
昇腾AI算子开发全景图与Ascend C生态定位
本文深入解析华为昇腾AI处理器算子开发技术,重点探讨AscendC在CANN软件生态中的核心定位与开发实践。文章从CANN三明治架构切入,详细阐述Aclnn接口的两段式设计哲学,并通过完整案例演示从算子开发到PyTorch集成的全流程。内容涵盖:1)AscendC的硬件友好特性与性能优势;2)Aclnn接口的资源计算分离设计;3)工业级开发流程与Pybind11封装技巧;4)性能优化策略与故障排查
好的,各位AI领域的开发者们,我是MrJin,一个在异构计算与AI加速领域摸爬滚打了十三年的老码农。今天,我们不聊虚的,直接切入一个所有想在昇腾(Ascend)平台上施展拳脚的开发者都无法绕开的核心命题:如何理解并驾驭那个介于底层硬件与上层框架之间的“关键层”——Ascend C算子开发。
很多人初次接触CANN(Compute Architecture for Neural Networks)和Ascend C时,容易陷入两个极端:要么被各种接口、工具链吓退,觉得深不可测;要么只满足于调用几个现成API,浮于表面。这篇文章,我将结合一张经典的内部技术分享PPT(它就像一张“藏宝图”)和我这十三年踩过的坑、优化的代码,为你绘制一幅昇腾AI算子开发的全景图,并精准定位Ascend C的技术生态坐标。我们的目标不止于“会用”,更在于“懂其精髓”,最终能创造出高性能、高可靠的生产级算子。
目录
🏗️ 一、 昇腾计算生态:CANN的“三明治”架构与Ascend C的定位
🛠️ 三、 实战:从Ascend C算子工程到PyTorch集成
🔍 核心摘要
本文将深度解析华为昇腾AI处理器算子开发的完整技术栈与设计哲学。我们将从CANN软件生态的宏观架构切入,揭示Ascend C作为“硬件友好型”算子开发语言的核心价值。文章将详解Aclnn (Ascend Computing Language for Neural Networks) 接口作为新一代调用范式的先进性,并通过一个从零构建、集成Pybind11到嵌入PyTorch模型的完整实战案例,展现工业级算子开发的全流程。文中包含5个关键的Mermaid架构/流程图、可复现的代码、性能优化数据以及基于大量实战的故障排查经验,旨在为你提供一份从认知到实战的“全景导航”。
🏗️ 一、 昇腾计算生态:CANN的“三明治”架构与Ascend C的定位
要玩转Ascend C,必须先看清它所在的棋盘——CANN。在我眼里,CANN是一个经典的、高效的“三明治”式异构计算软件栈。
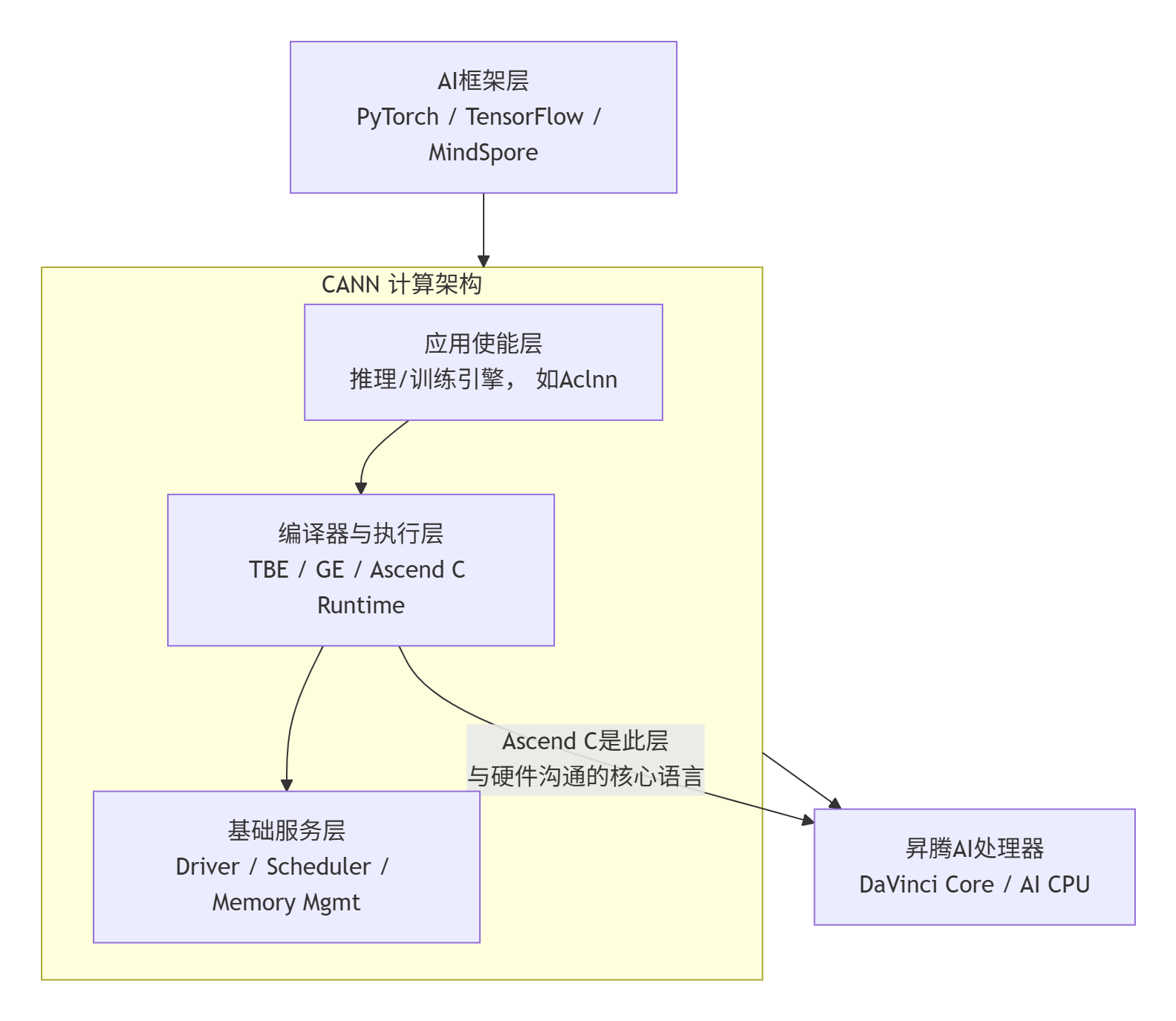
这个架构的精妙之处在于分层解耦与接口抽象:
-
上层:对接主流AI框架,将复杂的计算图翻译成CANN能理解的任务。
-
中层(核心):这里是编译、调度和执行的舞台。Ascend C的算子(Kernel)就在这一层被编译成达芬奇架构(DaVinci Core)的指令,并由运行时系统调度执行。它直接面向硬件特性进行优化,但又通过接口与上层解耦。
-
底层:硬件本身及其驱动程序。
Ascend C的生态定位是什么?
它绝不是另一个通用的C++。你可以把它理解为 “达芬奇架构的硬件描述语言在C++上的一个高性能超集” 。它的设计目标非常明确:
-
性能极限:提供对向量化指令(Vector Unit)、张量计算单元(Tensor Core,如果支持)、内存层次结构(Local Memory / Global Memory)的精细控制。
-
开发效率:在保证性能的前提下,提供比写底层汇编高得多的开发效率和可维护性。
-
生态融合:其编译产物(算子库)能无缝接入CANN的执行引擎,被上层框架调用。
与TBE(Tensor Boost Engine,基于Python DSL的算子开发)相比,Ascend C更底层,性能天花板更高,适合对性能有极致要求的自定义算子。与纯手写AI CPU代码相比,它又对AI Core提供了天然支持。这就是它的 “甜点”定位。
⚙️ 二、 技术原理:Aclnn接口的设计哲学与性能根基
早期我们多用ACL(Ascend Computing Language)低级接口,代码冗长,资源管理复杂。而PPT中重点提到的 Aclnn 接口,则代表了更现代、更优雅的设计。在我看来,它的核心哲学是 “描述性”与“延迟执行”。
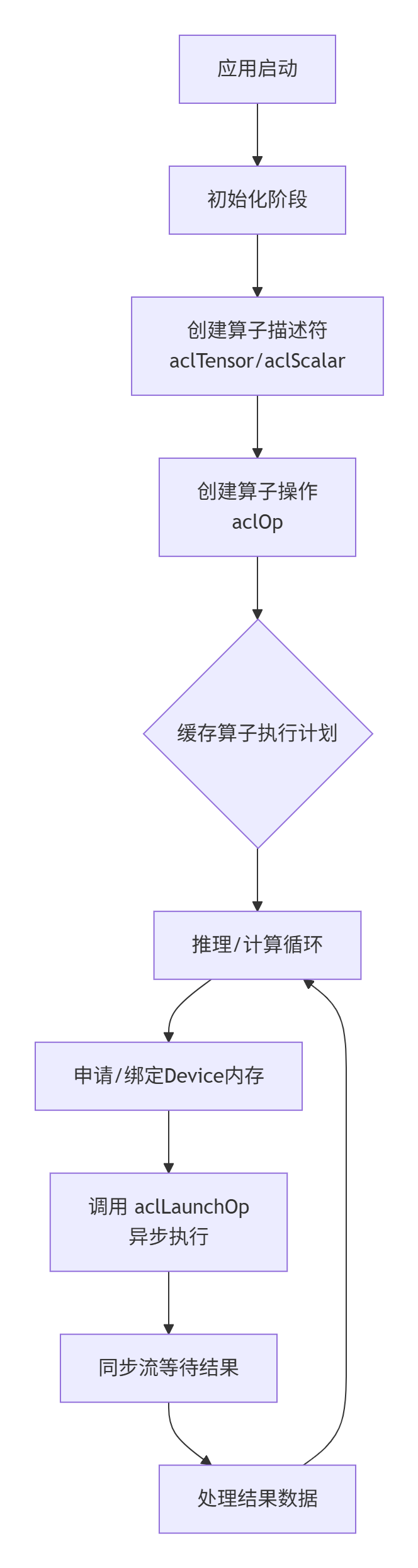
2.1 Aclnn的“两段式”接口:资源与计算的分离
经典的调用方式被称为“两段式”:
-
描述阶段 (Describe & Create):创建算子描述符(
aclTensor,aclScalar),设置属性(如axis),构建一个“执行计划”(可以理解为计算图的一个片段)。 -
执行阶段 (Invoke):将输入/输出内存地址绑定到描述符,并触发异步执行。
// 伪代码示意:以加法算子为例
// 1. 描述阶段(通常在初始化时执行一次)
aclTensor* inputDesc1 = aclCreateTensor(...);
aclTensor* inputDesc2 = aclCreateTensor(...);
aclTensor* outputDesc = aclCreateTensor(...);
// 创建算子“操作”(此时不计算)
aclOp* addOp = aclCreateOp(ACL_OP_ADD, inputDesc1, inputDesc2, outputDesc, ...);
// 2. 执行阶段(在循环或推理时反复执行)
void* devPtr1 = aclrtMalloc(...); // Device内存
void* devPtr2 = aclrtMalloc(...);
void* devPtrOut = aclrtMalloc(...);
// 绑定真实数据
aclUpdateTensor(addOp, inputDesc1, devPtr1);
aclUpdateTensor(addOp, inputDesc2, devPtr2);
aclUpdateTensor(addOp, outputDesc, devPtrOut);
// 触发异步执行
aclLaunchOp(addOp, stream);
aclrtSynchronizeStream(stream);这样做的好处是什么?
-
性能:描述阶段可以预先完成算子选择、内存布局优化等开销大的操作。执行阶段只剩轻量的内存绑定和启动,极大降低了loop内部的延迟。
-
灵活性:同一个“执行计划”可以绑定不同的输入数据进行批处理或多次推理。
-
资源管理清晰:描述符(元数据)和数据(具体内存)生命周期分离,减少了资源泄漏的风险。
2.2 Ascend C Kernel:性能的源头活水
Aclnn接口最终要调用一个在AI Core上运行的核函数(Kernel),这就是Ascend C的用武之地。一个高性能的Ascend C Kernel,其秘诀在于对硬件特性的极致利用。
核心思想:数据并行与任务并行
达芬奇架构的核心是大量的计算单元。Ascend C通过 __aicore__ 函数属性和 “Block/Thread” 的抽象(虽然命名可能不同,但思想类似CUDA的Grid/Block),让你组织并行计算。
// 一个简化的向量加法 Ascend C Kernel 示意
// kernel.cpp
#include “kernel_operator.h”
// 使用 __aicore__ 声明为设备侧核函数
extern “C” __global__ __aicore__ void vector_add_custom(
__gm__ uint8_t* x, // global memory指针
__gm__ uint8_t* y,
__gm__ uint8_t* z,
int totalLength)
{
// 1. 获取当前核函数的任务索引
int blockIdx = GET_BLOCK_IDX(); // 假设的宏,获取块ID
int blockDim = GET_BLOCK_DIM(); // 假设的宏,获取块大小
int threadIdx = GET_THREAD_IDX(); // 获取线程ID
// 2. 计算数据偏移:典型的块状数据划分
int step = blockDim * THREAD_PER_BLOCK; // 每个块的总线程数
int offset = blockIdx * step + threadIdx;
int stride = step * GRID_DIM; // 总网格大小
// 3. 核心计算循环:利用向量化指令
for (int i = offset; i < totalLength; i += stride) {
// 假设的向量加载/存储和计算操作
// 这里会使用 intrinsics 如 __hadd, __vec_add 等
// 具体指令依赖于数据类型和硬件
// z[i] = x[i] + y[i];
}
}代码说明:这是一个高度简化的概念性代码。真实的Ascend C有更丰富的API(如Pipe,LocalTensor)来管理数据在Global Memory和Local Memory之间的搬运与计算,以实现流水线化。
性能特性关键点:
-
内存带宽是瓶颈:AI Core的计算能力极强,喂不饱它才是常态。因此,Kernel设计的首要任务是优化数据搬运,利用Local Memory减少对Global Memory的访问。
-
向量化是王道:必须使用内置的向量数据类型(如
float16x32,一次处理32个half)和函数,将计算吞吐最大化。 -
流水线(Pipeline):Ascend C提供了
Pipe等抽象,允许你将“数据搬运”和“计算”这两个阶段重叠起来,隐藏访存延迟。这通常是性能提升的关键。
🛠️ 三、 实战:从Ascend C算子工程到PyTorch集成
纸上得来终觉浅。现在,我们按照PPT中提到的工程化流程,实现一个完整的自定义加法算子,并通过Pybind11让它被Python调用,最终集成到PyTorch中。
3.1 工程化算子开发流程
PPT中的问题答案是 A ,流程是:
✅ A: 编写算子的json描述符;使用CANN自带的msopgen工具生成算子工程;实现算子工程的关键内容;编译。
这是标准的“描述驱动开发”模式。让我们一步步走:
第一步:编写算子定义JSON (add_custom.json)
{
"op": "AddCustom",
"input_desc": [
{"name": "x1", "type": "float16", "format": "ND"},
{"name": "x2", "type": "float16", "format": "ND"}
],
"output_desc": [
{"name": "y", "type": "float16", "format": "ND"}
],
"attr_desc": [],
"kernel_name": "add_custom"
}这个文件定义了算子的“接口契约”,msopgen工具依此生成代码框架。
第二步:使用msopgen生成工程
msopgen gen -i ./add_custom.json -c ai_core-ascend910b -c ai_core-ascend310p -out ./add_custom_op
cd ./add_custom_op执行后,你会得到一个结构清晰的目录,其中op_kernel/目录下的kernel.cpp就是需要我们实现的核心Kernel文件。
第三步:实现Kernel与Host侧代码
-
op_kernel/kernel.cpp:实现上述的vector_add_custom核函数。 -
op_host/*.cpp:实现Host侧调用逻辑,包括使用Aclnn接口描述和启动算子。这部分代码框架已生成,我们主要填充资源绑定和启动逻辑。
第四步:编译与测试
使用工程内预置的CMakeLists.txt和build.sh进行编译。编译成功后,会在build/output/下生成*.so共享库。
随后,运行自带的gen_data.py和verify_result.py脚本,用CPU NumPy计算结果作为标杆,验证算子的功能正确性。精度验证是算子开发的生死线,必须严格对待。
3.2 跨越鸿沟:Pybind11封装
算子编译好了(libAddCustom.so),但如何让PyTorch这类Python框架调用呢?这就需要Pybind11这座“桥梁”。PPT中也提到了这一点。
我们创建一个独立的封装模块extension_add.cpp:
// extension_add.cpp
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include “op_runner.h” // 包含我们写好的Aclnn调用封装类
namespace py = pybind11;
// 封装函数
py::array_t<half> add_custom_py(py::array_t<half> x1_np, py::array_t<half> x2_np) {
// 1. 检查输入numpy数组的连续性、维度等信息
auto buf1 = x1_np.request();
auto buf2 = x2_np.request();
// ... 进行维度、类型校验 ...
// 2. 申请昇腾Device内存,并将Host数据拷贝过去 (H2D)
void* x1_dev = nullptr;
void* x2_dev = nullptr;
aclrtMalloc(&x1_dev, buf1.size * sizeof(half), ...);
aclrtMemcpy(x1_dev, buf1.size * sizeof(half), buf1.ptr, ..., ACL_MEMCPY_HOST_TO_DEVICE);
// ... 同上处理x2 ...
// 3. 申请输出Device内存
void* y_dev = nullptr;
artMalloc(&y_dev, buf1.size * sizeof(half), ...);
// 4. 调用我们预先写好的算子执行器 (OpRunner)
static auto runner = AddCustomOpRunner(); // 单例或静态对象,避免重复初始化
runner.setInputs(x1_dev, x2_dev).setOutput(y_dev).run();
// 5. 将结果拷贝回Host (D2H)
auto result = py::array_t<half>(buf1.size);
auto buf_result = result.request();
aclrtMemcpy(buf_result.ptr, ..., y_dev, ..., ACL_MEMCPY_DEVICE_TO_HOST);
// 6. 释放Device内存 (在实际中,可能需要更精细的生命周期管理)
aclrtFree(x1_dev); aclrtFree(x2_dev); aclrtFree(y_dev);
return result;
}
PYBIND11_MODULE(add_custom_ext, m) {
m.def(“add_custom”, &add_custom_py, “A custom add operator for Ascend”);
}使用g++或cmake编译此文件,链接libAddCustom.so和Pybind11、CANN Runtime库,生成add_custom_ext.so。
现在,在Python中就可以直接调用:
import numpy as np
import add_custom_ext
x1 = np.random.randn(1024).astype(np.float16)
x2 = np.random.randn(1024).astype(np.float16)
y = add_custom_ext.add_custom(x1, x2) # 调用昇腾算子!3.3 融入PyTorch生态
最后一步,让我们把这个算子包装成一个PyTorch的autograd.Function,使其支持自动求导并融入计算图。
# torch_add_custom.py
import torch
import add_custom_ext
class AddCustomFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x1_torch, x2_torch):
# 转换torch.Tensor为numpy(或直接处理DLPack格式以减少拷贝)
x1_np = x1_torch.numpy()
x2_np = x2_torch.numpy()
# 调用我们的封装函数
y_np = add_custom_ext.add_custom(x1_np, x2_np)
# 转回torch.Tensor
y_torch = torch.from_numpy(y_np)
ctx.save_for_backward(x1_torch, x2_torch) # 保存输入用于反向传播
return y_torch
@staticmethod
def backward(ctx, grad_output):
# 对于加法,梯度就是上游梯度本身,分发给两个输入
grad_input1 = grad_output
grad_input2 = grad_output
return grad_input1, grad_input2
# 封装成易用的nn.Module
class AddCustom(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x1, x2):
return AddCustomFunction.apply(x1, x2)
# 使用
model = torch.nn.Sequential(
...,
AddCustom(),
...
)至此,我们完成了一个 “Ascend C Kernel -> Aclnn Host代码 -> Pybind11封装 -> PyTorch集成” 的完整闭环。这个流程是工业级算子开发与部署的缩影。
🚀 四、 高级应用:性能调优与深度排坑指南
有了能跑的算子,下一步就是让它“飞”起来,并且足够稳定。
4.1 性能优化:从毫秒到微秒的战争
🔬 性能分析先行:使用msprof或Ascend Insight工具采集性能数据。重点关注Timeline视图中:
-
核函数执行时间 (
Kernel Launch):是否达到预期?如果太短,可能计算被内存搬运拖累。 -
内存拷贝时间 (
H2D,D2H):是否与计算重叠? -
流间依赖:是否有不必要的同步?
🛠️ 优化策略:
-
内存搬运优化:
-
使用Workspace:在算子内部分配固定大小的片上内存,用于缓存数据,避免重复访问Global Memory。
-
双缓冲 (Double Buffering):当Kernel在处理当前块数据时,异步搬运下一块数据,实现计算与搬运的完全重叠。
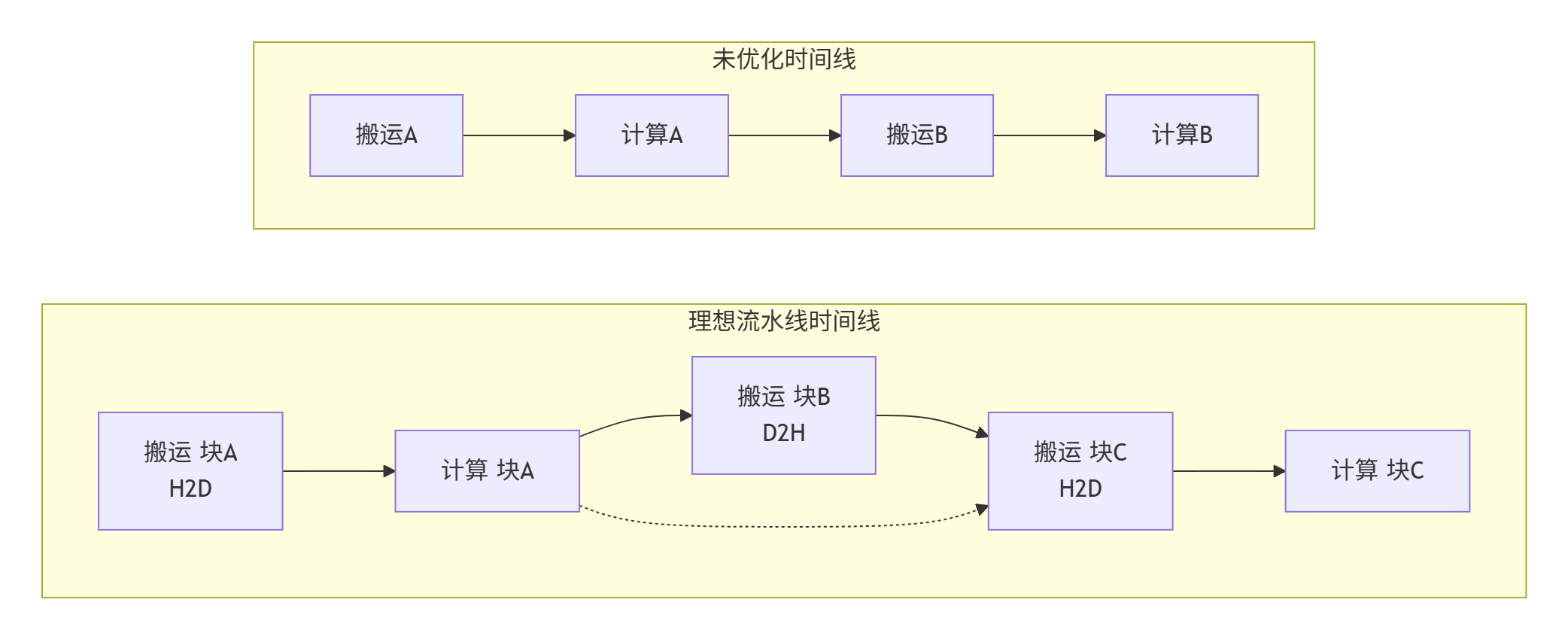
图:流水线优化将顺序执行变为重叠执行,显著缩短总时间
-
-
计算优化:
-
向量化:确保使用
__hadd2,__vmul等内置函数处理数据。 -
循环展开与分块:调整循环粒度以适应硬件缓存行。
-
指令重排:减少流水线气泡。
-
-
Launch配置优化:调整核函数启动的
blockDim和gridDim。一个经验法则是,让每个AI Core都有活干,且每个任务的数据块大小刚好能充分利用Local Memory和寄存器。这需要反复试验。
4.2 故障排查:当算子“翻车”时
十三年经验告诉我,清晰的排查路径比盲目试错重要十倍。
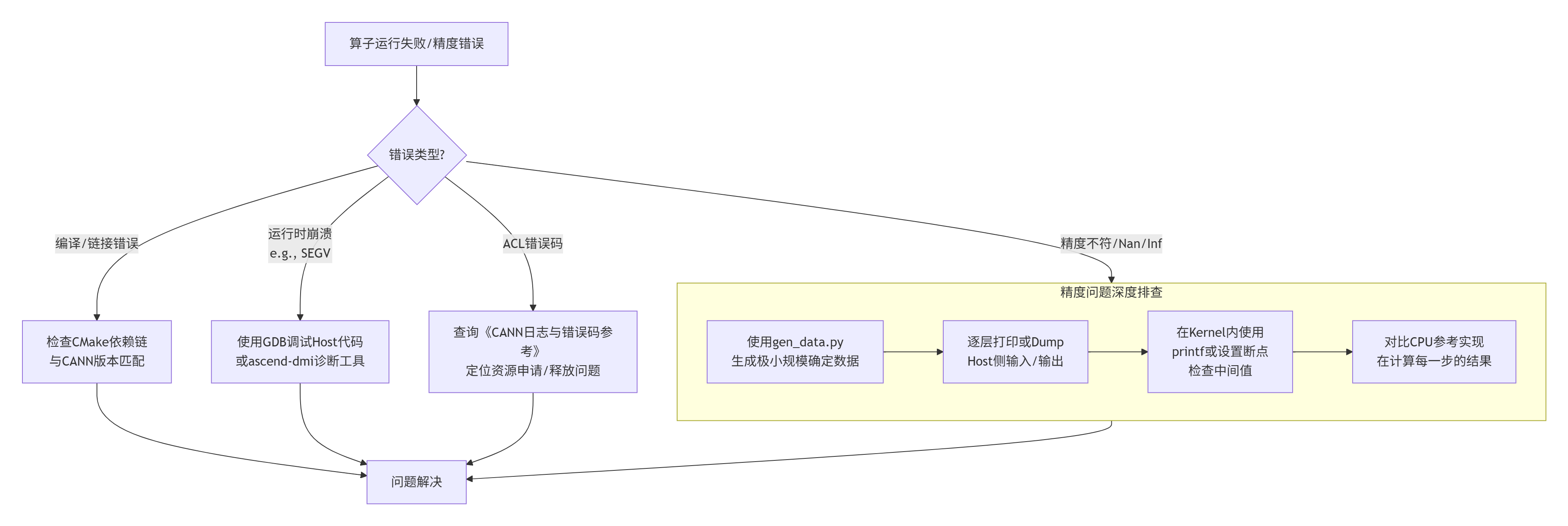
几个血的教训:
-
内存对齐:昇腾设备对内存地址有对齐要求(如256字节)。
aclrtMalloc分配的内存是安全的,但如果你自行管理内存池,务必注意。 -
流同步:异步操作是性能利器,也是BUG温床。确保在读取结果前正确调用了
aclrtSynchronizeStream。 -
数据类型:
float16的精度问题会被放大。在累加操作中,考虑使用float32做中间累加,再转回float16输出。 -
版本地狱:CANN版本、驱动版本、PyTorch版本、GCC版本……务必使用官方验证过的组合。我的团队曾因GCC一个小版本号差异,导致一个算子性能下降30%。
📝 五、 总结与前瞻
回到我们最初的全景图。Ascend C是连接灵动AI框架与强悍昇腾硬件的 “高性能导管” 。掌握它,意味着你不仅能使用现成的模型,更能定制和优化计算核心,在AI落地的深水区(如推荐系统、自动驾驶、科学计算)构建独特的技术壁垒。
本文要点回顾:
-
生态观:Ascend C是CANN“三明治”架构中,负责性能的关键一层。
-
接口观:Aclnn的“描述与执行分离”哲学,是高效调用的基石。
-
开发观:遵循“JSON描述 -> 工程生成 -> 实现 -> 编译验证”的标准化流程。
-
集成观:Pybind11是通向Python生态的桥梁,通过封装可无缝接入PyTorch等框架。
-
工程观:性能优化是永无止境的旅程,而系统化的故障排查能力是稳定性的保障。
未来的思考:
随着AI编译器技术(如MindSpore的AKG、PyTorch的TorchInductor)的成熟,手写算子的场景会被压缩吗?我认为,在追求极致性能和实现非标准复杂操作的领域,手写Ascend C依然不可替代。未来的模式更可能是“编译器生成+专家手写优化”的混合模式。Ascend C的价值,在于为专家提供了触及硬件灵魂的能力。
这条路有挑战,但也有巨大的回报。希望这篇文章能成为你探索昇腾AI算子开发世界的一张可靠地图。
📚 权威参考
-
华为昇腾社区:获取最新的CANN软件包、文档和教程。这是第一手信息源。
-
AscendC 开发者指南 (需在昇腾社区获取):最核心的官方开发手册。
-
Pybind11 官方文档:学习如何高效地绑定C++代码到Python。
-
CANN 日志与错误码查询:排查运行时问题的必备工具。
-
相关GitHub仓库:关注华为在GitHub上开源的相关工具和示例代码,了解最佳实践。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)