
**深度解析昇腾社区(hiascend.com):AI开发者的创新沃土**
昇腾社区(hiascend.com)是华为打造的AI开发者平台,提供昇腾系列AI处理器、异构计算架构CANN、MindSpore框架等核心技术资源。该平台包含硬件文档、开发工具链(如MindStudio)、预训练模型库等,支持从底层算子开发到上层应用部署的全流程。文章通过ACL初始化代码和TBE向量加法示例,展示了如何利用昇腾的计算能力,并演示了MindSpore框架在昇腾硬件上的应用开发流程。该
深度解析昇腾社区(hiascend.com):AI开发者的创新沃土
引言
在人工智能技术飞速发展的今天,昇腾社区(hiascend.com)作为华为昇腾计算产业的官方技术门户,正成为国内AI开发者不可或缺的资源宝库与创新平台。它不仅提供了从硬件驱动、开发工具链到算法模型的全方位技术支持,更构建了一个开放、协作、共享的开发者生态。
本文将带你深入探索昇腾社区的核心价值,并结合实际代码示例,展示如何利用其丰富的资源进行高效AI开发。
一、昇腾社区的核心资源导航
昇腾社区的资源体系主要围绕以下几个核心板块构建:
AI处理器与硬件:提供昇腾Ascend系列AI处理器(如Ascend 910, Ascend 310)的技术文档、硬件规格与开发板资源。
以下是一些与昇腾Ascend系列AI处理器相关的图片:
- Atlas 300T训练卡:基于昇腾910芯片,集成32个达芬奇AI核+16个TaiShan核。**
- Atlas 200I DK A2开发板:集成了昇腾310芯片,内置2个Al core,可支持128位宽的LPDDR4X。 
异构计算架构(CANN):这是昇腾AI生态的核心软件栈,提供了驱动、固件、编程语言和高性能算子库。
以下是一些与异构计算架构CANN相关的图片:
- CANN逻辑架构:

- 昇腾计算架构[__LINK_ICON]:

- CANN总体架构: 
AI框架支持:官方支持MindSpore,并兼容TensorFlow、PyTorch等主流框架。
模型与算法:ModelZoo提供了大量预训练模型,覆盖视觉、自然语言处理等多个领域。
开发者工具:包括MindStudio(全流程开发工具链)、MindX SDK等,极大提升了开发与部署效率。
以下是一些与MindStudio和MindX SDK相关的图片:
- MindX SDK总体结构[__LINK_ICON]:** 
- MindX SDK安装界面[__LINK_ICON]:
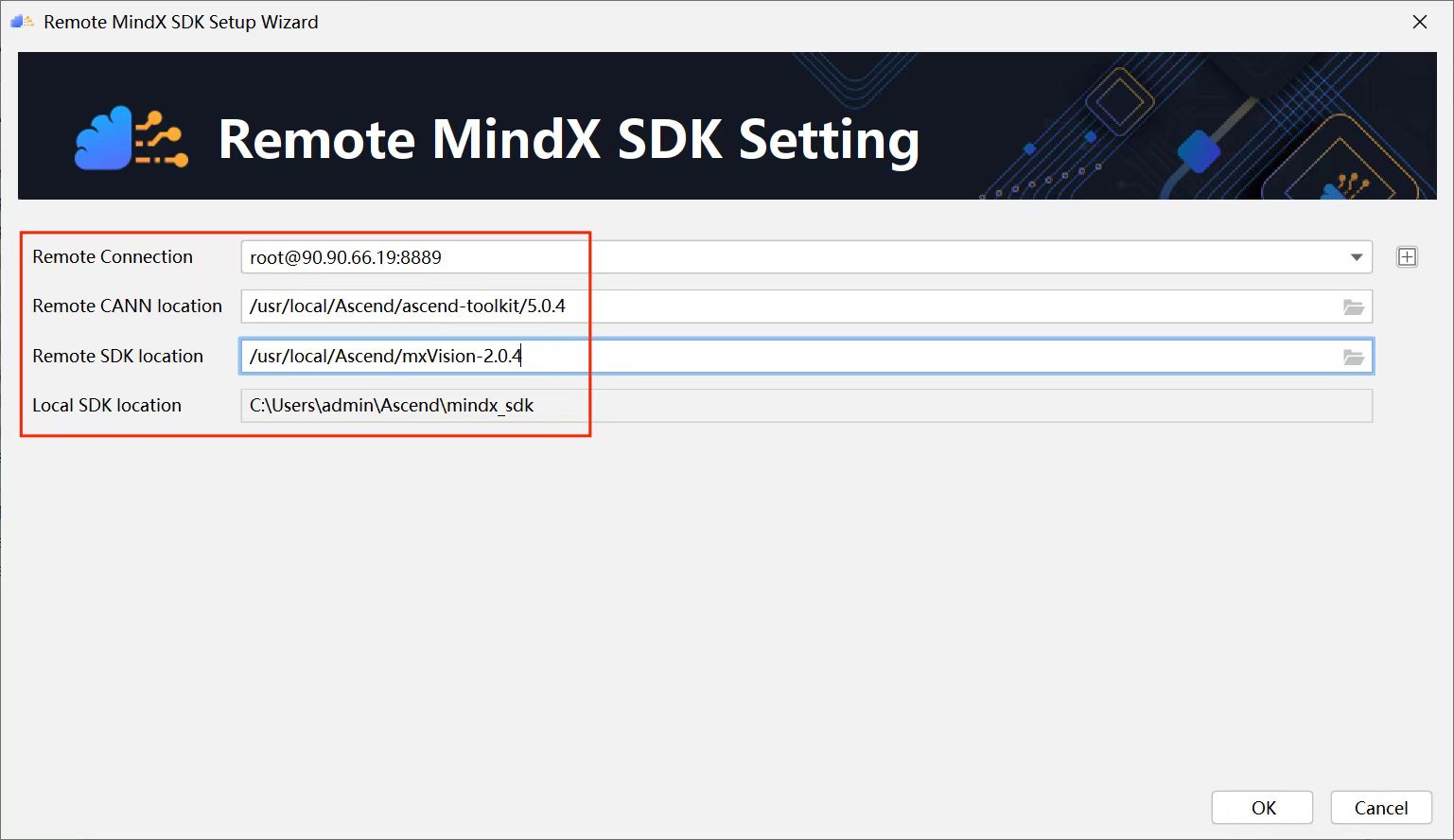
- MindStudio功能框架: 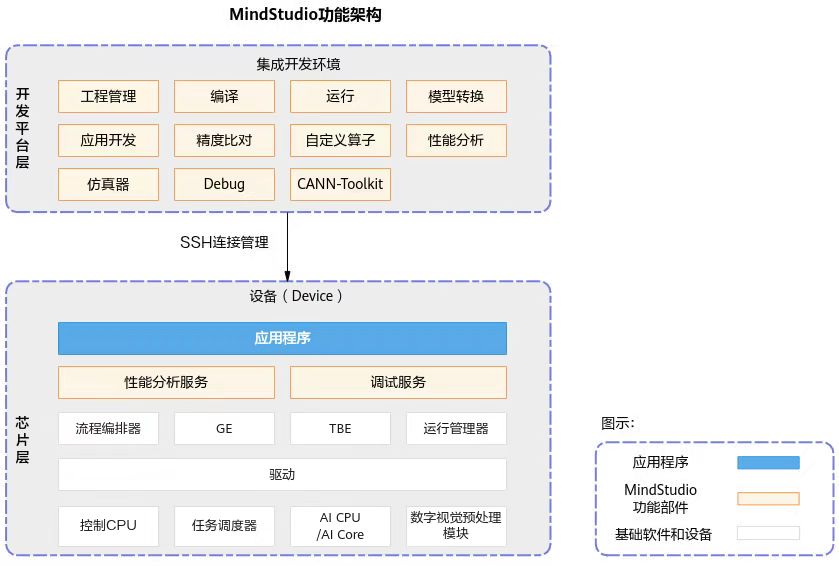
- MindX SDK业务流程相关基础单元[__LINK_ICON]:
二、CANN:昇腾计算的基石
Compute Architecture for Neural Networks (CANN) 是连接上层AI框架与底层昇腾硬件的桥梁。它通过向上提供编程接口,向下屏蔽硬件细节,使开发者能更专注于算法和应用开发。
2.1 使用ACL(Ascend Computing Language)进行开发
ACL是CANN提供的底层C/C++ API,用于实现极致性能的定制化开发。以下是一个简化的ACL初始化和内存分配的代码示例:
代码:
#include <acl/acl.h>
int main() {
// 1. 初始化ACL运行环境
aclInit(nullptr);
// 2. 指定计算设备ID (例如: 0)
int deviceId = 0;
aclError ret = aclrtSetDevice(deviceId);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Failed to set device." << std::endl;
return -1;
}
// 3. 创建Context (上下文)
aclrtContext context;
ret = aclrtCreateContext(&context, deviceId);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Failed to create context." << std::endl;
aclrtResetDevice(deviceId);
aclFinalize();
return -1;
}
// 4. 分配设备内存 (例如: 分配1024字节)
size_t dataSize = 1024;
void *deviceData = nullptr;
ret = aclrtMalloc(&deviceData, dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
std::cerr << "Failed to allocate memory on device." << std::endl;
// 错误处理...
}
// ... 在此处进行计算核心操作 (如Kernel启动) ...
// 5. 释放设备内存
aclrtFree(deviceData);
// 6. 销毁Context并重置设备
aclrtDestroyContext(context);
aclrtResetDevice(deviceId);
// 7. 最终化ACL
aclFinalize();
return 0;
}
2.2 高性能算子开发:Ascend C与TBE
对于算子开发,昇腾提供了两种主要方式:
Ascend C:一种更贴近硬件、追求极致性能的编程语言。
TBE (Tensor Boost Engine):基于Python的DSL(领域特定语言),开发效率更高。
以下是一个使用TBE进行简单向量加法的伪代码框架:
代码:
from tbe import tik
import tbe.common.platform as tbe_platform
假设在此处定义了数据量
data_size = 1024
1. 创建Tik实例,指定运行模式
tik_instance = tik.Tik(tik.Dprofile(“Ascend910”, “Mini”))
2. 定义输入输出数据占位符
input_x = tik_instance.Tensor(“float16”, (data_size,), name=“input_x”, scope=tik.scope_gm)
input_y = tik_instance.Tensor(“float16”, (data_size,), name=“input_y”, scope=tik.scope_gm)
output_z = tik_instance.Tensor(“float16”, (data_size,), name=“output_z”, scope=tik.scope_gm)
3. 定义计算过程 (伪代码,具体实现依赖tik API)
- 将数据从Global Memory (GM) 搬运到Unified Buffer (UB)
- 在UB上执行加法运算
- 将结果从UB搬运回GM
with tik_instance.new_stmt_scope():
# 伪代码:数据分块处理
for i in range(0, data_size, block_length):
# 从GM搬运数据块到UB
data_x_ub = tik_instance.Tensor(“float16”, (block_length,), name=“data_x_ub”, scope=tik.scope_ubuf)
data_y_ub = tik_instance.Tensor(“float16”, (block_length,), name=“data_y_ub”, scope=tik.scope_ubuf)
tik_instance.data_move(data_x_ub, input_x[i], 0, 1, block_length // 16, 0, 0)
tik_instance.data_move(data_y_ub, input_y[i], 0, 1, block_length // 16, 0, 0)
# 执行计算
data_z_ub = data_x_ub + data_y_ub
# 将结果从UB搬运回GM
tik_instance.data_move(output_z[i], data_z_ub, 0, 1, block_length // 16, 0, 0)
4. 构建Kernel
tik_instance.BuildCCE(kernel_name=“vector_add”, inputs=[input_x, input_y], outputs=[output_z])
5. 编译生成可执行文件 (.o) 和信息文件 (.json)
三、MindSpore框架实战
昇腾官方主推的AI框架MindSpore,与昇腾硬件深度结合,能充分发挥硬件性能。下面是一个使用MindSpore在昇腾上进行简单线性回归的示例:
import numpy as np
import mindspore as ms
import mindspore.nn as nn
from mindspore import Tensor, context
1. 设置运行模式为图模式,并指定设备为Ascend
context.set_context(mode=context.GRAPH_MODE, device_target=“Ascend”)
2. 准备模拟数据
np.random.seed(0)
x_train = np.random.randn(100, 1).astype(np.float32)
y_train = 2 * x_train + 1 + 0.1 * np.random.randn(100, 1).astype(np.float32)
3. 定义模型
class LinearNet(nn.Cell):
def init(self):
super(LinearNet, self).init()
self.dense = nn.Dense(1, 1)
def construct(self, x):
return self.dense(x)
model = LinearNet()
4. 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = nn.Momentum(model.trainable_params(), learning_rate=0.01, momentum=0.9)
5. 定义训练过程
def train_step(inputs, targets):
def forward(inputs, targets):
predictions = model(inputs)
loss = loss_fn(predictions, targets)
return loss
grad_fn = ms.value_and_grad(forward, None, optimizer.parameters)
loss, grads = grad_fn(inputs, targets)
optimizer(grads)
return loss
6. 开始训练
epochs = 100
for epoch in range(epochs):
x_tensor = Tensor(x_train)
y_tensor = Tensor(y_train)
loss = train_step(x_tensor, y_tensor)
if epoch % 20 == 0:
print(f"Epoch {epoch}, Loss: {loss.asnumpy()}")
print(“Training finished.”)
四、昇腾社区ModelZoo的便捷使用
昇腾社区的ModelZoo提供了大量经过优化的模型,开发者可以直接下载使用或进行迁移学习。通常,模型会提供详细的README,包含训练、评估和推理的脚本。
例如,下载一个图像分类模型(如ResNet-50)后,其推理脚本可能如下:
代码:
#!/bin/bash
infer.sh
模型文件路径
MODEL_PATH=“./resnet50.om” # .om 是昇腾的离线模型文件
测试图片路径
IMAGE_PATH=“./test_image.jpg”
使用ATC工具转换模型(如果需要从其他框架转换)
atc --model=resnet50.pb --framework=3 --output=resnet50 --soc_version=Ascend910
使用Ascend推理工具(伪命令,具体取决于提供的工具)进行推理
ascend_inference_tool --model $MODEL_PATH --input $IMAGE_PATH --output result.json
echo “Inference completed. Check result.json for predictions.”
结语
昇腾社区(hiascend.com)不仅仅是一个资源下载站,它更是一个赋能AI开发者的强大引擎。通过其核心的CANN软件栈、高效的MindSpore框架、丰富的ModelZoo以及完善的开发者工具链,无论是底层算子开发、上层模型训练还是最终的应用部署,昇腾社区都提供了坚实的技术支撑和广阔的创新空间。
对于渴望在AI领域深耕的开发者而言,深入探索昇腾社区,意味着能够站在一个更高的起点,利用国产化全栈AI技术,加速从创意到产品的转化。拥抱昇腾,就是拥抱一个开放、高效且充满可能性的AI未来。现在就访问 昇腾社区,开启你的高效AI开发之旅吧!
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)