
昇腾CANN HCCL深度解析:构建分布式AI训练的高速通信网道
华为昇腾AI处理器中的HCCL(Huawei Collective Communication Library)是分布式AI训练的核心通信库,向上支持主流AI框架,向下管理硬件资源。HCCL采用软硬件协同设计,具有三大创新:高性能自适应通信算法、硬件级计算通信协同调度以及计算通信并行执行。它支持AllReduce、Broadcast等核心通信原语,并针对不同集群规模提供Ring、H-D_R等优化算
1 引言:AI分布式训练的革命
随着神经网络模型参数规模从亿级迈向万亿级,单卡训练已成为历史,分布式并行训练成为了应对这一挑战的核心技术。在分布式训练中,梯度同步往往是最耗时的瓶颈环节,而集合通信技术正是解决这一瓶颈的关键。
华为昇腾AI处理器打造的CANN(Compute Architecture for Neural Networks) 异构计算架构中,HCCL(Huawei Collective Communication Library) 作为高性能集合通信库,承担着多卡多机间高效数据通信的重任。它如同AI训练集群的"神经系统",将各个计算节点紧密连接,实现高效协同工作。接下来将深入解析HCCL的架构设计、通信原理,并通过实际代码展示其应用方法。
2 HCCL架构全景:软硬件协同设计的典范
HCCL在昇腾软硬自研体系中的位置介于AI框架与硬件之间,向上为PyTorch、TensorFlow、MindSpore等主流框架提供集合通信接口,向下直接管理昇腾AI处理器的通信硬件资源。这种分层设计使得AI框架开发者无需关心底层硬件细节,就能充分利用多机多卡的计算能力。
HCCL的软件架构包含以下几个关键组件:
- 通信域管理:负责集群节点的分组与通信上下文维护
- 通信原语层:实现AllReduce、Broadcast等标准集合通信操作
- 算法调度层:根据网络拓扑、数据量智能选择最优通信算法
- 硬件抽象层:封装HCCS、PCIe、RoCE等底层通信链路差异
2.2 核心特点与创新
HCCL相比其他集合通信库,有几个突出的技术创新点:
- 高性能集合通信算法:HCCL具备全局网络拓扑探测与建模能力,可依据服务器节点内、外的层次化网络结构,智能调度其多元自研通信算法库,形成最优的动态路由策略,以最大化通信带宽与效率。这种自适应能力确保了在不同集群规模和数据量下都能获得接近最优的通信性能。
- 计算通信统一硬化调度:依托专用硬件调度器与底层通信原语,实现了计算与通信任务的硬件级协同调度。该架构从根本上消除了传统软件调度的系统开销,并确保了极致的性能与确定性延迟。这种硬软件协同设计使得通信过程更加稳定可靠。
- 计算通信高性能并发:"归约"类集合通信操作通过随路方式实现,不占用计算资源。这意味着计算和通信可以并行执行,大幅降低总执行时长,实现计算与通信的流水线掩盖。
3 通信原语:分布式训练的基石
集合通信是一个进程组的所有进程都参与的全局通信操作,HCCL支持主流的通信原语,满足各种并行策略的需求。
3.1 核心通信原语详解
- AllReduce:All-Reduce 操作实现了跨节点的数据全局归约与结果同步,确保通信域内所有节点获得完全一致的结果,是维持分布式系统状态一致性的关键。在数据并行训练中,AllReduce用于同步各计算节点上的梯度,确保模型参数的一致性。
- Broadcast:将指定根节点的数据广播到通信域内的所有其他节点。常用于初始化阶段分发模型参数,或处理需要全局一致的数据。
- AllGather:AllGather 操作将通信域内各节点的输入数据,按其全局秩序号进行全局聚合与有序拼接,最终在所有节点生成一个完全一致的全局数据视图。在模型并行场景中,AllGather用于收集分布在各个设备上的部分计算结果。
- ReduceScatter:将所有节点的输入进行归约操作后,按照rank编号均匀分散到各个节点的输出buffer。与AllReduce类似,但结果分布在不同节点上。
- AlltoAll:通信域内的每个节点都向其他所有节点发送数据,同时从所有其他节点接收数据。在混合并行策略中尤为有用,如专家并行(MoE模型)和序列并行。
下面的表格总结了HCCL主要通信原语的特性和典型应用场景: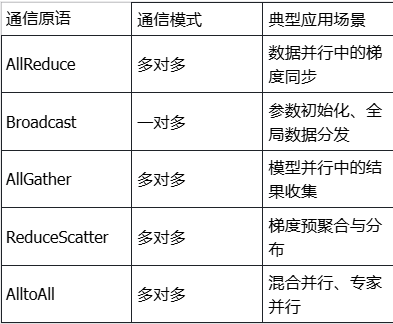
4 通信算法深度解析:适应多样化的集群环境
HCCL提供了多种通信算法,每种算法都有其独特的优势和适用场景。
4.1 基础通信算法
- Ring(环)算法:通信步数线性增长,时延较高;但通信模式固定,鲁棒性强,受网络拥塞影响小。适合通信域内Server个数较少、通信数据量较小 的场景。在非2的整数次幂节点规模下,Ring算法通常是最稳定的选择。
- H-D_R(递归二分和倍增)算法:通信步数少(对数复杂度),时延相对较低,但在非2次幂节点规模下会引入额外的通信量。适合通信域内Server个数是2的整数次幂 且pipeline算法不适用的场景,或Server个数不是2的整数次幂但通信数据量较小的场景。
- NHR(非均衡层次环)算法:通信步数少(对数复杂度),时延相对较低。适合通信域内Server个数较多 且pipeline算法不适用的场景。相比传统Ring算法,在大规模集群中性能优势明显。
- Pipeline(流水线)算法:该通信策略采用层次化聚合,可并发利用节点内与节点间的高速链路,专为处理大规模数据并优化多GPU服务器架构下的通信而设计。通过将数据切块并在不同链路上并行传输,大幅提升带宽利用率。
4.2 进阶算法:细粒度分级流水
HCCL的关键创新在于其细粒度分级流水算法,该算法专为优化大规模分级网络中的通信瓶颈而生,实现了异构链路下的性能最大化。
传统分级算法的问题:
- 带宽浪费:Server间数据传输时,Server内链路处于空闲状态
- 离散数据:数据在传输过程中不连续,需要额外重排或引入发送头开销
细粒度分级流水的解决方案:
以Allgather为例,Server间采用Ring算法,Server内采用Full Mesh算法。该算法通过重构Ring通信的数据依赖,实现了节点内与节点间传输的完全解耦与并行,达成了层次化网络下的最优通信效率。
具体来说,在Ring算法的每一步中,节点同时进行两种操作:
- 按照Ring算法规则继续与相邻节点交换数据
- 将上一步接收到的数据块传输给同Server内的其他节点
这种算法充分利用了数据依赖关系,实现了微观层面的流水线并行,既提高了带宽利用率,又避免了离散数据问题。在理想情况下,当Server内外带宽接近时,随着Server数量增加,性能提升可接近1倍。
5 实战指南:HCCL代码开发详解
5.1 环境配置与初始化
使用HCCL前需要正确安装CANN软件包,并配置集群信息。HCCL支持通过rank table文件或环境变量两种方式配置集群。
# 设置rank table文件路径
export RANK_TABLE_FILE=/path/to/rank_table.json
# 配置Server间通信算法(可选)
export HCCL_ALGO="level0:NA;level1:H-D_R"
5.2 基础开发流程
HCCL提供了C++和Python两种接口,以下以C++接口为例,展示一个完整的AllReduce操作:
#include "hccl/hccl.h"
#include "acl/acl.h"
// 设备资源初始化
ACLCHECK(aclInit(NULL));
// 指定集合通信操作使用的设备
ACLCHECK(aclrtSetDevice(dev_id));
// 创建任务stream
aclrtStream stream;
ACLCHECK(aclrtCreateStream(&stream));
// 获取集群配置文件
char* rank_table_file = getenv("RANK_TABLE_FILE");
// 根据集群配置文件初始化集合通信域
HcclComm hccl_comm;
HCCLCHECK(HcclCommInitClusterInfo(rank_table_file, rank_id, &hccl_comm));
// 申请集合通信操作的内存
ACLCHECK(aclrtMalloc((void**)&sendbuff, malloc_kSize, ACL_MEM_MALLOC_HUGE_FIRST));
ACLCHECK(aclrtMalloc((void**)&recvbuff, malloc_kSize, ACL_MEM_MALLOC_HUGE_FIRST));
// 执行集合通信操作
HCCLCHECK(HcclAllReduce((void *)sendbuff, (void*)recvbuff, count,
(HcclDataType)dtype, (HcclReduceOp)op_type, hccl_comm, stream));
// 等待stream中集合通信任务执行完成
ACLCHECK(aclrtSynchronizeStream(stream));
// 销毁集合通信内存资源
ACLCHECK(aclrtFree(sendbuff));
ACLCHECK(aclrtFree(recvbuff));
// 销毁集合通信域
HCCLCHECK(HcclCommDestroy(hccl_comm));
// 销毁任务流
ACLCHECK(aclrtDestroyStream(stream));
// 重置设备
ACLCHECK(aclrtResetDevice(dev_id));
// 设备去初始化
ACLCHECK(aclFinalize());
开发流程遵循标准的"初始化-执行-销毁"模式:
- 初始化阶段:初始化ACL运行时和HCCL通信域,建立设备间的通信上下文
- 执行阶段:分配设备内存,调用HCCL通信算子,通过Stream异步执行
- 清理阶段:同步等待操作完成,释放内存和通信域资源
5.3 算法选择与性能调优
HCCL默认会根据产品形态、数据量和Server个数自动选择最优算法,但也支持手动调优:
# 全局配置算法类型
export HCCL_ALGO="level0:NA;level1:H-D_R"
# 按算子配置算法类型
export HCCL_ALGO="allreduce=level0:NA;level1:ring/allgather=level0:NA;level1:pipeline"
手动调优在特定场景下可以带来显著性能提升。例如,当发现AllReduce操作在大规模非2次幂集群上性能不佳时,可以显式指定为NHR算法;而对于AlltoAll操作,在数据量较大且需要避免网络"一打多"现象时,pairwise算法可能是更好的选择。
6 性能分析与优化实战
6.1 性能数据采集与分析
HCCL与Ascend Profiler深度集成,可以收集详细的性能数据:
- 时间线视图:显示每个通信算子的开始时间、持续时间和并发关系
- 统计视图:汇总所有通信算子的执行次数、总耗时、平均耗时和最大耗时
- 流水掩盖分析:可视化计算与通信的重叠程度,识别性能瓶颈
通过分析性能数据,可以识别出通信操作中的热点,例如: - 某个AllReduce操作耗时异常长
- 计算与通信重叠不足,存在大量空闲间隙
- 特定rank的通信带宽明显低于其他rank
6.2 重叠优化与带宽提升
提高计算与通信的重叠度是优化分布式训练性能的关键策略。以下是一些实用技巧:
- 梯度融合:将多个小梯度张量合并为一个大张量进行AllReduce,减少通信次数
- 计算通信交错:在模型合适的位置插入通信操作,使其与计算重叠
- 使用异步API:利用HCCL的异步特性,使通信在后台执行
7 总结与展望
HCCL作为昇腾AI软硬自研生态中的关键通信组件,通过高性能的通信算法、软硬自研的调度机制和精细化的性能优化工具,为大规模分布式训练提供了坚实的通信基础。
AI模型复杂度的持续攀升,使得集合通信的效能日益成为整体性能的核心瓶颈。HCCL通过实现如细粒度分级流水等先行性创新,正致力于突破此瓶颈,为大规模分布式训练的持续演进提供核心驱动力,未来还将继续探索更高效的通信拓扑、更智能的算法选择策略,以及更深入的计算通信融合技术,为下一代万亿参数级别的AI模型提供可扩展的通信能力。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)