
RAG系统架构设计中的向量数据库选型:从原理到企业级实践
本文深度解析7大主流向量数据库(Pinecone、Milvus、Qdrant等)的技术特性与选型策略。通过架构对比、性能测试数据和实战案例,为不同业务阶段(PoC/生产/大规模)提供针对性选型建议,涵盖性能优化、成本控制和容灾设计等关键维度。特别针对RAG系统需求,分析各数据库在延迟、扩展性和多模态支持等方面的表现,并展望昇腾AscendC等异构计算技术的融合前景。最终给出基于业务场景的选型决策框
目录
2.2.2 nytimes-256-angular数据集性能
摘要
向量数据库已成为企业级RAG系统的核心基础设施,其选型直接影响检索质量、成本结构和系统可扩展性。本文深入解析七大主流向量数据库(Pinecone、Chroma、Weaviate、Qdrant、Milvus、PgVector、Redis)的架构设计理念、性能特性及应用场景,提供从原型开发到大规模部署的完整选型策略。通过性能对比数据、实战代码示例及企业级案例,帮助技术团队在性能、延迟与成本之间找到最佳平衡点,构建稳健高效的RAG系统。
一、向量数据库:RAG系统的“记忆引擎”
1.1 为什么向量数据库是RAG的关键基础设施?
RAG(Retrieval-Augmented Generation)系统的本质,是让大语言模型基于企业知识回答问题而不是凭空猜测。其核心流程包含三个关键环节:
-
文本向量化(Embedding):将文本转换为高维向量表示
-
相似性检索(Similarity Search):在向量空间检索最相似内容
-
增强生成(Augmented Generation):将检索结果与问题一起输入LLM生成答案
其中,第二步的向量检索是整个系统稳定性和质量的核心。如果向量数据库检索不准、延迟过高或扩展性弱,后续LLM再强大也无济于事。一个生产级的RAG系统对向量数据库有严格要求:
-
高性能ANN索引:支持近似最近邻算法,在召回率与速度间取得平衡
-
低延迟检索:热数据查询延迟低于30ms,保证用户体验
-
水平可扩展:支持分片、分布式部署,应对数据增长
-
混合查询能力:支持向量检索+元数据过滤的混合搜索
-
增量更新:支持实时或近实时的数据更新
向量数据库实质上是企业级RAG的“检索引擎”+“知识记忆体”,决定了系统的智能上限。
1.2 向量数据库核心技术原理
1.2.1 近似最近邻(ANN)算法
精确最近邻搜索在海量高维数据中计算成本极高,实际生产系统多采用近似最近邻算法。主流ANN算法对比:
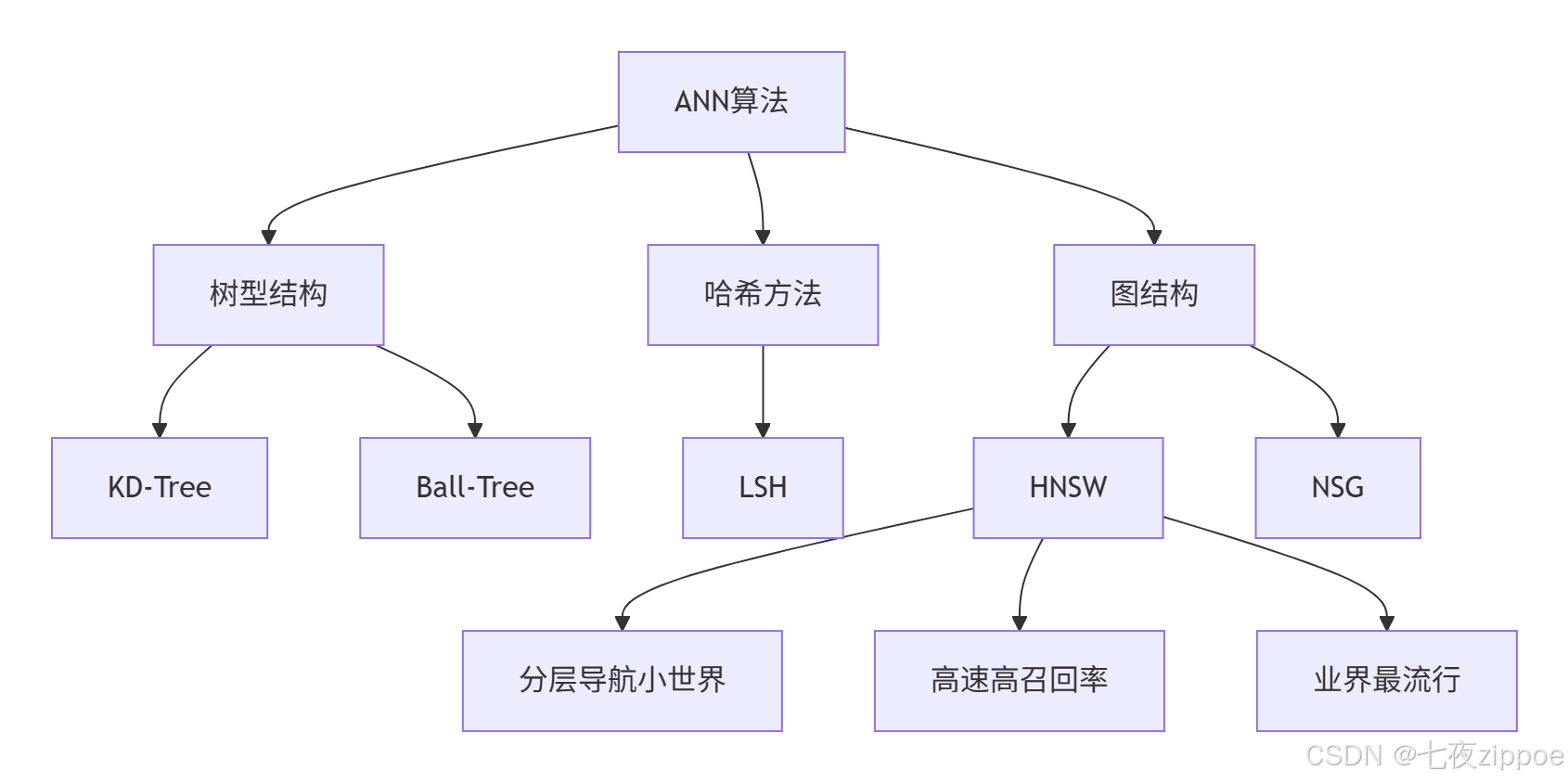
HNSW(Hierarchical Navigable Small World) 是目前最流行的ANN算法,结合了可导航小世界图和层次分解的优点,在速度和精度间取得良好平衡。其核心思想是通过构建多层图结构,从上到下粒度逐渐变细,实现快速导航。
1.2.2 向量相似度度量
不同的相似度度量方法适用于不同场景:
|
度量方法 |
公式 |
适用场景 |
|---|---|---|
|
余弦相似度 |
cos(θ) = A·B/‖A‖‖B‖ |
文本相似度计算,忽略向量大小 |
|
欧氏距离 |
d = √Σ(a_i - b_i)² |
空间距离敏感场景 |
|
内积相似度 |
A·B = Σa_i b_i |
向量已归一化时的高效计算 |
大多数向量数据库支持多种相似度度量方式,根据数据特性和应用场景选择合适的方法。
二、主流向量数据库深度横向评测
2.1 七大向量数据库架构与特性对比
2.1.1 Pinecone:全托管云服务标杆
架构特点:完全托管的SaaS服务,用户无需关心基础设施运维。采用自动分片、多副本和自动扩容设计。
核心优势:
-
零运维:专业团队负责底层维护,开发者专注业务逻辑
-
高性能:针对企业级负载优化,延迟表现优秀
-
高可用:提供SLA保障,自动故障转移
局限性:
-
成本较高:按使用量计费,大规模应用成本显著
-
厂商锁定:数据迁移和系统重构成本高
-
网络延迟:国内访问可能不稳定
适用场景:预算充足、快速上线的AI产品团队,适合PoC验证和中小规模生产环境。
2.1.2 Milvus:大规模分布式事实标准
架构特点:专为超大规模向量搜索设计的云原生架构,组件包括Proxy、Coordinator、DataNode和IndexNode。
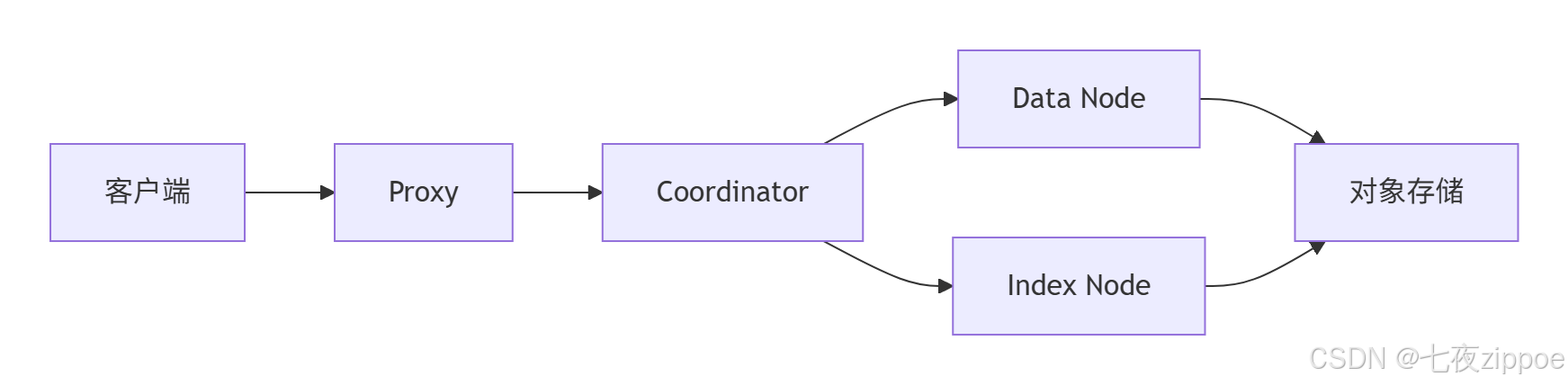
核心优势:
-
海量数据支持:支持PB级向量数据,千亿级别向量检索
-
高扩展性:天生为分布式设计,可水平扩展
-
多模态支持:支持图像、视频、音频等多模态数据
局限性:
-
运维复杂:需要Kubernetes等容器编排平台
-
资源消耗大:集群部署需要较高硬件配置
-
过度设计:对小规模项目过于复杂
适用场景:超大规模企业平台、AI工厂、多模态RAG系统。
2.1.3 Qdrant:开源阵营的性能平衡者
架构特点:基于Rust开发的高性能向量数据库,支持内存和磁盘混合存储模式。提供云服务(Qdrant Cloud)和自托管两种部署方式。
核心优势:
-
性能优异:Rust实现,资源利用率高,延迟低
-
功能全面:支持过滤、多向量、集合等高级功能
-
开源灵活:Apache 2.0协议,可自由修改和部署
技术特性:
-
支持多种数据类型和索引方式
-
提供丰富的SDK(Python、JS、Go、Java等)
-
内置分布式支持和故障恢复机制
适用场景:对性能有要求的生产级RAG系统,中等至大规模数据场景。
表:Qdrant技术规格详情
|
特性 |
支持情况 |
备注 |
|---|---|---|
|
最大向量维度 |
无限制 |
适应各种嵌入模型 |
|
索引类型 |
HNSW |
高性能图索引 |
|
分布式 |
支持 |
分片和副本 |
|
过滤检索 |
支持 |
元数据条件过滤 |
2.1.4 其他主流方案对比
表:七大向量数据库全面对比
|
数据库 |
开发语言 |
开源协议 |
最大维度 |
特色功能 |
适用场景 |
|---|---|---|---|---|---|
|
Pinecone |
闭源 |
商业 |
无限制 |
全托管、自动缩放 |
快速上线、运维敏感型 |
|
Milvus |
Go/C++ |
Apache-2.0 |
32768 |
分布式、多模态 |
超大规模数据平台 |
|
Qdrant |
Rust |
Apache-2.0 |
无限制 |
高性能、过滤强大 |
生产级RAG系统 |
|
Weaviate |
Go |
BSD-3 |
65535 |
图查询、混合搜索 |
知识图谱复杂结构 |
|
Chroma |
Python |
Apache-2.0 |
无限制 |
轻量级、易部署 |
原型开发、个人项目 |
|
PgVector |
C |
PostgresQL |
2000 |
SQL集成、一致性 |
已有PG生态团队 |
|
Redis |
C |
Redis协议 |
无限制 |
内存级延迟 |
实时推荐、高速缓存 |
2.2 性能基准测试数据分析
根据ANN-Benchmarks和实际应用测试,不同向量数据库在各类数据集上表现各异:
2.2.1 glove-100-angular数据集性能
在120万向量、100维度的glove数据集上:
-
Milvus在召回率低于0.95时吞吐量最高
-
Weaviate索引体积最小,构建时间适中
-
Qdrant在召回率超过0.95时表现稳定
2.2.2 nytimes-256-angular数据集性能
在29万向量、256维度的新闻数据集上:
-
Weaviate构建时间最长但索引体积最小
-
Milvus索引体积最大(约440MB)但查询性能优秀
-
各数据库在高维数据上性能差距缩小
实战洞察:选择向量数据库时不能仅看峰值性能,要结合实际数据特征和业务需求。对于文本类RAG系统,100-300维的向量较为常见,Qdrant和Weaviate在此维度范围内表现均衡。
三、企业级选型策略与实战指南
3.1 基于业务发展阶段的选择策略
3.1.1 MVP阶段:速度优先
推荐方案:Chroma或PgVector
选型理由:
-
快速验证:最小化运维开销,专注核心流程验证
-
低成本:开源方案无需额外费用,PgVector可复用现有数据库
-
易集成:与主流AI框架(LangChain、LlamaIndex)集成友好
实战代码示例:Chroma快速上手
# 环境要求:python>=3.8, chromadb>=0.4.0
import chromadb
from sentence_transformers import SentenceTransformer
# 初始化客户端和模型
client = chromadb.Client()
collection = client.create_collection("knowledge_base")
model = SentenceTransformer("all-MiniLM-L6-v2")
# 准备和嵌入文档
documents = [
"昇腾Ascend C是华为自研的AI编程语言",
"向量数据库是RAG系统的核心组件",
"大模型时代需要专用基础设施"
]
embeddings = model.encode(documents).tolist()
# 存入向量数据库
ids = [str(i) for i in range(len(documents))]
collection.add(
documents=documents,
embeddings=embeddings,
ids=ids
)
# 查询相似内容
query = "什么是RAG的关键基础设施?"
query_embedding = model.encode([query]).tolist()
results = collection.query(
query_embeddings=query_embedding,
n_results=2
)
print("最相似结果:", results['documents'][0])关键技术指标:在此阶段应重点关注检索→LLM→反馈的闭环构建,评估问题召回率和文本匹配效果,而非过早优化性能。
3.1.2 初期生产阶段:稳定性与功能平衡
推荐方案:Qdrant或Weaviate
选型考量:
-
多副本高可用:确保服务连续性
-
监控告警:完善的监控指标体系
-
索引更新:支持增量更新,避免全量重建
Qdrant生产部署示例:
# docker-compose.prod.yml
version: '3.8'
services:
qdrant:
image: qdrant/qdrant:latest
restart: unless-stopped
ports:
- "6333:6333"
- "6334:6334"
volumes:
- ./qdrant_storage:/storage
environment:
- QDRANT__STORAGE__STORAGE_PATH=/storage
- QDRANT__CLUSTER__ENABLED=true
deploy:
resources:
limits:
memory: 2G
cpus: '2'性能调优要点:
-
根据数据量调整HNSW参数(ef_construct, m)
-
配置合理的分片策略,平衡负载
-
启用持久化存储,防止数据丢失
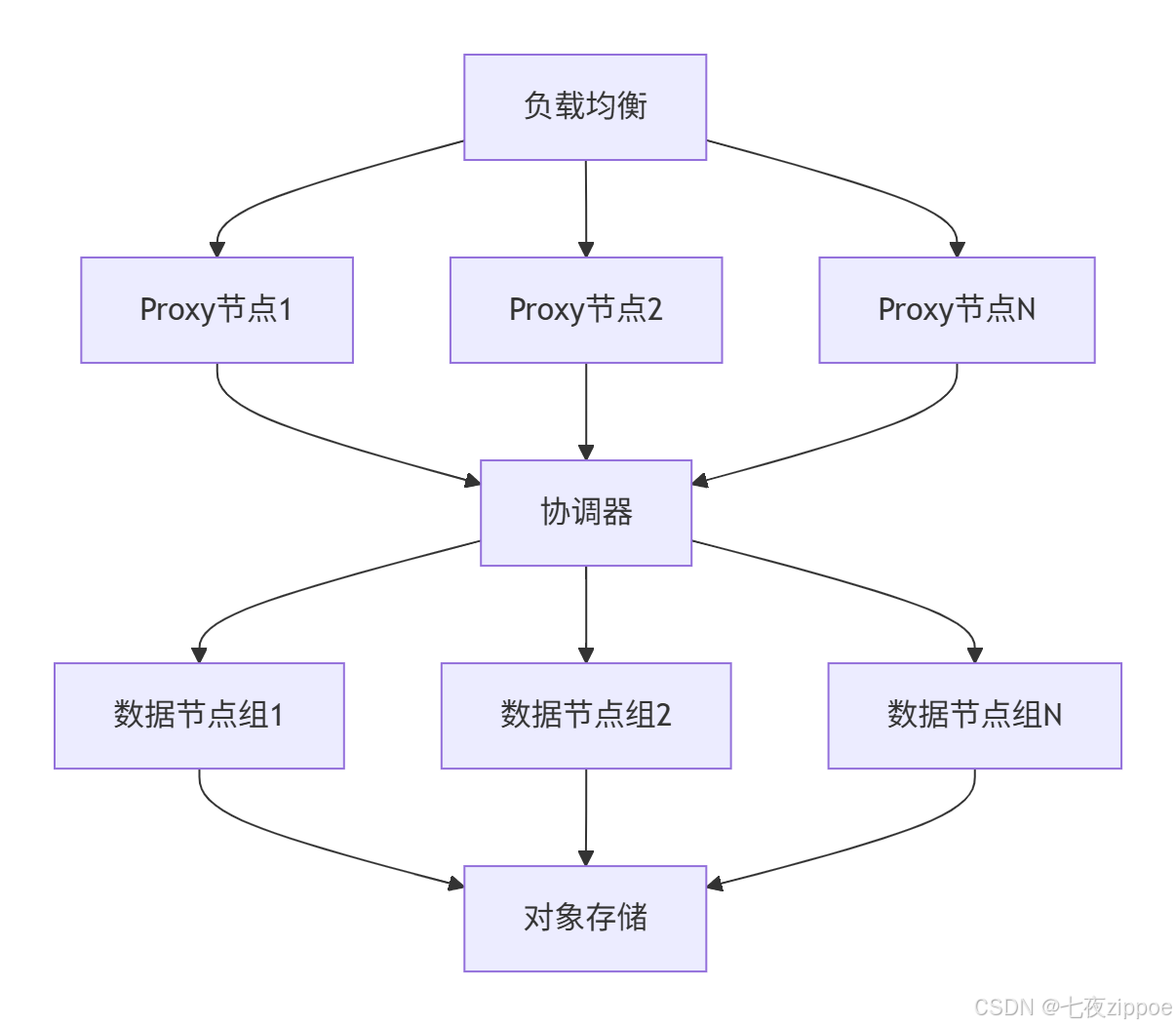
3.1.3 大规模增长阶段:扩展性与分布式能力
推荐方案:Milvus或Pinecone
选型决策矩阵:
|
考量维度 |
Milvus |
Pinecone |
|---|---|---|
|
运维需求 |
需要专业团队 |
全托管,零运维 |
|
成本结构 |
硬件+人力成本 |
按使用量付费 |
|
控制粒度 |
完全控制,深度定制 |
有限配置,标准服务 |
|
数据合规 |
完全可控,满足严格合规 |
依赖厂商合规认证 |
大规模部署架构:
3.2 性能、延迟、成本的三角平衡
企业级决策需要在性能、延迟和成本之间找到平衡点。以下是根据数据量规模的推荐方案:
|
数据规模 |
推荐方案 |
理由 |
预期延迟 |
月成本估算 |
|---|---|---|---|---|
|
< 10M向量 |
PgVector/Chroma |
成本低、维护简单 |
< 50ms |
$100-500 |
|
10M-200M向量 |
Qdrant/Weaviate |
性能与功能平衡 |
< 30ms |
$500-2000 |
|
200M-10B向量 |
Milvus/Pinecone |
大规模分布式能力 |
< 50ms |
$2000+ |
|
高速实时(<10ms) |
Redis |
内存级延迟 |
< 10ms |
内存成本为主 |
成本优化技巧:
-
使用标量量化减少存储空间
-
采用分层存储(热数据内存+冷数据磁盘)
-
合理配置索引参数,平衡精度与速度
3.3 针对不同RAG场景的专项选择
3.3.1 客服问答系统(低延迟、高查询量)
关键技术需求:
-
查询延迟低于30ms
-
高并发支持(千级QPS)
-
高可用性(99.9%+ SLA)
推荐方案:Redis或Qdrant
优化策略:
-
使用内存存储热数据
-
实现查询缓存层
-
配置连接池避免频繁建立连接
3.3.2 企业知识库(复杂结构、多租户)
关键技术需求:
-
结构化元数据管理
-
多租户隔离
-
版本控制和权限管理
推荐方案:Weaviate或Milvus
架构优势:
-
Weaviate的Schema-first设计适合复杂知识结构
-
内置多租户namespace隔离
-
图查询能力支持关联知识发现
3.3.3 多模态搜索系统
关键技术需求:
-
支持文本、图像、视频等多模态向量
-
跨模态检索能力
-
超大向量维度支持
推荐方案:Milvus
实战示例:多模态向量统一检索
# 使用Milvus实现多模态检索
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 连接Milvus集群
connections.connect("default", host="localhost", port="19530")
# 定义多模态向量Schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="text_vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="image_vector", dtype=DataType.FLOAT_VECTOR, dim=1024),
FieldSchema(name="metadata", dtype=DataType.JSON)
]
schema = CollectionSchema(fields, "多模态知识库")
collection = Collection("multimodal_kb", schema)
# 创建混合索引
index_params = {
"index_type": "HNSW",
"metric_type": "L2",
"params": {"M": 8, "efConstruction": 64}
}
collection.create_index("text_vector", index_params)
collection.create_index("image_vector", index_params)四、企业级最佳实践与性能优化
4.1 向量数据库不仅是“存储”:可运维性考量
生产环境中的向量数据库需要具备完整的可观测性和可维护性:
4.1.1 向量索引重建策略
全量重建vs增量重建:
-
全量重建:保证索引最优性,但资源消耗大,期间服务不可用
-
增量重建:服务不中断,但索引可能不是最优状态
实践建议:大型系统采用滚动重建策略,将数据分片后轮流重建,平衡性能与可用性。
4.1.2 多租户与权限控制
企业级系统需要完善的隔离和权限管理:
-
命名空间隔离:不同业务部门数据完全隔离
-
RBAC权限模型:基于角色的访问控制
-
查询配额限制:防止异常查询影响整体服务
4.1.3 可观测性指标体系
监控向量数据库的关键指标:
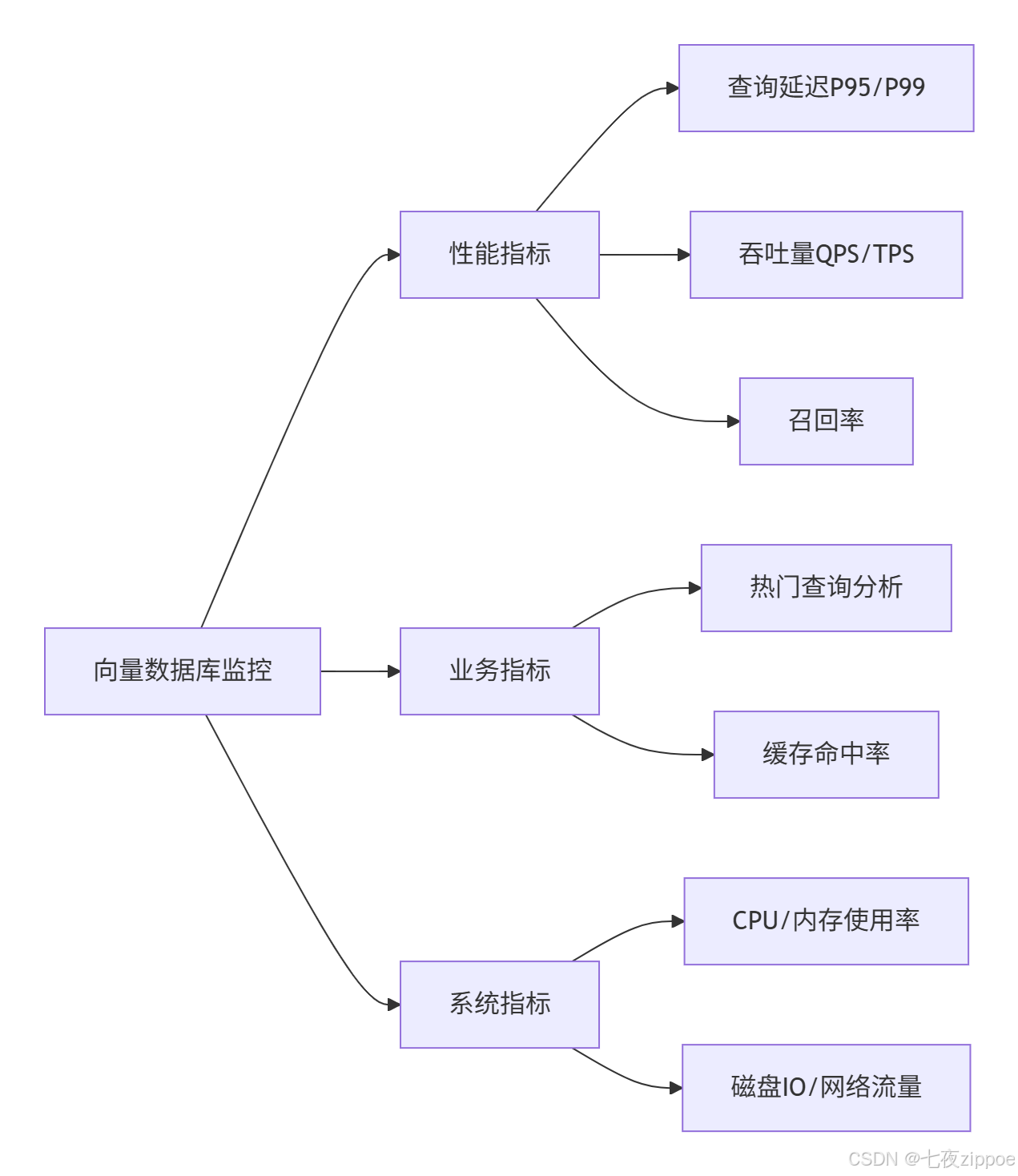
4.2 性能优化高级技巧
4.2.1 索引参数调优
HNSW索引关键参数优化指南:
# Qdrant HNSW优化配置示例
from qdrant_client import QdrantClient
from qdrant_client.http import models
client = QdrantClient("localhost", port=6333)
client.create_collection(
collection_name="optimized_collection",
vectors_config=models.VectorParams(
size=768,
distance=models.Distance.COSINE
),
hnsw_config=models.HnswConfigDiff(
m=16, # 层内最大连接数,影响精度和内存
ef_construct=100, # 索引构建时的候选集大小
full_scan_threshold=10000, # 全扫描阈值
max_indexing_threads=4 # 并行索引线程数
)
)参数调优原则:
-
内存充足时增加
m和ef_construct提升精度 -
高吞吐场景适当降低
ef_search减少延迟 -
根据CPU核心数设置索引线程,避免过度竞争
4.2.2 查询优化策略
-
分级检索:先粗筛后精排,平衡速度与精度
-
查询剪枝:利用元数据过滤减少搜索空间
-
批量查询:合并请求减少网络开销
# 分级检索优化示例
def hierarchical_search(query_vector, metadata_filters, coarse_k=1000, fine_k=10):
# 第一阶段:粗筛,低精度高速检索
coarse_results = collection.search(
query_vector=query_vector,
query_filter=metadata_filters, # 元数据过滤剪枝
limit=coarse_k,
params={"hnsw_ef": 32} # 较低精度设置
)
# 第二阶段:精排,高精度重排序
reranked_results = rerank_model.rerank(
query=query_text,
documents=coarse_results
)
return reranked_results[:fine_k]4.3 故障排查与容灾设计
4.3.1 常见问题解决方案
高延迟问题排查路径:
-
检查系统资源(CPU、内存、网络)
-
分析查询模式(向量维度、并发数)
-
审查索引配置(HNSW参数)
-
评估数据分布(是否需要重新分片)
召回率低问题排查:
-
验证嵌入模型质量
-
调整相似度度量方法
-
优化索引参数(ef、m)
-
检查数据预处理流程
4.3.2 容灾与备份策略
多活区域部署架构:
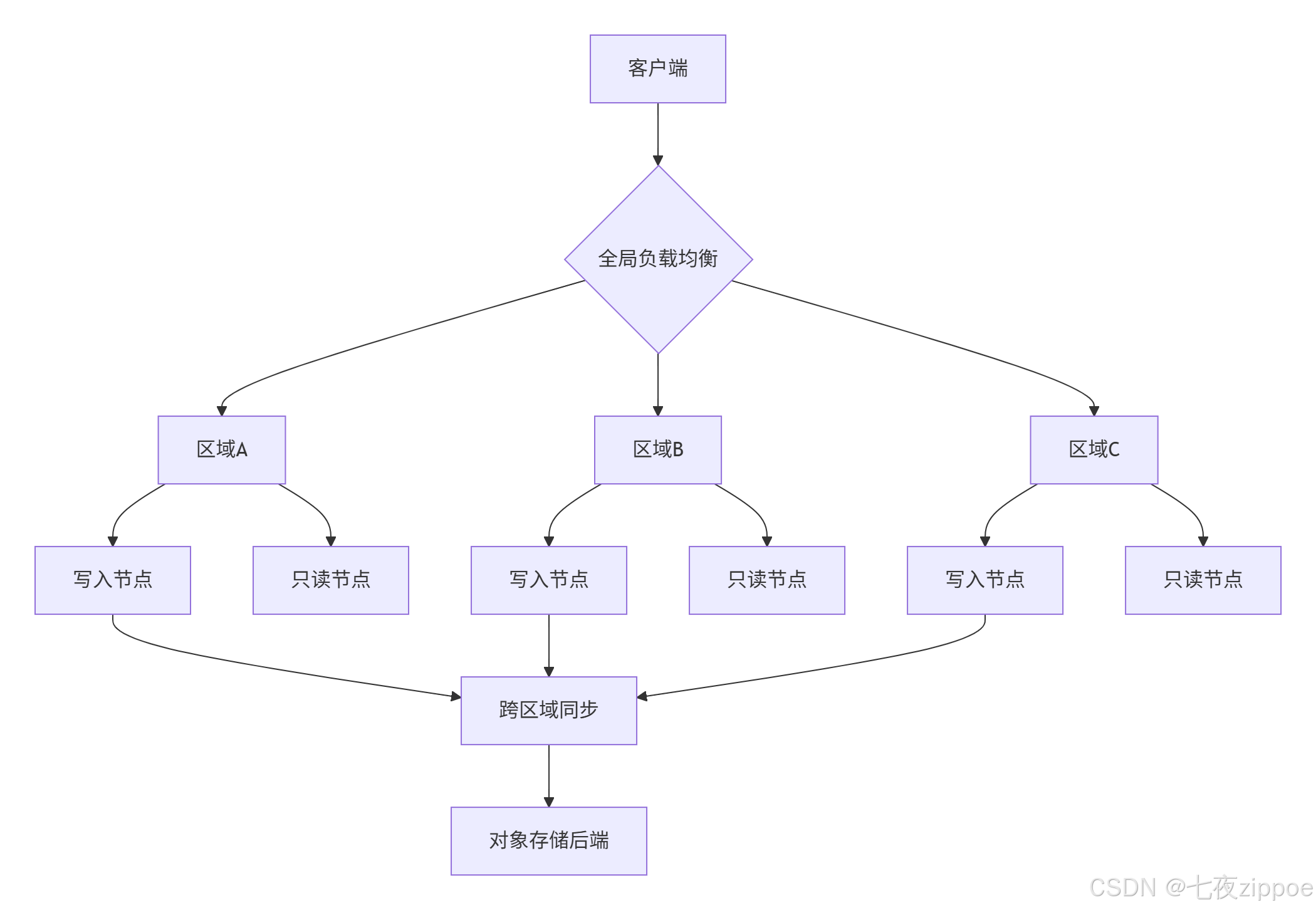
备份策略:
-
实时增量备份:WAL日志实时同步到对象存储
-
全量快照备份:每日全量快照,保留7天
-
跨区域复制:关键数据异步复制到灾备区域
五、技术选型的未来演进趋势
5.1 向量数据库技术发展方向
-
云原生深度融合:Kubernetes原生调度、弹性伸缩成为标配
-
AI-Native架构:面向大模型工作负载的特化优化
-
多模统一查询:支持向量+标量+全文的联合查询
-
异构计算支持:更好利用GPU、NPU等硬件加速
5.2 昇腾Ascend C与向量数据库的融合前景
作为华为自研的AI编程语言,昇腾Ascend C在向量计算场景具有显著优势:
// 示例:使用Ascend C加速向量索引构建
class VectorIndexBuilder {
public:
// 利用AI Core并行计算优势加速索引构建
void build_hnsw_index(const std::vector<std::vector<float>>& vectors) {
// 1. 数据加载到AI Core
// 2. 并行计算距离矩阵
// 3. 高效构建HNSW图结构
}
// 批量查询优化
std::vector<SearchResult> batch_search(const std::vector<std::vector<float>>& queries) {
// 利用多核并行处理批量查询
// 显著提升吞吐量
}
};融合优势:
-
性能提升:针对向量计算特化优化,比通用CPU实现显著提速
-
能效优化:相同任务功耗降低30-50%
-
端边协同:支持边缘场景部署,减少云端传输开销
六、总结与建议
6.1 选型决策框架
基于业务阶段、数据规模和团队能力的决策框架:
-
评估现状:明确当前数据量、查询模式、团队技能栈
-
预测增长:预估未来1-3年数据增长曲线和性能需求
-
技术验证:对候选方案进行概念验证测试
-
成本评估:计算3年总体拥有成本(TCO)
-
制定路线:规划从当前到目标的演进路径
6.2 最终选型建议表
|
业务场景 |
首选方案 |
次选方案 |
关键考量 |
|---|---|---|---|
|
初创/PoC |
Chroma |
Pinecone |
上手速度、开发效率 |
|
中小企业生产 |
Qdrant |
Weaviate |
功能全面性、运维复杂度 |
|
大规模企业 |
Milvus |
专用向量扩展 |
扩展性、定制能力 |
|
实时高速场景 |
Redis |
Qdrant |
延迟敏感、内存充足 |
|
已有PG生态 |
PgVector |
扩展方案 |
技术栈统一、迁移成本 |
|
多模态复杂查询 |
Weaviate |
Milvus |
多模态支持、查询灵活性 |
6.3 关键成功因素
构建高效RAG系统不仅在于向量数据库选型,还需要关注:
-
数据质量优先:优质嵌入向量是高质量检索的基础
-
端到端优化:从数据预处理到结果重排的全链路优化
-
持续迭代:根据业务反馈持续调整参数和策略
-
团队培养:构建具备向量数据库专业运维能力的团队
记住:没有最好的向量数据库,只有最合适的向量数据库。正确的选型来自于对业务需求的深刻理解和技术方案的客观评估。
官方文档与权威参考
-
Milvus官方文档- 架构详解和API参考
-
Qdrant官方文档- 配置指南和性能调优
-
ANN-Benchmarks- 向量数据库性能基准测试
-
HNSW算法论文- 算法原理和实现细节
-
华为昇腾Ascend C编程指南- 异构计算编程最佳实践
本文基于实际项目经验和技术社区实践总结,随着技术快速发展,建议持续关注各向量数据库最新版本特性和性能优化。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 76
76 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)