
庖丁解牛Vector开发:开源样例代码精讲,带你轻松上手
2025年昇腾CANN训练营第二季推出0基础入门、开发者案例等课程,助力开发者提升算子开发技能。本文以官方VectorAdd算子为例,深度解析AscendC开发范式。文章剖析了标准算子类的结构,包括初始化函数、核心处理函数和三级流水线设计,详细讲解了内存管理、队列通信等关键技术点。通过分析Init、Process、CopyIn、Compute、CopyOut等核心函数,总结出AscendC开发的三
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在软件工程中,学习一门新技术最快的方式往往不是啃文档,而是阅读高质量的开源代码。对于 Ascend C 算子开发而言,昇腾社区提供的官方 Samples 就是我们最好的老师。
很多初学者写出来的算子能跑,但往往存在代码风格不规范、内存管理混乱、流水线设计不合理等问题。本期文章将以官方开源的 Vector Add 算子为例,进行逐行级的深度解析。我们将剥开代码的表象,探究其背后的设计范式(Design Pattern),让你写出既优雅又高效的算子代码。
一、 宏观视角:标准算子类的骨架
在 Ascend C 中,一个标准的 Kernel 实现通常被封装在一个 C++ 类中。这种**面向对象(OOP)**的设计,能够很好地隔离状态(成员变量)与行为(成员函数)。
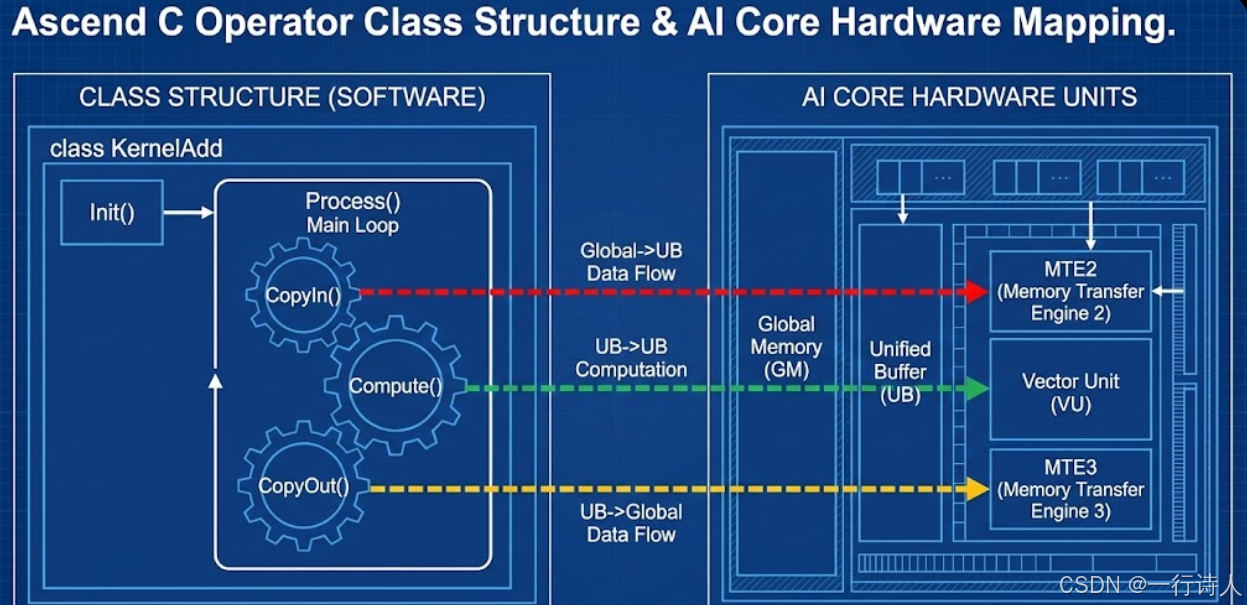
1.1 核心类定义
#include "kernel_operator.h" // 核心头文件,包含 Ascend C 所有基础 API
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2; // 双缓冲配置,固定为 2
class KernelAdd {
public:
// 1. 初始化函数:完成内存初始化、Tiling 参数解析
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileLength) {
// ...
}
// 2. 核心处理函数:编排流水线
__aicore__ inline void Process() {
// ...
}
private:
// 3. 流水线三级 stage
__aicore__ inline void CopyIn(int32_t progress);
__aicore__ inline void Compute(int32_t progress);
__aicore__ inline void CopyOut(int32_t progress);
private:
// 4. 成员变量:管道与队列
TPipe pipe;
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; // 输入队列 VECIN
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; // 输出队列 VECOUT
// 5. 成员变量:Global Tensor (管理 GM 地址)
GlobalTensor<half> xGm, yGm, zGm;
// 6. 成员变量:Tiling 参数
uint32_t totalLength;
uint32_t tileLength;
};
解析:
-
constexpr int32_t BUFFER_NUM = 2:这是实现 Ping-Pong 流水线的基石。 -
TPipe pipe:管道对象,负责管理 Unified Buffer (UB) 的内存分配。 -
TQue:队列对象,是 Ascend C 中最关键的通信原语,用于在 CopyIn/Compute/CopyOut 之间传递数据并实现同步。
二、 微观拆解:逐函数精讲
接下来,我们深入到每个函数的内部,看看标准写法是怎样的。
2.1 Init():把好入口关
Init 函数主要负责两件事:入参解析 和 资源初始化。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength, uint32_t tileLength) {
// [1] 初始化 Global Tensor
// SetGlobalBuffer 将 GM_ADDR (void*) 转换为带类型的 GlobalTensor
// 这里的 totalLength 是该核需要处理的总长度(已由 Host 侧 Tiling 算好)
xGm.SetGlobalBuffer((__gm__ half*)x + block_idx * totalLength, totalLength);
yGm.SetGlobalBuffer((__gm__ half*)y + block_idx * totalLength, totalLength);
zGm.SetGlobalBuffer((__gm__ half*)z + block_idx * totalLength, totalLength);
// [2] 保存 Tiling 参数
this->totalLength = totalLength;
this->tileLength = tileLength;
// [3] 初始化内存队列
// InitBuffer 会在 UB 上根据 tileLength * sizeof(T) 划分物理内存
// BUFFER_NUM=2 表示为每个队列分配两块这样的内存,用于双缓冲
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, this->tileLength * sizeof(half));
}
最佳实践:
-
即使在多核场景下,
Init的入参通常也只是 Base Address。需要结合block_idx(当前核 ID)来计算当前核应该处理的数据偏移。 -
pipe.InitBuffer是真正的内存分配动作。如果 UB 空间不够,程序会在这里挂掉。
2.2 Process():流水线总指挥
Process 函数负责循环调度。
__aicore__ inline void Process() {
// 计算需要循环多少次 (TileNum)
int32_t loopCount = this->totalLength / this->tileLength;
for (int32_t i = 0; i < loopCount; i++) {
// 标准的三级流水线调用
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
思考: 为什么这里是串行调用的? 虽然代码写的是串行,但由于 TQue 的存在,CopyIn 把数据放入队列后就会返回,Compute 只要检测到队列有数据就会开始执行。硬件上,MTE 和 Vector 单元是并行工作的。
2.3 CopyIn():搬运工
__aicore__ inline void CopyIn(int32_t progress) {
// [1] 申请 Local Tensor (从 UB 里的 inQueueX 分配一块空闲内存)
// 如果队列满了 (2块都在用),这里会阻塞,直到 Compute 释放一块
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// [2] 执行搬运 (GM -> UB)
// DataCopy 是异步指令,发出后不等待搬运完成
DataCopy(xLocal, xGm[progress * tileLength], tileLength);
DataCopy(yLocal, yGm[progress * tileLength], tileLength);
// [3] 入队 (EnQue)
// 这一步是关键!它告诉后续的 Compute 阶段:"这块内存我正在搬运中,等搬完了你就可以用了"
// 硬件会自动处理 DataCopy 完成后的依赖关系
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
2.4 Compute():计算核心
__aicore__ inline void Compute(int32_t progress) {
// [1] 出队 (DeQue)
// 阻塞等待 CopyIn 搬运完成。一旦返回,说明 xLocal/yLocal 里已经是有效数据了
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
// [2] 申请输出内存
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// [3] 执行计算 (Vector Unit)
Add(zLocal, xLocal, yLocal, tileLength);
// [4] 释放输入内存 (FreeTensor)
// 这一步非常重要!释放后,CopyIn 才能利用这块 Ping-Pong 内存搬运下一轮数据
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
// [5] 输出入队
outQueueZ.EnQue(zLocal);
}
2.5 CopyOut():善后工作
__aicore__ inline void CopyOut(int32_t progress) {
// [1] 出队 (DeQue)
// 等待 Compute 计算完成
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// [2] 搬回 GM
DataCopy(zGm[progress * tileLength], zLocal, tileLength);
// [3] 释放输出内存
outQueueZ.FreeTensor(zLocal);
}
三、 总结:从代码到哲学的升华
通过解剖这份样例代码,我们可以总结出 Ascend C Vector 开发的 "黄金法则":
-
资源预分配:所有 UB 内存都在
Init中通过pipe.InitBuffer规划好,Process运行期间不进行动态内存分配(除了 Stack)。 -
队列驱动:
Alloc->DataCopy->EnQue->DeQue->Compute->Free。这套组合拳是死记硬背也要记住的。 -
双缓冲隐喻:代码中并没有显式写 "Ping Buffer" 或 "Pong Buffer",而是通过
BUFFER_NUM = 2和队列机制,让硬件自动实现了 Ping-Pong 切换。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)