
深度解析华为 CANN 单算子调用:从原理到实战的完整指南
在越来越多的 AI 应用落地过程中,开发者会发现一个共同趋势:实际工程往往不仅包含模型推理,还涉及大量独立的数学运算、数据转换、图像处理等前后处理逻辑。如果这些部分也能直接利用昇腾 AI 处理器的算力,那么整体系统的性能才能真正被完全释放。
深度解析华为 CANN 单算子调用:从原理到实战的完整指南
在越来越多的 AI 应用落地过程中,开发者会发现一个共同趋势:实际工程往往不仅包含模型推理,还涉及大量独立的数学运算、数据转换、图像处理等前后处理逻辑。如果这些部分也能直接利用昇腾 AI 处理器的算力,那么整体系统的性能才能真正被完全释放。
很多开发者误以为使用昇腾算力就必须构建完整的模型图并通过推理框架执行,而事实上 **CANN 同样支持“单算子调用”**的轻量级模式,只需要编译一个算子即可独立执行,不依赖模型构建与训练流程。
本文将从使用场景、技术架构、开发流程、关键接口、动态 Shape 处理、Handle 高效执行机制等多个角度,系统性解析 CANN 单算子调用的内部逻辑与工程实践,帮助你从零掌握这一必备能力。
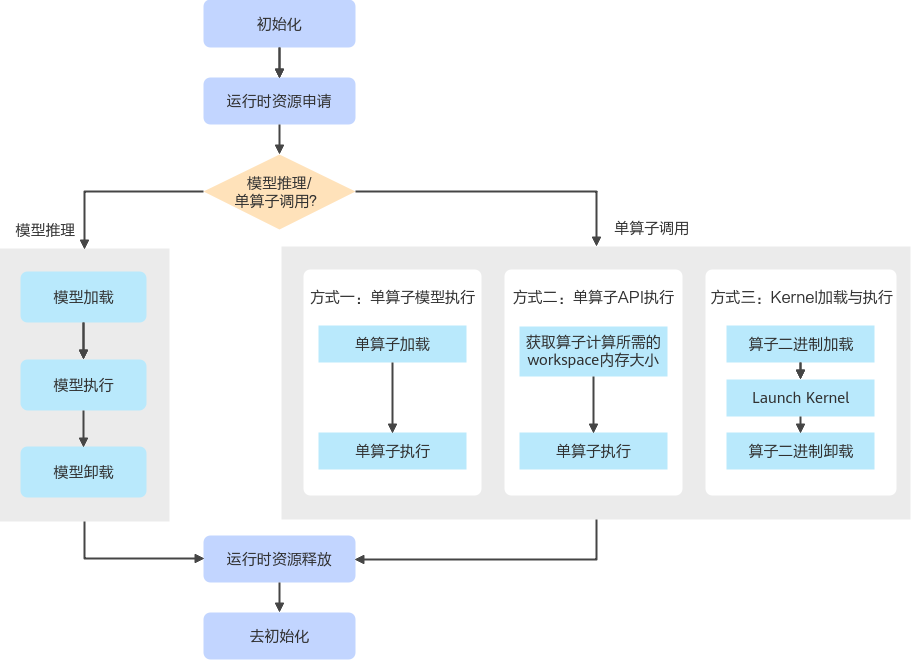
一、为什么需要单算子调用?
在真实的 AI 系统里,很多过程并不适合通过模型推理来解决:
- 纯数学运算(如 GEMM、矩阵加减、归一化)
- 数据预处理/后处理(如格式转换、数据类型 Cast)
- 自定义算子原型验证
- 需要反复执行某个算子的小型 pipeline
这类任务如果强行构建成模型,不但使用成本高,性能上也不划算;而使用 CPU 或 GPU 又无法最大化利用昇腾侧算力。
因此 CANN 提供了 pyacl 单算子执行接口:
你只需准备好算子描述文件和 .om 文件,就能直接把算子的输入数据送到昇腾 Device 上执行。
这让昇腾不仅是 AI 推理芯片,也成为可编程的高性能计算加速器。
二、单算子调用 vs 模型推理:相似与不同
在 API 层面,两者共享一些共性,也有关键差异。
共同点:
- 都需要执行 Runtime 初始化与最终销毁
- 都涉及 Device 端内存申请与释放
- 都需要 Host ↔ Device 数据传输
- 都有“加载 → 执行”的基本流程
不同点:
- 单算子调用“加载的不是模型图”,而是一个“算子模型文件(.om)”
- 模型推理需要执行模型卸载;单算子不需要
- 单算子更轻量,用于高频小运算更高效
单算子执行本质上是将 算子封装成单独可运行的 kernel,然后通过 Runtime 直接调度运行,因此整个链路更短。
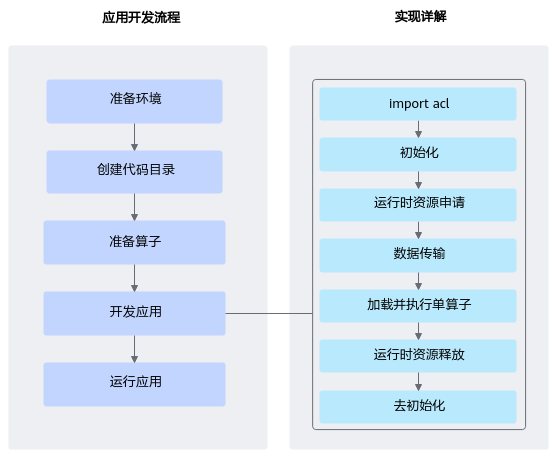
三、单算子调用的整体开发流程
下面从工程角度重建一个标准的单算子执行流程。
环境准备 → 构造算子描述文件 → ATC 编译为 .om → pyacl 加载并执行算子 → 输出结果
流程简洁,但背后涉及多个关键细节。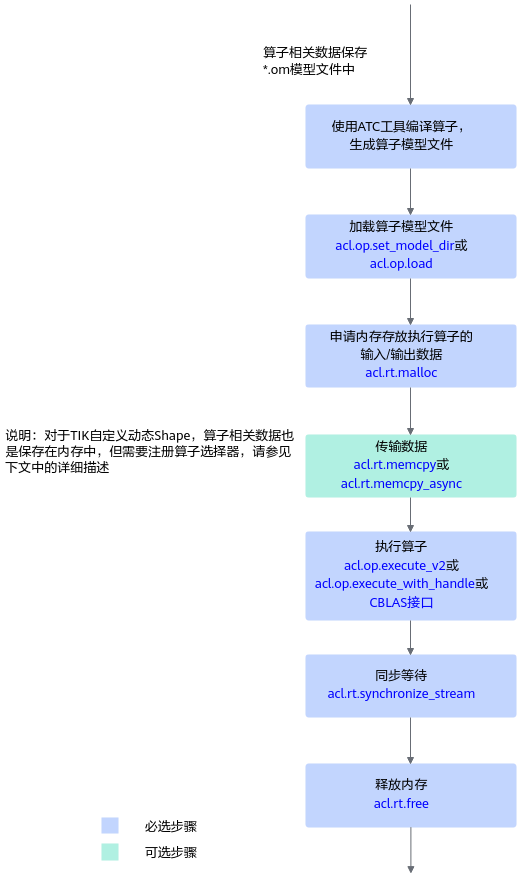
1. 环境准备
需要安装:
- Ascend 设备驱动
- CANN Toolkit
- Python pyacl 库
- ATC 模型转换工具
环境准备中的版本要求需与硬件匹配,否则将直接影响 ATC 编译与 pyacl 执行。
2. 创建代码工程目录
建议结构:
project/
│── op_desc.json
│── run_op.py
│── data/
│ ├── input.npy
│ └── output.npy
保持算子描述文件与程序文件分离,方便后续扩展。
3. 准备算子描述文件(*.json)
这是单算子调用的核心,它描述了:
- 输入/输出 tensor 的 shape、dtype
- 算子的属性(如 transpose、axis、mode 等)
- 算子类型(如 “GEMM”, “Cast”, “AddN”…)
示例结构类似:
{
"op": "Cast",
"input_desc": [...],
"output_desc": [...],
"attr": { "dst_type": "float16" }
}
描述文件最终由 ATC 编译成一个可执行 .om 文件。
4. 使用 ATC 编译算子
典型命令:
atc --singleop=op_desc.json --soc_version=Ascend310B4 --output=cast_op
最终得到 cast_op.om。
5. 开发应用逻辑(pyacl 执行算子)
这一部分是本文的重点,下节将展开细讲。
四、接口调用流程深度解析
单算子调用的底层流程本质上是:
初始化 Runtime → 加载算子模型 → 准备输入 → 执行算子 → 获取输出 → 清理资源
我们按顺序讲解每个关键接口及其背后的机制。
1. 加载算子模型文件
pyacl 提供两种方式:
方式 A:从目录加载
acl.op.set_model_dir("./op_models")
适用于多个 .om 文件集中管理。
方式 B:从内存加载
acl.op.load(op_bytes)
你需要自行读取 .om 文件并管理内存。
两种方式最终都会把算子模型加载到 Device 内部用于匹配和执行。
2. 分配 Device 内存
dev_ptr = acl.rt.malloc(size, ACL_MEM_MALLOC_NORMAL_ONLY)
所有算子输入、输出都必须放在 Device 内存,这点与模型推理一致。
如果输入数据来自 Host,需要:
acl.rt.memcpy(dev_ptr, size, host_ptr, size, ACL_MEMCPY_HOST_TO_DEVICE)
3. 动态 Shape:推导输出 Shape(可选)
对于静态 Shape 算子你可以直接指定输出 Tensor 大小,但对于动态 Shape 算子,你必须:
- 调用
acl.op.infer_shape - 根据推导结果构造输出 Tensor 描述
- 申请足够的 Device 内存
示例调用链:
num_dims = acl.get_tensor_desc_num_dims(desc)
dims = acl.get_tensor_desc_dim_v2(desc, idx)
range = acl.get_tensor_desc_dim_range(desc, idx)
这是动态算子最容易踩坑的部分,尤其是输出空间不足会直接导致运行失败。
4. 执行算子:Handle 模式 vs 非 Handle 模式
CANN 提供两套执行方式。
方式 A:非 Handle(每次执行均匹配算子模型)
常用接口:
- 封装算子:
acl.blas.gemm_ex,acl.op.cast - 通用执行:
acl.op.execute_v2
优点:简单
缺点:每次执行都需匹配算子模型 → 有额外开销
方式 B:Handle(适合高频执行)
执行流程:
-
创建算子 Handle
handle = acl.op.create_handle(op_name, ...) -
执行算子
acl.op.execute_with_handle(handle, inputs, outputs) -
用完后销毁
acl.op.destroy_handle(handle)
Handle 的本质:内部缓存算子模型与属性的匹配结果
→ 避免每次重复解析 → 性能显著提升。
尤其在高频场景(如循环执行 GEMM)下,Handle 模式能带来明显收益。
5. 同步流并获取结果
算子执行是异步的,必须通过:
acl.rt.synchronize_stream(stream)
保证执行完成后再读取结果。
回传 Host:
acl.rt.memcpy(host_ptr, size, dev_ptr, size, ACL_MEMCPY_DEVICE_TO_HOST)
否则可能出现“读取到未完成数据”的问题。
6. 资源释放
包括:
acl.rt.free释放 Device 内存acl.op.unload(若使用 load 方式)acl.finalize清理 Runtime
资源清理不彻底会导致 Device 显存泄漏。
五、一个完整的单算子执行示例(Python)
下面是经过重写的示例(非文档原代码),展示从加载到执行的完整过程:
import acl
import numpy as np
acl.init()
device_id = 0
acl.rt.set_device(device_id)
context, _ = acl.rt.create_context(device_id)
stream, _ = acl.rt.create_stream()
# 加载单算子模型文件
acl.op.set_model_dir("./op_models")
# 准备输入数据
data = np.ones((4, 4), dtype=np.float32)
input_size = data.nbytes
dev_in, _ = acl.rt.malloc(input_size)
acl.rt.memcpy(dev_in, input_size, data.ctypes.data, input_size,
acl.ACL_MEMCPY_HOST_TO_DEVICE)
# 创建输出空间
dev_out, _ = acl.rt.malloc(input_size)
# 执行 Cast 算子(示例)
desc_in = acl.op.create_tensor_desc(acl.ACL_FLOAT, (4, 4))
desc_out = acl.op.create_tensor_desc(acl.ACL_FLOAT16, (4, 4))
acl.op.cast(desc_in, dev_in, desc_out, dev_out)
# 等待执行完成
acl.rt.synchronize_stream(stream)
# 回传结果
host_out = np.empty((4, 4), dtype=np.float16)
acl.rt.memcpy(host_out.ctypes.data, host_out.nbytes, dev_out, host_out.nbytes,
acl.ACL_MEMCPY_DEVICE_TO_HOST)
print(host_out)
# 清理资源
acl.rt.free(dev_in)
acl.rt.free(dev_out)
acl.finalize()
六、常见问题与经验总结
1. 为什么执行失败?
大概率来自:
- Device 内存不足
- 输出 Tensor 大小设置错误(尤其动态 Shape)
- om 文件编译参数与设备版本不一致
- 没有同步 stream 就读取数据
2. 动态 Shape 输出空间如何预估?
建议:
- 使用 infer_shape 接口
- 给输出至少预留略大于理论值的空间
- 避免 runtime size mismatch
3. Handle 是否值得使用?
只要算子会被执行多次,强烈建议使用 Handle,尤其是 GEMM、Conv 等大计算量算子。
七、总结:单算子调用让昇腾更像一块可编程计算加速器
CANN 的单算子调用机制让开发者无需构建模型,也能直接调用昇腾的底层算力,对于:
- 算子验证
- 轻量级前后处理
- 小规模数学运算
- 自定义算子开发测试
- 高性能 pipeline 搭建
都有极大价值。
它的核心优势在于:
- 更轻量,不依赖模型图
- 使用灵活,工程集成简单
- 支持自定义算子验证
- 性能可通过 Handle 模式进一步压榨
掌握这一能力,你将不仅能跑模型,还能构建真正的 “异构加速”应用,让昇腾芯片的计算潜力得到最大化释放。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)