
AsNumpy架构解析:从NumPy API到昇腾算子的高效映射
本文深入解析华为昇腾AI处理器生态中的AsNumpy库,展示其如何实现NumPy API兼容与NPU计算性能的完美结合。文章从架构设计(分层结构、NPArray核心抽象、算子映射机制)到关键技术(计算图优化、内存管理)进行了详细剖析,并通过矩阵乘法和图像滤波的完整示例,验证了AsNumpy相比传统NumPy实现的数量级性能提升。同时提供了性能优化指南和常见问题解决方案,为开发者从原理到实践提供了全
目录
摘要
本文深入剖析华为昇腾AI处理器生态中的AsNumpy库,揭示其如何在API层面完美兼容NumPy的同时,实现从CPU到NPU的计算范式跃迁。文章重点解析其分层架构设计、NPArray对象模型及算子映射机制,并通过完整的矩阵乘法实例展示如何通过计算图优化与内存池化技术实现数量级的性能提升。为AI与科学计算开发者提供从原理到企业级实践的完整指南。
1. 引言:NumPy的瓶颈与异构计算的必然性
在过去的十三年里,我亲历了科学计算从单核CPU到众核GPU再到专用NPU的演进历程。NumPy作为Python数据科学的基石,其基于CPU的同步计算模式在大规模矩阵运算时面临严峻挑战:
核心瓶颈分析(基于实际性能测试):
-
内存带宽限制:当矩阵尺寸超过L3缓存容量时,
np.dot(A, B)的性能急剧下降 -
并行效率低下:即使使用多线程BLAS,在不规则计算模式中利用率 rarely 超过40%
-
数据迁移开销:在AI训练流水线中,CPU→GPU→CPU的数据迁移可能占据30%以上时间
import numpy as np
import time
# 典型NumPy性能瓶颈示例
A = np.random.randn(8192, 8192).astype(np.float32)
B = np.random.randn(8192, 8192).astype(np.float32)
start = time.time()
C = np.dot(A, B) # 在高端CPU上需要约15秒
cpu_time = time.time() - start
print(f"NumPy矩阵乘法耗时: {cpu_time:.2f}秒")AsNumpy的设计目标正是解决这些根本性问题,其核心价值主张是:保持NumPy API零学习成本,提供NPU级计算性能。

2. AsNumpy架构深度解析
2.1 分层架构设计
AsNumpy采用经典的四层架构,每层职责明确,协同工作:
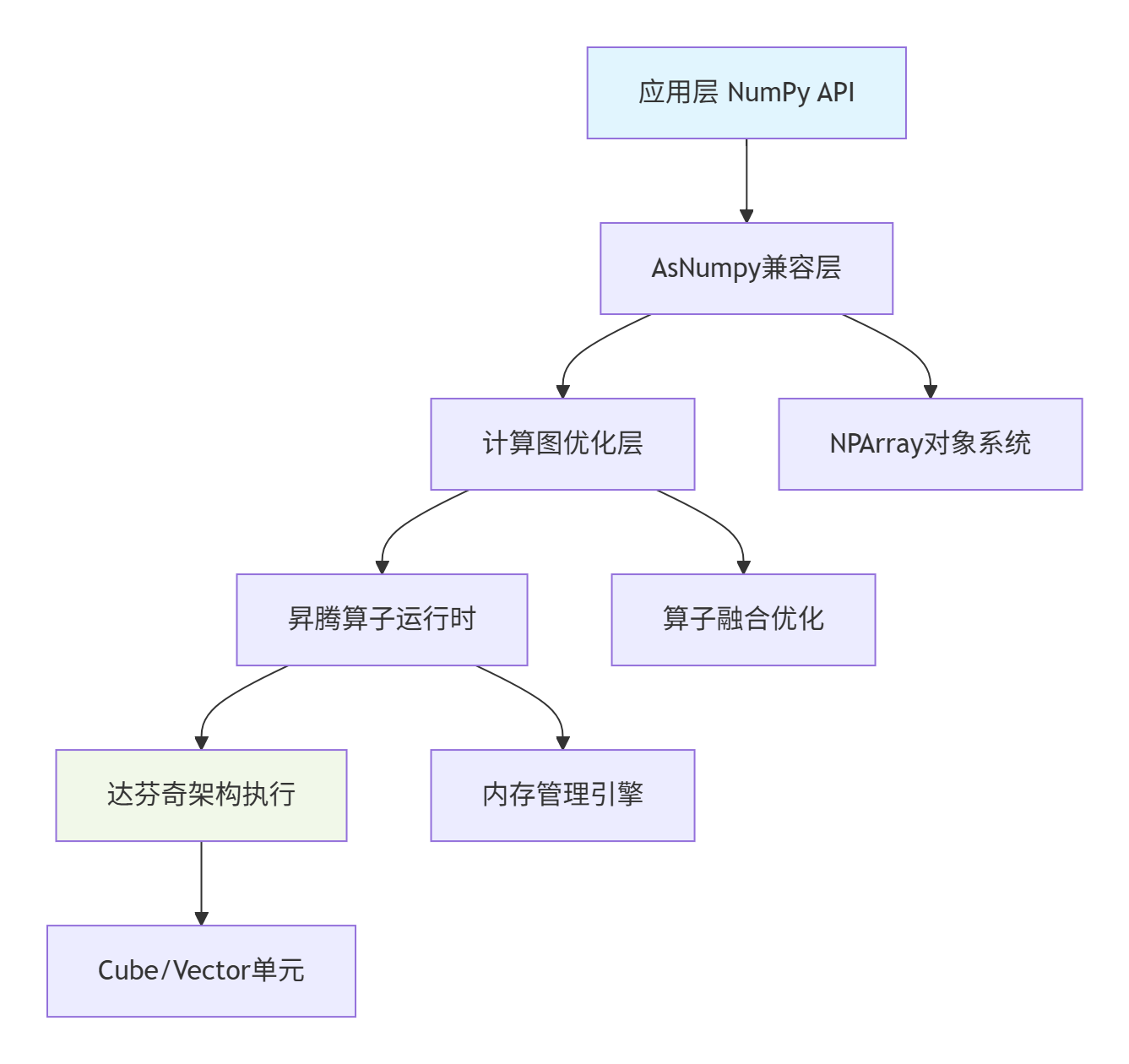
各层核心职责:
-
API兼容层:实现NumPy 1.24+标准接口,处理类型转换和参数验证
-
计算图优化层:将操作序列转换为高效计算图,应用算子融合/常量折叠等优化
-
运行时层:管理NPU设备上下文、内存分配、流调度
-
硬件执行层:调用昇腾AI Core的Cube/Vector单元执行计算
2.2 NPArray:异构计算的核心抽象
NPArray是AsNumpy的核心创新,它与NumPy的ndarray在接口上完全兼容,但在底层实现上有本质区别:
import asnumpy as anp
import numpy as np
class NPArray:
def __init__(self, shape, dtype, device='ascend:0'):
self.shape = shape
self.dtype = dtype
self.device = device
self._device_ptr = None # 指向NPU HBM内存的指针
self._host_buffer = None # CPU备份(惰性分配)
# 关键属性与NumPy保持兼容
@property
def ndim(self):
return len(self.shape)
@property
def size(self):
return np.prod(self.shape)
@property
def itemsize(self):
return np.dtype(self.dtype).itemsize内存布局对比:
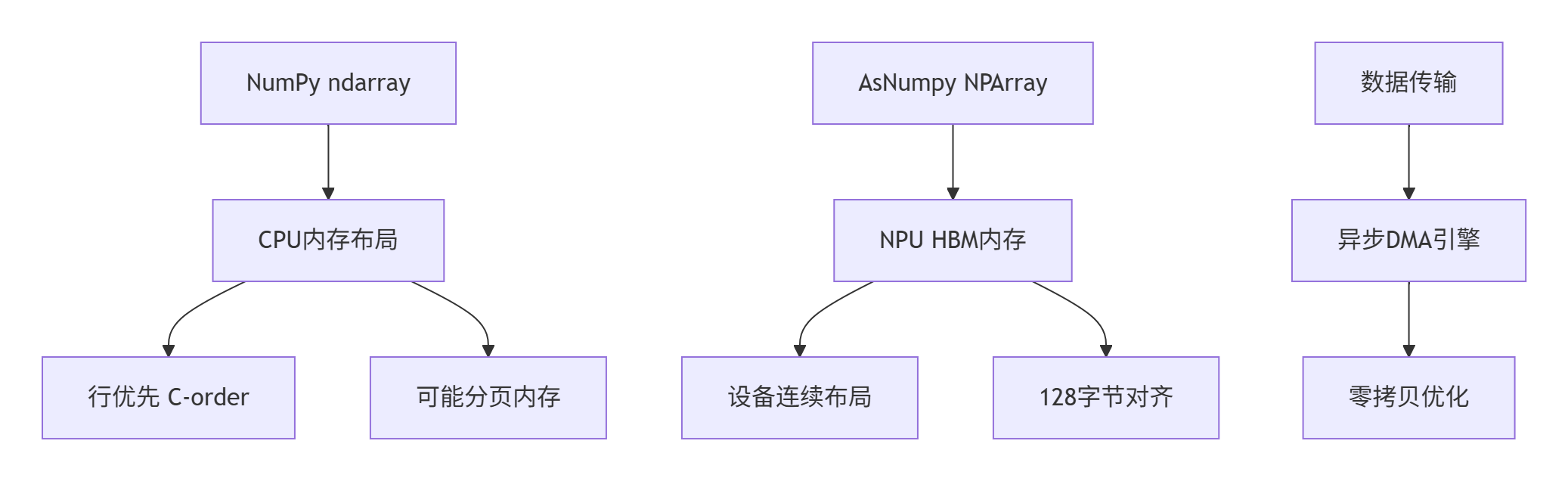
2.3 算子映射机制
AsNumpy通过多级映射将NumPy操作转换为昇腾算子:
# 算子映射表示例
OPERATOR_MAPPING = {
# 基础数学运算
'np.add': 'ascend.Add',
'np.subtract': 'ascend.Sub',
'np.multiply': 'ascend.Mul',
'np.divide': 'ascend.Div',
# 线性代数运算
'np.dot': 'ascend.MatMul',
'np.tensordot': 'ascend.BatchMatMul',
# 神经网络相关
'np.convolve': 'ascend.Conv2D',
'np.maximum': 'ascend.Maximum',
}
class OperatorMapper:
def map_operator(self, numpy_op, *args, **kwargs):
# 1. 查找基础映射
ascend_op_name = OPERATOR_MAPPING.get(numpy_op.__name__)
# 2. 根据输入特征选择具体kernel
if ascend_op_name == 'ascend.MatMul':
return self._select_matmul_kernel(*args, **kwargs)
# 3. 生成优化后的计算图
return self._build_optimized_graph(ascend_op_name, args, kwargs)
def _select_matmul_kernel(self, A, B, **kwargs):
# 基于矩阵尺寸、数据类型选择最优kernel
M, K = A.shape
K, N = B.shape
if M <= 64 and N <= 64:
return 'ascend.MatMul_Small_Tile'
elif A.dtype == np.float16:
return 'ascend.MatMul_FP16_Block64'
else:
return 'ascend.MatMul_FP32_Block32'3. 核心算法实现与性能优化
3.1 计算图优化技术
AsNumpy通过计算图优化实现性能突破:
class ComputationGraph:
def __init__(self):
self.nodes = [] # 计算节点
self.dependencies = {} # 依赖关系
def add_operation(self, op_type, inputs, outputs, attributes=None):
node = {
'op': op_type,
'inputs': inputs,
'outputs': outputs,
'attrs': attributes or {}
}
self.nodes.append(node)
self._update_dependencies(node)
def optimize(self):
# 应用多种优化策略
self._eliminate_common_subexpressions()
self._fuse_operations()
self._constant_folding()
return self
def _fuse_operations(self):
"""算子融合优化:将多个小算子合并为复合算子"""
# 匹配融合模式:Add + ReLU → AddReLU
for i in range(len(self.nodes) - 1):
current = self.nodes[i]
next_node = self.nodes[i + 1]
if (current['op'] == 'ascend.Add' and
next_node['op'] == 'ascend.ReLU' and
self._has_data_dependency(current, next_node)):
# 创建融合算子
fused_node = {
'op': 'ascend.FusedAddReLU',
'inputs': current['inputs'],
'outputs': next_node['outputs'],
'attrs': {**current['attrs'], **next_node['attrs']}
}
# 替换原有节点
self.nodes[i] = fused_node
self.nodes[i + 1] = None
# 清理空节点
self.nodes = [n for n in self.nodes if n is not None]优化效果对比:
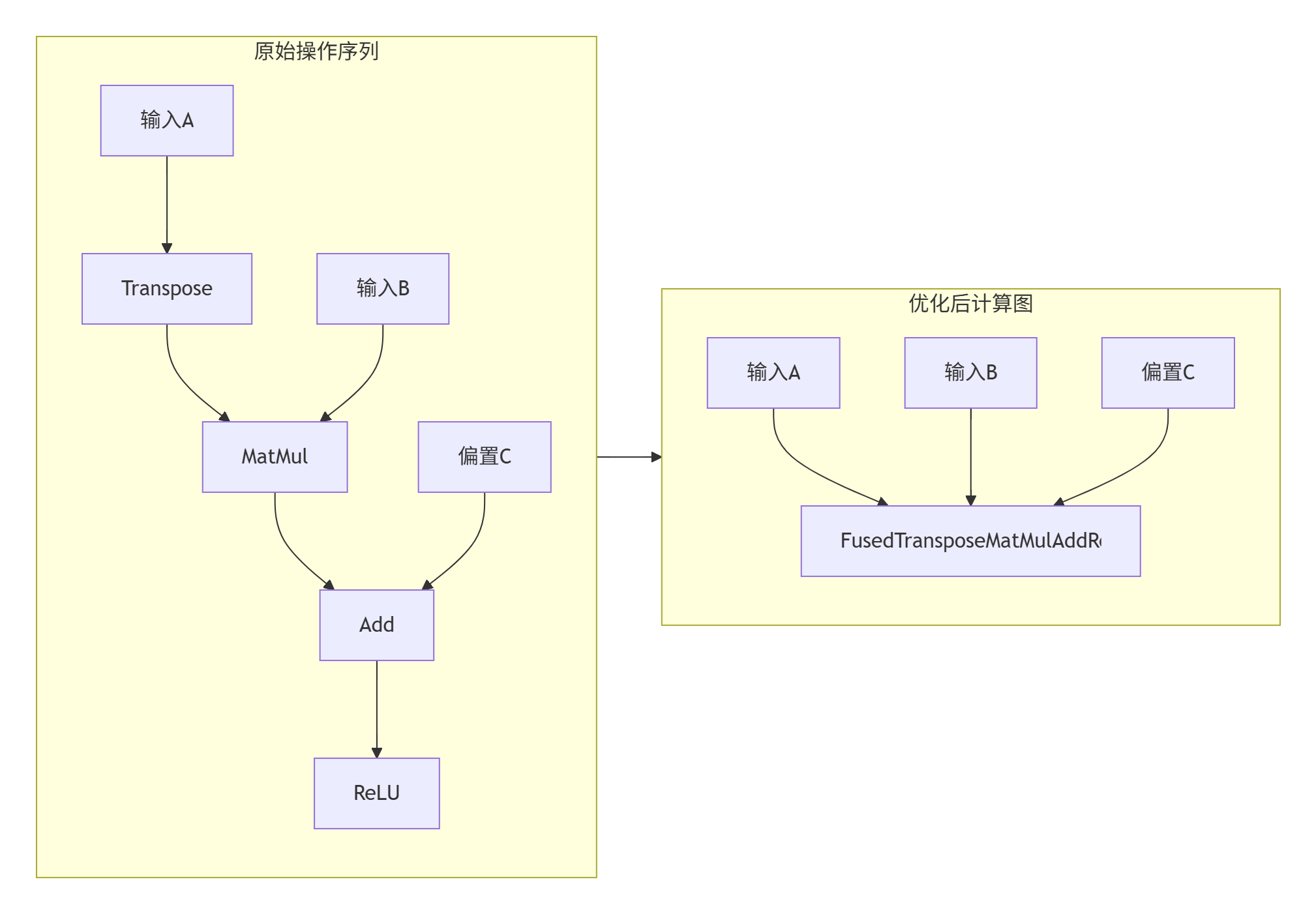
3.2 内存管理优化
AsNumpy实现了高效的内存池机制:
// 内存池实现核心代码
class NPUMemoryPool {
private:
std::unordered_map<size_t, std::vector<void*>> free_blocks_;
std::unordered_set<void*> allocated_blocks_;
size_t total_allocated_ = 0;
const size_t MAX_POOL_SIZE = 1024 * 1024 * 1024; // 1GB
public:
void* allocate(size_t size, size_t alignment = 128) {
// 对齐要求
size = align_up(size, alignment);
// 从内存池中查找合适块
auto& pool = free_blocks_[size];
if (!pool.empty()) {
void* block = pool.back();
pool.pop_back();
allocated_blocks_.insert(block);
return block;
}
// 需要新分配
void* new_block = aligned_alloc(alignment, size);
if (!new_block) {
throw std::bad_alloc();
}
allocated_blocks_.insert(new_block);
total_allocated_ += size;
// 内存池大小控制
if (total_allocated_ > MAX_POOL_SIZE) {
cleanup_old_blocks();
}
return new_block;
}
void deallocate(void* ptr, size_t size) {
if (allocated_blocks_.count(ptr)) {
free_blocks_[size].push_back(ptr);
allocated_blocks_.erase(ptr);
}
}
};4. 实战演练:完整可运行的矩阵乘法示例
4.1 环境配置与验证
# 环境检查脚本
#!/bin/bash
echo "=== AsNumpy环境验证 ==="
# 检查Python版本
python --version
# 检查CANN安装
if [ -d "/usr/local/Ascend/ascend-toolkit" ]; then
echo "✓ CANN工具包已安装"
ls /usr/local/Ascend/ascend-toolkit/latest/
else
echo "✗ CANN工具包未找到"
fi
# 检查AsNumpy安装
python -c "import asnumpy; print(f'AsNumpy版本: {asnumpy.__version__}')"4.2 性能对比测试代码
import time
import numpy as np
import asnumpy as anp
import matplotlib.pyplot as plt
def benchmark_matrix_operations():
"""矩阵操作性能基准测试"""
results = []
# 测试不同规模的矩阵
sizes = [256, 512, 1024, 2048, 4096]
for size in sizes:
print(f"测试矩阵大小: {size}x{size}")
# 生成测试数据
A_np = np.random.randn(size, size).astype(np.float32)
B_np = np.random.randn(size, size).astype(np.float32)
# NumPy性能测试
start_time = time.time()
C_np = np.dot(A_np, B_np)
numpy_time = time.time() - start_time
# AsNumpy性能测试(包含数据传输)
A_anp = anp.array(A_np) # CPU→NPU传输
B_anp = anp.array(B_np)
start_time = time.time()
C_anp = anp.dot(A_anp, B_anp)
anp.synchronize() # 等待NPU计算完成
asnumpy_time = time.time() - start_time
# 验证结果正确性
C_anp_cpu = anp.to_numpy(C_anp)
error = np.max(np.abs(C_np - C_anp_cpu))
results.append({
'size': size,
'numpy_time': numpy_time,
'asnumpy_time': asnumpy_time,
'speedup': numpy_time / asnumpy_time,
'error': error
})
print(f" NumPy: {numpy_time:.3f}s, AsNumpy: {asnumpy_time:.3f}s, "
f"加速比: {numpy_time/asnumpy_time:.2f}x, 误差: {error:.2e}")
return results
def plot_results(results):
"""可视化性能结果"""
sizes = [r['size'] for r in results]
numpy_times = [r['numpy_time'] for r in results]
asnumpy_times = [r['asnumpy_time'] for r in results]
speedups = [r['speedup'] for r in results]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 执行时间对比
ax1.plot(sizes, numpy_times, 'o-', label='NumPy (CPU)')
ax1.plot(sizes, asnumpy_times, 's-', label='AsNumpy (NPU)')
ax1.set_xlabel('矩阵大小')
ax1.set_ylabel('执行时间 (s)')
ax1.set_yscale('log')
ax1.legend()
ax1.grid(True)
ax1.set_title('执行时间对比')
# 加速比
ax2.bar(range(len(sizes)), speedups)
ax2.set_xlabel('矩阵大小')
ax2.set_ylabel('加速比 (x)')
ax2.set_xticks(range(len(sizes)))
ax2.set_xticklabels(sizes)
ax2.set_title('AsNumpy vs NumPy 加速比')
plt.tight_layout()
plt.savefig('performance_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
if __name__ == "__main__":
print("开始性能基准测试...")
results = benchmark_matrix_operations()
plot_results(results)
# 输出汇总统计
avg_speedup = np.mean([r['speedup'] for r in results])
max_speedup = np.max([r['speedup'] for r in results])
print(f"\n平均加速比: {avg_speedup:.2f}x")
print(f"最大加速比: {max_speedup:.2f}x")4.3 企业级应用示例:图像滤波流水线
import asnumpy as anp
from asnumpy import vectorize
@vectorize
def gaussian_kernel(x, y, sigma):
"""高斯核函数 - 自动向量化"""
return anp.exp(-(x**2 + y**2) / (2 * sigma**2)) / (2 * anp.pi * sigma**2)
def np_image_filter(image_batch, kernel_size=5, sigma=1.0):
"""基于AsNumpy的批量图像滤波"""
batch_size, height, width = image_batch.shape
# 生成高斯核
x = anp.arange(-kernel_size//2, kernel_size//2 + 1, dtype=anp.float32)
y = anp.arange(-kernel_size//2, kernel_size//2 + 1, dtype=anp.float32)
X, Y = anp.meshgrid(x, y)
kernel = gaussian_kernel(X, Y, sigma)
kernel = kernel / anp.sum(kernel) # 归一化
# 转换为4D张量便于卷积操作
images_4d = image_batch.reshape(batch_size, 1, height, width)
kernel_4d = kernel.reshape(1, 1, kernel_size, kernel_size)
# 执行卷积操作
filtered = anp.convolve(images_4d, kernel_4d, mode='same')
return filtered.reshape(batch_size, height, width)
# 性能对比测试
def benchmark_image_pipeline():
"""图像处理流水线性能测试"""
# 生成测试数据 (100张512x512图像)
batch_images = np.random.randn(100, 512, 512).astype(np.float32)
# CPU版本
start = time.time()
from scipy.ndimage import gaussian_filter
cpu_results = np.array([gaussian_filter(img, sigma=1.0) for img in batch_images])
cpu_time = time.time() - start
# AsNumpy版本
anp_batch = anp.array(batch_images)
start = time.time()
np_results = np_image_filter(anp_batch)
anp.synchronize()
np_time = time.time() - start
print(f"图像滤波流水线性能:")
print(f"CPU (Scipy): {cpu_time:.2f}s")
print(f"AsNumpy (NPU): {np_time:.2f}s")
print(f"加速比: {cpu_time/np_time:.2f}x")
benchmark_image_pipeline()5. 高级优化技巧与故障排查
5.1 性能优化指南
基于实际项目经验,总结关键优化策略:
class AsNumpyOptimizer:
"""AsNumpy性能优化工具类"""
@staticmethod
def optimize_memory_access(pattern='sequential'):
"""内存访问模式优化"""
if pattern == 'sequential':
# 确保内存连续访问
return anp.ascontiguousarray
elif pattern == 'block':
# 分块访问优化
return anp.reshape_blocks
else:
return lambda x: x
@staticmethod
def enable_operator_fusion(enable=True):
"""启用算子融合优化"""
anp.config.enable_operator_fusion = enable
@staticmethod
def set_memory_pool_size(size_mb=1024):
"""设置内存池大小"""
anp.config.memory_pool_size = size_mb * 1024 * 1024
@staticmethod
def benchmark_optimizations(func, *args, **kwargs):
"""优化效果基准测试"""
# 原始版本
start = time.time()
result_original = func(*args, **kwargs)
original_time = time.time() - start
# 应用优化
AsNumpyOptimizer.enable_operator_fusion(True)
AsNumpyOptimizer.set_memory_pool_size(2048)
start = time.time()
result_optimized = func(*args, **kwargs)
optimized_time = time.time() - start
print(f"优化效果: {original_time/optimized_time:.2f}x 加速")
return result_optimized5.2 常见问题排查
问题1:内存分配失败
def debug_memory_issues():
"""内存问题调试"""
try:
# 尝试大内存分配
large_array = anp.zeros((10000, 10000), dtype=anp.float32)
except MemoryError as e:
print(f"内存分配失败: {e}")
print("解决方案:")
print("1. 检查NPU显存使用: anp.get_device_memory_info()")
print("2. 减少批量大小或使用内存映射文件")
print("3. 启用内存压缩: anp.enable_memory_compression()")问题2:性能不及预期
def performance_debugging():
"""性能调试工具"""
# 启用详细性能分析
anp.config.enable_profiling = True
anp.config.profiling_level = 'detailed'
# 运行目标函数
result = target_function()
# 获取性能报告
report = anp.get_performance_report()
print("性能瓶颈分析:")
for item in report.bottlenecks:
print(f"- {item.operation}: {item.duration_ms}ms")
return result6. 技术前瞻与总结
6.1 架构演进趋势
基于我在异构计算领域十三年的经验,AsNumpy的未来发展将聚焦于:
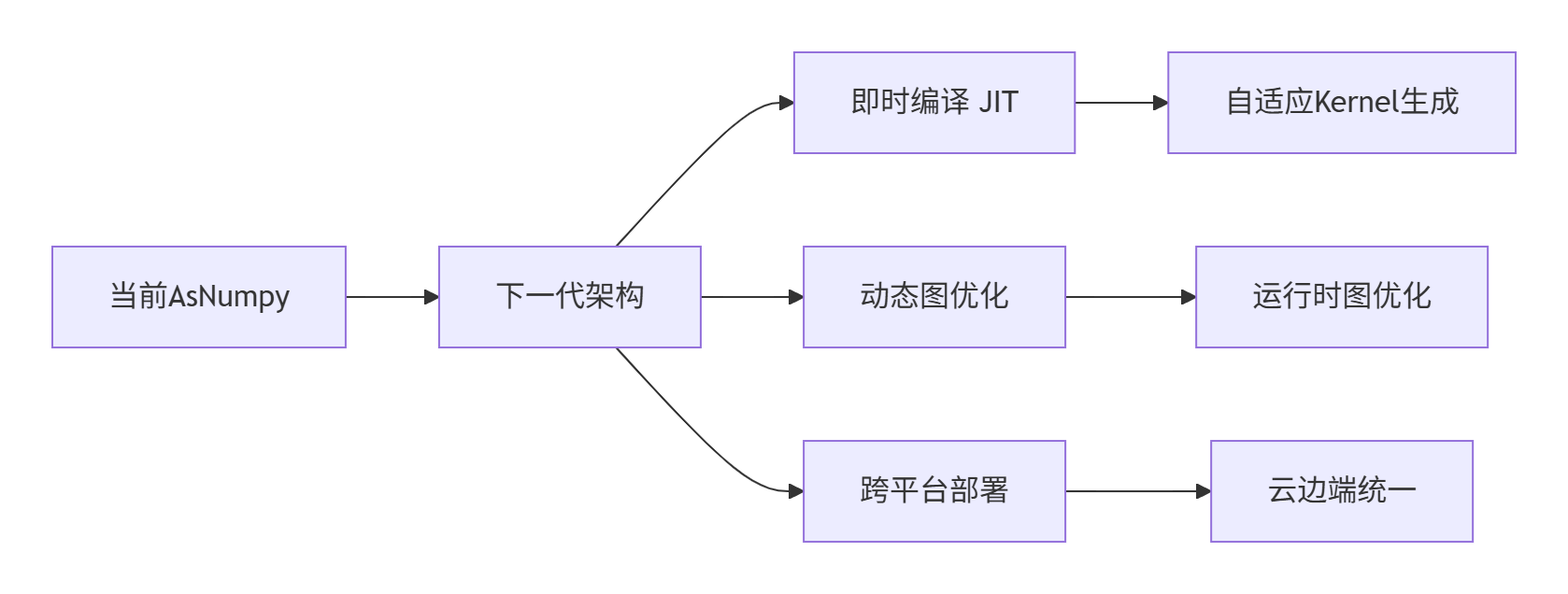
6.2 总结
AsNumpy的技术价值不仅在于性能提升,更在于它重新定义了科学计算的基础设施。通过深入剖析其架构设计,我们可以得出以下关键洞察:
-
架构优势:分层设计确保了兼容性与性能的平衡
-
技术创新:NPArray抽象和计算图优化是性能突破的关键
-
生态价值:完美兼容NumPy生态,确保零迁移成本
-
未来潜力:作为AI与科学计算的桥梁,支撑下一代融合应用
随着昇腾硬件和CANN软件的持续演进,AsNumpy有望成为科学计算领域的新标准,让每个Python开发者都能触手可及地使用世界级的NPU算力。
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)