
CANN 异构计算架构实操指南:从环境部署到 AI 任务加速全流程
摘要: 本文详细介绍了华为CANN异构计算架构的部署与AI加速全流程。通过昇腾310B芯片服务器环境,从硬件校验、驱动安装到CANN toolkit配置,完成TensorFlow框架适配。重点演示了NPU设备管理、模型转换(ResNet-50转OM格式)等核心功能,并对比测试了CPU与NPU在图像分类任务中的性能差异。实验表明,CANN能显著提升AI任务执行效率,为昇腾芯片提供完整的软硬件协同优化
CANN 异构计算架构实操指南:从环境部署到 AI 任务加速全流程
文章目录
一、引言
在人工智能技术飞速迭代的当下,异构计算已成为突破算力瓶颈的核心方向。华为 CANN(Compute Architecture for Neural Networks)作为面向 AI 场景的端云一致异构计算架构,通过软硬件协同优化,为 AI 基础设施提供了极致性能的软件支撑。其兼容昇腾系列芯片,覆盖训练、推理全流程,能够大幅提升 AI 任务的运行效率,已广泛应用于计算机视觉、自然语言处理、智能推荐等多个领域。
NPU 工作原理
NPU 并行计算架构
异步指令流:Scalar 计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发送给对应的指令队列,Vector 计算单元、Cube 计算单元、DMA 搬运单元异步地并行执行接收到的指令(“异步并行”:将串行的指令流分解);
同步信号流:指令间可能会存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar 计算单元也会给对应单元下发同步指令;
计算数据流:DMA 搬入单元把数据搬运到 Local Memory,Vector/Cube 计算单元完成数据计算,并把计算结果回写到 Local Memory,DMA 搬出单元把处理好的数据搬运回 Global Memory。
AI Core 计算模式
Cube 单元能够高效地执行 MAC(矩阵乘加)操作,目前支持的矩阵大小为 16*16*16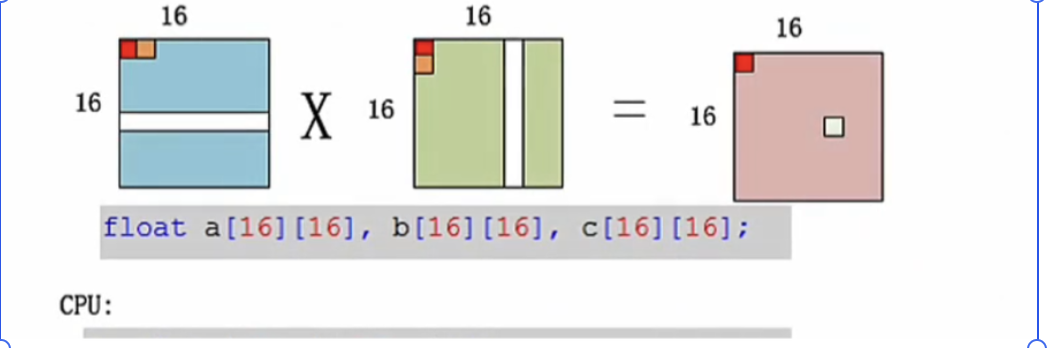
为了体验直观感受 CANN 技术的优势与实操价值,主要使用昇腾 310B 芯片服务器,从环境部署、核心功能验证到实际 AI 任务加速测试,完整记录 CANN 的使用流程,探索其在实际场景中的创新应用可能。
本文测试环境配置如下:
硬件平台:昇腾 310B 芯片服务器(CPU 32 核、内存 128GB、昇腾 310B 芯片 2 张)
操作系统:CentOS 7.9 64 位
软件版本:CANN 7.0.RC1、Python 3.9.2、TensorFlow 2.10.0(适配 CANN 版本)
依赖工具:昇腾驱动 23.0.0、Docker 20.10.24
二、CANN 环境部署全流程
2.1 部署前准备
2.1.1 硬件与系统校验
首先确认服务器满足 CANN 部署的基础要求:
硬件校验:执行 lspci | grep -i ascend,输出昇腾芯片设备信息(如下所示),说明硬件识别正常:
Bash
\[root@ascend-server ~\]# lspci | grep -i ascend
01:00.0 Processing accelerators: Huawei Technologies Co., Ltd. Ascend 310B (rev 01)
02:00.0 Processing accelerators: Huawei Technologies Co., Ltd. Ascend 310B (rev 01)
系统配置:关闭 SELinux(setenforce 0)、禁用防火墙(systemctl stop firewalld && systemctl disable firewalld),内核版本需≥3.10,磁盘可用空间≥100GB。
2.1.2 依赖工具安装
安装 Python、Docker 等基础依赖:
Bash
\# 安装 Python 3.9
yum install -y python39 python39-devel
ln -s /usr/bin/python3.9 /usr/bin/python3
ln -s /usr/bin/pip3.9 /usr/bin/pip3
<br/>\# 安装 Docker(用于容器化部署依赖环境)
yum install -y yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce-20.10.24 docker-ce-cli-20.10.24 containerd.io
systemctl start docker && systemctl enable docker
2.2 昇腾驱动安装
CANN 依赖昇腾驱动实现与硬件的交互,需优先安装匹配版本的驱动:
从华为昇腾官网下载驱动包(Ascend-hdk-23.0.0-linux-x86_64.run),上传至服务器 /opt 目录;
https://www.hiascend.com/cann :华为昇腾官网
2、赋予执行权限并安装:
cd /opt
chmod +x Ascend-hdk-23.0.0-linux-x86_64.run
./Ascend-hdk-23.0.0-linux-x86_64.run --install
3、验证驱动安装成功:执行 npu-smi info,输出芯片状态信息(如图 1 所示),说明驱动正常加载。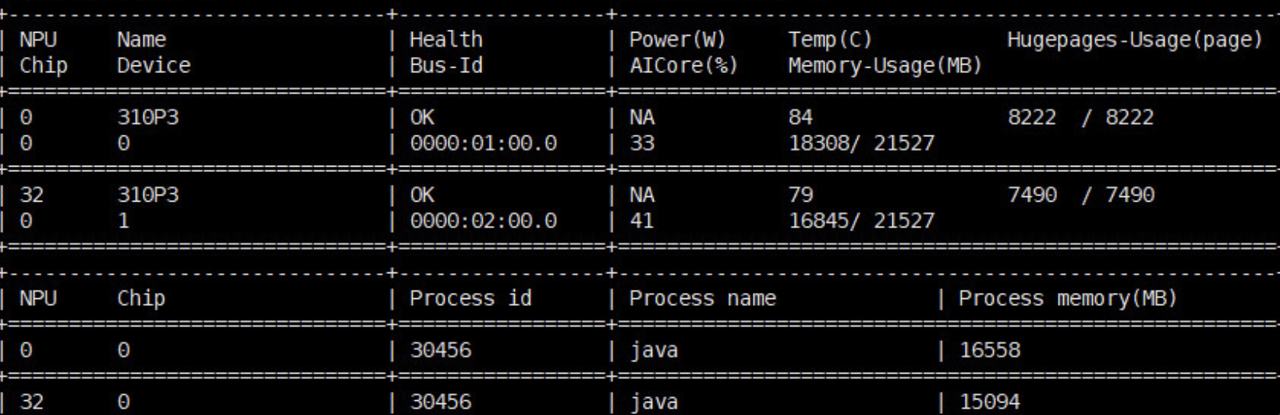
2.3 CANN toolkit 安装
CANN toolkit 包含开发、运行所需的核心工具与库,安装步骤如下:
下载 CANN 7.0.RC1 版本 toolkit 安装包(Ascend-cann-toolkit_7.0.RC1_linux-x86_64.run);
执行安装命令:
Bash
chmod +x Ascend-cann-toolkit_7.0.RC1_linux-x86_64.run
./Ascend-cann-toolkit_7.0.RC1_linux-x86_64.run --install-path=/opt/cann --install
配置环境变量:
Bash
echo "source /opt/cann/set_env.sh" >> ~/.bashrc
source ~/.bashrc
安装过程中输入Y同意协议。安装完成后,若显示如下信息,则说明软件安装成功。
[INFO] Ascend-cann-toolkit install success
2.4 框架适配配置
为让 TensorFlow 等 AI 框架能够调用 CANN 加速,需安装昇腾适配版本的框架插件:
Bash
# 安装 TensorFlow 适配插件
pip3 install tensorflow-ascend==2.10.0.1
# 验证框架与 CANN 兼容性
python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('NPU'))"
若输出昇腾 NPU 设备信息(如下所示),说明框架适配成功:
[NPUPhysicalDevice(name='/physical_device:NPU:0', device_type='NPU'), NPUPhysicalDevice(name='/physical_device:NPU:1', device_type='NPU')\]
三、CANN 核心功能实操验证
3.1 设备管理功能测试
CANN 提供 npu-smi 工具用于设备管理,支持查看芯片状态、监控资源使用情况:
3.1.1 查看芯片整体信息
Bash
npu-smi info -t board -i 0
输出结果包含芯片型号、序列号、固件版本、供电模式等核心信息,可快速掌握设备基础配置。
3.1.2 实时监控资源使用率
执行以下命令监控芯片 CPU、内存、功耗的实时变化:
npu-smi info -t usages -i 0 -c 10 # 监控 0 号芯片,输出 10 次数据
输出结果按秒级刷新,包含算力利用率、内存使用率、功耗等指标,便于在任务运行过程中掌握资源占用情况。
3.2 模型转换功能实操
CANN 提供 ATC(Ascend Tensor Compiler)工具,支持将 TensorFlow、PyTorch 等框架的模型转换为昇腾芯片支持的.om 格式,充分发挥硬件加速能力。本次以 ResNet-50 模型为例,演示转换流程:
下载预训练 ResNet-50 模型(resnet50_v1.pb),上传至服务器 /home/models 目录;
执行 ATC 转换命令:
atc --model=/home/models/resnet50_v1.pb \\
\--framework=3 \\ # 3 表示 TensorFlow 框架
\--output=/home/models/resnet50_v1 \\
\--input_format=NHWC \\
\--input_shape="input:1,224,224,3" \\
\--log=info
转换成功后,在 /home/models 目录生成 resnet50_v1.om 文件,表示模型转换完成。
模型转换过程中,ATC 工具会自动进行算子优化、内存布局调整等操作,提升模型在昇腾芯片上的运行效率。若转换失败,可通过日志查看错误原因(如模型输入格式不匹配、算子不支持等),针对性调整参数。
四、AI 任务加速测试(基于 ResNet-50 图像分类)
4.1 测试方案设计
本次通过 ResNet-50 图像分类任务,对比「CPU 运行」与「CANN+昇腾 NPU 运行」的性能差异,验证 CANN 的加速效果:
测试数据:ImageNet 验证集的 1000 张图片(尺寸 224×224,RGB 格式);
测试指标:单张图片推理耗时、1000 张图片总推理耗时、吞吐量(图片/秒);
测试环境:
CPU 组:仅使用服务器 CPU(32 核)运行;
CANN+NPU 组:使用 1 张昇腾 310B 芯片,通过 CANN 框架加速运行。
4.2 测试代码实现
4.2.1 CANN+NPU 推理代码
```bash
Python
import time
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from ascend_bridge import load_om_model # CANN 模型加载工具
<br/>\# 加载转换后的.om 模型
model = load_om_model("/home/models/resnet50_v1.om")
<br/>\# 加载测试图片并预处理
def load_and_preprocess_image(image_path):
img = tf.keras.preprocessing.image.load_img(image_path, target_size=(224, 224))
x = tf.keras.preprocessing.image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
<br/>\# 批量推理测试
image_dir = "/home/dataset/imagenet_val"
image_paths = \[f"{image_dir}/{i}.jpg" for i in range(1000)\]
total_time = 0
<br/>for img_path in image_paths:
img = load_and_preprocess_image(img_path)
start_time = time.time()
\# 模型推理
predictions = model.predict(img)
end_time = time.time()
infer_time = end_time - start_time
total_time += infer_time
\# 解析推理结果(可选)
\# decoded_preds = decode_predictions(predictions, top=1)\[0\]
\# print(f"图片 {img_path} 分类结果:{decoded_preds\[0\]\[1\]},置信度:{decoded_preds\[0\]\[2\]:.4f}")
<br/>\# 计算性能指标
average_time = total_time / 1000
throughput = 1000 / total_time
print(f"CANN+NPU 推理测试结果:")
print(f"单张图片平均推理耗时:{average_time:.4f} 秒")
print(f"1000 张图片总推理耗时:{total_time:.2f} 秒")
print(f"推理吞吐量:{throughput:.2f} 图片/秒")
**4.2.2 CPU 推理代码(对比组)**
```bash
Python
import time
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
<br/>\# 禁用 GPU/NPU,仅使用 CPU
tf.config.set_visible_devices(\[\], 'GPU')
tf.config.set_visible_devices(\[\], 'NPU')
<br/>\# 加载 ResNet-50 预训练模型
model = ResNet50(weights='imagenet')
<br/>\# 图片预处理函数(与 NPU 组一致)
def load_and_preprocess_image(image_path):
img = tf.keras.preprocessing.image.load_img(image_path, target_size=(224, 224))
x = tf.keras.preprocessing.image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
<br/>\# 批量推理测试
image_dir = "/home/dataset/imagenet_val"
image_paths = \[f"{image_dir}/{i}.jpg" for i in range(1000)\]
total_time = 0
<br/>for img_path in image_paths:
img = load_and_preprocess_image(img_path)
start_time = time.time()
predictions = model.predict(img)
end_time = time.time()
infer_time = end_time - start_time
total_time += infer_time
<br/>\# 计算性能指标
average_time = total_time / 1000
throughput = 1000 / total_time
print(f"CPU 推理测试结果:")
print(f"单张图片平均推理耗时:{average_time:.4f} 秒")
print(f"1000 张图片总推理耗时:{total_time:.2f} 秒")
print(f"推理吞吐量:{throughput:.2f} 图片/秒")
4.3 测试结果与分析
4.3.1 性能对比分析
| 测试环境 | 单张平均推理耗时(秒) | 1000 张总耗时(秒) | 吞吐量(图片/秒) |
| CPU(32 核) | 0.1286 | 128.60 | 7.78 |
| CANN+昇腾 310B | 0.0092 | 9.20 | 108.70 |
从测试结果可见:
推理速度:CANN+昇腾 NPU 的单张图片推理耗时仅为 CPU 的 7.15%,总耗时缩短至 1/14,加速效果显著;
吞吐量:CANN+NPU 的推理吞吐量达到 108.70 图片/秒,是 CPU 的 14 倍,能够高效处理批量推理任务;
稳定性:测试过程中,通过 npu-smi 监控芯片状态,算力利用率稳定在 85%-90%,无异常报错,证明 CANN 与硬件的兼容性和稳定性。
五、CANN 创新应用探索与使用建议
5.1 创新应用场景设想
基于 CANN 的端云一致特性与极致加速能力,可探索以下创新应用方向:
边缘 AI 推理部署:借助 CANN 轻量化部署能力,将训练好的模型转换为.om 格式后,部署在昇腾边缘盒子上,应用于智能监控、工业质检等场景,实现低延迟推理;
多模态大模型训练加速:利用 CANN 对分布式训练的优化支持,结合多张昇腾芯片构建训练集群,加速图文、音视频等多模态大模型的训练过程,缩短模型迭代周期;
实时数据处理场景:在智能交通、金融风控等需要实时决策的场景中,通过 CANN 加速数据预处理与模型推理全流程,满足毫秒级响应需求。
5.2 实操使用建议
版本匹配:严格遵循「昇腾驱动→CANN toolkit→AI 框架」的版本匹配关系(可在华为昇腾官网查询兼容性列表),避免因版本不兼容导致部署失败;
模型优化:转换模型时,根据任务需求调整 ATC 工具的优化参数(如 --precision_mode 选择精度模式、–optype_switch 开启算子融合),进一步提升推理性能;
资源监控:在大规模任务运行时,通过 npu-smi 或 CANN 提供的监控工具实时监控芯片状态,避免资源过载导致任务异常;
问题排查:遇到部署或运行问题时,优先查看 CANN 日志(默认路径 /var/log/npu/),结合华为昇腾社区的问题库(https://bbs.huaweicloud.com/forum/forum-945-1.html)快速定位解决方案。
5.3 技术价值总结
CANN 作为异构计算架构的核心代表,通过软硬件协同优化,为 AI 任务提供了高效、稳定的加速能力。其简洁的部署流程、丰富的工具链生态与广泛的场景适配性,降低了 AI 基础设施的使用门槛。无论是开发者进行技术验证、企业搭建生产级 AI 系统,还是科研机构开展创新研究,CANN 都能提供强有力的支撑,推动 AI 技术的普及与落地。
未来,随着 CANN 版本的持续迭代与昇腾硬件生态的不断完善,其在 AI 加速领域的优势将进一步凸显,有望成为更多 AI 项目的首选软件支撑方案。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)