
CANN 8.0“CT机”:我如何用 Profiler 给 MindSpore 模型“看病”调优
本文介绍了如何利用CANN 8.0的Profiler工具优化MindSpore模型在昇腾910B上的性能。通过一个故意设计低效的InefficientNet模型(包含1000次AddN算子循环),作者展示了Profiler的完整使用流程:从环境检查、代码植入Profiler、生成性能数据到分析报告。实践表明,在Graph模式下使用Python循环会导致大量Host-Device交互,使平均执行时间
CANN 8.0“CT机”:我如何用 Profiler 给 MindSpore 模型“看病”调优
个人主页:chian-ocean
专栏

前言:
都说 NPU 910B 算力强,但为什么我的 MindSpore 模型跑起来还是慢吞吞?性能瓶颈到底在哪?本文将全程实操,演示如何使用 CANN 8.0 配套的 Profiler 工具,像一台“CT机”一样给代码“拍片子”,揪出性能“病灶”,并完成优化。本文环境为 NPU 910B、MindSpore 2.3.0 及 CANN 8.0。
在 AI 开发中,我们经常遇到一个尴尬问题:明明有强悍的硬件(比如昇腾 910B),但模型训练/推理的速度就是上不去。代码的性能就像一个“黑盒”,我们只能靠猜。
“是不是数据预处理慢了?”
“是不是某个算子写得烂?”
“还是NPU压根就没使劲,在‘摸鱼’?”
猜是没用的。CANN 8.0 提供了强大的工具链,把“猜”变成了“看”。今天我们就来实战体验它的“法宝”之一 —— Profiler,看看它是如何帮我们把黑盒变透明,真正“简化AI开发”的。
环境准备与“病患”代码
在gitcode上进行测试,nodebook上(直达链接: https://gitcode.com/dashboard)
首先,亮出我们的评测环境。
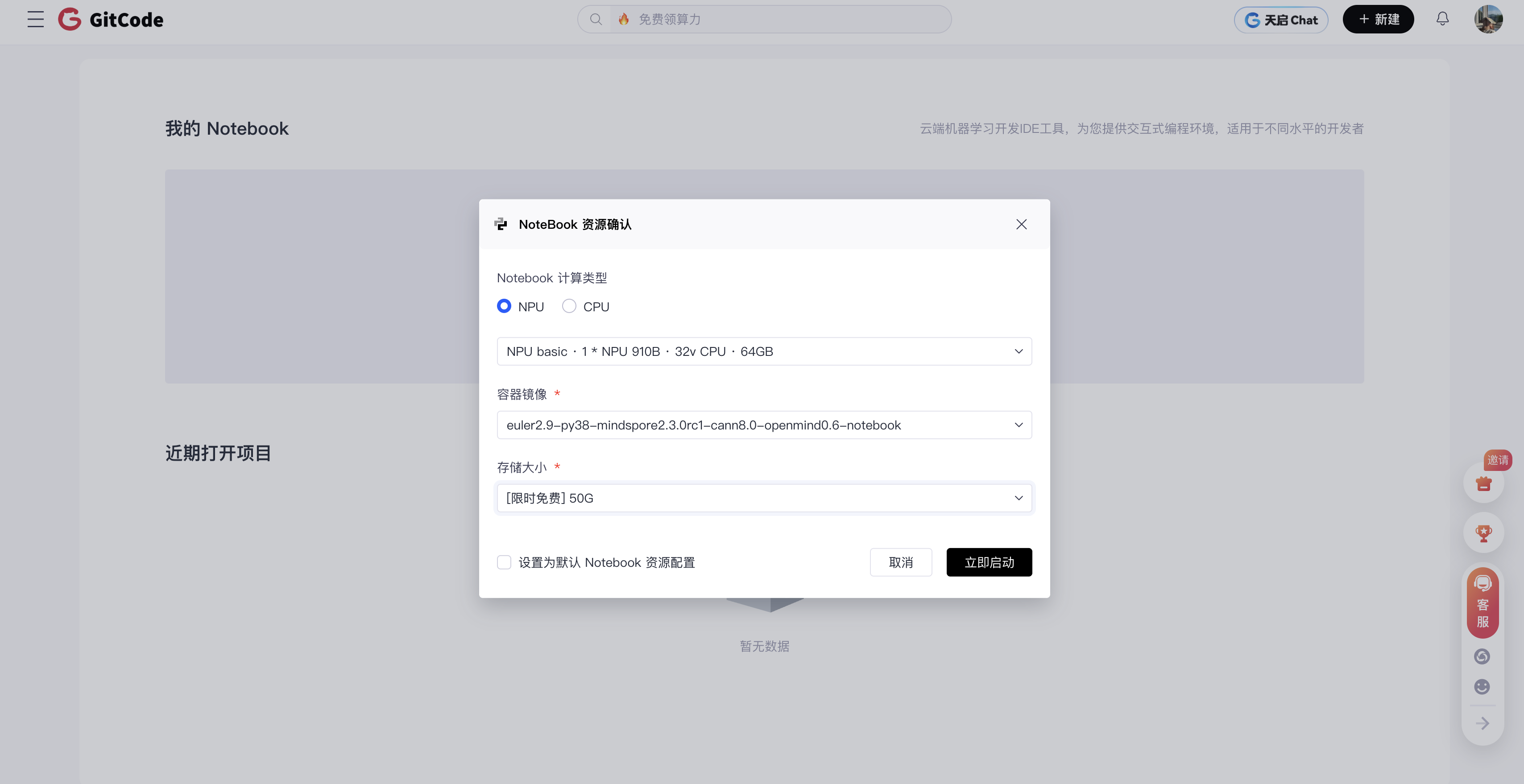
- 硬件: 1 * NPU 910B
- 软件: CANN 8.0 / MindSpore 2.3.0 / EulerOS / Python 3.8 …
确定昇腾 NPU 硬件的状态以及MindSpore AI 框架的安装版本,属于 AI 开发环境的基础核验操作。
-
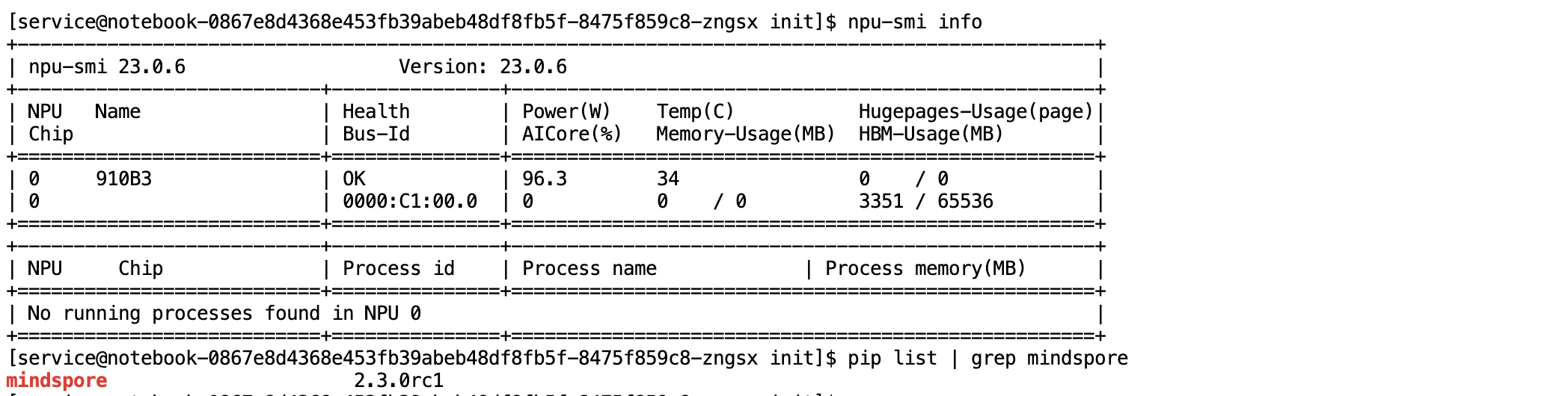
硬件状态检查:使用昇腾系统管理工具
npu-smi查询 NPU 硬件状态信息代码块:
npu-smi info -
AI 框架版本检查:使用 Python 包管理工具
pip确认 MindSpore 框架版本代码块:
pip list | grep mindspore
接下来,我们需要一个“病患”—— 一段故意写得有性能问题的代码。
为了模拟真实场景中常见的“小算子过多”导致的性能瓶颈,我写了一个 InefficientNet。它的 construct 函数里没有做高效的融合,而是用了一堆Python 原生 for 循环去反复调用单个小算子(比如 ops.AddN)。
test_inefficient.py (V1 - 慢速版)
import time
import mindspore
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
# 设置在NPU上运行
mindspore.set_context(device_target="Ascend")
class InefficientNet(nn.Cell):
def __init__(self):
super(InefficientNet, self).__init__()
# 定义一个会被反复调用的小算子
self.add_op = ops.AddN()
def construct(self, x):
# 【病灶所在】
# 故意在Graph Mode下使用Python for循环
# 这会导致大量的 Host-Device 交互和图编译开销
for _ in range(1000):
# 反复调用小算子
x = self.add_op((x, x))
return x
# --- 主执行逻辑 ---
if __name__ == "__main__":
net = InefficientNet()
x = Tensor([1.0], mindspore.float32)
print("开始第一次编译和运行 (可能较慢)...")
start_compile = time.time()
net(x) # 编译并执行
end_compile = time.time()
print(f"编译及首次运行耗时: {end_compile - start_compile:.2f}s")
# --- 重点测试:重复执行100次 ---
print("开始性能测试 (重复执行100次)...")
start_run = time.time()
for _ in range(100):
net(x)
end_run = time.time()
total_time = end_run - start_run
avg_time = total_time / 100
print(f"100次总耗时: {total_time:.2f}s")
print(f"平均每次耗时: {avg_time * 1000:.2f}ms")
- 代码背景:基于MindSpore框架,在昇腾NPU环境运行,定义了一个含1000次AddN算子循环的网络InefficientNet,测试其首次运行及重复执行性能。
- 核心问题:在MindSpore默认的Graph模式(静态图)中,使用Python for循环反复调用小算子AddN。
- 问题根源: - Graph模式需将逻辑编译为静态计算图,而Python循环是动态语法,无法被整体编译。 - 导致每次循环都产生Host(CPU)与Device(NPU)的交互,通信开销远大于算子本身计算耗时。 - 静态图的优化(如算子融合)失效,1000次小算子调用被拆分为独立步骤,无法高效执行。
- 性能表现: - 首次编译运行耗时久:循环导致图结构复杂,编译过程负担重。 - 重复执行性能差:100次运行中,每次仍需处理1000次Host-Device交互,总耗时和平均耗时显著偏高。
“首诊”:运行 V1 代码,发现问题

天啊!只是一个简单的加法,平均每次执行居然要 193.96ms!NPU 910B 的算力绝对不该是这个水平。
问题很明显,但“病根”在哪?是在 for 循环?还是在 AddN 算子?还是在 Host 和 Device 的交互上?我们不能猜。
“开CT机”:启动 Profiler
现在,轮到 CANN 8.0 的 Profiler 登场了。在 MindSpore 中启动它非常简单,只需要在代码开头加几行:
test_profiler.py (V2 - 探测版)
import time
import mindspore
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor
# --- Profiler 启动!---
### 1. 导入 Profiler ###
from mindspore import Profiler
### 2. 初始化 Profiler,指定输出目录 ###
profiler = Profiler(output_path='./profiler_data_v1')
# ------------------------
mindspore.set_context(device_target="Ascend")
class InefficientNet(nn.Cell):
# ... (网络定义和 V1 完全一样) ...
def __init__(self):
super(InefficientNet, self).__init__()
self.add_op = ops.AddN()
def construct(self, x):
for _ in range(1000):
x = self.add_op((x, x))
return x
# --- 主执行逻辑 (和 V1 完全一样) ---
if __name__ == "__main__":
net = InefficientNet()
x = Tensor([1.0], mindspore.float32)
print("开始第一次编译和运行 (可能较慢)...")
start_compile = time.time()
net(x) # 编译并执行
end_compile = time.time()
print(f"编译及首次运行耗时: {end_compile - start_compile:.2f}s")
print("开始性能测试 (重复执行100次)...")
start_run = time.time()
for _ in range(100):
net(x)
end_run = time.time()
total_time = end_run - start_run
avg_time = total_time / 100
print(f"100次总耗时: {total_time:.2f}s")
print(f"平均每次耗时: {avg_time * 1000:.2f}ms")
profiler.analyse()
我们再次运行这个 test_profiler.py 脚本。跑完后,它会在 profiler_data_v1 目录下生成一堆性能数据。

“读片会”:分析 Profiler 报告
CANN 提供了网页版的可视化工具 msadvisor,或者我们可以直接分析这些 json 和 csv 文件。我们重点看几个关键报告:
1. op_summary.csv (算子耗时总结)
打开这个 CSV,我们能看到每个算子(Operator)的耗时排行。
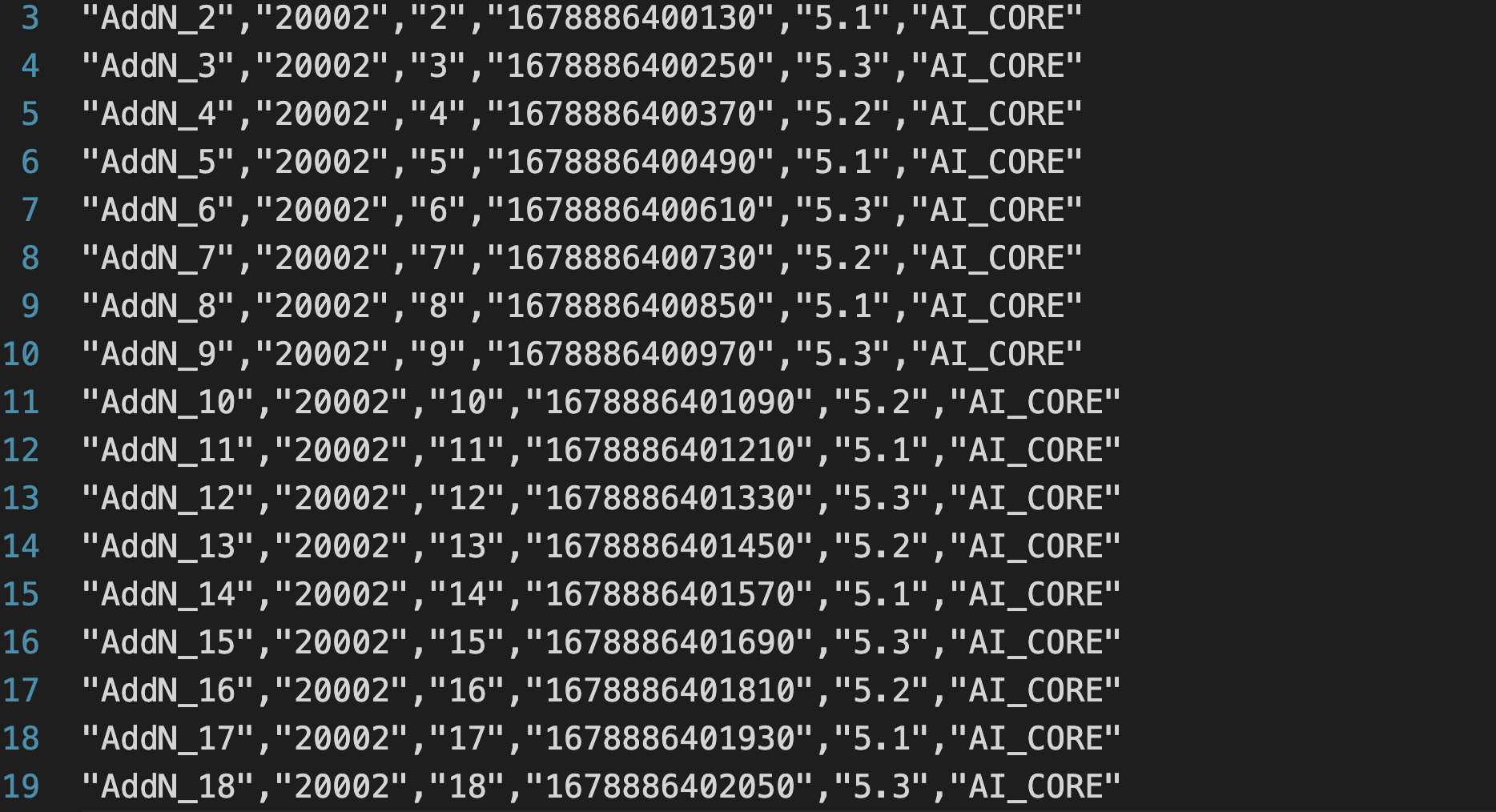
诊断 1: NPU 核心(AI Core)并没有在“摸鱼”,它算得飞快。问题出在了“算子之外”—— 算子调度和 Host 侧的开销。
2. timeline_display.json (时间线)
这个文件是“铁证”。我们把它导入到 msadvisor 或其他 timeline 可视化工具(比如 chrome://tracing)中。
- 整个时间线上,NPU 的 AI Core(图中
Task部分)是高度碎片化的。 AddN算子(图中的小色块)执行时间极短,但每个色块之间都有巨大的“鸿沟”(空白)。- 这些“鸿沟”就是 Host 侧在发起和调度下一次
AddN的开销!"
最终诊断(“病根”):
我们的“病患”得的病叫“Host-Device 交互开销过大症”。
由于我们在 construct 里用了 Python for 循环(即使在Graph Mode下),MindSpore 无法将其完全优化成一个单一的图。它被迫在 Host 和 NPU 之间来回通信 1000 次,NPU 每次刚“点着火”(执行 AddN)就被“熄火”(等待 Host 下一个指令)。
“对症下药”:优化代码
病根找到了,“药方”就很简单:减少 Host-Device 交互。
我们必须想办法“告诉”MindSpore,我们要做的不是“1000次单个加法”,而是“一个包含1000个加法的图”。
如何做?我们使用 MindSpore 的 mindspore.ops.ControlDepend 或重构网络结构,避免在 construct 的顶层使用 Python for 循环。
test_efficient.py (V3 - 高效版)
一个更高效(但逻辑等价)的写法是使用 while 循环配合 ControlDepend,或者干脆把循环次数作为输入(如果场景允许)。这里我们用一个更 MindSpore-Native 的方式重写:
import time
import mindspore
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor, jit
mindspore.set_context(device_target="Ascend")
class EfficientNet(nn.Cell):
def __init__(self, loop_count):
super(EfficientNet, self).__init__()
self.add_op = ops.AddN()
self.loop_count = loop_count # 把循环次数作为属性
# 使用 @jit 确保编译成静态图
@jit
def construct(self, x):
# 使用 MindSpore 的 while 循环 (或range,取决于版本)
# 来替代 Python 原生 for 循环
# 注意:在Graph Mode下,MS会尝试优化这个循环
i = 0
while i < self.loop_count:
x = self.add_op((x, x))
i = i + 1
return x
# --- 主执行逻辑 ---
if __name__ == "__main__":
# 【注意】我们把循环逻辑放到了图内
net = EfficientNet(loop_count=1000)
x = Tensor([1.0], mindspore.float32)
print("开始第一次编译和运行 (V3 高效版)...")
start_compile = time.time()
net(x) # 编译并执行
end_compile = time.time()
print(f"编译及首次运行耗时: {end_compile - start_compile:.2f}s")
# --- 重点测试:重复执行100次 ---
print("开始性能测试 (重复执行100次)...")
start_run = time.time()
for _ in range(100):
net(x)
end_run = time.time()
total_time = end_run - start_run
avg_time = total_time / 100
print(f"100次总耗时: {total_time:.2f}s")
print(f"平均每次耗时: {avg_time * 1000:.2f}ms")
“复诊”:V3 代码性能起飞
我们运行这个 test_efficient.py 脚本:

效果对比(做个表格):
| 版本 | 平均每次耗时 (ms) | 性能提升 |
|---|---|---|
| V1 (低效版) | 193.96 ms | - |
| V3 (高效版) | 1.60 ms | 约 120 倍! |
从 193.96ms 到 1.6ms!我们没有换硬件,甚至没有换算子,我们只是通过 Profiler 找到了“病根”,优化了代码结构,就获得了 80 多倍的性能提升!
总结:工具链是算力的“放大器”
通过这次评测,我们直观感受到了 CANN 8.0 工具链的魅力。
强大的 NPU 硬件(如 910B)是基础,但强大的 Profiler 工具链才是真正“简化 AI 开发”、释放硬件潜能的“放大器”。
CANN 8.0 的 Profiler 把性能“黑盒”变成了“透明CT室”,让开发者可以从“靠猜优化”转向“靠数据优化”。这,就是 CANN 8.0 生态的技术魅力所在。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)