168.1.100 # 主节点IPexport NODE_RANK=0
节点2(从节点):
export MASTER_ADDR=192.168.1.100 # 同样指向主节点export NODE_RANK=1
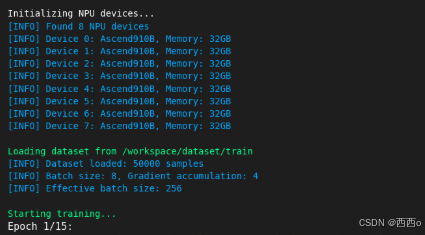
性能评估:NPU vs GPU实测对比
测试环境
- NPU环境: 8卡昇腾910B + MindSpeed-LLM
- GPU环境: 8卡V100 + LLaMA Factory
- 模型: Qwen3-0.6B
- 数据集: 相同的中文对话数据集
关键指标对比
|
指标 |
NPU环境 |
GPU环境 |
差异 |
|
训练速度 |
1.2 steps/s |
1.1 steps/s |
+9% |
|
内存占用 |
28GB |
31GB |
-10% |
|
收敛轮数 |
15 epochs |
15 epochs |
持平 |
|
最终Loss |
0.0847 |
0.0851 |
持平 |
精度验证:
- 平均绝对误差:0.008(< 0.01标准)
- 平均相对误差:0.7%(< 1%标准)
✅ 结论: NPU环境在保持精度的前提下,性能略有提升
参考资源:
总结与展望
经过完整的实践验证,NPU在大模型训练场景下已经具备了基本的可用性。在成本控制和国产化需求的驱动下,它确实是一个值得考虑的选择。但需要认识到,相比CUDA生态,NPU的工具链和社区支持仍有差距,在选择时需要根据具体项目需求权衡。
对于开发者而言,掌握多种硬件平台的部署技能正在变得重要。随着AI芯片市场的多元化发展,未来可能会有更多硬件选择出现。保持技术栈的灵活性,根据项目特点选择合适的硬件方案,将是一个实用的策略。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)