
深入理解华为 CANN:AI Core 架构的算子执行之道
在昇腾 CANN 的算子开发体系中,AI Core 是整个算子执行的计算核心。算子开发者要想写出高性能的 TBE/Ascend C 代码,必须理解 AI Core 的“内部世界”。这一内部世界并非传统意义上的 CPU 或 GPU,而是一套面向 AI 算法场景深度定制的计算体系。
深入理解华为 CANN:AI Core 架构的算子执行之道
在昇腾 CANN 的算子开发体系中,AI Core 是整个算子执行的计算核心。算子开发者要想写出高性能的 TBE/Ascend C 代码,必须理解 AI Core 的“内部世界”。这一内部世界并非传统意义上的 CPU 或 GPU,而是一套面向 AI 算法场景深度定制的计算体系。
本文将从架构设计理念入手,逐层剖析 AI Core 的计算单元、存储系统与指令流水线,帮助开发者构建对算子性能调优的宏观理解与微观认知。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、为什么需要 AI Core?从通用架构到特定域架构(DSA)
深度学习模型越来越大,算子对矩阵乘、卷积、激活等操作的计算密度要求越来越高。
传统 CPU 更偏向控制逻辑处理,GPU 虽然擅长矩阵向量计算,但其通用性带来的编程自由度也意味着硬件资源利用率难以极致压榨。
AI Core 属于“特定域架构”(Domain Specific Architecture),即为了特定任务场景(深度学习)而进行硬件设计优化。
其核心目标是:
- 把深度学习常见计算(矩阵乘、向量计算、标量控制)拆成三类专用计算单元;
- 将数据的生命周期固定在多级 Buffer 中,尽可能减少吞吐瓶颈;
- 通过五类并行指令流水线最大化运算重叠度。
结果就是:在相同算力规模下,AI Core 可以比通用架构获得更高的有效利用率。
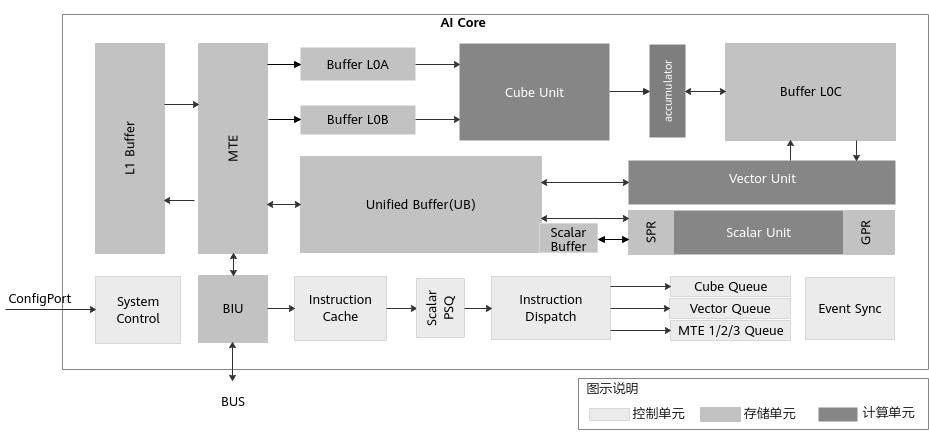
二、AI Core 的整体结构:一台专为 AI 打造的“微架构引擎”
AI Core 的内部逻辑可以分为三大模块:
- 计算单元(Compute Units)——负责算力输出
- 存储系统(Memory & Buffers)——负责数据调度和缓存
- 控制系统(Control Units)——负责指令流控制与调度执行
这三个模块构成了 AI Core 的硬件基础,就像汽车的发动机、油箱和控制器协同工作一样。
下面我们逐个展开。
三、计算单元:Cube、Vector、Scalar 三驾马车
在 AI Core 中,每种计算任务都被划分到最适合的执行部件中,以避免通用性设计造成的性能浪费。
3.1 Cube Unit:为深度学习矩阵乘量身定制的“矩阵引擎”
Cube 是整个 AI Core 中最强大的计算模块,专门用于执行深度学习中占比最高的矩阵乘。
它的特点包括:
- 固定规模矩阵块计算(如 16×16×16/int8 模式为 16×32×16)
- 高吞吐、低控制复杂度
- 数据固定从 L0A/L0B 进入,结果写入 L0C
Cube 的设计思路是:
把矩阵乘的核心逻辑固化为硬件流水线,让硬件自动处理大部分 tile-level 的数据流。
因此算子开发中,我们只需要知道“如何把矩阵拆分成 Cube 支持的 tile”,而无需关心矩阵乘具体如何计算。
3.2 Vector Unit:灵活、多样、可执行数学函数的向量计算单元
对许多非纯矩阵类算子,例如:
- 激活函数(ReLU、Sigmoid)
- 求倒数、求平方根
- 广播计算
- BatchNorm、LayerNorm 部分过程
Vector Unit 的作用更加关键。
其特点:
- 计算灵活度高,适合执行 element-wise 运算
- 数据必须存放在 Unified Buffer(UB)
- 操作要求严格对齐(32 字节)
Vector 加载/存储依赖 MTE,而不是直接访问外部存储。
因此 向量算子性能优化的关键,就是设计高效的 UB 分配与数据搬运策略。
3.3 Scalar Unit:AI Core 内部的小型“控制 CPU”
标量单元主要负责:
- Loop 计数器
- 条件判断
- 程序流控制
- 参数准备(地址计算、Cube/Vector 参数配置)
Scalar Unit 本身算力弱,但承担整个算子执行流程的调度大脑角色。
一句话总结:
Cube 是肌肉,Vector 是四肢,而 Scalar 是大脑。
四、多级存储体系:数据流动是算子性能的核心
AI Core 的存储体系比 GPU 更“显式”,更强调数据搬运路径。
其本质目标是:
- 减少访问外部存储(GM)的次数
- 保证 Cube、Vector 在运算时不会被数据加载延迟阻塞
为此 AI Core 构建了多级 Buffer 系统:
4.1 L1 Buffer:算子内部的数据中转站
L1 是一个较大的内部缓存,常用于:
- 存放重复使用的数据
- 作为 MTE 格式转换的源(如 Img2Col)
- 减少外部总线访问
在算子调优中,如何利用 L1 缓存更多中间块,能显著影响吞吐。
4.2 L0A / L0B / L0C:Cube 的专用三级小缓存
Cube 读取的数据必须来自:
- L0A:矩阵 A
- L0B:矩阵 B
- L0C:输出矩阵和中间累加值
这三者的容量很小,但延迟极低。
算子调优实质上就是:
如何把大矩阵切成适合 Cube tile 的片段,并设计最优 L0 数据流。
4.3 Unified Buffer(UB):Vector 的计算地带
Vector 计算完全在 UB 内部进行。UB 较大,但也有限,通常需要:
- Tile 切分
- Double-buffer 机制
- 数据搬运 Pipeline 化
因此好的 Vector 算子往往关键是“数据搬运策略”。
4.4 Scalar Buffer + GPR + SPR
用于:
- 存储标量数据
- 扩展 GPR 寄存器不足的情况
- 配置 AI Core 的执行行为(SPR)
开发者不需要直接操作寄存器,但需要理解:
Scalar 操作也会消耗指令周期,设计 Tiling 时不能让 Scalar 成为瓶颈。
五、数据搬运引擎 MTE:Buffer 之间的高速公路
为了让数据在不同 Buffer 间高效移动,AI Core 提供三个 MTE 执行队列:
- MTE1:L1 与 L0/UB 之间搬运
- MTE2:GM → L1/L0/UB
- MTE3:UB → GM
搬运不仅仅是“复制数据”,还支持:
- Padding
- Transpose
- NCHW→NHWC
- Img2Col
因此 MTE 本身就是一个“轻计算引擎”,很多算子性能瓶颈其实来自 MTE 调度不当。
六、控制系统:AI Core 的“指挥中心”如何调度整个算子执行?
AI Core 的控制系统负责任务执行的调度,包括:
- 指令缓存(Instruction Cache)
- Scalar 指令队列(Scalar PSQ)
- 指令分发(Dispatch)
- Cube/Vector/MTE 队列
- 队列之间的同步(Event Sync)
关键机制:五队列并行执行
AI Core 支持六类指令:
- S(Scalar)
- V(Vector)
- M(Matrix)
- MTE1
- MTE2
- MTE3
其中五类(除 Scalar 外)的队列可乱序执行,这意味着:
只要没有数据依赖,不同类型指令可以完全并行,从而实现最高的 pipeline 吞吐。
深度学习算子性能的核心思路:让五类队列持续不断地忙碌
一个优秀的算子应该做到:
- Cube 在计算
- 同时 MTE2 在加载下一 tile
- MTE3 在把上一 tile 结果写回
- Vector 在做激活或归一化
- Scalar 在准备下一轮循环参数
所有队列都应当“无空闲”,才是最佳性能。
七、队列之间的依赖与同步:Barrier 与 Flag 的本质
虽然 CANN 封装了同步细节,但算子开发者仍需理解:
- Barrier 用于队列内部顺序控制
- Flag 用于不同队列之间的依赖控制
例如:
- 当 Cube 使用的数据还未搬进 L0,就必须 wait。
- 当 Vector 需要使用 UB 中的数据,也要 wait MTE 完成。
理解这点对于 Tiling 切分和指令调度策略极其关键。
八、总结:理解 AI Core,才能写出高性能算子
AI Core 是一个高度专业化的加速器架构,其设计理念围绕深度学习高并发、高吞吐的计算需求展开。
理解其结构有助于我们在 TBE/Ascend C 开发中做出正确的性能决策:
- Cube 用于矩阵计算,Vector 用于 element-wise,Scalar 负责控制
- 数据必须在多级 Buffer 间高效流动
- 五类队列并行调度是性能优化的核心
- MTE 承担大量数据转换与搬运任务
- 理解同步机制可以显著减少 pipeline stall
最终目的只有一个:
写出能高效利用硬件、真正发挥昇腾算力的高性能 AI 算子。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)