
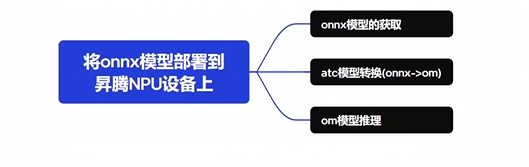
香橙派aipro部署yolov8(OM昇腾AI处理器的专用模型)
(经过查询,atc工具支持的NumPy 1.21.6不支持Python3.10,所以我们需要选择支持Python3.10的1.x版本。添加3.7或者3.8版本的python环境(注意系统不一定支持该低版本python,后续尝试安装NumPy用于atc转.om时候可能报错,强烈建议直接docker)2.2.2在虚拟环境目录下安装各种需要的包(大部分安装包下载都需要加上清华源加速,避免网络问题下载失败
准备:
由手册文档先烧录好系统,接好显示器,鼠标,键盘,登录板子并ping好网络方便我们开启远程ssh
(初次使用不知道怎么做的可以去翻我之前rk3588的文章,有较详细的步骤说明,下面默认已经接好)
已知我们使用的实验板芯片型号310B4
https://github.com/han-minhee/yolo-rust-ort 用于测试的开源目标检测项目(github搜索:ultralytics/yolo8或者ultralytics/yolo10找到可使用的就行)
一.电脑端
1.1准备cann工具下载
(具体根据板子本身配置情况,有些镜像烧录完发现找不到atc工具就需要自己安装并解压,配置环境path等,一般都是自带了的)
登录账号后就可以下载了,需要把安装包都拷进板上
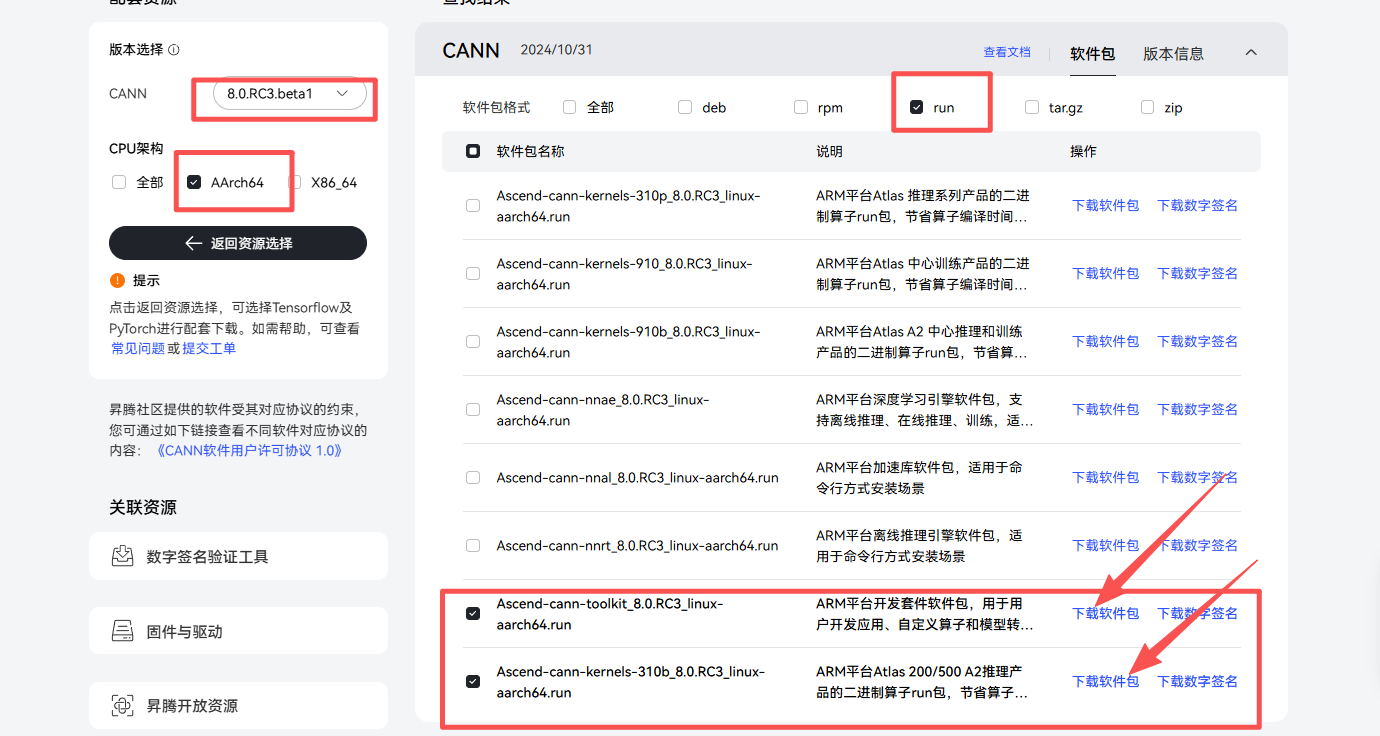
因为是在板子上使用的,我选择AArch64,下载之后记得自己的文件保存位置
1.2准备best.pt转.onnx
打开模型所在文件,找出runs下的best.pt
创建脚本create_onnx.py
import torch
import os
model_path = "/mnt/e/yolov8/ultralytics-main/yolo8/ultralytics-main/runs/segment/train7-emm/weights/best.pt"#放你文件的地址
try:
from ultralytics import YOLO
# 加载模型
model = YOLO(model_path)
# 使用最小的YOLOv8模型进行测试(如果可用)
# 如果只有当前模型,继续使用它但用更小尺寸
# 我的魔改分割在内存8G板上跑不起来,后面再写一篇如何根据自己使用的部署工具进行模型量化
model.export(
format='onnx',
imgsz=320, # 使用小尺寸,一般都是640
opset=11, # 确保使用opset11,看cann版本的,小一点适配的算子多才不容易卡,一般不会到opset=19
simplify=True, # 启用简化
dynamic=False, # 静态形状,我发现分割只有检测任务可以使用,分割是有两个output的,总之先试试,模型太复杂我们后续再回到onnx改)
print("简化版ONNX导出完成")
except Exception as e:
print(f"导出失败: {e}")记住你.onnx存放的位置
1.3准备ssh远程连接
- 确保AI PRO 和你的电脑连在同一个 WiFi / 局域网里;
- 查到IP 地址:给AI PRO 接显示器,登录后输
ifconfig看IP - 填连接信息:
- 在
Remote host框里输入Orange Pi 的 IP 地址; - 端口保持默认的
22; - 勾选
Specify username,输入账号(选root或HwHiAiUser)。
- 在
- 确认连接:点
OK后,在弹出的密码框输入Mind@123,就能成功连接啦~
1.4npu驱动包
(香橙派自己家的,到工具包中下载驱动.run,同样的需要先检测板子是否下载完镜像就已经拥有,可直接调用)

上传
二.AIPRO端
2.1这里选择使用热点(已经获取板子IP地址)
按正确顺序安装:CANN → PyTorch → torch_npu
2.2创建虚拟环境生成.om(或者直接docker)
先上传我们的文件(不缺atc工具可以直接跳到下一步)
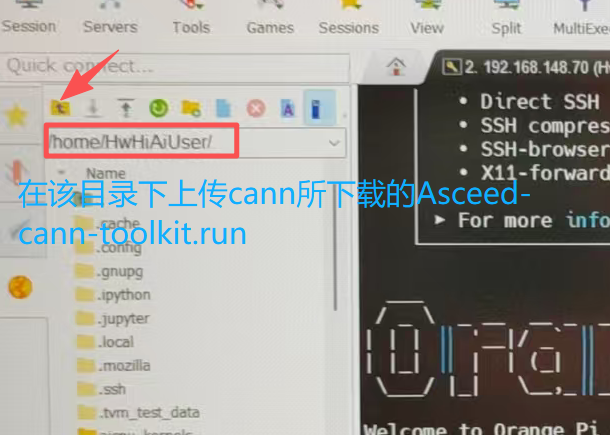
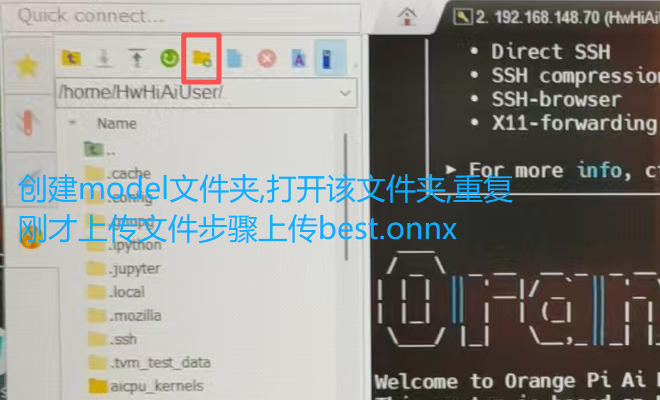
2.2.1基础环境配置
在目录home下,安装虚拟环境(加个清华源下载快一些)
pip3 install --user virtualenv pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir --timeout 120# 用清华源(最稳定,优先选)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir --timeout 120
# 若清华源仍失败,换阿里云源
pip install ultralytics -i https://mirrors.aliyun.com/pypi/simple --no-cache-dir --timeout 120
# 备选:豆瓣源(小文件快)、中科大源(稳定)
pip install ultralytics -i https://pypi.doubanio.com/simple --no-cache-dir --timeout 120
pip install ultralytics -i https://pypi.mirrors.ustc.edu.cn/simple --no-cache-dir --timeout 120添加3.7或者3.8版本的python环境(注意系统不一定支持该低版本python,后续尝试安装NumPy用于atc转.om时候可能报错,强烈建议直接docker)
(经过查询,atc工具支持的NumPy 1.21.6不支持Python3.10,所以我们需要选择支持Python3.10的1.x版本。NumPy 1.22.0开始支持Python3.10)
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装基础依赖
sudo apt install -y python3-pip python3-venv wget curl vim
# 创建虚拟环境
conda create -n yolov8_npu python=3.8
conda activate yolov8_npu
# 安装基础Python包
pip install opencv-python numpy pillow protobuf==3.20
在虚拟环境目录下安装各种需要的包(大部分安装包下载都需要加上清华源加速,避免网络问题下载失败)
# 安装YOLOv8基础依赖
pip install ultralytics
pip install opencv-python
pip install numpy
pip install pillow
# 安装昇腾相关依赖
pip install torch
pip install torchvision
# 安装其他可能需要的工具
pip install matplotlib
pip install seaborn
pip install pandas
#测试
# 测试YOLOv8是否能正常导入
python -c "from ultralytics import YOLO; print('YOLOv8导入成功!')"
# 测试OpenCV
python -c "import cv2; print(f'OpenCV版本: {cv2.__version__}')"
# 测试numpy
python -c "import numpy as np; print('NumPy工作正常')"安装之前上传的包
-
Ascend-cann-toolkit_8.0.RC3_linux-aarch64.run
-
Ascend-cann-kernels-310b_8.0.RC3_linux-aarch64.run
# 添加执行权限 chmod +x Ascend-cann-toolkit_8.0.RC3_linux-aarch64.run chmod +x Ascend-cann-kernels-310b_8.0.RC3_linux-aarch64.run # 安装工具包 ./Ascend-cann-toolkit_8.0.RC3_linux-aarch64.run --install # 安装内核包 ./Ascend-cann-kernels-310b_8.0.RC3_linux-aarch64.run --install
环境变量的配置
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
nano $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
#提前安装nano编辑器
#粘贴输入下列内容,ctrl+x然后输入y再enter退出
#!/bin/bash
export ASCEND_TOOLKIT_HOME=~/Ascend/ascend-toolkit/latest
export ASCEND_HOME=~/Ascend/ascend-toolkit/latest
export LD_LIBRARY_PATH=$ASCEND_TOOLKIT_HOME/lib64:$ASCEND_TOOLKIT_HOME/runtime/lib64:$ASCEND_TOOLKIT_HOME/runtime/lib64/stub:/usr/lib/aarch64-linux-gnu:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
export PYTHONPATH=$ASCEND_TOOLKIT_HOME/python/site-packages:$ASCEND_TOOLKIT_HOME/opp/op_impl/built-in/ai_core/tbe:$PYTHONPATH
export PATH=$ASCEND_TOOLKIT_HOME/bin:$PATH
export ASCEND_AICPU_PATH=$ASCEND_TOOLKIT_HOME
export ASCEND_OPP_PATH=$ASCEND_TOOLKIT_HOME/opp
export NPU_HOST_LIB=$ASCEND_TOOLKIT_HOME/runtime/lib64/stub
export TE_PARALLEL_COMPILER=1 # 设置算子最大并行编译进程数为1
export MAX_COMPILE_CORE_NUMBER=1 # 设置图编译时可用的CPU核数为1
更新文件 source ~/.bashrc
torch_npu安装配置
# 下载安装包
wget https://download.pytorch.org/whl/cpu/torch-2.4.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.rc3-pytorch2.4.0/torch_npu-2.4.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
# 安装PyTorch和torch_npu
pip install torch-2.4.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip install torch_npu-2.4.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl安装npu驱动包
# 1. 给驱动包添加执行权限
chmod +x Ascend-hdk-310b-npu-driver-soc_23.0.0_linux-aarch64-opiaipro.run
# 2. 安装
# 方法1:使用完整安装模式
sudo ./Ascend-hdk-310b-npu-driver-soc_23.0.0_linux-aarch64-opiaipro.run --full
# 方法2:或者使用运行模式
sudo ./Ascend-hdk-310b-npu-driver-soc_23.0.0_linux-aarch64-opiaipro.run --run
# 3. 安装过程中:
# - 阅读并接受EULA协议(输入Y)
# - 等待安装完成
#然后重启设备
sudo reboot
# 1. 重新加载驱动模块
sudo modprobe hisi_hccs
# 2. 验证驱动加载
lsmod | grep hisi_hccs
# 3. 检查设备节点
ls -la /dev/davinci*
# 4. 最终NPU测试
python -c "import torch_npu; print('NPU设备数量:', torch_npu.npu.device_count(), 'NPU可用:', torch_npu.npu.is_available())"如果安装成功,您应该看到:
-
lsmod | grep hisi_hccs显示驱动模块已加载 -
torch_npu.npu.device_count()返回 1(而不是0) -
torch_npu.npu.is_available()返回 True
注意项:经典的错误
报错1:libhccl.so找不到
ImportError: libhccl.so: cannot open shared object file: No such file or directory
解决:
# 查找libhccl.so实际位置
find ~/Ascend -name "libhccl.so" -type f 2>/dev/null
# 创建符号链接或复制到正确位置
sudo cp ~/Ascend/ascend-toolkit/latest/lib64/libhccl.so ~/Ascend/ascend-toolkit/latest/runtime/lib64/
sudo chmod 755 ~/Ascend/ascend-toolkit/latest/runtime/lib64/libhccl.so报错2:HcclCommInitAll符号未定义
ImportError: undefined symbol: HcclCommInitAll
# 验证符号存在性
nm -D ~/Ascend/ascend-toolkit/latest/lib64/libhccl.so | grep HcclCommInitAll
# 确保环境变量包含lib64路径(在runtime之前)
export LD_LIBRARY_PATH=$ASCEND_TOOLKIT_HOME/lib64:$ASCEND_TOOLKIT_HOME/runtime/lib64:...报错3:CANN安装路径不匹配
RuntimeError: The path does not exist: /usr/local/Ascend/ascend-toolkit/latest
解决:
# 找到实际安装路径
find ~/Ascend -name "atc" -type f 2>/dev/null
# 更新环境变量指向正确路径
export ASCEND_TOOLKIT_HOME=~/Ascend/ascend-toolkit/8.0.RC3/aarch64-linux报错4:权限问题
ln: failed to create symbolic link: Permission denied
解决:
# 更改目录所有权
sudo chown -R $USER:$USER ~/Ascend/ascend-toolkit/8.0.RC3/aarch64-linux/runtime/
# 或使用sudo创建链接
sudo ln -sf ~/Ascend/ascend-toolkit/8.0.RC3/aarch64-linux/lib64/libhccl.so ~/Ascend/ascend-toolkit/8.0.RC3/aarch64-linux/runtime/lib64/libhccl.so最后可以写个检验脚本查看是否有环境问题
import os
import ctypes
import sys
def diagnose_environment():
print("=== 环境诊断 ===")
# 检查环境变量
print("环境变量检查:")
print(f"ASCEND_TOOLKIT_HOME: {os.environ.get('ASCEND_TOOLKIT_HOME')}")
print(f"LD_LIBRARY_PATH: {os.environ.get('LD_LIBRARY_PATH')}")
# 检查关键库
print("\n关键库检查:")
key_libs = ['libhccl.so', 'libascendcl.so', 'libruntime.so']
for lib in key_libs:
try:
ctypes.CDLL(lib)
print(f"✓ {lib} - 可加载")
except Exception as e:
print(f"✗ {lib} - 加载失败: {e}")
# 检查torch_npu
print("\nPyTorch NPU检查:")
try:
import torch_npu
print("✓ torch_npu导入成功")
print(f"NPU可用: {torch_npu.npu.is_available()}")
if torch_npu.npu.is_available():
print(f"NPU设备数量: {torch_npu.npu.device_count()}")
except Exception as e:
print(f"✗ torch_npu导入失败: {e}")
print("=== 诊断完成 ===")
if __name__ == "__main__":
diagnose_environment()2.2.3使用atc工具
通过给定的atc工具设置,我们可以直接生成.om模型,这个过程大概在十几分钟左右
# 检查环境变量
echo $ASCEND_HOME
# 检查atc工具
which atc
atc --version
# 检查NPU状态
sudo npu-smi info
# 安装昇腾推理框架
pip install ais_bench# 使用系统环境运行的ATC转换指令
atc --model=/home/HwHiAiUser/model/best.onnx --framework=5 --output=/home/HwHiAiUser/model --input_shape="images:1,3,640,640" --soc_version=Ascend310B4
#一些说明
--model: 你的ONNX模型文件路径。
--framework=5: 表示原始框架是ONNX。
--output: 输出的OM模型文件名(不含后缀)。
--input_shape: 模型输入的shape,请务必根据你的YOLOv8模型实际情况调整。如果你的模型后还有一个input,就在前一段后面加个;images:a,b,c,d"
--soc_version: 通过 npu-smi info 命令查询芯片型号,在"Name"字段值前加"Ascend",例如查询到Name为310B4,则此处填Ascend310B42.2.4推理om模型(代码来源:samples/cpp_dvpp/1.HelloWorld/main.cpp · 胡安/learning-cann - 码云 - 开源中国)
这里是你已经完成了atc工具转换得到om模型,如果你是c++推理,那就需要main.cpp和CMakeLists.txt,如果你是脚本,那就python main.py
CMakeLists.txt
# Copyright (c) Huawei Technologies Co., Ltd. 2019. All rights reserved.
cmake_minimum_required(VERSION 3.5.1)
project(main)
add_compile_options(-std=c++11)
include_directories(
/usr/local/Ascend/ascend-toolkit/latest/runtime/include/
)
link_directories(
/usr/local/Ascend/ascend-toolkit/latest/runtime/lib64/stub
)
add_executable(main
main.cpp)
target_link_libraries(main ascendcl stdc++ opencv_core opencv_imgproc opencv_imgcodecs)
main.cpp
#include <opencv2/opencv.hpp>
#include "acl/acl.h"
using namespace cv;
using namespace std;
namespace {
const float min_chn_0 = 123.675;
const float min_chn_1 = 116.28;
const float min_chn_2 = 103.53;
const float var_reci_chn_0 = 0.0171247538316637;
const float var_reci_chn_1 = 0.0175070028011204;
const float var_reci_chn_2 = 0.0174291938997821;
const int channel = 3;
const int modelHeight = 256;
const int modelWeight = 256;
const int classNum = 30;
}
float * ProcessInput(const string testImgPath)
{
// 原始图片
Mat srcImage = imread(testImgPath);
// resize后的图片
Mat resizedImage;
resize(srcImage, resizedImage, Size(256, 256));
// 分配需要的内存空间
int input_data_size = channel * modelHeight * modelWeight * sizeof(float);
float * imageBytes = (float*)malloc(input_data_size);
memset(imageBytes, 0, input_data_size);
// 图片标准化
uint8_t bgrToRgb = 2;
float meanRgb[3] = {min_chn_2, min_chn_1, min_chn_0};
float stdRgb[3] = {var_reci_chn_2, var_reci_chn_1, var_reci_chn_0};
for (int c = 0; c < channel; ++c)
{
for (int h = 0; h < modelHeight; ++h)
{
for (int w = 0; w < modelWeight; ++w)
{
int dstIdx = (bgrToRgb - c) * modelHeight * modelWeight + h * modelWeight + w;
imageBytes[dstIdx] = static_cast<float>((resizedImage.at<cv::Vec3b>(h, w)[c] -
1.0f*meanRgb[c]) * 1.0f*stdRgb[c] );
}
}
}
return imageBytes;
}
void printMax(float * out_class_data)
{
// create map<confidence, class> and sorted by maximum
map<float, unsigned int, greater<float>> resultMap;
for (unsigned int j = 0; j < classNum; ++j) {
resultMap[*out_class_data] = j;
out_class_data++;
}
// 计算softmax的sum
double totalValue=0.0;
for (auto it = resultMap.begin(); it != resultMap.end(); ++it) {
totalValue += exp(it->first);
}
// get max <confidence, class>
float confidence = resultMap.begin()->first;
unsigned int index = resultMap.begin()->second;
string line = format("label:%d conf:%lf ", index, exp(confidence) / totalValue);
cout << line << endl;
}
int main()
{
// ***************************** 初始准备工作 *****************************
aclInit(""); // 初始化
aclrtSetDevice(0); // 设置使用第1块NPU
// 加载模型
uint32_t modelId;
aclError ret = aclmdlLoadFromFile("./resnet50.om", &modelId);
// ***************************** 准备模型输入 *****************************
// 对输入图片进行处理
float * cpu_input_buffer = ProcessInput("./2.jpg"); // cpu_input_buffer是float32 [1, 3, 256, 256]
// 将cpu上数据拷贝到NPU上
void * npu_input_buffer;
int input_data_size = channel * modelHeight * modelWeight * sizeof(float);
aclrtMalloc(&npu_input_buffer, input_data_size, ACL_MEM_MALLOC_HUGE_FIRST); // 在NPU上分配内存
aclrtMemcpy(npu_input_buffer, input_data_size, cpu_input_buffer, input_data_size,
ACL_MEMCPY_DEVICE_TO_DEVICE); // 把CPU上数据拷贝到NPU中
// 把NPU中分配的显存绑定到aclmdlDataset结构体上
aclDataBuffer * inputData = aclCreateDataBuffer(npu_input_buffer, input_data_size);
aclmdlDataset * inputDataset = aclmdlCreateDataset();
aclmdlAddDatasetBuffer(inputDataset, inputData);
// ***************************** 准备模型输出空间 *****************************
// 在npu上分配空间
void * npu_output_buffer;
int output_data_size = classNum * sizeof(float);
aclrtMalloc(&npu_output_buffer, output_data_size, ACL_MEM_MALLOC_HUGE_FIRST);
// 把NPU中分配的显存绑定到aclmdlDataset结构体上
aclDataBuffer * outputData = aclCreateDataBuffer(npu_output_buffer, output_data_size);
aclmdlDataset * outputDataset = aclmdlCreateDataset();
aclmdlAddDatasetBuffer(outputDataset, outputData);
// ***************************** 模型执行推理 *****************************
ret = aclmdlExecute(modelId, inputDataset, outputDataset);
// ***************************** 模型输出后处理 *****************************
float * out_class_data = (float*)malloc(output_data_size);
aclrtMemcpy((void*)out_class_data, output_data_size, npu_output_buffer, output_data_size, ACL_MEMCPY_DEVICE_TO_DEVICE);
printMax(out_class_data);
// ***************************** 释放昇腾资源 *****************************
aclrtFree(npu_input_buffer);
aclmdlDestroyDataset(inputDataset);
aclrtFree(npu_output_buffer);
aclmdlDestroyDataset(outputDataset);
aclmdlUnload(modelId);
aclrtResetDevice(0);
aclFinalize();
return 0;
}main.py(python推理版本)
import acl
import cv2
import numpy as np
min_chn = np.array([123.675, 116.28, 103.53], dtype=np.float32)
var_reci_chn = np.array([0.0171247538316637, 0.0175070028011204, 0.0174291938997821], dtype=np.float32)
channel = 3
modelHeight = 256
modelWeight = 256
ACL_MEMCPY_DEVICE_TO_DEVICE = 3
ACL_MEM_MALLOC_HUGE_FIRST = 0
classNum = 30
def ProcessInput(input_path):
image = cv2.imread(input_path)
resize_image = cv2.resize(image, (modelWeight, modelHeight))
# switch channel BGR to RGB
image_rgb = cv2.cvtColor(resize_image, cv2.COLOR_BGR2RGB)
image_rgb = image_rgb.astype(np.float32)
# data standardization
image_rgb = (image_rgb - min_chn) * var_reci_chn
# HWC to CHW
image_rgb = image_rgb.transpose([2, 0, 1]).copy()
return image_rgb.tobytes()
def main():
# ***************************** 初始准备工作 *****************************
acl.init() # 初始化
acl.rt.set_device(0) # 设置使用第1块NPU
modelId, ret = acl.mdl.load_from_file("./resnet50.om") # 加载模型
# ***************************** 准备模型输入 *****************************
# 对输入图片进行处理
cpu_input_buffer = ProcessInput("2.jpg")
# 将cpu上数据拷贝到npu上
input_data_size = len(cpu_input_buffer)
npu_input_buffer, ret = acl.rt.malloc(input_data_size, ACL_MEM_MALLOC_HUGE_FIRST)
cpu_input_buffer = acl.util.bytes_to_ptr(cpu_input_buffer)
ret = acl.rt.memcpy(npu_input_buffer, input_data_size, cpu_input_buffer, input_data_size, ACL_MEMCPY_DEVICE_TO_DEVICE)
# 把NPU中分配的显存绑定到aclmdlDataset结构体上
inputData = acl.create_data_buffer(npu_input_buffer, input_data_size)
inputDataset = acl.mdl.create_dataset()
inputDataset, ret = acl.mdl.add_dataset_buffer(inputDataset, inputData)
# ***************************** 准备模型输出空间 *****************************
output_buffer_size = classNum * 4
npu_output_buffer, ret = acl.rt.malloc(output_buffer_size, ACL_MEM_MALLOC_HUGE_FIRST)
outputData = acl.create_data_buffer(npu_output_buffer, output_buffer_size)
outputDataset = acl.mdl.create_dataset()
outputDataset, ret = acl.mdl.add_dataset_buffer(outputDataset, outputData)
# ***************************** 模型执行推理 *****************************
ret = acl.mdl.execute(modelId, inputDataset, outputDataset)
# ***************************** 模型输出后处理 *****************************
out_class_data, ret = acl.rt.malloc(output_buffer_size, ACL_MEM_MALLOC_HUGE_FIRST)
ret = acl.rt.memcpy(out_class_data, output_buffer_size, npu_output_buffer, output_buffer_size, ACL_MEMCPY_DEVICE_TO_DEVICE)
# printMax(out_class_data)函数部分
bytes_data = acl.util.ptr_to_bytes(out_class_data, output_buffer_size)
data = np.frombuffer(bytes_data, dtype=np.float32).reshape([1, 30])
data = data.flatten()
vals = np.exp(data)/np.sum(np.exp(data))
top_index = vals.argsort()[-1]
print(f"class:{top_index} conf:{vals[top_index]:06f}")
# ***************************** 释放昇腾资源 *****************************
acl.rt.free(npu_input_buffer)
acl.mdl.destroy_dataset(inputDataset)
acl.rt.free(npu_output_buffer)
acl.mdl.destroy_dataset(outputDataset)
ret = acl.mdl.unload(modelId)
acl.rt.reset_device(0)
acl.finalize()
if __name__ == "__main__":
main()代码使用时,需要下载acl
注意,aclruntime和ais_bench推理程序的whl包请 前往下载。
晟腾git 仓库 :https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_bench
对于whl包的下载和解包,在前面 1.1准备cann工具下载 时已有示例了
最终推理结果:
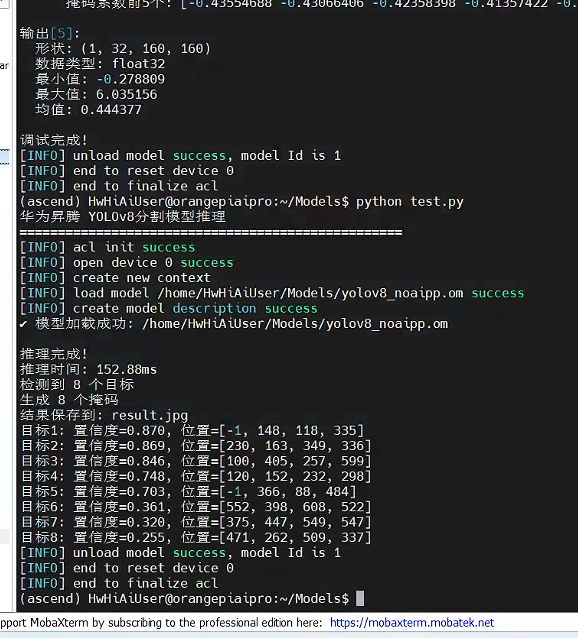
使用手册(因为量化需求不同我们可以根据需求更改推理代码,这里我把main.py改进到test.py)
启动 输入指令:
conda activate ascend
cd ~/Models
python test.py
运行后得到结果
test1.py是用于检测文件.om一些适配参数 ,需要根据生成完的.om文件或者之前用于推理的.onnx文件进行配置
使用这些参数就能在test.py中调参实现对.om模型的推理了
test.py代码中有注释 其中 .om模型文件位置、用于测试推理的图片文件位置、推理后图片文件位置是需要根据实际情况调整的
如果需要导入新模型.onnx使用 需设置opset在11到15之间
参考文章:

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)