
深入解析华为CANN算子开发-从TensorFlow框架到昇腾AI执行(训练营深度实战篇)
在人工智能加速器的开发实践中,算子(Operator)是连接高层框架与底层硬件的关键纽带。华为昇腾AI处理器通过CANN(Compute Architecture for Neural Networks)提供了高性能算子开发框架,使开发者能够将主流深度学习框架如TensorFlow的算子映射到硬件上执行,从而充分发挥昇腾AI算力。本篇文章将从算子开发流程、框架适配、插件开发到测试验证,系统解析CA
深入解析华为CANN算子开发-从TensorFlow框架到昇腾AI执行(训练营深度实战篇)
在人工智能加速器的开发实践中,算子(Operator)是连接高层框架与底层硬件的关键纽带。华为昇腾AI处理器通过CANN(Compute Architecture for Neural Networks)提供了高性能算子开发框架,使开发者能够将主流深度学习框架如TensorFlow的算子映射到硬件上执行,从而充分发挥昇腾AI算力。本篇文章将从算子开发流程、框架适配、插件开发到测试验证,系统解析CANN算子的开发实践,帮助读者理解完整技术路径。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
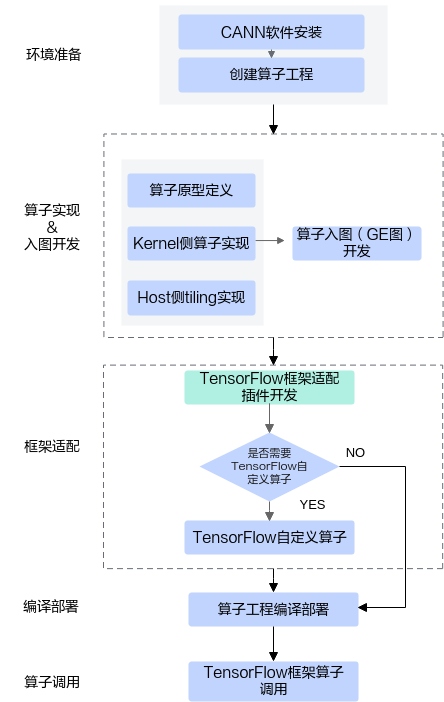
一、算子开发流程概览
将TensorFlow算子映射到CANN算子,主要包括以下几个环节:
-
环境准备
需要确保CANN软件环境和开发工具安装完备,同时确认AI处理器可用。 -
算子工程创建
使用msOpGen工具创建算子工程时,通过framework=tf参数指定框架为TensorFlow。工具将自动生成适配代码和工程目录结构。例如,自定义CANN算子AddCustom的生成命令如下:${INSTALL_DIR}/python/site-packages/bin/msopgen gen -i $HOME/sample/add_custom.json -f tf -c ai_core-<soc_version> -lan cpp -out $HOME/sample/AddCustom -
算子实现
算子实现分为两个层面:- Kernel层:在AI处理器上执行实际计算,调用CANN提供的Tiling API完成高效内存布局和算子分块操作。
- Host层:提供Tiling参数配置接口及辅助功能,保证Kernel的输入输出匹配。
-
算子入图开发
在GE图(Graph Engine)中集成算子时,需要实现Shape推导和输入输出映射,确保算子在构建计算图时自动完成数据匹配。 -
框架适配插件开发
创建算子后,需实现TensorFlow框架适配插件,用于将TensorFlow算子调用映射到CANN算子执行。 -
编译部署
通过算子工程的编译脚本生成算子动态库(.so)或算子包,用于在训练或推理中加载。 -
TensorFlow算子调用验证
编写测试脚本,将TensorFlow原生算子或自定义算子调用映射到CANN算子,验证AI处理器上执行结果与CPU端的参考结果一致性。
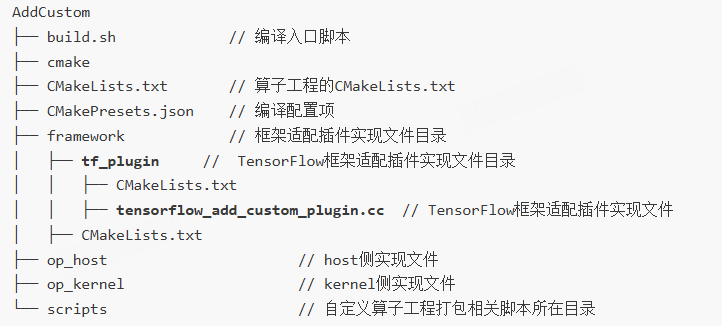
二、TensorFlow算子适配插件开发
CANN算子工程生成后,通常包含一个framework/tf_plugin目录,用于存放TensorFlow适配插件。插件的核心任务是注册自定义算子与原生算子的映射关系,并实现参数解析回调。以AddCustom为例:
#include "register/register.h"
namespace domi {
REGISTER_CUSTOM_OP("AddCustom")
.FrameworkType(TENSORFLOW)
.OriginOpType("AddCustom")
.ParseParamsByOperatorFn(AutoMappingByOpFn);
}
其中:
REGISTER_CUSTOM_OP:注册自定义算子,保证OpType与CANN原型一致。FrameworkType(TENSORFLOW):表明源算子来自TensorFlow。OriginOpType:指定TensorFlow中原始算子名。ParseParamsByOperatorFn:用于解析TensorFlow算子参数并映射到CANN算子。
当TensorFlow算子与CANN算子原型不完全一致时,需要通过ParseOpToGraphFn回调函数进行可选输入映射和参数调整,例如FlashAttentionScore算子:
REGISTER_CUSTOM_OP("FlashAttentionScore")
.FrameworkType(TENSORFLOW)
.OriginOpType({"FlashAttentionScore"})
.ParseParamsByOperatorFn(FlashAttentionScoreMapping)
.ParseOpToGraphFn(AddOptionalPlaceholderForFA);
三、TensorFlow算子映射实践
1. 映射到TensorFlow原生算子
以AddCustom映射到TensorFlow内置Add算子为例,只需修改插件中的OriginOpType即可完成映射。测试时,通过构造TensorFlow单算子网络,在AI处理器上执行,并与CPU端结果进行对比:
import tensorflow as tf
import numpy as np
from npu_bridge.estimator import npu_ops
x_data = np.random.uniform(-2, 2, size=(8, 2048)).astype(np.float16)
y_data = np.random.uniform(-2, 2, size=(8, 2048)).astype(np.float16)
x = tf.compat.v1.placeholder(tf.float16, shape=(8, 2048))
y = tf.compat.v1.placeholder(tf.float16, shape=(8, 2048))
out = tf.math.add(x, y)
通过Session配置选择在AI Core或CPU上运行,比较输出精度:
cmp_result = np.allclose(result_ai_core, result_cpu, atol=0.001, rtol=0.001)
2. 自定义算子映射
自定义算子如AddCustom需要在TensorFlow注册原型:
REGISTER_OP("AddCustom")
.Input("x: T")
.Input("y: T")
.Output("z: T")
.Attr("T: {half}")
.SetShapeFn(shape_inference::BroadcastBinaryOpShapeFn);
并实现CPU Kernel以保证TensorFlow计算图构建不报错,随后通过load_op_library加载.so动态库,实现自定义算子调用。
四、可选输入和动态输入算子处理
TensorFlow算子原型不支持可选输入,CANN提供了插件回调函数实现可选输入映射。以FlashAttentionScore为例:
-
通过ParseParamsByOperatorFn注册属性映射
将TensorFlow算子属性映射到中间算子,保证类型和默认值一致。 -
通过ParseOpToGraphFn注册输入映射
将动态或可选输入插入到Graph中,调整连边关系,例如real_shift、drop_mask等输入。 -
TensorFlow调用封装
在Python端封装函数,将外部未使能的可选输入传入空列表:
def create_optional_input_list(input):
return [input] if input is not None else []
flash_result = tfOpLib.flash_attention_score(
query=query, key=key, value=value,
real_shift=create_optional_input_list(real_shift),
drop_mask=create_optional_input_list(drop_mask),
)
五、总结与实践要点
CANN算子开发流程完整覆盖了从TensorFlow框架算子到昇腾AI执行的全过程。关键要点包括:
- 充分利用
msOpGen生成算子工程,保证结构规范。 - 核心Kernel层实现结合Tiling API,实现高性能执行。
- 插件开发不仅实现参数映射,还需处理可选和动态输入。
- 测试阶段需在CPU端和AI Core端对比输出结果,保证数值一致性。
通过这一流程,开发者可以高效地将TensorFlow算子或自定义算子移植到昇腾AI平台,实现高性能推理与训练,为AI应用提供坚实的算子基础。



作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)