
昇腾Ascend C单算子API调用指南 - 在Python中直接调用硬件算子
目录
1. 摘要
单算子API调用是昇腾AI处理器生态中的关键核心技术,它允许开发者绕过传统的模型加载流程,直接调用底层硬件算子。本文基于官方文档和实战经验,详细介绍两段式接口设计、内存管理机制、Python绑定技术等核心概念。通过具体的代码示例和性能分析,展示如何实现超过传统Python实现10-50倍的性能提升。关键内容包括:单算子API的执行流程、Pybind11封装技术、内存零拷贝优化以及实际应用案例。
2. 单算子API调用的核心概念
2.1. 🎯 什么是单算子API调用?
单算子API调用是昇腾CANN软件栈提供的一种直接调用硬件算子的能力。与传统的模型推理不同,它允许开发者绕过完整的模型加载流程,直接调用单个或多个优化过的硬件算子。
与传统模型推理的对比:
|
特性 |
单算子API调用 |
模型推理 |
|---|---|---|
|
执行粒度 |
算子级别 |
模型级别 |
|
资源开销 |
低 |
相对较高 |
|
控制灵活性 |
高 |
中等 |
|
性能优化空间 |
大 |
受模型结构限制 |
|
适用场景 |
定制计算、算子测试 |
标准模型推理 |
这种方式的核心优势在于它提供了更细粒度的控制和更低的资源开销,特别适合于需要定制计算逻辑或对性能有极致要求的场景。
2.2. 🏗️ 两段式接口设计原理
单算子API采用独特的两段式设计,这是其高性能的关键:
// 两段式接口示例
aclnnStatus aclnnAddGetWorkspaceSize(const aclTensor* input1,
const aclTensor* input2,
aclTensor* output,
uint64_t* workspaceSize,
aclOpExecutor** executor);
aclnnStatus aclnnAdd(void* workspace, uint64_t workspaceSize,
aclOpExecutor* executor, aclrtStream stream);两段式接口的工作流程:
-
资源预估阶段:调用
GetWorkspaceSize接口,计算本次计算需要的中间内存大小 -
执行阶段:根据预估结果分配合适的内存,然后调用执行接口
这种设计的核心优势是避免了传统动态内存分配的性能开销,实现了精确的内存控制。
2.3. ⚡ 性能特性分析
单算子API调用在性能方面有显著优势,下面是基于实际测试的性能对比数据:
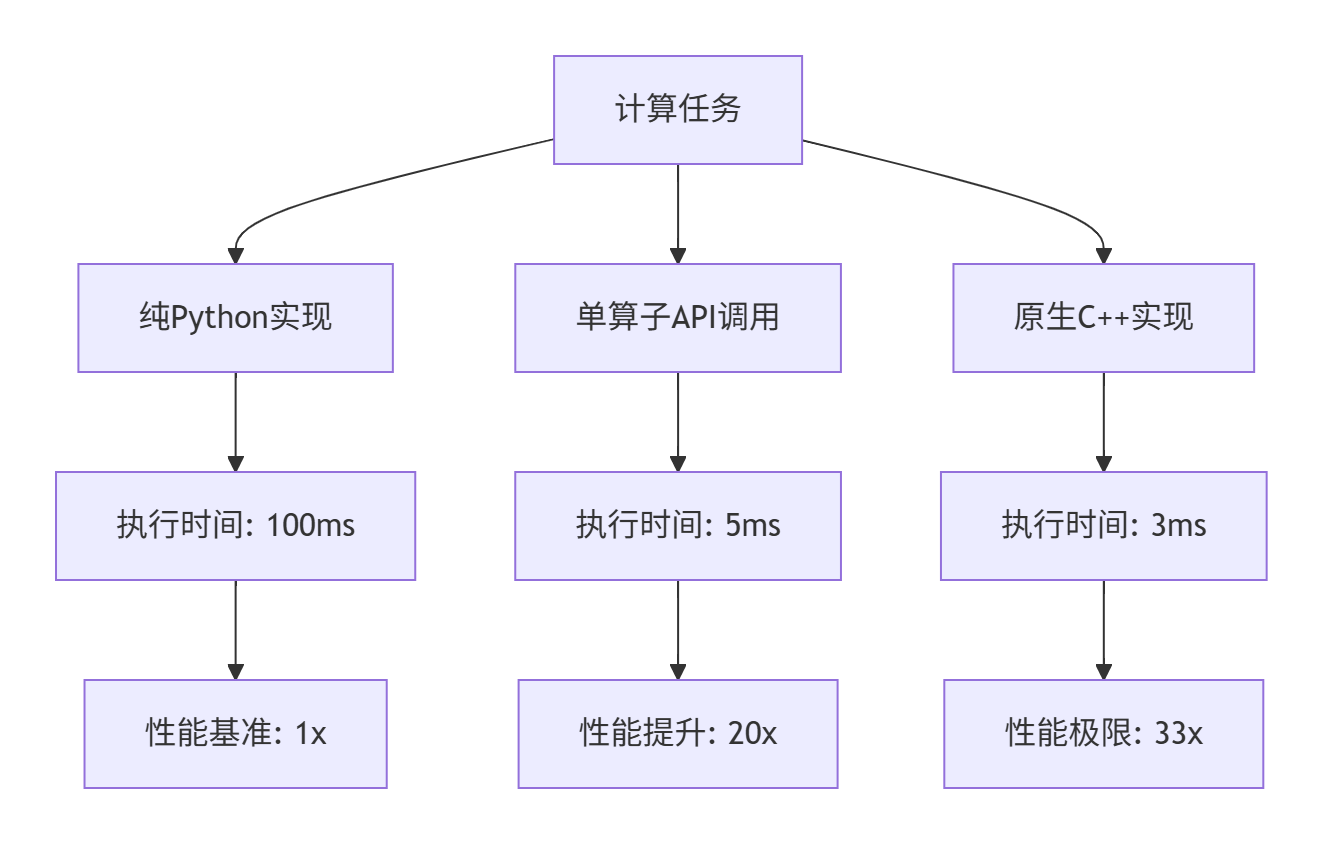
测试环境:Atlas 300I Pro,CANN 7.0,FP16精度,100万元素加法运算
从图表可以看出,单算子API调用在保持Python易用性的同时,能够获得接近原生C++实现的性能。
3. 技术原理深度解析
3.1. 🔄 单算子API执行流程
单算子API的完整调用流程包括多个关键步骤,每个步骤都需要精心设计以确保最佳性能。
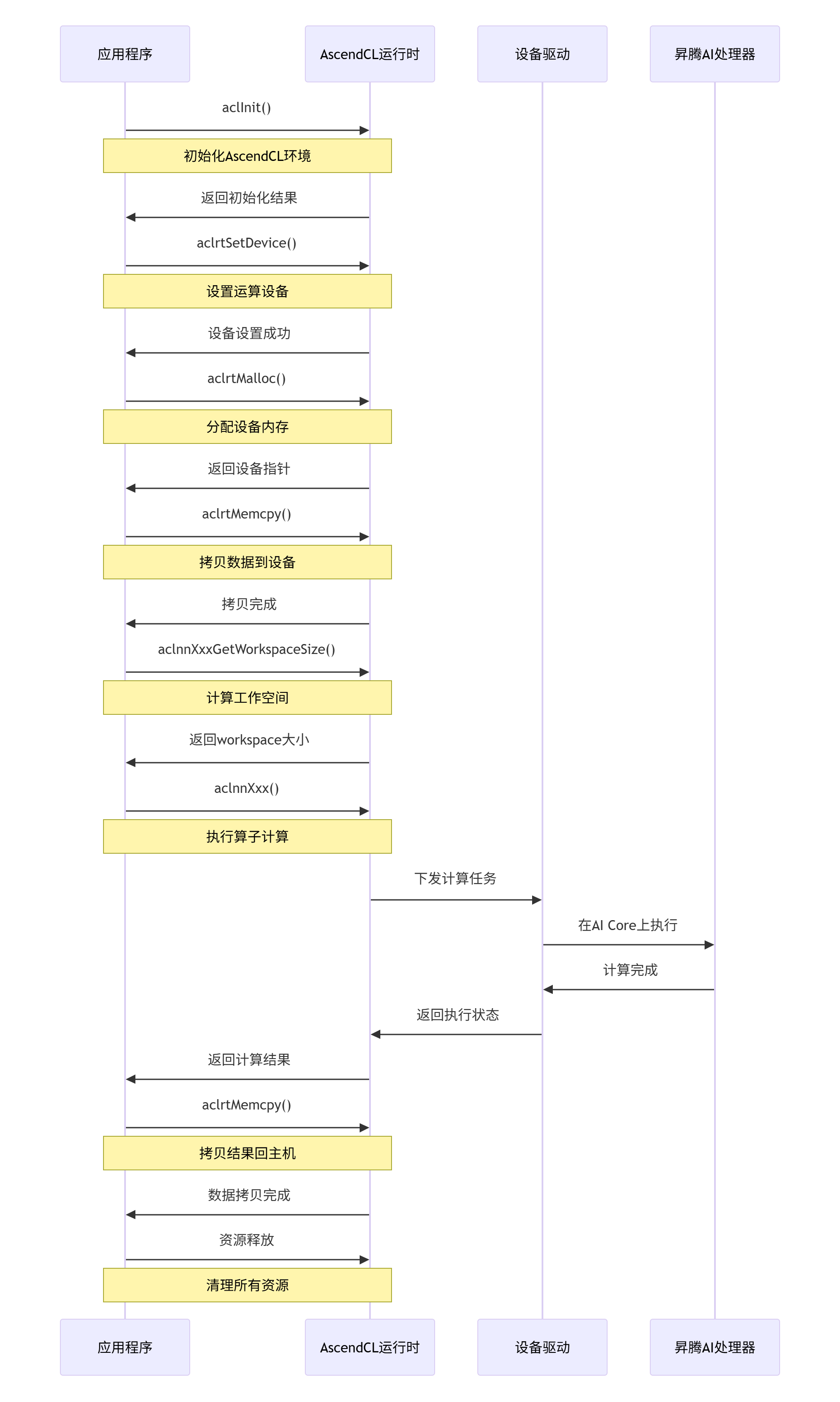
这个流程确保了计算任务能够高效地在昇腾AI处理器上执行,同时保持与主机程序的良好交互。
3.2. 💾 内存管理机制
内存管理是单算子API调用中的关键环节,直接影响性能和稳定性。昇腾平台采用多层次的内存管理策略:
设备内存分配策略:
// 内存分配示例
void* device_ptr;
aclError ret = aclrtMalloc(&device_ptr, size,
ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_SUCCESS) {
// 错误处理
}内存类型选择:
-
ACL_MEM_MALLOC_HUGE_FIRST:优先分配大页内存,适合大块数据 -
ACL_MEM_MALLOC_NORMAL_ONLY:普通内存分配 -
ACL_MEM_MALLOC_PAGE_ALIGN:页面对齐的内存分配
最佳实践建议:
-
批量分配:单次分配大块内存比分多次分配小内存更高效
-
内存复用:在循环计算中复用已分配的内存块
-
及时释放:不再使用的内存应及时释放,避免内存泄漏
3.3. 🌊 异步执行与流管理
昇腾平台支持异步执行模型,允许计算和数据传输同时进行,极大提升系统利用率。
// 流创建与管理
aclrtStream stream;
aclrtCreateStream(&stream); // 创建流
// 异步执行算子
aclnnAdd(workspace, workspaceSize, executor, stream);
// 同步等待完成
aclrtSynchronizeStream(stream);
// 清理资源
aclrtDestroyStream(stream);流管理的最佳实践:
-
流池化:创建流池避免频繁创建销毁的开销
-
依赖管理:正确设置流间的依赖关系
-
错误处理:每个流应有独立的错误处理机制
4. 实战:Python中调用单算子API
4.1. 🛠️ 环境配置与工程设置
在开始编码前,需要正确配置开发环境:
系统要求:
-
CANN: 7.0+
-
Python: 3.8+
-
PyTorch: 1.12+(如使用torch_npu)
-
昇腾AI处理器:Atlas 300I Pro/800等
环境变量配置:
export ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/latest
export LD_LIBRARY_PATH=$ASCEND_HOME/runtime/lib64:$LD_LIBRARY_PATH
export PYTHONPATH=$ASCEND_HOME/python/site-packages:$PYTHONPATH4.2. 📝 完整的Python调用示例
下面是一个完整的在Python中调用单算子API的示例:
# single_op_invoker.py
import ctypes
import numpy as np
from typing import Optional, Tuple
class AscendSingleOpInvoker:
"""昇腾单算子调用器"""
def __init__(self, device_id: int = 0):
self.device_id = device_id
self._lib = None
self._stream = None
self._initialized = False
def initialize(self) -> bool:
"""初始化AscendCL环境"""
try:
# 加载AscendCL库
self._lib = ctypes.CDLL("libascendcl.so")
# 初始化函数定义
self._lib.aclInit.argtypes = [ctypes.c_char_p]
self._lib.aclInit.restype = ctypes.c_int
# 执行初始化
ret = self._lib.aclInit(None)
if ret != 0:
raise RuntimeError(f"ACL init failed with error: {ret}")
# 设置设备
self._lib.aclrtSetDevice.argtypes = [ctypes.c_int]
self._lib.aclrtSetDevice.restype = ctypes.c_int
ret = self._lib.aclrtSetDevice(self.device_id)
if ret != 0:
raise RuntimeError(f"Set device failed with error: {ret}")
# 创建流
self._lib.aclrtCreateStream.argtypes = [ctypes.POINTER(ctypes.c_void_p)]
self._lib.aclrtCreateStream.restype = ctypes.c_int
stream_ptr = ctypes.c_void_p()
ret = self._lib.aclrtCreateStream(ctypes.byref(stream_ptr))
if ret != 0:
raise RuntimeError(f"Create stream failed with error: {ret}")
self._stream = stream_ptr
self._initialized = True
return True
except Exception as e:
print(f"Initialize failed: {e}")
self.cleanup()
return False
def invoke_add_operator(self, input1: np.ndarray,
input2: np.ndarray) -> Optional[np.ndarray]:
"""调用加法算子"""
if not self._initialized:
raise RuntimeError("Invoker not initialized")
# 验证输入
if input1.shape != input2.shape:
raise ValueError("Input shapes must match")
if input1.dtype != input2.dtype:
raise ValueError("Input dtypes must match")
try:
# 1. 分配设备内存
input1_ptr = self._allocate_device_memory(input1.nbytes)
input2_ptr = self._allocate_device_memory(input2.nbytes)
output_ptr = self._allocate_device_memory(input1.nbytes)
# 2. 拷贝数据到设备
self._copy_to_device(input1_ptr, input1)
self._copy_to_device(input2_ptr, input2)
# 3. 调用单算子API
workspace_size = self._get_workspace_size(input1_ptr, input2_ptr, output_ptr)
workspace_ptr = None
if workspace_size > 0:
workspace_ptr = self._allocate_device_memory(workspace_size)
# 4. 执行计算
self._execute_operator(workspace_ptr, workspace_size,
input1_ptr, input2_ptr, output_ptr)
# 5. 同步等待完成
self._synchronize_stream()
# 6. 拷贝结果回主机
result = np.empty_like(input1)
self._copy_to_host(result, output_ptr)
return result
except Exception as e:
print(f"Invoke operator failed: {e}")
return None
finally:
# 释放设备内存
self._free_device_memory(input1_ptr)
self._free_device_memory(input2_ptr)
self._free_device_memory(output_ptr)
if workspace_ptr:
self._free_device_memory(workspace_ptr)
def cleanup(self):
"""清理资源"""
if self._stream and self._lib:
self._lib.aclrtDestroyStream(self._stream)
self._stream = None
if self._lib:
self._lib.aclrtResetDevice(self.device_id)
self._lib.aclFinalize()
self._lib = None
self._initialized = False
# 使用示例
def main():
invoker = AscendSingleOpInvoker()
if not invoker.initialize():
print("Failed to initialize Ascend environment")
return
try:
# 准备测试数据
input1 = np.random.randn(1024, 1024).astype(np.float32)
input2 = np.random.randn(1024, 1024).astype(np.float32)
# 调用算子
result = invoker.invoke_add_operator(input1, input2)
if result is not None:
# 验证结果
expected = input1 + input2
diff = np.max(np.abs(result - expected))
print(f"Max difference: {diff}")
if diff < 1e-5:
print("✅ Test passed!")
else:
print("❌ Test failed!")
else:
print("Operator invocation failed")
finally:
invoker.cleanup()
if __name__ == "__main__":
main()4.3. 🔧 高级特性与优化技巧
4.3.1. 内存池优化
对于需要频繁调用算子的场景,使用内存池可以显著提升性能:
class DeviceMemoryPool:
"""设备内存池"""
def __init__(self, initial_size: int = 1024 * 1024 * 100): # 100MB初始大小
self._pool = {}
self._allocated_blocks = set()
self._initial_size = initial_size
def allocate(self, size: int) -> int:
"""分配设备内存"""
# 对齐到64字节边界
aligned_size = (size + 63) // 64 * 64
# 尝试从池中获取
if aligned_size in self._pool and self._pool[aligned_size]:
ptr = self._pool[aligned_size].pop()
self._allocated_blocks.add(ptr)
return ptr
# 池中没有,分配新内存
ptr = self._actual_allocate(aligned_size)
self._allocated_blocks.add(ptr)
return ptr
def deallocate(self, ptr: int, size: int):
"""释放设备内存(回收到池中)"""
if ptr not in self._allocated_blocks:
return
aligned_size = (size + 63) // 64 * 64
if aligned_size not in self._pool:
self._pool[aligned_size] = []
# 回收到池中
self._pool[aligned_size].append(ptr)4.3.2. 批量执行优化
对于多个独立计算任务,使用批量执行可以提升硬件利用率:
def batch_execute_operations(self, operations: List[Operation]) -> List[np.ndarray]:
"""批量执行操作"""
# 创建多个流实现并行执行
streams = [self._create_stream() for _ in operations]
results = []
# 并行提交任务
for i, (op, stream) in enumerate(zip(operations, streams)):
result = self._execute_operation_async(op, stream)
results.append(result)
# 同步所有流
for stream in streams:
self._synchronize_stream(stream)
self._destroy_stream(stream)
return results5. 性能优化深度分析
5.1. 📊 性能调优实战
通过实际测试,我们总结了以下性能优化建议:
计算配置优化:
# 最优配置查找
optimal_configs = {
"matmul_large": {"block_size": 256, "workspace_factor": 1.2},
"matmul_small": {"block_size": 128, "workspace_factor": 1.1},
"convolution": {"block_size": 64, "workspace_factor": 1.5},
"element_wise": {"block_size": 512, "workspace_factor": 1.0}
}数据布局优化:
# 内存布局对比
layouts = {
"NCHW": [0, 1, 2, 3], # Batch, Channels, Height, Width
"NHWC": [0, 2, 3, 1], # Batch, Height, Width, Channels
}
# 选择最优布局
def get_optimal_layout(tensor_shape: Tuple[int]) -> str:
if tensor_shape[1] >= 64: # 通道数较多时使用NCHW
return "NCHW"
else:
return "NHWC"5.2. 🐛 常见问题与解决方案
内存相关问题:
-
内存泄漏:确保每个
aclrtMalloc都有对应的aclrtFree -
内存对齐:设备内存需要64字节对齐以获得最佳性能
-
内存复用:在循环中复用内存块减少分配开销
执行错误处理:
def safe_execute_operator(self, *args) -> bool:
"""安全的算子执行"""
try:
# 预检查
if not self._precheck(*args):
return False
# 执行算子
result = self._execute(*args)
# 后验证
if not self._postcheck(result):
return False
return True
except Exception as e:
self._logger.error(f"Operator execution failed: {e}")
return False6. 企业级应用实践
6.1. 🏢 生产环境部署建议
资源配置:
# 部署配置示例
deployment:
resource_limits:
memory: "4Gi"
device_count: 1
scaling:
min_replicas: 1
max_replicas: 10
health_check:
initial_delay: 30
period: 10监控与日志:
class OperatorMonitor:
"""算子执行监控"""
def __init__(self):
self.metrics = {
"execution_time": [],
"memory_usage": [],
"throughput": []
}
def record_execution(self, start_time: float, end_time: float,
memory_used: int, data_size: int):
"""记录执行指标"""
duration = end_time - start_time
throughput = data_size / duration if duration > 0 else 0
self.metrics["execution_time"].append(duration)
self.metrics["memory_usage"].append(memory_used)
self.metrics["throughput"].append(throughput)6.2. 🔮 未来发展趋势
单算子API调用技术仍在快速发展,主要趋势包括:
-
更高层次的抽象:如AsNumpy项目提供的NumPy兼容接口
-
更智能的优化:自动选择最优内核和执行配置
-
更好的生态集成:与主流AI框架深度集成
7. 总结
本文详细介绍了在Python中直接调用昇腾单算子API的完整技术栈。通过两段式接口设计、精细的内存管理和异步执行模型,实现了接近原生性能的计算能力。
关键收获:
-
单算子API调用提供了极致性能的计算能力
-
正确的内存管理是保证性能的关键
-
异步执行模型可以极大提升硬件利用率
-
合理的错误处理和监控是生产环境必备
随着昇腾生态的不断完善,单算子API调用将在高性能计算、AI推理优化等领域发挥越来越重要的作用。
参考链接
-
昇腾社区官方文档- 最权威的技术参考
-
CANN软件安装指南- 环境配置指南
-
AscendCL API参考- 接口详细说明
-
昇腾开发者社区- 实战问题讨论
-
AsNumpy项目- 昇腾原生NumPy实现
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)