
【贡献经历】走进 Kurator 社区:一个云原生开发者的分布式之旅!
Kurator开源项目实践分享 从用户视角切入Kurator分布式云平台,通过解决多集群监控安装问题首次贡献开源社区。从文档修正到功能优化,逐步深入参与Feature开发,体验开源协作全流程。 核心收获 文档贡献是开源入门最佳路径 真实需求驱动技术深度探索 开源设计需平衡创新与克制 关注专栏《零基础学鸿蒙开发》,获取完整学习路径!
你是不是也在想——“鸿蒙这么火,我能不能学会?”
答案是:当然可以!
这个专栏专为零基础小白设计,不需要编程基础,也不需要懂原理、背术语。我们会用最通俗易懂的语言、最贴近生活的案例,手把手带你从安装开发工具开始,一步步学会开发自己的鸿蒙应用。
不管你是学生、上班族、打算转行,还是单纯对技术感兴趣,只要你愿意花一点时间,就能在这里搞懂鸿蒙开发,并做出属于自己的App!
📌 关注本专栏《零基础学鸿蒙开发》,一起变强!
每一节内容我都会持续更新,配图+代码+解释全都有,欢迎点个关注,不走丢,我是小白酷爱学习,我们一起上路 🚀
全文目录:
一、起点:为什么我会盯上 Kurator 这个项目?
坦白说,最早看到 Kurator,是在一篇介绍「分布式云原生一站式解决方案」的技术文章里:Kurator 作为一个开源的分布式云原生平台,目标是帮助用户构建自己的分布式云原生基础设施,统一处理多云、多集群、云边协同等复杂问题。
还有几个特点,当时直接戳中我的痛点:
- 它不是「再造一个 Kubernetes」,而是站在 Kubernetes 等主流栈之上;
- 内部整合了 Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno 等一长串“熟面孔”;
- 上层提供统一资源编排、统一调度、统一流量治理、统一监控遥测等能力,典型就是以 Fleet 为单位做分布式云统一管理。
换句话说,如果 CNCF 的那堆项目是“零件库”,Kurator 更像是一套「装配好的分布式云原生底盘」。
对我这种长期被「多云多集群 YAML 地狱」折磨的开发 / 运维同学来说,这种一站式开源方案天然有吸引力,于是我从一个普通使用者的视角,慢慢走进了 Kurator 社区。
首先先来参考下官方的Kurator架构图:
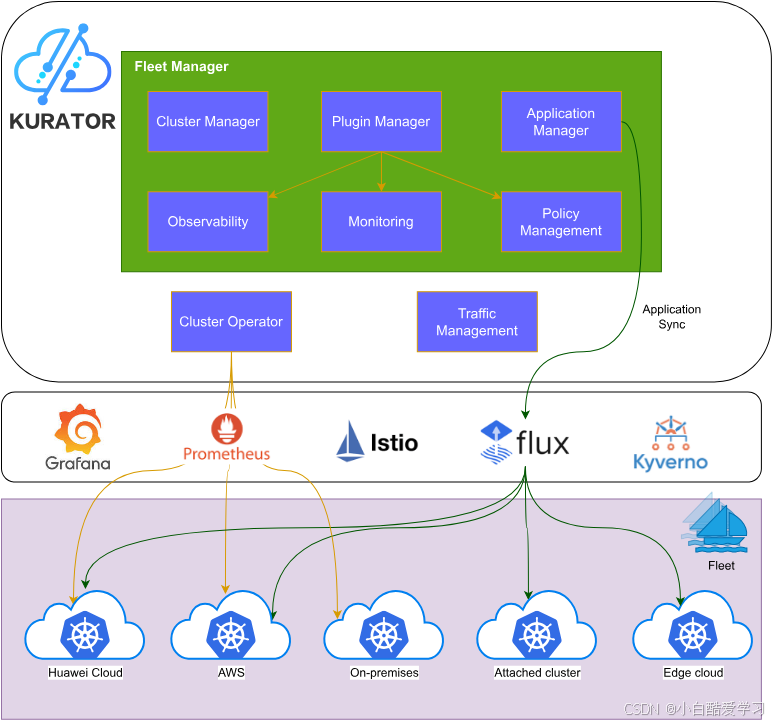
二、从“用”到“改”:第一次参与 Kurator 的 Issue & PR
2.1 触发点:多集群监控安装体验的小瑕疵
我真正开始动手贡献,是在踩到一个多集群监控安装体验的小坑之后。
当时我们的实验环境大概是这样:
- 管理集群上部署 Kurator;
- 三个业务集群被纳入 Fleet;
- 需要按官方方案,基于 Prometheus + Thanos + Grafana + Fleet 搭多集群统一监控。
按照文档安装时,我遇到两个问题:
- 某个 CRD 的示例 YAML 和实际版本有点偏差;
- 在某些网络受限环境下,个别镜像拉取有点“卡”。
这两个问题都不算大,但对新用户的「首次体验」影响挺明显。于是我做了两件事:
- 在本地环境把问题复现 + 理清根因;
- 到 Kurator 仓库提了一个 Issue,把环境信息、复现步骤、错误日志都贴得清清楚楚。
Issue 提出去后,大概几个小时之内,就有 Maintainer 来跟帖确认、补问细节。那一刻的感受很明显: **这是一个真的有人在「看」和「维护」的社区,而不是“摆着的 GitHub 仓库”。**😄
2.2 和 Maintainer 的第一次深度互动:从问题到方案的推敲
在 Issue 中,我们做了几轮往返:
-
Maintainer 补充了当前统一监控方案的整体架构说明:通过 Fleet 简化多集群监控组件安装,使用 Prometheus + Thanos Sidecar 做指标采集和聚合查询;
-
我进一步给出了我们实际的网络拓扑(有跳板机 / 私有镜像仓库 / 没有直连公网);
-
双方一起分析,发现:
- 文档中的镜像地址在公网环境完全没问题;
- 在企业私有环境,需要给出一个更清晰的镜像替换策略。
最后 Maintainer 直接反问我一句:
要不要你顺手提个 PR,把这块“非公网场景”的最佳实践,补充到文档里?
这也就成了我在 Kurator 的第一笔 PR。
当然,我们还可以参考如下流程图:
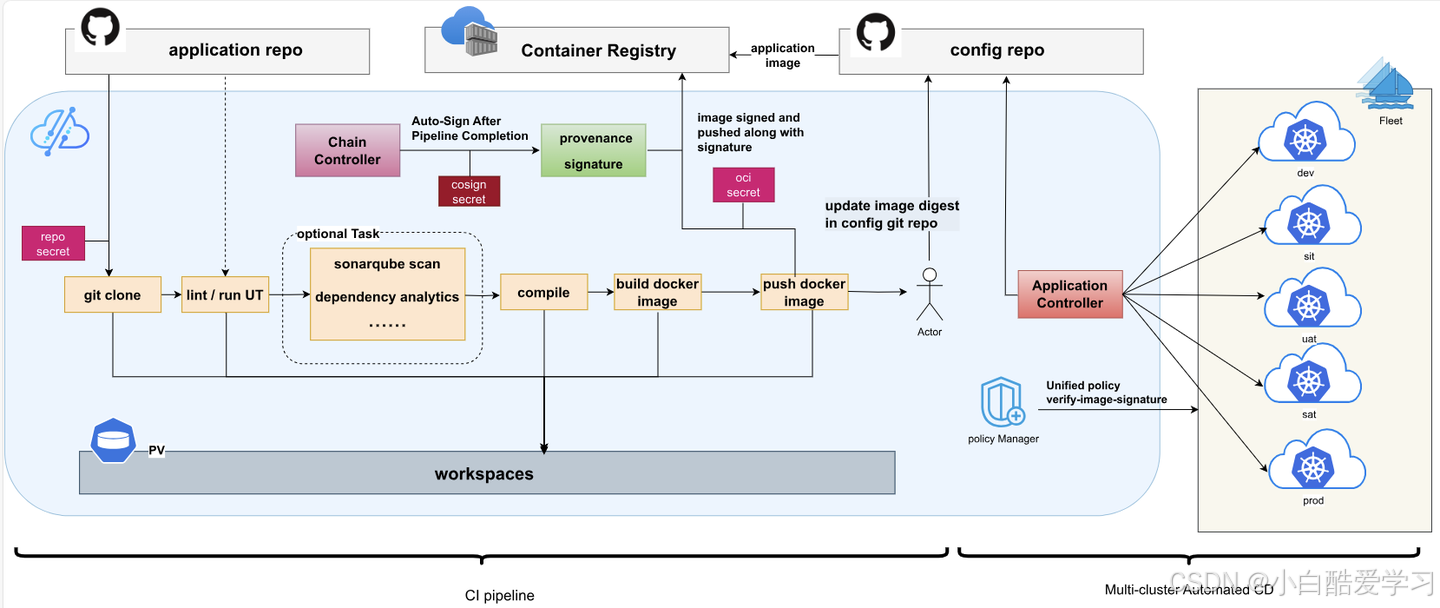
2.3 我在 Kurator 的第一笔 PR:从写文档开始是个好主意
很多同学一提贡献开源,脑子里就自动联想到「高大上 Feature 开发」或「复杂 Bug 修复」。但实际体验是:从文档入手,是最合适的切入口之一。
那次 PR 做了几件小事:
-
在统一监控文档中增加“离线 / 内网安装”一节
- 说明如何在企业镜像仓库中同步 Prometheus、Thanos、Grafana 等镜像;
- 如何在 Kurator 的配置中使用自定义镜像前缀;
- 提醒读者注意 CA 证书及仓库认证配置。
-
把示例 YAML 与当前版本 CRD 对齐
- 修正了两处字段名;
- 增加了一些注释(例如字段的语义、推荐配置)。
从提交到合并,大致经历了:
- Maintainer 进行第一次 Review;
- 提出一些格式 / 表述上的优化建议;
- 我根据建议做了小改动;
- CI 通过后,PR 被合并,Release Notes 里出现了我的 GitHub ID ✨
对我个人来说,这个过程有两个非常实在的收获:
- 熟悉 Kurator 的文档结构和整体能力边界;
- 提前适应了社区的协作节奏:Issue → 设计讨论 → PR → Review → 合并。
当然,如果这里你已经感兴趣了,你可以直接去克隆代码:
三、第二阶段:从“小修小改”迈向 Feature 级贡献
有了第一笔 PR 的“正向反馈”之后,我开始有意地找机会做更深一点的贡献。
我给自己定了一个小目标:
不再只停留在“文档层 / 表象问题”,而是真正把 Kurator 的某一部分功能研究透,做一次有完整设计和实现的 Feature 级贡献。
我最终选中的方向是:统一应用分发 + GitOps 流水线的一段增强。
3.1 先把 Kurator 的应用管理路线吃透
要对某个功能模块做 Feature 级贡献,第一步肯定是“把它理解清楚”。
我花了不少时间翻文档、看架构说明,大概整理出 Kurator 在应用管理上的技术路线:
-
基于 Karmada 做多集群编排基础
- Karmada 为多集群提供统一 API 和编排能力,用于在多个 Kubernetes 集群之间复制、调度、协调资源。
-
Kurator 在其之上封装“统一应用分发”能力
- 以 Fleet 为单位,把应用一次定义、多处分发;
- 采用 GitOps 方式,将应用配置托管在 Git 仓库,通过声明式方式在多集群自动同步。
-
CI/CD 与渐进式发布打通(v0.6.0)
- 引入流水线管理,实现编译、构建、测试、镜像推送的一体化自动化;
- 内置
git-clone、go-test、go-lint、build-and-push-image等任务模板,开发者只要进行组装; - 往下连接统一应用分发,多集群部署;
- 往侧边连接渐进式发布(Canary / A/B / 蓝绿),利用 Istio 等网格完成流量拆分与治理。
-
完整闭环:代码 → 构建 → 分发 → 流量 → 观测 → 回滚
- 指标数据由 Prometheus / Thanos 提供;
- 策略与安全由 Kyverno 等统一策略管理组件保障。
做完这轮“扫盲”,我对自己说:OK,下一步就该从用户视角出发,看看这条链路在真实使用时还有哪些「可优化」之处。
3.2 一个真实需求:流水线与统一分发的“场景模板化”
在和团队一起试用时,我们复盘了一个典型场景:
一个 Go 微服务,需要在「测试环境集群」和「生产环境 Fleet(多集群)」中,通过不同策略发布,同时复用大部分构建与测试逻辑。
现有 Kurator 给的能力已经足够使用,但有两个现实感受:
- 每个服务都要单独定义一份 Pipeline + Application,如果规范不严格,很容易出现“各写各的”的情况;
- 希望能抽象出一套 “场景模板”:比如「标准 Web 服务模板」、「带金丝雀发布的核心服务模板」、「边缘服务模板」等,减轻重复劳动。
于是我们提出了一个 Feature 级需求:
在 Kurator 的 Pipeline 与 Application 定义层,引入“场景模板 + 继承 / 覆盖”的模式,降低多项目接入成本。
3.3 设计评审:在开源项目里讲“妥协的艺术”
我把这个需求整理成一个设计草案,主要包括:
-
一个新的 CRD:比如
ApplicationTemplate(名称这里只是示意); -
允许在模板中定义:
- CI/CD 任务编排骨架;
- 对应的统一应用分发策略(目标 Fleet、Namespace、拓扑标签等);
- 基础的发布策略类型(如是否默认开启 Canary);
-
应用方只需要继承模板,在少数字段上做覆盖(镜像名、镜像标签、资源配额等)。
在和 Maintainer 以及部分社区贡献者一起 Review 时,大家给了不少非常实在的反馈,比如:
-
CRD 设计要避免和现有 Application / Pipeline 语义冲突
尽量不要引入“第二套 Application 概念”,以免认知负担增加。 -
要考虑和 FluxCD / Argo CD 的对接空间
Kurator 已经集成了 FluxCD / Argo 等工具,后续有可能进一步对接。 -
插件化 vs 内置:哪些放在 Kurator 核心,哪些做成扩展?
不是所有场景都适合放进"核心分布式云能力"里。
经过几轮拉锯式讨论,我们最终做了几个妥协:
- 先不引入新的 CRD,而是在现有 Pipeline / Application 上增加“模板引用”字段;
- “场景模板”的实现方式更偏向“工具层 + 代码生成”,而不是“控制面逻辑层”;
- 保留一个增强提案(RFC)文档,未来根据社区反馈再考虑“模板 CRD”的方案。
这次设计评审让我第一次真正感受到:
在一个面向广泛用户、技术栈非常丰富的开源项目里,“做好功能”不难,“做好合适的功能”才难。
很多时候你必须接受:**你的想象力可以很丰富,但项目的抽象层次需要克制。**🙂
3.4 实现与合并:边写代码边学“云原生组合拳”
最终那次 Feature 的结果是:
-
我提交了一组 PR:
- 在 Kurator 的 CLI 中加入“基于模板生成应用骨架”的辅助子命令;
- 为一类典型部署场景(如 Go Web 服务)提供了一组可选模板;
- 在文档中增加了“如何使用应用模板快速接入 CI/CD + 统一分发”的章节。
-
Maintainer 对代码结构、可扩展性、错误处理做了非常细致的 Review;
-
在几次版本迭代中,这部分功能也逐渐被更多用户试用、反馈再迭代。
对我而言,这是一次非常完整的「从需求 → 设计 → 评审 → 实现 → 文档 → 反馈」的闭环。
在这个过程中,我不是“在写某个技术栈的代码”,而是在拿着 Kurator 这把“分布式云组合拳”去解决一个实打实的工程问题。
可看下如下分发示意图,以便于理解:
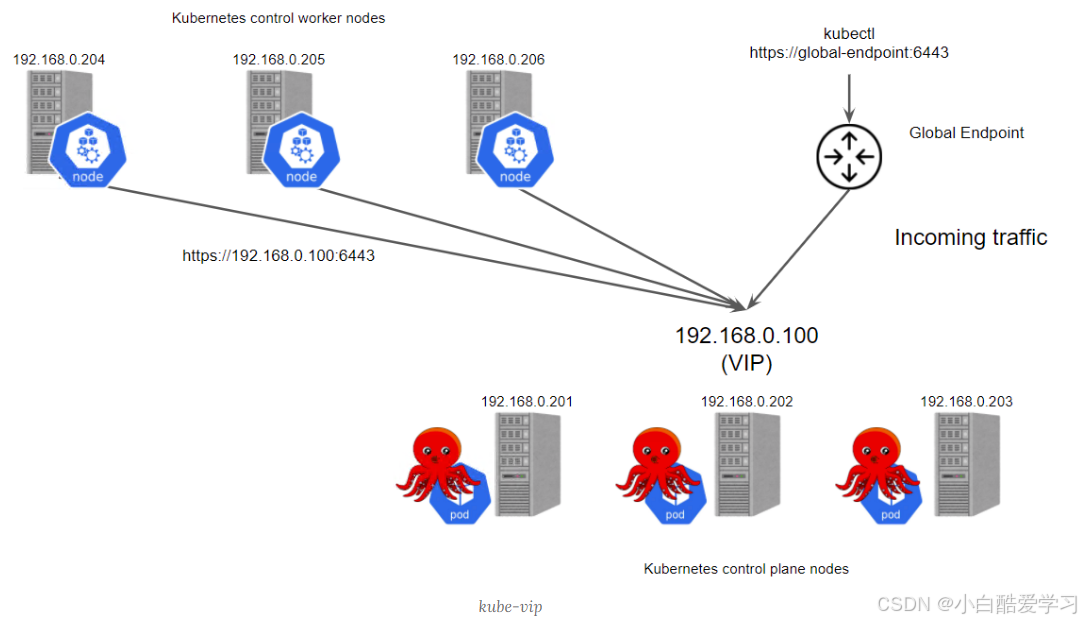
四、协作背后:我眼中的 Kurator 社区文化
作为一个贡献者,我也有机会站在“协作”的角度,观察 Kurator 社区是如何运转的。总结下来有几点印象很深:
4.1 技术路线非常透明
-
官方文档和博客对 Kurator 的目标、架构和核心特性有清晰说明:
- 统一资源编排、统一调度、统一流量管理、统一遥测;
- 基于 Cluster Operator + Fleet Manager 的整体架构;
- 典型能力包括:多集群生命周期管理、统一应用分发、统一监控、统一策略管理等。
-
在 GitHub 仓库和官网上,Roadmap、Release Note 都比较及时;
这意味着作为贡献者,你不会陷入“项目到底想往哪儿走”的迷茫。
4.2 Maintainer 的“反馈密度”很关键
在我参与的几个 Issue / PR 中,一个共同感受是:Maintainer 的响应都比较及时。
哪怕是一个小改动,他们也会明确给出:
- 技术上的意见(比如兼容性、性能、边界条件);
- 风格上的建议(比如命名、日志、注释、文档结构);
- 面向社区的一致性要求(比如是否需要在 Changelog / Release Note 中说明)。
这种高密度反馈对贡献者其实是很激励的:**你会发自内心地觉得“自己的时间没有被浪费掉”。**✨
4.3 “实用主义”与“工程完备性”的平衡
Kurator 所处的领域注定很“工程”:分布式云、云原生基础设施、多集群管理……
我最大的感受是:社区在功能设计上非常强调“实用主义”与“工程完备性”的平衡:
- 一方面,不做太多“炫技”的东西,优先解决真实场景里的痛点;
- 另一方面,对于生命周期管理、统一监控、策略管理这种基础能力,又会非常在意「完整性」——宁可少一点 Feature,也要保证整体模型闭环。
这种氛围对贡献者也有潜移默化的影响:你会慢慢从“我能写什么酷代码”转向“我能让这套平台更好地跑在别人生产环境上”。
而且,我们也可以看到,社区开源信息基本都给出了:
五、在贡献过程中,如何系统理解 Kurator 的技术栈?
从贡献者视角再看 Kurator 的技术栈,会比“纯使用者”多一些结构化认知,这里我用自己的话总结一下,也方便给后来者做个“读图索骥”。
5.1 Kurator 的“底座”:站在行业主流技术栈之上
Kurator 官方自己就写得很明确:它是站在众多主流云原生技术栈的肩膀上:
- Kubernetes:统一容器编排的基础;
- Istio:服务网格,负责流量治理;
- Prometheus / Thanos / Grafana:监控与可观测性基础设施;
- FluxCD / Argo:GitOps 与工作流引擎;
- Karmada:多集群编排与统一 API;
- KubeEdge:边缘侧的 Kubernetes 能力延伸;
- Volcano:批处理 / AI 工作负载调度;
- Kyverno:策略与安全控制。
如果只盯某一块,很容易觉得“Kurator 只是又多了一个平台”。
但当你从社区贡献者的视角去看,会很自然地意识到:Kurator 做的是“把这些能力拼成一个完整故事”:
- 资源层面:Cluster API + Cluster Operator → Fleet → 多集群一体化管理;
- 应用层面:Karmada → 统一应用分发 + 场景模板;
- 流量层面:Istio → 金丝雀、A/B、蓝绿、跨集群路由;
- 观测层面:Prometheus + Thanos → 多集群统一监控;
- 策略与安全层面:Kyverno + Fleet → 多集群统一策略;
5.2 分布式云原生的“设计模式”
在中国信通院等机构的定义中,分布式云原生本身就是一种“通过云原生技术统一多云技术栈,为业务创造价值的设计模式”。
在参与 Kurator 社区的过程中,这个定义对我而言不再只是抽象概念,而是具体表现为几件事:
-
任何一个能力,必须考虑多云 / 多集群 / 云边协同场景
- 例如:统一监控不会只考虑“单集群中的 Prometheus”;
- 策略管理不会只管“一个 Namespace 的准入策略”。
-
任何一个组件的选择,都要考虑“能否被纳入统一控制平面”
- 不是为了“多集群而多集群”,而是要在统一视图下管理生命周期与策略。
-
业务价值是第一驱动力
- 不管是统一分发、渐进式发布,还是边缘协同,本质上都是在提高发布效率 / 稳定性 / 成本控制能力。
作为贡献者,你写下的每一行代码、每一个文档段落,背后都应该在这套设计模式里对齐自己的位置。
作为华为的开源项目,对于Kurator项目也上了热门开源项目榜:

六、从贡献到落地:我总结的几条“实战心得”
站在「Kurator 贡献者 + 使用者」的双重身份上,我整理了几条对我自己很有帮助的心得,也分享给准备参与「Kurator·云原生实战派」的你 😆
6.1 对“多云多集群”的理解要落到具体用例
别停留在:
“我们也要多云多集群,因为大家都这么干。”
更实在的思路是:
- 你有哪些业务确实需要多集群部署(跨地域容灾?就近访问?合规隔离?);
- 哪些业务需要下沉到边缘(IoT?门店?工厂?);
- 你希望 Kurator 在这里扮演什么角色(统一应用分发?统一监控?统一策略?)。
当你能说清楚这些,用 Kurator 的体验会好非常多,也更容易写出“有血有肉”的实战文章。
6.2 在设计发布策略时,把“观测”放在前面
无论是 Canary、A/B 还是蓝绿发布,没有观测就没有渐进式发布。
在贡献 Kurator 的过程中,我越来越坚定地相信:
- 在你写第一个 Rollout 策略之前,先把 Prometheus 指标、Thanos 查询、Grafana 看板和告警体系定义好;
- 指标不仅要有“技术指标”,也要有“业务指标”(如转化率、错误率等);
- 在设计策略时,要明确“放大招”按钮:什么时候自动回滚、什么时候需要人工干预。
6.3 GitOps 不是“配置挪到 Git”那么简单
很多团队以为:
我们已经把 YAML 都放在 Git 里了,所以我们是 GitOps 团队了。
实际参与 Kurator 的流水线 / 统一分发 / 策略管理之后,我会更倾向于这样的理解:
-
GitOps 强调的是「以 Git 中的声明为唯一真相源(source of truth)」;
-
这意味着:
- 任何手工在集群上的修改,最终都要回归到 Git;
- 发布流程、策略变更都要构建在“Pull Request + Review + 自动化执行”的模式上;
- 运维和开发需要共享同一套 Git 仓库视图,而不是双方各管一摊。
6.4 开源贡献不只是“给别人做免费劳动力”
这句话听起来有点直白,但在 Kurator 的贡献经历让我非常确定:
你在 Kurator 上投入的每一份时间,都会以“认知升级 + 工程经验 + 社区人脉”的形式,回到自己身上。
对我个人来说,有三个非常直观的收获:
- 对分布式云原生的整体图景有了系统理解,而不是碎片化地学某个组件;
- 学到了一套在复杂工程项目中“做权衡、做妥协”的方法论;
- 认识了一批真正落地分布式云的大厂 / 团队的工程师,很多技术讨论都非常高价值。
如下是GitHub开源截图:
七、作为贡献者,我对 Kurator 的几点期望与建议
既然是【贡献经历】,最后也说几条比较真诚的小建议,既是给 Kurator 社区,也可以算是对「分布式云原生」发展的一点私人看法:
-
持续强化“开箱即用”的体验
- Kurator 已经通过 Fleet Manager、Cluster Operator 和一键安装方式,降低了上手门槛;
- 未来可以更多在“企业内网 / 离线环境 / 合规环境”的场景下,提供更加完备的模板和工具。
-
在云边协同和 AI 场景上,继续加码
- 依托 KubeEdge 和 Volcano 等能力,Kurator 在边缘与 AI Batch 的基础已经具备;
- 期待未来能看到更系统的“云边协同 + AI 推理 / 训练一体”的解决方案示例。
-
加强与主流 GitOps / Workflow 项目的协同实践
- 目前已经集成 FluxCD、Argo 等组件,后续可以在实践层给更多「最佳实践蓝图」,帮助企业快速落地。
-
继续保持“工程实用主义”的社区氛围
- 希望 Kurator 一直保持现在这种风格:敢于拥抱新技术,但不盲目追热点;
- 多从真实用户场景中“抠需求”,少造“只好看不耐用”的轮子。
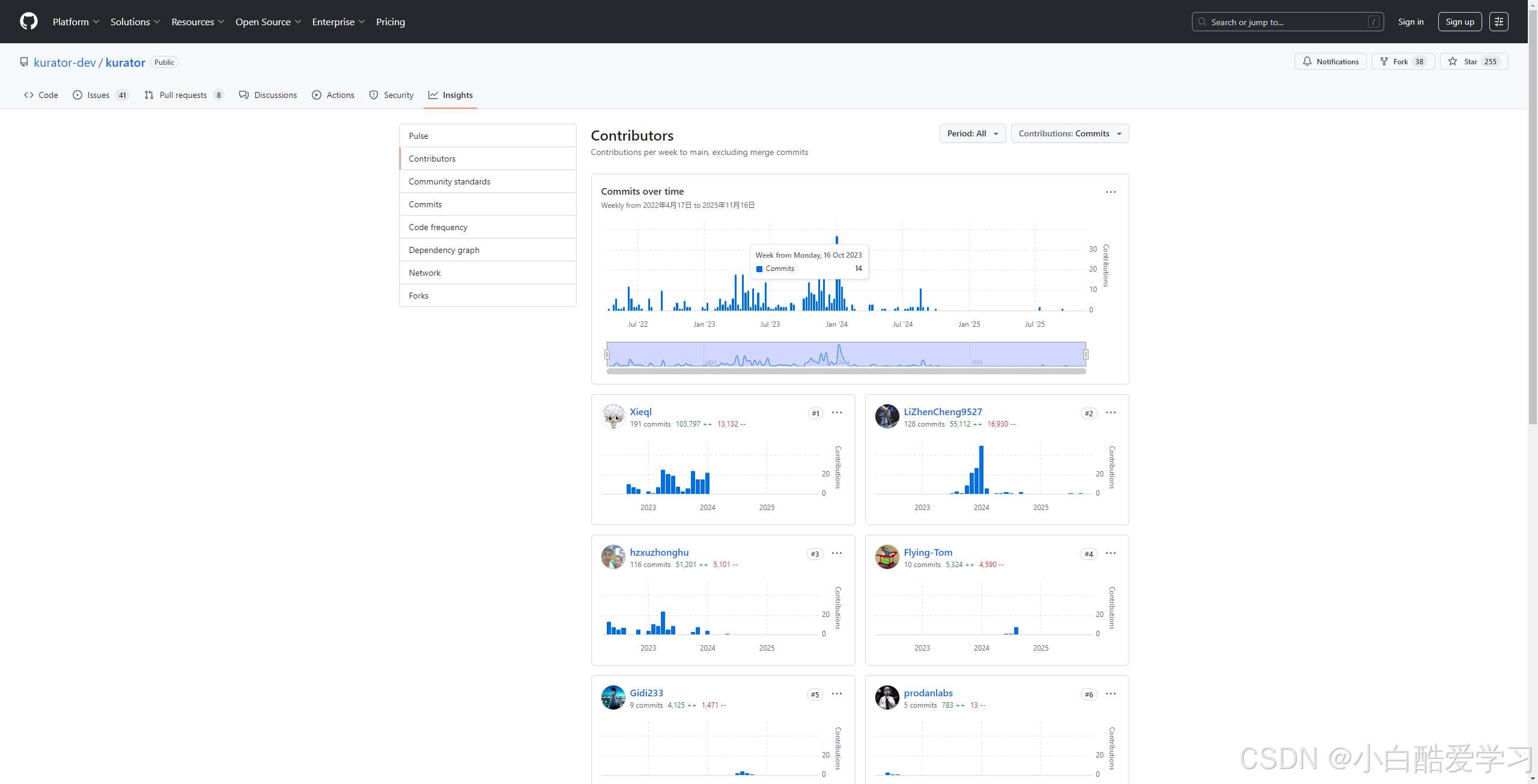
我们可以看到,一直在维护贡献:
八、给想参与 Kurator 社区的你:一封小小的公开信
如果你看到这里,说明你大概率符合下面其中一条:
- 你是云原生开发 / 运维 / 架构师,对多云多集群、云边一体有兴趣;
- 你刚好在准备 CSDN「Kurator·云原生实战派」征文,想找点灵感;
- 你已经在用 Kurator,只是还没迈出“贡献”的第一步。
那我想对你说的只有两句话:
-
先大胆用起来,再勇敢提 Issue。
- 不用一上来就写代码,先把你真实的使用体验、疑问、改进建议写清楚,这本身就是对社区非常重要的贡献;
-
当你愿意写下第一笔 PR,你已经是这个分布式云原生故事的一部分了。
Kurator 不是一个只属于大厂的项目,它也非常需要来自一线开发者、运维工程师、架构师的声音。
❤️ 如果本文帮到了你…
- 请点个赞,让我知道你还在坚持阅读技术长文!
- 请收藏本文,因为你以后一定还会用上!
- 如果你在学习过程中遇到bug,请留言,我帮你踩坑!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 7
7 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)