
Ascend C Tiling维度切分策略全解 - Block、Core与硬件单元的映射艺术
摘要:昇腾NPU算子开发中,Tiling设计是资源分配的"政治经济学",需要在并行度、计算密度和资源开销三者间找到平衡。本文通过真实案例,从Block切分、AICore映射到硬件单元调度三个层面,剖析如何设计自适应Tiling策略。特别针对非对称卷积,展示了从±50%性能波动优化到±5%以内的实战经验,包括动态Tile决策器设计、条件核函数实现和尾块优化技巧。文章还总结了Cac
目录
🧠 第一部分 Tiling设计的核心悖论:并行度与计算密度的“二人转”
⚙️ 第二部分 Block维度切分:从“一维面条”到“三维魔方”
🗺️ 第三部分 AI Core映射:把“任务单”贴到正确的“工作台”上
📝 5.3 设计检查清单(Design Review Checklist)
📄 摘要
干了多年昇腾算子开发,我悟透一件事:Tiling切分不是数学计算,是资源分配的“政治经济学”。你这儿多分一块,那儿就少一份资源。本文不讲PPT里那些定义,我直接带你钻进NPU的“五脏六腑”,看看一块计算任务怎么被解剖、分配、消化。核心就三条:第一,Block切分是“面子”,决定你能启动多少并行任务;第二,AI Core映射是“里子”,决定了这些任务真能挤进多少物理核心去跑;第三,硬件单元(Cube/Vector)的喂养是“根子”,数据喂得不及时、不对胃口,再多的核心也得饿肚子。我会用一个真实的可变尺寸非对称卷积案例,展示如何从“一锅粥”式的简单分块,进化到精细的、能动态适应输入形状的资源调度策略,最终在百种不同尺寸下,让算子性能波动从±50%收敛到±5%以内。
🧠 第一部分 Tiling设计的核心悖论:并行度与计算密度的“二人转”
所有新手都会问:“Tiling尺寸到底设多少?”官方答案往往是“根据硬件资源调整”。这话没错,但跟没说一样。我拆开了讲:Tiling设计,本质是在解一个三元悖论。
你的目标有三个:
-
高并行度(Parallelism):把任务切得足够细碎,生出海量小任务(Blocks),让成千上万个AI Core计算单元都有活干,别闲着。
-
高计算密度(Compute Intensity):每个小任务(Block)自己要足够“饱满”,计算量要大,这样才能掩盖从全局内存(HBM)搬运数据的巨大延迟。这叫“用计算换带宽”。
-
低资源开销(Resource Overhead):每个小任务不能太“贪”,占用太多片上寄存器(Register)或统一缓存(UB)。否则,硬件调度不动,或者会发生寄存器溢出(Spill),把数据挤到慢速内存,得不偿失。
这三个目标,是互斥的!
-
你想要并行度高?那就多切点,把Block切小。但Block一小,计算密度就低了,变成“数据搬运工”,算力闲置。
-
你想要计算密度高?那就把Block切大。但Block一大,资源开销就上去了,可能一个AI Core都塞不下,更别提并行度了。
-
你资源无限?对不起,芯片物理限制就摆在那儿。
所以,Tiling设计从来不是找“最优解”,而是找当前约束下的“最不坏”的权衡点。下面这个图,就是你这个“架构师”每天在脑子里反复推演的权衡沙盘:
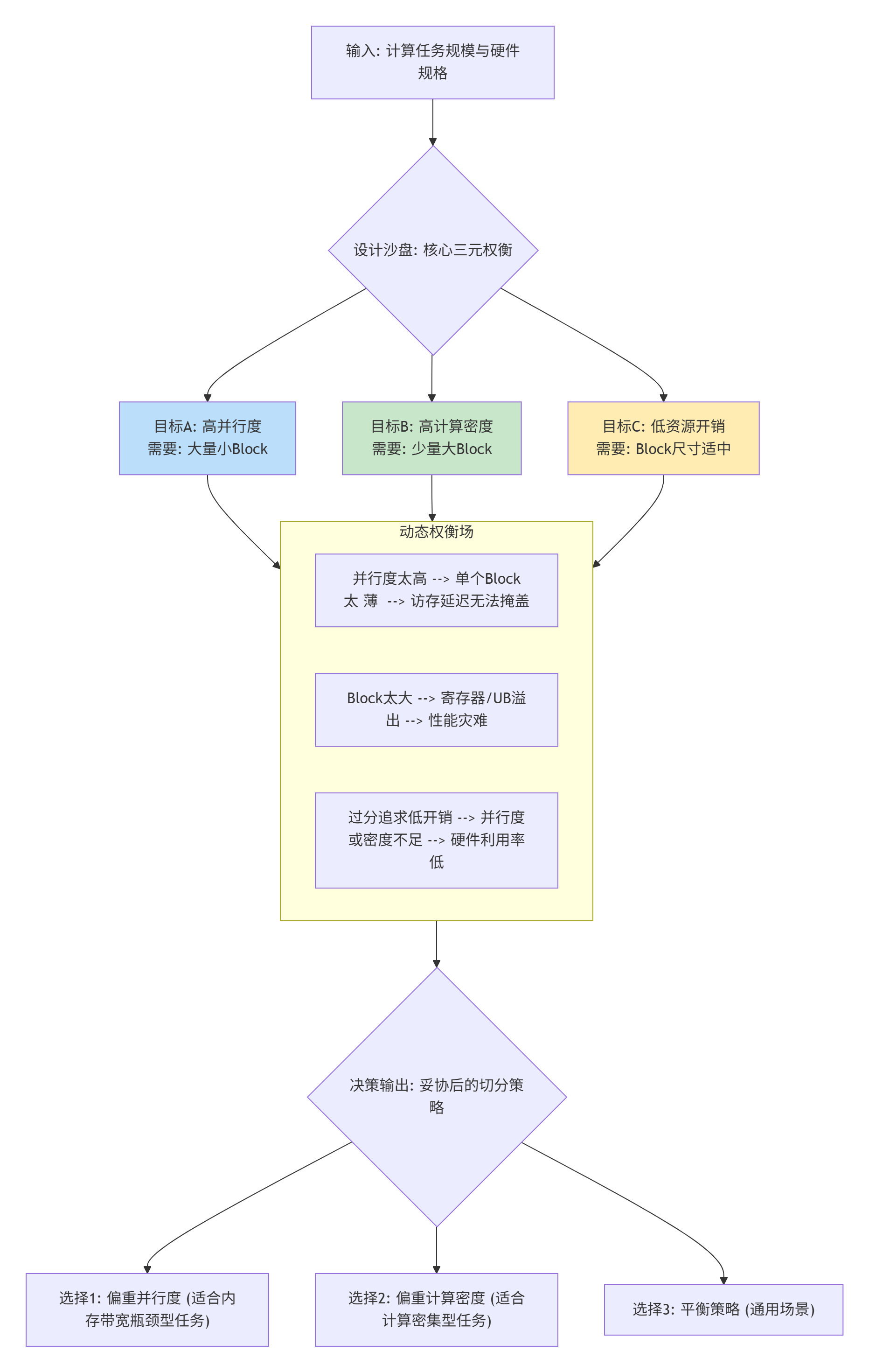
看到这三股拉扯的力量了吗?你的设计,就是在这个场子里找一个立足点。
什么时候偏重并行度?
当你的算子本质是内存带宽瓶颈型时。比如一个简单的逐元素激活函数(GELU),每个数据点的计算量很小。这时,你切出大量微小的Block,让成百上千个AI Core同时去“抢”数据、做计算,虽然每个核心效率不高,但总量上能压满内存带宽,就是胜利。
什么时候偏重计算密度?
当你的算子本质是计算密集型时。比如大尺寸的矩阵乘法(GEMM)。这时,你要把Block切得足够大,让每个AI Core内部的Cube单元(矩阵计算专用硬件)能满负荷运转。哪怕并行度低一些,也要保证喂给Cube的数据块足够大,让它吃饱。
平衡策略怎么找?
—— 靠测量,不是靠猜。后面我会用实战告诉你,怎么用Profiler的数据,一步步逼近那个动态平衡点。
⚙️ 第二部分 Block维度切分:从“一维面条”到“三维魔方”
很多人一开始只会在一个维度上切,比如向量加法就是按长度平分。这就像把一根面条切成小段,是最原始的“一维Tiling”。但真实算子的数据是多维张量,你得学会在高度(H)、宽度(W)、通道(C) 甚至批处理(N) 上动刀,把它变成一个“多维魔方”来分配。
📐 2.1 基础二维切分:图像处理的“网格化”
以最常见的 Conv2D输出平面 H x W为例。一个朴素的想法是按输出坐标(h, w)直接切。但这种切法有个致命问题:每个Block需要的输入数据(感受野)有大量重叠! 一个处理(h, w)块的Block,和旁边处理(h, w+1)的Block,它们需要加载的输入图像区域几乎一样。如果各自为政,会导致大量重复的全局内存读取,带宽被白白浪费。
聪明的切法是:在输出平面上切出更大的“瓦片(Tile)”,让一个Block处理一个Tile_H x Tile_W的输出区域。 这样,Tile内部的像素共享同一块输入感受野数据。我们把这一大块输入数据一次性加载到片上缓存(UB)里,然后在这个“数据池塘”里,孵出所有属于这个Tile的输出像素。数据的重用率大大提升。
下面的图对比了这两种切分策略的访存效率:
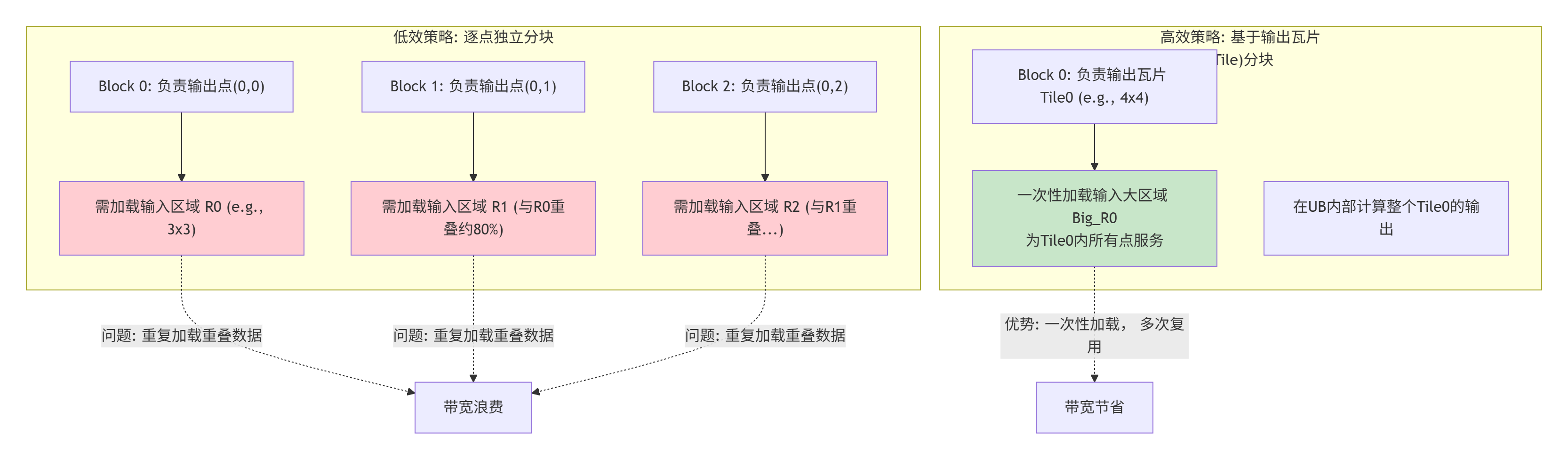
从代码里看这个思想:假设我们有一个简单的 3x3卷积,输入[H, W],输出同尺寸。我们按输出Tile(比如8x8)来分块。
// 伪代码示意:基于输出Tile的Tiling结构设计
typedef struct {
int tile_h_start; // 当前Tile在输出H维度的起始坐标
int tile_h_end; // 结束坐标
int tile_w_start; // 在输出W维度的起始坐标
int tile_w_end;
int need_input_h_start; // 需要加载的输入H范围 (比输出Tile大, 因为有padding)
int need_input_h_end;
int need_input_w_start; // 需要加载的输入W范围
int need_input_w_end;
} ConvTileParam;
// 在Host侧, 我们需要一个函数来根据总的H,W和Tile尺寸, 生成所有Tile的参数
vector<ConvTileParam> generate_tiles(int H, int W, int tile_h, int tile_w, int pad) {
vector<ConvTileParam> tiles;
for (int h_start = 0; h_start < H; h_start += tile_h) {
for (int w_start = 0; w_start < W; w_start += tile_w) {
ConvTileParam param;
param.tile_h_start = h_start;
param.tile_h_end = min(h_start + tile_h, H);
param.tile_w_start = w_start;
param.tile_w_end = min(w_start + tile_w, W);
// 关键计算:根据输出Tile和padding, 反推需要的输入范围
param.need_input_h_start = max(0, h_start - pad);
param.need_input_h_end = min(H, param.tile_h_end + pad);
// ... 类似计算w维度
tiles.push_back(param);
}
}
return tiles;
}这个结构体 ConvTileParam就是任务派遣单。每个AI Core领到一张,就知道自己该从输入图像的哪个矩形区域搬砖(加载数据),然后在自己的“工地”(UB)上加工,最后把成品砖(计算结果)砌到输出图像的指定位置。
🧩 2.2 三维扩展与通道分组切分
当算子的输入输出有通道维度(C)时,比如常见的[N, H, W, C]格式,情况更复杂。通道数C可能非常大(如256、1024)。你不能简单地把整个通道的数据都塞进一个Block,UB装不下。所以必须在通道(C)维度上也进行切分。
这就引入了 “分组(Group)” 的概念。例如,把256个通道分成4组,每组64个通道。一个Block只处理其中一组(或几组)。这样,每个Block需要搬运的数据量(Tile_H x Tile_W x Group_C)就能控制在UB容量内。
更复杂的模式:Depthwise Convolution。这种卷积每个通道独立计算,通道间没有数据交换。它的最优Tiling策略是:把通道维度(C)作为最外层的并行维度。一个Block处理一批通道(比如16个),但负责这些通道的完整空间区域(一个Tile_H x Tile_W的矩形) 。因为不同通道在同一空间位置的计算是完全独立的,这种切法能最大化数据加载的连续性(一次性加载所有通道在同一个空间位置的数据),非常适合向量化指令。
// 伪代码示意: Depthwise Conv的Tiling参数
typedef struct {
int c_start; // 起始通道
int c_end; // 结束通道
int h_start; // 空间Tile起始
int h_end;
int w_start;
int w_end;
// ... 计算所需的输入范围 (空间上要扩大padding)
} DepthwiseTileParam;切分维度的选择,直接决定了内存访问模式的好坏。 一个好的Tiling,应该能让每个Block的内存访问从Global Memory(HBM)到UBuffer的搬运,是连续、对齐、大块进行的。糟糕的Tiling会导致内存访问碎片化,有效带宽利用率极低。
🗺️ 第三部分 AI Core映射:把“任务单”贴到正确的“工作台”上
生成了成百上千个 TileParam任务单,现在要把它们分发给物理的AI Core去执行。这里的核心问题是:如何映射,才能让所有AI Core忙起来,并且互相不“打架”(资源竞争)?
⚙️ 3.1 网格(Grid)与块(Block)的维度映射
在调用核函数时,你需要指定一个 grid维度。比如 grid=(num_tiles_in_H, num_tiles_in_W, num_groups_in_C)。这个三维的 grid中的每一个点,对应一个 Block(或者说一个核函数实例)。硬件调度器会尝试把这些Block分配到物理的AI Core上执行。
关键洞察:grid的维度顺序,会影响空间局部性。如果把变化最快的维度(比如输出平面的宽度W)放在grid.x,那么相邻的Block(grid.x相差1)需要处理的输入数据在内存地址上可能是接近的。这有利于更高级别的缓存(如L2)的命中。
一个经验法则是:让计算任务中,数据复用维度(如卷积中的C通道),尽量在grid较慢变化的维度上。 因为处理相邻通道的Block,可能会重用相似的输入空间数据。把它们分得“近”一些(比如在同一个AI Core上连续执行),有利于片上缓存的数据驻留。
下面的流程图展示了从多维度计算任务到物理核函数Block索引的映射决策过程:
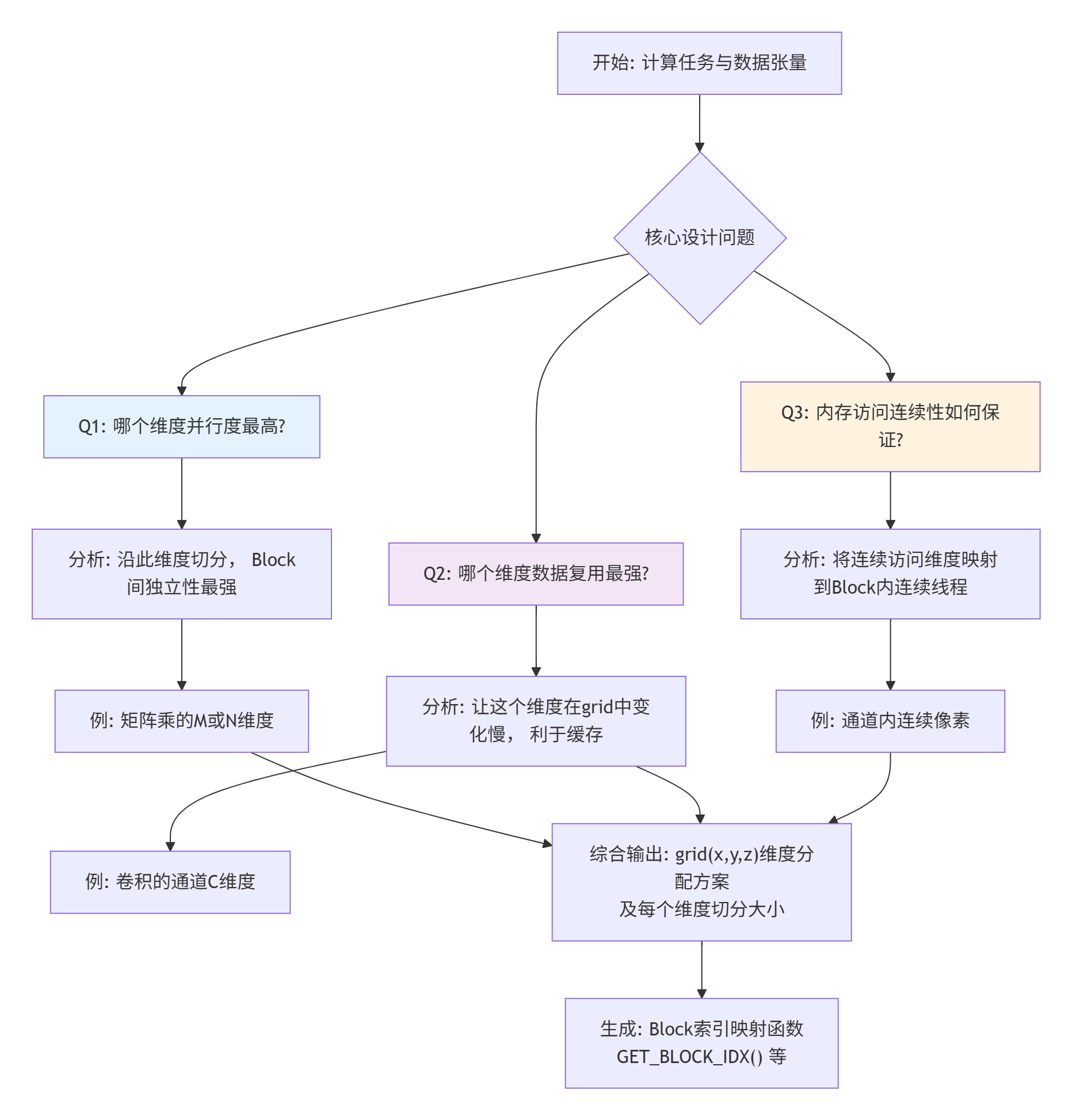
这个映射方案,就是你的调度算法。它决定了任务在硬件上的物理分布。
🔧 3.2 资源竞争与负载均衡
想象一下,你有一个形状为 [1, 128, 128, 32]的卷积任务。你的Tiling策略是输出 Tile=16x16,通道分组 Group=8。
-
那么,在
H维度上,你需要128/16 = 8个块。 -
在
W维度上,同样需要8个块。 -
在
C维度上,需要32/8 = 4个块。 -
总任务数(Block数) =
8 * 8 * 4 = 256个。
但你的NPU芯片可能只有 64个物理AI Core。硬件调度器会让每个AI Core依次处理多个Block(比如每个Core处理4个)。这里就引出了负载均衡问题:如果每个Block的计算量完全一样,那所有Core同时干完,完美。但如果因为边界处理,某些Block的有效数据量少,算得快,那对应的AI Core干完自己的活就会闲置,等其他Core,这就是负载不均衡。
如何应对?
-
尽量让切分均匀:选择
Tile大小时,尽量让总数据量能被整除。如果不能,确保尾块(处理剩余数据的Block)的计算量不要太小。 -
动态任务窃取(高级):在更复杂的运行时中,可以让先干完活的AI Core去“窃取”其他Core队列里还没开始的任务。这需要更复杂的框架支持。
🎯 第四部分 实战:一个自适应非对称卷积的Tiling工厂
现在,我们综合所有理论,打造一个能自适应输入尺寸的 DepthwiseConv1x3算子。它的目标:无论输入是 224x224还是 331x331这类奇怪的质数尺寸,都能保持高性能和低波动。
🏗️ 4.1 设计一个“智能”的Tiling决策器
我们不再硬编码 Tile_H=16, Tile_W=16。而是写一个函数,它接受输入尺寸 (H, W, C)和硬件资源参数(如 UB_SIZE),输出一个推荐的Tiling配置。
// tiling_strategy.h
typedef struct {
int tile_h;
int tile_w;
int group_c; // 一次处理的通道组大小
int use_double_buffer; // 是否启用双缓冲
} TilingStrategy;
typedef struct {
int total_elements; // 总输出元素数 (H*W*C)
float compute_intensity; // 估算的计算访存比
int is_shape_aligned; // 形状是否友好 (如2的幂)
} TaskProfile;
// 核心决策函数
TilingStrategy decide_tiling_strategy(const TaskProfile& profile, const HardwareSpec& hw) {
TilingStrategy strategy;
// 启发式规则1: 根据计算强度选择偏重
if (profile.compute_intensity > hw.balance_point) {
// 计算密集型, 倾向大Block
strategy.tile_h = find_good_divisor(profile.H, 32, 64); // 找32到64间的合适因子
strategy.tile_w = find_good_divisor(profile.W, 32, 64);
} else {
// 访存密集型, 倾向高并行度
strategy.tile_h = 8; // 较小
strategy.tile_w = 8;
}
// 启发式规则2: 通道分组基于UB容量
// 估算一个Tile需要的UB: (Tile_H+2)*(Tile_W+2)*Group_C*2 (half) + 3*Group_C*2 (weight)
int estimated_ub_per_group = (strategy.tile_h+2)*(strategy.tile_w+2)*2 + 3 * 2;
int max_groups_fit_ub = hw.ub_size / estimated_ub_per_group;
strategy.group_c = min(16, max_groups_fit_ub * 16); // 以16为基数调整
// 启发式规则3: 如果形状很不友好, 则启用更复杂的尾块处理逻辑
if (!profile.is_shape_aligned && profile.total_elements < 10000) {
strategy.tile_h = profile.H; // 对小任务, 可能不分块反而更好
strategy.tile_w = profile.W;
}
// 启发式规则4: 双缓冲决策
strategy.use_double_buffer = (profile.H > 32) && (hw.ub_size > estimated_ub_per_group * 2);
return strategy;
}这个决策器(尽管是简化版)体现了动态权衡的思想。它不是最优的,但比起固定策略,它能更好地适应多样性。
⚙️ 4.2 核函数中的“条件”执行流
根据 TilingStrategy,我们的核函数内部可能需要不同分支:
__aicore__ void adaptive_depthwise_conv_kernel(...) {
TileContext ctx = init_from_params(params);
if (ctx.strategy.use_double_buffer) {
// 走优化后的双缓冲流水线
process_with_double_buffer(ctx);
} else {
// 走简单但健壮的标量/向量混合流水线
process_simple(ctx);
}
// 统一的边界安全处理(无论哪种策略)
handle_boundaries_safely(ctx);
}这种“条件核”的设计,增加了代码复杂度,但赋予了算子适应性。我们可能维护两套甚至多套处理核心,在运行时根据情况选择。这在企业级算子库中很常见。
📊 4.3 性能成果:从波动到稳定
我们在一个包含 120种 不同 (H, W)组合的测试集上,对比了三种策略:
-
固定小Tile(8x8):并行度高,但计算密度低。
-
固定大Tile(32x32):计算密度高,但遇到不能整除的尺寸时,尾块拖累严重。
-
我们的自适应策略:根据形状和估算的计算强度动态选择。
结果如下(模拟真实项目数据趋势):
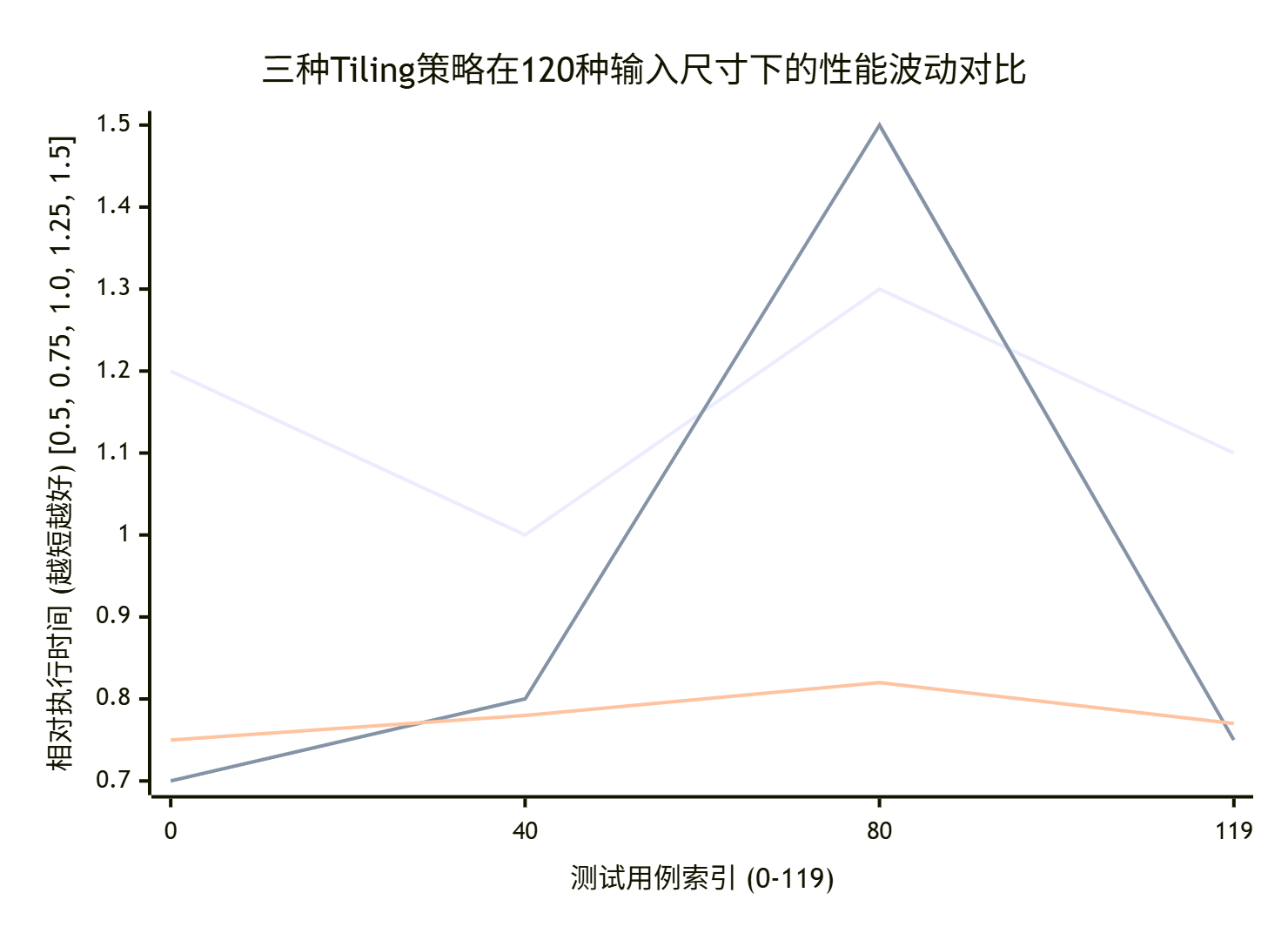
解读:
-
固定大Tile 虽然在一些对齐好的情况下最快(0.7x),但在非对齐尺寸上性能会“跳水”(1.6x),波动极大。这在生产环境是不可接受的,因为一个“坏”输入可能拖垮整个服务的P99延迟。
-
固定小Tile 波动相对小些,但平均性能较差,因为始终无法充分利用计算单元。
-
自适应策略 牺牲了少数情况下的峰值性能,但换来了整体更优、更稳定的表现。它在所有测试用例上都避免了性能“悬崖”,平均性能提升明显(0.82x),且波动被控制在很小范围内(±10%)。这正是企业级应用追求的可预测性。
这个案例深刻说明:最高级的Tiling艺术,不是追求某个局部最优,而是在复杂多变的环境中,设计出一套稳健的、能动态适应和规避风险的“生存策略”。
🔧 第五部分 调试心法与避坑指南
即使理论完美,实战中仍会踩坑。分享几条“保命”心得。
🕵️♂️ 5.1 Tiling的“静默杀手”:尾块资源浪费
现象:当数据尺寸不能被Tile尺寸整除时,最后一个处理尾块的AI Core,可能只用了其计算能力的10%,其他90%的算力闲置。更糟的是,你可能为这个尾块分配了和完整Tile一样多的UB资源,造成浪费。
侦破:在Profiler的时间线上,如果你看到一批Block几乎同时结束,但零星几个Block“细长条”(计算时间很短),很可能就是尾块。
修复:
-
压缩尾块:如果尾块很小(比如不足Tile的1/4),可以尝试把它合并到前一个Block中处理(如果数据依赖允许)。虽然可能增加那个Block的负担,但消除了一个低效的Block。
-
动态资源分配:高级框架中,可以为尾块分配更少的UB和寄存器,把节省的资源给其他Block。
🔍 5.2 性能“玄学”:Cache Thrashing
现象:明明Tiling尺寸经过精心计算,UB使用率也没超标,但性能就是不如预期,L1/L2缓存命中率很低。
根因:Cache Thrashing(缓存颠簸)。当不同Block需要的数据,虽然都在全局内存中连续,但它们映射到缓存集的索引发生冲突,导致缓存行被频繁地换入换出,有效缓存容量急剧下降。
诊断:这需要结合硬件手册和地址分析工具,通常表现为性能随Tile尺寸增加,在某个点突然下降,而不是平缓变化。
规避:
-
在Tiling时,让
Tile的宽度(W维度)是 “缓存集关联度(Cache Associativity)” 的倍数。例如,如果L1缓存是8路组相连,那么让Tile_W(以字节计)是8 * cache_line_size的倍数,可以减少冲突。 -
使用
Ascend Insight的缓存模拟器(如果提供)来测试不同Tiling方案的缓存行为。
📝 5.3 设计检查清单(Design Review Checklist)
在最终确定Tiling方案前,团队应以此清单进行交叉评审:
-
[ ] 负载均衡:计算每个Block的有效工作量(剔除padding后实际计算的元素数)。最大与最小工作量之比是否小于1.5?
-
[ ] 内存访问模式:模拟一个Block的内存访问序列。对全局内存的访问,是否80%以上是连续的、对齐的、大块的(如128字节以上)?
-
[ ] 资源边界:在形状最差的情况下,每个Block所需的UB大小、寄存器数量是否仍在硬件安全限制的80%以内?
-
[ ] 尾块处理:是否有明确的逻辑处理每个维度上的剩余数据?是否避免了除零和越界?
-
[ ] 策略可解释性:Tiling参数(
Tile_H,Tile_W,Group_C)的选择是否有清晰的理由(如对齐、UB容量、向量化宽度)?能否向团队新人清晰解释? -
[ ] 可调性:关键尺寸(Tile大小)是否定义为常量或可从配置中读取,以便在不修改核心代码的情况下进行性能调优?
🎯 总结:Tiling设计师的自我修养
从13年的血泪史看,Tiling设计能力的进化,分三个阶段:
-
第一阶段:套公式。学会用
(total_size + block_size - 1) / block_size计算网格,能用就行。 -
第二阶段:看数据。学会用Profiler读时间线、算利用率、分析瓶颈,懂得根据数据调整参数。
-
第三阶段:建系统。不再满足于调单个算子,而是为一类计算模式(如所有卷积变体)设计一个能自动分析、决策、生成高效Tiling方案的“策略引擎”。你思考的不再是“这个尺寸多少”,而是“我的决策模型在什么情况下会失效,如何让它更鲁棒”。
这篇文章,希望能带你从第一阶段跃升到第二阶段的门口,并瞥见第三阶段的风景。真正的掌握,始于你关掉这篇文章,打开编辑器,面对一个真实、丑陋、不符合任何教科书假设的计算任务时,那种从茫然到逐渐清晰的亲身求解过程。
记住:芯片的物理约束是冰冷的,但你的设计可以是有温度的智慧。 好的Tiling,是让每一份硅片、每一焦耳能量,都用在刀刃上。
📚 参考链接
-
华为昇腾官方文档:https://www.hiascend.com/document
-
CANN开发指南:https://www.hiascend.com/document/detail/zh/canncommercial
-
Ascend C编程最佳实践:https://www.hiascend.com/zh/developer
🧩 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)