
【昇腾CANN训练营·第四期】Ascend C算子开发进阶:深入解析Vector算子泛化Tiling策略
摘要:2025年昇腾CANN训练营第二季推出系列课程,助力开发者提升算子开发技能。本文重点探讨AscendC算子开发中的泛化Tiling策略设计,解决动态Shape处理难题。文章详细分析了Tiling策略的硬件约束条件,包括UB容量限制、双缓冲机制和内存对齐要求,并推导了基于Vector向量算子场景的通用切分算法。通过Host侧代码实现和Kernel侧逻辑适配,展示了如何构建自适应任意数据长度、满
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在算子开发初期,为了快速验证逻辑,开发者往往采用固定的Tiling参数(如固定分块大小或核数)。然而,在实际的工业级应用中,算子必须具备处理动态Shape的能力。输入数据的维度和大小在运行时才能确定,硬编码(Hard-coded)的切分策略会导致以下问题:
-
内存利用率低:对于小Shape数据,无法充分利用Unified Buffer (UB),导致流水线空转。
-
程序崩溃:对于超大Shape数据,固定大小可能导致UB溢出或地址越界。
-
性能瓶颈:无法根据硬件资源(如不同芯片的Core数量、UB大小)自适应调整,无法发挥硬件最大算力。
本文将深入探讨Ascend C算子开发中的核心难点——泛化Tiling策略的设计与实现。我们将基于Vector向量算子场景,构建一套能够自适应任意数据长度、满足内存对齐约束且性能最优的通用切分算法。
一、 Tiling策略的约束条件与设计原则
Tiling(切分)的本质是解决AI Core有限的片上存储(Local Memory)与大规模片外数据(Global Memory)之间的矛盾。设计Tiling策略时,必须严格遵循以下三个硬件约束:
1.1 统一缓冲区(UB)容量限制
AI Core内部的Unified Buffer容量是固定的(例如Ascend 910B通常为192KB或更大)。算子执行过程中,所有的输入、输出以及中间临时变量都必须驻留在UB中。 设计原则:单次处理的数据块(Tile)大小之和不能超过UB的总可用容量。
1.2 流水线并行与双缓冲(Double Buffer)
为了掩盖数据搬运(MTE)的延迟,Ascend C推荐使用Double Buffer机制。这意味着我们需要将分配给Tensor的UB空间一分为二。 设计原则:在计算Block Size时,有效可用空间应除以2。即:
$$\text{BlockSize} \le \frac{\text{AvailableUB}}{2}$$
1.3 内存地址对齐(Alignment)
这是导致算子执行失败最常见的原因。AI Core的DMA搬运指令(DataCopy)通常要求源地址和目标地址满足32字节对齐(对于FP16类型,即16个元素)。 设计原则:切分出的TileLength必须向下取整,满足32字节对齐约束。
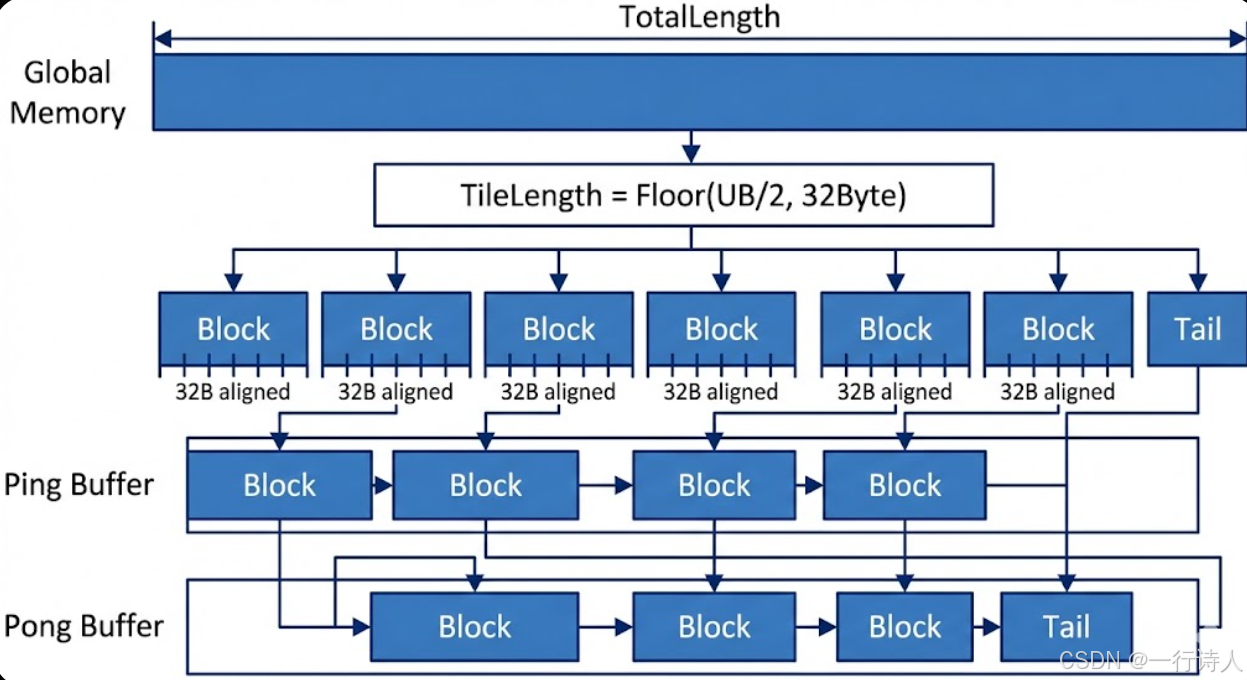
二、 泛化Tiling算法推导
一个鲁棒的Tiling算法需要根据输入数据的总长度(TotalLength)和硬件资源,动态计算出三个关键参数:
-
BlockDim:参与计算的核数。 -
TileNum:每个核需要处理的分块数量。 -
TileLength:每个分块的数据长度。
2.1 算法流程
步骤 1:计算每个核的工作负载 为了充分利用多核并发,首先将总数据量均匀分配到尽可能多的AI Core上。
$$\text{CoreDataNum} = \frac{\text{TotalLength}}{\text{BlockDim}}$$
(注:需处理不能整除的情况,通常采用向上取整或让前几个核多处理一个数据块的策略)
步骤 2:计算UB允许的最大Tile容量 根据数据类型大小(sizeof(T)),计算UB一半空间能容纳的最大元素个数,并执行32字节对齐。
$$\text{MaxElements} = \frac{\text{UbSize}}{2 \times \text{sizeof(T)}}$$$$\text{TileLength} = \lfloor \frac{\text{MaxElements}}{16} \rfloor \times 16 \quad (\text{针对FP16})$$
步骤 3:计算切分数量与尾块处理 根据单核负载和Tile容量,计算循环次数。
$$\text{TileNum} = \lceil \frac{\text{CoreDataNum}}{\text{TileLength}} \rceil$$$$\text{LastTileLength} = \text{CoreDataNum} \pmod{\text{TileLength}}$$
若 LastTileLength 为0,则说明恰好整除,最后一块长度等于 TileLength。
三、 Host侧Tiling代码实现
以下代码展示了如何在 op_host 侧实现上述算法。该实现具备通用性,适用于大多数Element-wise类的Vector算子。
#include "add_custom_tiling.h"
#include "register/op_def_registry.h"
#include "tiling/platform/platform_ascendc.h"
namespace optiling {
const uint32_t TILE_ALIGN = 32; // 32字节对齐约束
static ge::graphStatus TilingFunc(gert::TilingContext* context) {
AddCustomTilingData tiling;
// 1. 获取输入Shape与总数据量
// 实际生产中应处理多维Shape转一维的逻辑
const gert::StorageShape* shape = context->GetInputShape(0);
uint32_t totalLength = shape->GetStorageShape().GetShapeSize();
uint32_t sizeofDataType = 2; // 假设数据类型为FP16 (2 Bytes)
// 2. 获取硬件平台UB信息
auto platformInfo = context->GetPlatformInfo();
auto ascendcPlatform = platform_ascendc::PlatformAscendC(platformInfo);
uint32_t ubSize;
ascendcPlatform.GetCoreMemSize(platform_ascendc::CoreMemType::UB, ubSize);
// 3. 确定多核并行策略 (BlockDim)
// 获取硬件可用的最大AI Core数量
uint32_t totalCoreNum = ascendcPlatform.GetCoreNumAic();
// 简单的负载均衡策略:如果数据量较小,不需要启动所有核
// 此处为简化示例,设定固定使用8核,实际应根据 totalLength 动态计算
uint32_t blockDim = 8;
context->SetBlockDim(blockDim);
// 计算单核数据量 (假设能整除,实际需处理余数分配)
uint32_t coreLength = totalLength / blockDim;
// 4. 计算单核内的Tiling策略
// 预留少量UB空间给系统使用,剩余空间用于Double Buffer
uint32_t availableUb = ubSize - 1024; // 预留1KB
uint32_t ubHalf = availableUb / 2;
// 计算满足32字节对齐的最大元素个数
// 32字节 / 2字节 = 16个元素
uint32_t alignElements = TILE_ALIGN / sizeofDataType;
uint32_t maxTileLength = (ubHalf / TILE_ALIGN) * alignElements;
// 计算TileNum和尾块
uint32_t tileNum = 0;
uint32_t lastTileLength = 0;
if (coreLength <= maxTileLength) {
// 数据量小于半个UB,无需切分
tileNum = 1;
maxTileLength = coreLength;
lastTileLength = coreLength;
} else {
tileNum = coreLength / maxTileLength;
lastTileLength = coreLength % maxTileLength;
if (lastTileLength > 0) {
tileNum++;
} else {
lastTileLength = maxTileLength; // 恰好整除
}
}
// 5. 序列化Tiling参数
tiling.set_totalLength(coreLength); // 当前核负责的总长度
tiling.set_tileNum(tileNum); // 切分块数
tiling.set_tileLength(maxTileLength); // 标准块长度
tiling.set_lastTileLength(lastTileLength); // 尾块长度
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
return ge::GRAPH_SUCCESS;
}
} // namespace optiling
四、 Kernel侧逻辑适配
Host侧计算出的策略通过 TilingData 结构体传递给Kernel。Kernel侧的实现应专注于执行逻辑,严格按照 tileNum 进行循环。
// op_kernel/add_custom.cpp
__aicore__ inline void Process() {
// 循环处理每一个Tile
for (int32_t i = 0; i < tileNum; i++) {
// 动态判断当前块的长度
// 如果是最后一块 (i == tileNum - 1),使用 lastTileLength
// 否则使用标准的 tileLength
uint32_t currentTileLength = (i == tileNum - 1) ? lastTileLength : tileLength;
// 调用流水线接口
CopyIn(i, currentTileLength);
Compute(i, currentTileLength);
CopyOut(i, currentTileLength);
}
}
关键注意事项: 在 CopyIn 和 CopyOut 阶段计算Global Memory偏移地址(Offset)时,必须始终使用标准的 tileLength 进行步进,而不能使用 currentTileLength。
// 错误示例:
// offset = i * currentTileLength; // 错误!会导致地址计算错误
// 正确示例:
auto offset = i * tileLength;
DataCopy(xLocal, xGm[offset], currentTileLength);
五、 总结
泛化Tiling策略是Ascend C算子走向商用的必经之路。通过合理的算法设计,我们可以确保算子在不同硬件配置和不同输入规模下,始终保持高效、稳定的运行。
核心要点回顾:
-
硬件感知:动态获取Core数量和UB大小,而非硬编码。
-
严格对齐:始终保证
TileLength满足32字节对齐,防止DMA搬运异常。 -
边界处理:精确计算
LastTileLength,确保数据不丢不重。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)