
PyTorch深度学习实战:基于PyTorchLightning框架的视觉转换器
摘要 本课程介绍Vision Transformers(ViT)在计算机视觉任务中的应用。学员将学习ViT的工作原理,包括图像分块、分类令牌和位置编码等关键技术。实验基于CIFAR10数据集,使用PyTorch Lightning框架在昇腾NPU设备上进行模型训练和测试。课程涵盖环境配置、数据预处理(包含随机裁剪、水平翻转等增强方法)、数据集划分以及模型实现等完整流程。通过对比传统CNN架构,帮助
Vision Transformers视觉变换器
学习目标
通过本课程,学员能够学习Vision Transformers的原理与实现,了解其将图像分块、添加分类令牌和位置编码的方法,并实现在CIFAR10数据集上的训练与模型性能的测试,掌握PyTorch Lightning框架在昇腾设备上的使用。
相关知识点
- Vision Transformers视觉变换器
学习内容
1 Vision Transformers视觉变换器
1.1 安装环境依赖
- seaborn是基于Matplotlib的高级数据可视化库,提供更美观的默认样式和更简洁的 API,用于绘制统计图表(如热力图、箱线图、分布图等)。
- pytorch-lightning是简化PyTorch模型训练流程的框架,提供结构化代码模板,自动处理训练循环、验证、日志记录等。
- tensorboard是TensorFlow的可视化工具,用于监控训练过程中的指标(如损失、准确率)、查看模型结构、分析数据分布等。
%pip install matplotlib-inline==0.1.7
%matplotlib inline
%pip install seaborn==0.13.2
%pip install pytorch-lightning==2.4.0
%pip install tensorboard==2.19.0
%pip install ipdb==0.13.13
ascend_npu_for_pytorch_lightning是适配华为Ascend NPU环境,要求pytorch_lightning版本为2.4.0。运行以下指令获取源码包:
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_codes/35121d201b6411f0acd1fa163edcddae/ascend_npu_for_pytorch_lightning.zip
!unzip ascend_npu_for_pytorch_lightning.zip
1.2 CIFAR10数据集和预训练模型获取
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。运行以下指令从obs桶中获取CIFAR10数据集和预训练模型:
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_models/35121d201b6411f0acd1fa163edcddae/saved_models.zip
!wget --no-check-certificate https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/35121d201b6411f0acd1fa163edcddae/data.zip
!unzip saved_models.zip
!unzip data.zip
本课程将深入探讨用于计算机视觉的Transformer。自从Alexey Dosovitskiy等人成功地将Transformer应用于多种图像识别基准测试以来,出现了大量后续工作,表明卷积神经网络(CNN)可能不再是计算机视觉的最佳架构。但Vision Transformer(视觉变换器)究竟是如何工作的,与CNN相比,它们提供了哪些好处和缺点?本课程将通过实现一个Vision Transformer并在CIFAR10数据集上进行训练来解答这些问题。
%cd ascend_npu_for_pytorch_lightning
以下代码主要进行实验配置环境,加载数据集,并设置相关参数以确保实验的可重复性和高效性。首先导入基础库包括文件路径操作、科学计算库、画图库等,后导入PyTorch核心库、计算机视觉工具库,以及图片预处理工具。DATASET_PATH设置数据集下载路径,CHECKPOINT_PATH设置预训练模型保存路径。最后进行计算设备的设置,本课程使用NPU进行验证。
#基础依赖模块导入
import os
import numpy as np
import random
import math
import json
from functools import partial
from PIL import Image
import matplotlib
matplotlib.use('module://matplotlib_inline.backend_inline') # 设置为 Jupyter Notebook 的内联后端
import matplotlib.pyplot as plt
plt.set_cmap('cividis')
%matplotlib inline
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="torch_npu")
import os
os.environ['PYTORCH_NPU_ALLOC_CONF'] = 'expandable_segments:True'
import matplotlib_inline
matplotlib_inline.backend_inline.set_matplotlib_formats('svg', 'pdf')
from matplotlib.colors import to_rgb
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.reset_orig()
from tqdm.notebook import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
import torch_npu
import torchvision
from torchvision.datasets import CIFAR10
from torchvision import transforms
%reload_ext tensorboard
try:
import pytorch_lightning as pl
except ModuleNotFoundError:
!pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
%reload_ext tensorboard
%load_ext tensorboard
NUM_WORKERS = os.cpu_count()
DATASET_PATH = "../data"
CHECKPOINT_PATH = "../saved_models/tutorial15"
pl.seed_everything(42)
torch.use_deterministic_algorithms(True)
device = torch.device("npu:0")
print("Device:", device)
print("Number of workers:", NUM_WORKERS)
以下代码用于配置预训练模型路径,以确认预训练模型存在。
base_url = "./"
pretrained_files = ["tutorial15/ViT.ckpt", "tutorial15/tensorboards/ViT/events.out.tfevents.ViT",
"tutorial15/tensorboards/ResNet/events.out.tfevents.resnet"]
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
当代码成功回显Device等相关内容 ,表示设备及基础环境已经完成配置。然后使用以下指令加载CIFAR10数据集并进行相关预处理,包括数据增强、数据集划分、数据加载以及可视化示例。
- 数据增强:训练集使用随机水平翻转和随机裁剪增强,防止模型过拟合;测试集仅进行标准化处理。其作用是通过几何变换(翻转、裁剪)和像素变换(噪声、对比度)扩充数据集,增强模型对不同视角和光照条件的鲁棒性。
- 数据集分割:将50000张训练图像分为45000张训练集和5000张验证集,确保模型评估的客观性,
- 数据加载器:设置batch_size=128,训练集开启shuffle,使用pin_memory加速数据传输。
test_transform = transforms.Compose([transforms.ToTensor(), # 将PIL图片转为PyTorch张量,形状为[C,H,W],数值范围[0,1]
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])# 图象各通道均值、标准差
train_transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomResizedCrop((32,32),scale=(0.8,1.0),ratio=(0.9,1.1)),
# 随机裁剪并Resize,从原图随机区域裁剪,面积为原图的80%-100%
transforms.ToTensor(),
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])# 与测试集相同的标准化
train_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=train_transform, download=False) # 从本地加载数据集
val_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=test_transform, download=False)
pl.seed_everything(42) # 固定随机种子确保划分可复现
train_set, _ = torch.utils.data.random_split(train_dataset, [45000, 5000]) # 从train_dataset中划分45000为训练集
pl.seed_everything(42)
_, val_set = torch.utils.data.random_split(val_dataset, [45000, 5000]) #从val_dataset中划分5000为测试集
test_set = CIFAR10(root=DATASET_PATH, train=False, transform=test_transform, download=False)
from torch.utils.data import Subset
# 创建一个索引列表,表示前 1000 个样本
train_data = list(range(450))
val_data = list(range(50))
test_data =list(range(100))
# 使用 Subset 创建子集
train_set = Subset(train_set, train_data)
val_set = Subset(val_set, val_data)
test_set = Subset(test_set, test_data)
# 定义数据加载器
train_loader = data.DataLoader(train_set, batch_size=128, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = data.DataLoader(val_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
test_loader = data.DataLoader(test_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
# 从验证集中获取前4张图像的张量
NUM_IMAGES = 4
CIFAR_images = torch.stack([val_set[idx][0] for idx in range(NUM_IMAGES)], dim=0)
# 创建图像网络
img_grid = torchvision.utils.make_grid(CIFAR_images, nrow=4, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(8,8))
plt.title("Image examples of the CIFAR10 dataset")
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()

输出可看到四张CIFAR10数据集的数据示例。
1.3 图像分类中的 Transformer
Transformer 最初是为处理集合而提出的,因为它是一种排列等变架构,即如果输入被排列,就会产生相同的输出,只是顺序不同。为了将 Transformer 应用于序列,简单地在输入特征向量中添加了位置编码,而模型本身学会了如何处理它。那么,为什么不在图像上做同样的事情呢?这正是Alexey Dosovitskiy 等人在他们的论文“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”中提出的。具体来说,视觉 Transformer 是一种用于图像分类的模型,它将图像视为更小的图像块序列。作为一种预处理步骤,将例如 48×4848\times 4848×48 像素的图像分割成9个16×1616\times1616×16的图像块。这些图像块中的每一个都被视为一个“单词”/“标记”,并被投影到特征空间中。通过添加位置编码和一个用于分类的标记,可以像往常一样将 Transformer 应用于这个序列,并开始训练它以完成我们的任务。下面展示了一个关于该架构的 GIF 动画可视化。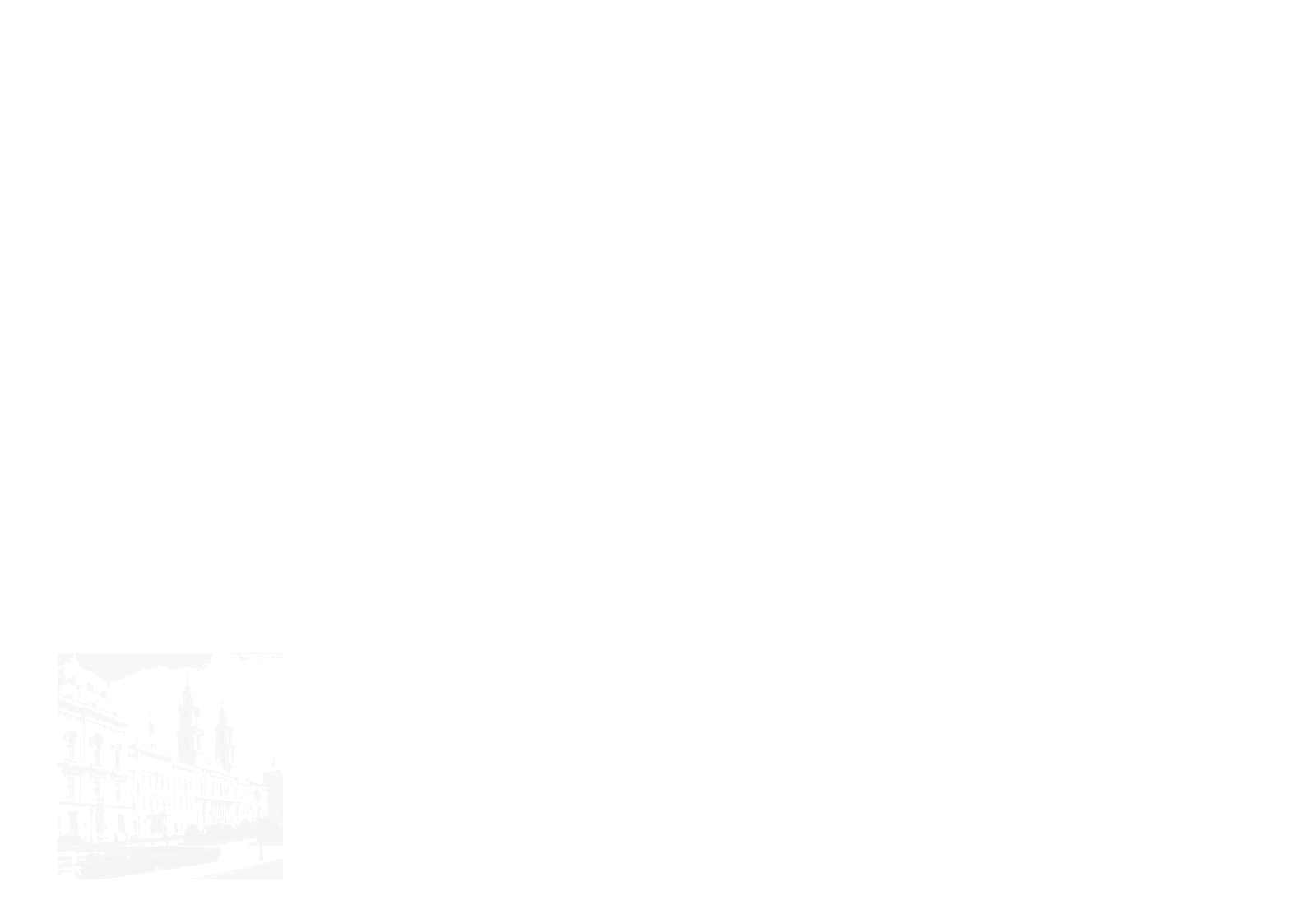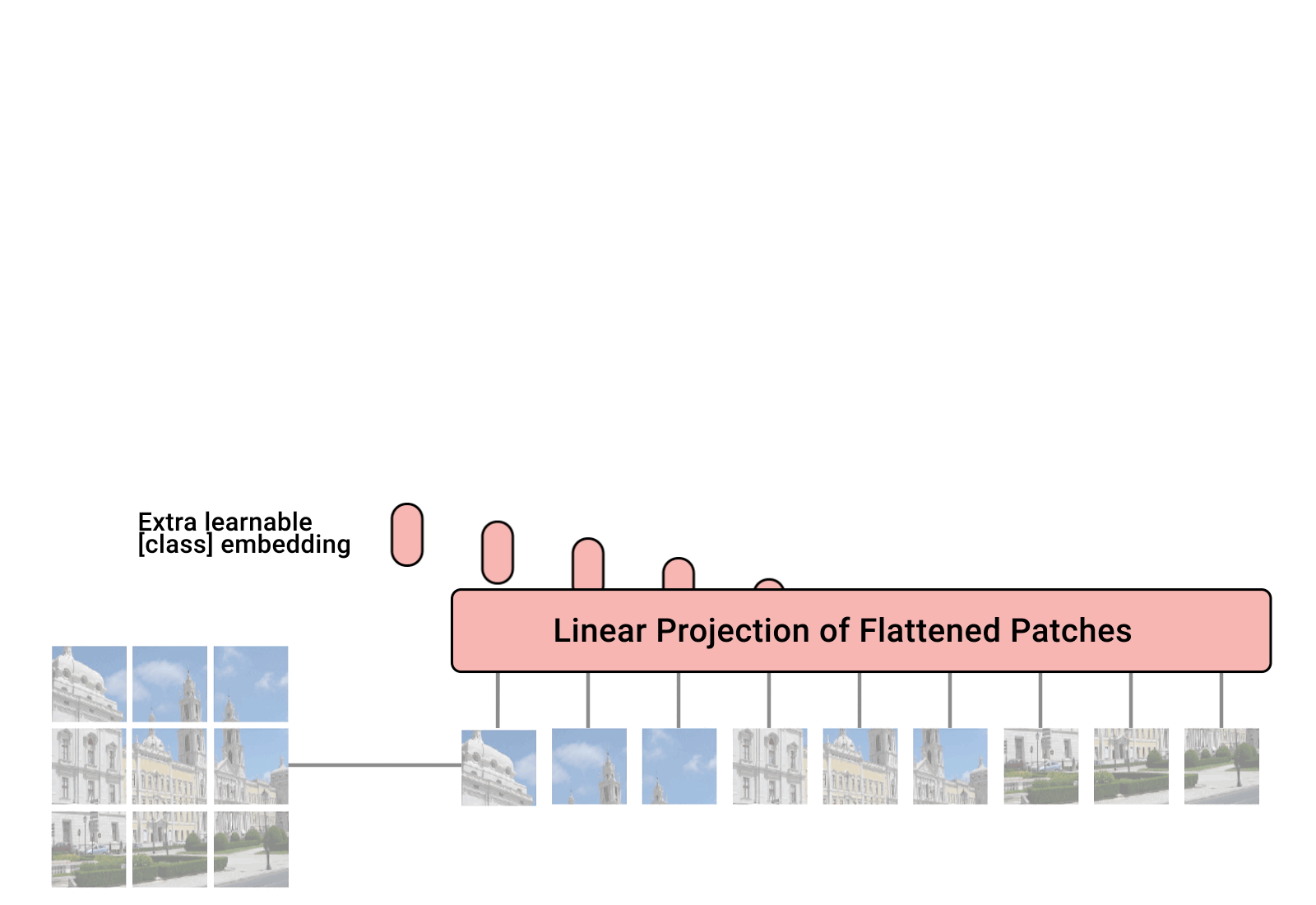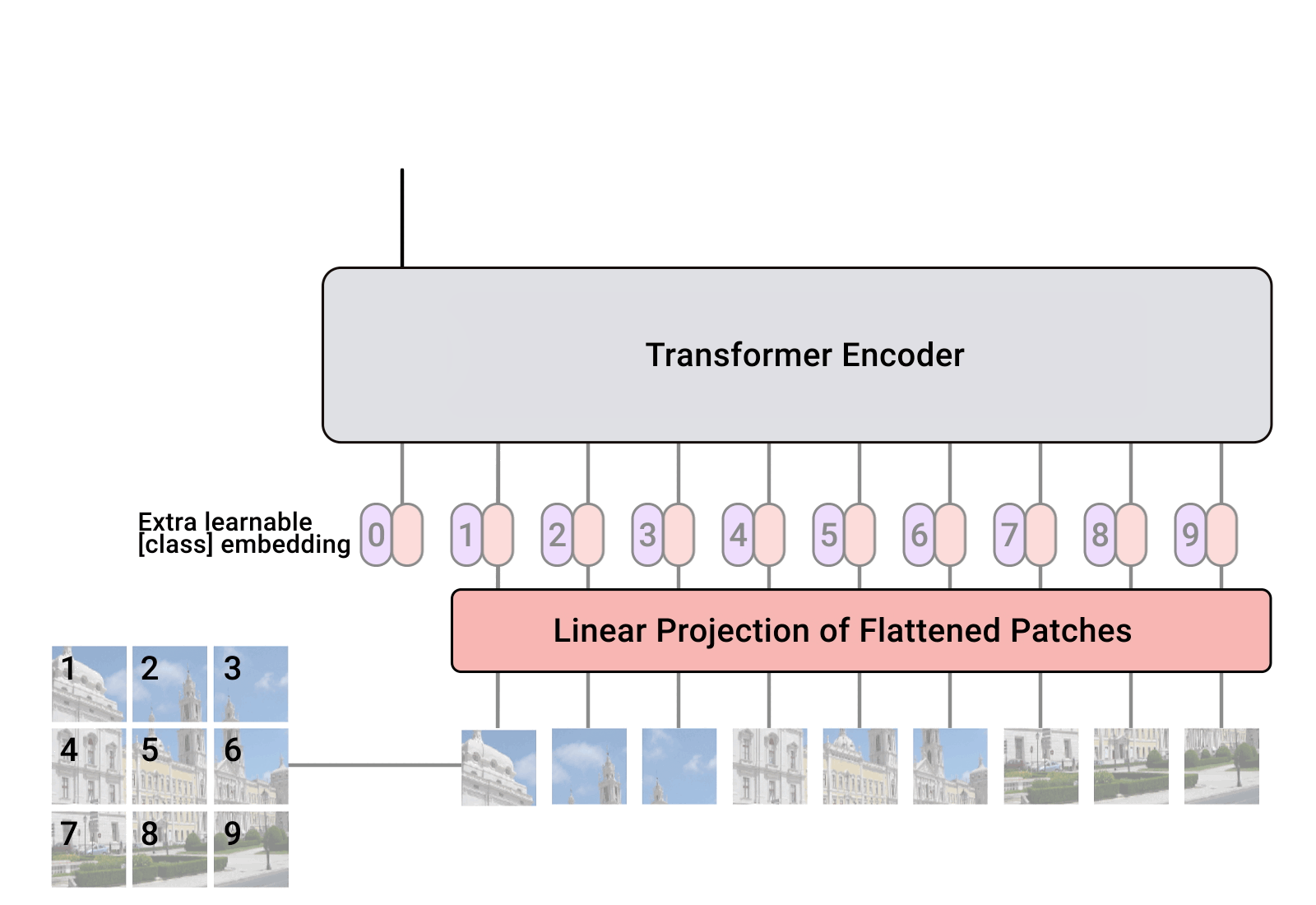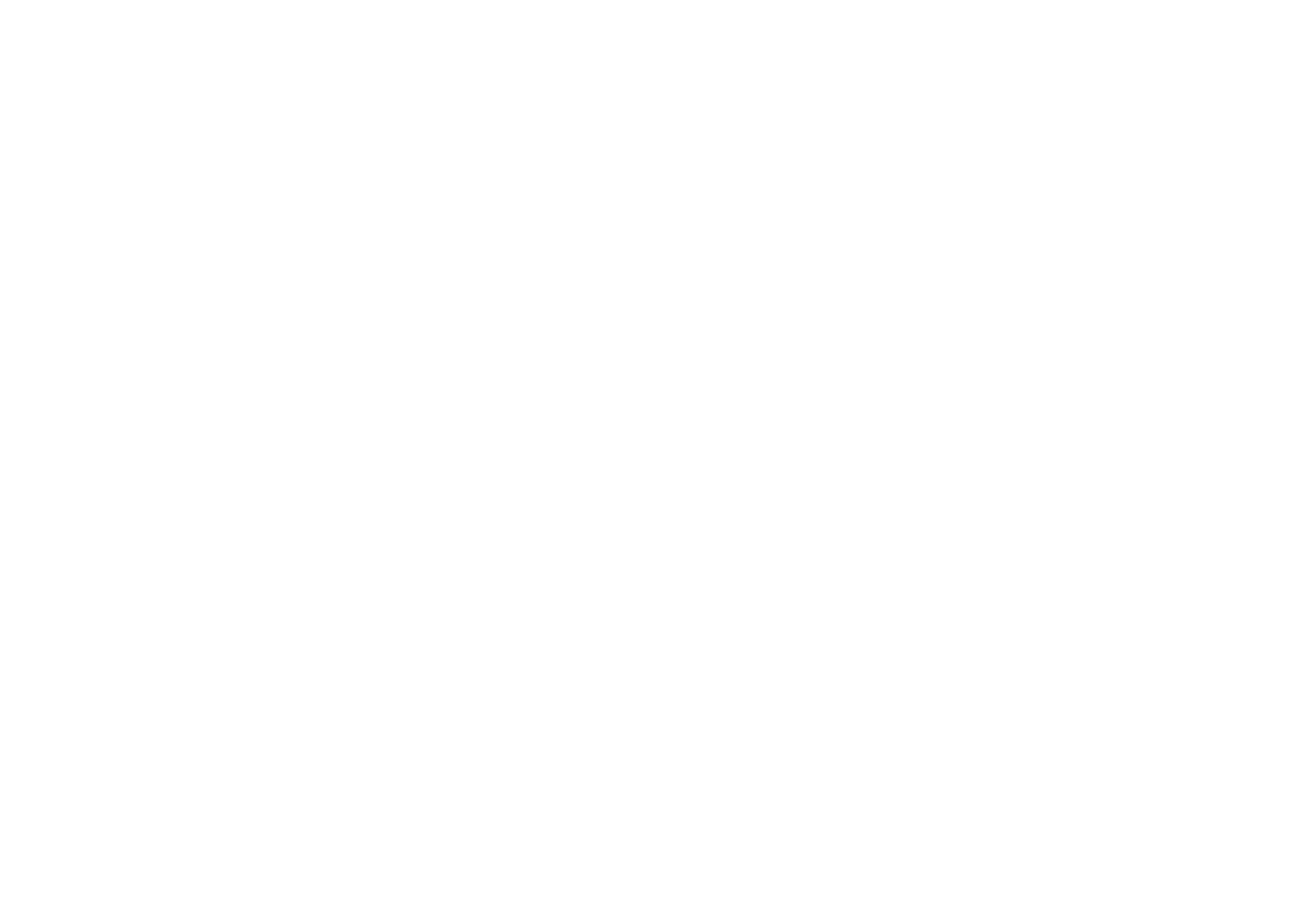
图1:Transformer框架
下面将逐步深入了解视觉 Transformer,并自行实现其所有部分。首先,实现图像预处理:将大小为 N×NN\times NN×N 的图像分割成 (N/M)2(N/M)^2(N/M)2 个大小为 M×MM\times MM×M 的图像块。这些图像块代表 Transformer 的输入单词。
- 分块逻辑:将输入图像(32×32)按 patch_size=4 分割为 8×8=64 个补丁,每个补丁尺寸为 4×4×3(RGB)。
- 维度变换:通过 reshape 和 permute 操作将图像从 [B, C, H, W] 转换为 [B, N, C×P×P],其中 N 为补丁数量(64)。
- 可视化:将分块后的补丁重新排列成网格,展示输入 Transformer 的序列形式。
理论补充:
- ViT 的核心思想:将图像视为 “补丁序列”,每个补丁类比 NLP 中的 “单词”,通过线性投影转换为特征向量。这种处理方式打破了 CNN 的空间连续性假设,将图像转化为无序集合。
- 归纳偏置的缺失:CNN 通过卷积操作内置了 “局部性” 和 “平移不变性” 归纳偏置,而 ViT 需要通过位置编码显式学习位置信息。
def img_to_patch(x, patch_size, flatten_channels=True):
"""
输入:
x:表示图像的PyTorch张量,形状为[批量大小(B),通道数(C),高度(H),宽度(W)]
patch_size:图像块每个维度的像素数
flatten_channels:若为True,将以展平格式作为特征向量返回,而非图像网格
"""
B, C, H, W = x.shape
x = x.reshape(B, C, H//patch_size, patch_size, W//patch_size, patch_size)
x = x.permute(0, 2, 4, 1, 3, 5)
x = x.flatten(1,2)
if flatten_channels:
x = x.flatten(2,4)
return x
下面将详细展示 CIFAR 示例中是如何工作的。对于大小为 32×3232\times 3232×32 的图像,选择的图像块大小为 4。因此,得到了 64 个大小为 4×44\times 44×4 的图像块序列。在下面对它们进行了可视化:
img_patches = img_to_patch(CIFAR_images, patch_size=4, flatten_channels=False)
fig, ax = plt.subplots(CIFAR_images.shape[0], 1, figsize=(14,3))
fig.suptitle("Images as input sequences of patches")
for i in range(CIFAR_images.shape[0]):
img_grid = torchvision.utils.make_grid(img_patches[i], nrow=64, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
ax[i].imshow(img_grid)
ax[i].axis('off')
plt.show()
plt.close()

与原始图像相比,现在的这些图像块列表很难识别出其中的对象。不过,这就是提供给 Transformer 用于对图像进行分类的输入。模型必须自己学习如何组合这些图像块以识别对象。在 CNN 中,图像是一个像素网格的归纳偏差,而在这种输入格式中则丢失了这种偏差。
在了解了预处理之后,现在可以开始构建 Transformer 模型了。此外,还将使用Ruibin Xiong et al.等人在 2020 年提出的 Transformer 块的预层归一化版本。其想法是将层归一化应用于残差块内的第一层,而不是残差块之间。这种层的重新组织有助于更好的梯度流动,并消除了预热阶段的必要性。标准的后层归一化(Post-LN)和预层归一化(Pre-LN)版本之间的差异可视化如下。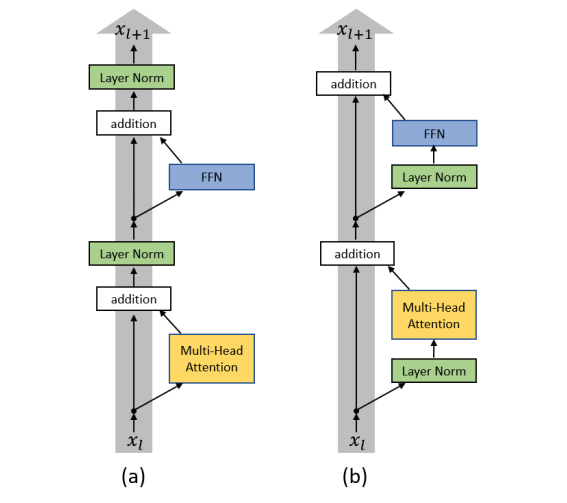
图2:后层归一化(Post-LN)和预层归一化版本之间的差异可视化
预层归一化注意力块的实现如下所示:
- Pre-LN 架构:在注意力和前馈网络前应用 LayerNorm,而非传统的 Post-LN,改善梯度流动,无需学习率预热。
- 多头注意力:使用 PyTorch 的 nn.MultiheadAttention,将输入特征分为 num_heads 个并行子空间,增强模型捕捉不同语义信息的能力。
- 前馈网络:包含 GELU 激活函数和 Dropout,提升模型非线性表达能力并防止过拟合。
理论补充:
- Layer Normalization 的位置:传统 Transformer 采用 Post-LN(在残差连接后应用 LayerNorm),而 Pre-LN 将 Norm 前置,避免深层网络中的梯度消失问题,尤其适合训练深层 ViT。
- 自注意力机制:允许模型捕获补丁间的长距离依赖关系,这是 CNN 通过多层卷积难以高效实现的。每个补丁的特征与所有补丁的特征计算注意力权重,实现全局上下文建模。
class AttentionBlock(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_heads, dropout=0.0):
"""
输入:
embed_dim:输入特征向量和注意力特征向量的维度
hidden_dim:前馈网络中隐藏层的维度
num_heads:多头注意力模块中使用的头数
dropout:在前馈网络中应用的dropout概率
"""
super().__init__()
self.layer_norm_1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads,
dropout=dropout)
self.layer_norm_2 = nn.LayerNorm(embed_dim)
self.linear = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
inp_x = self.layer_norm_1(x)
x = x + self.attn(inp_x, inp_x, inp_x)[0]
x = x + self.linear(self.layer_norm_2(x))
return x
现在已经准备好了所有模块,可以开始构建自己的视觉 Transformer 了。除了 Transformer 编码器外,还需要以下模块:
- 一个 线性投影 层,用于将输入图像块映射到更大尺寸的特征向量。它通过一个简单的线性层实现,该层独立地将每个 M×MM\times MM×M 图像块作为输入。
- 一个添加到输入序列中的 分类标记。我们将使用该分类标记(简称 CLS 标记)的输出特征向量来确定分类预测。
- 在被 Transformer 处理之前添加到标记中的可学习 位置编码。这些位置编码用于学习位置相关的特征,并将集合转换为序列。由于我们通常使用固定分辨率,因此可以学习位置编码,而不是使用正弦和余弦函数的模式。
- 一个 MLP 头,它接受 CLS 标记的输出特征向量,并将其映射到分类预测。这通常通过一个小型前馈网络甚至一个单一的线性层实现。
- 输入处理流程:图像分块→线性投影→添加 CLS 令牌→位置编码→Transformer 编码→CLS 令牌分类。
- CLS 令牌:一个可学习的特殊令牌,作为序列的全局表示,类比 NLP 中的句子嵌入。
- 位置编码:可学习的 1D 向量,与补丁特征相加,赋予序列顺序信息。
理论补充:
- ViT 架构组件:
- 补丁分割:将 2D 图像转换为 1D 补丁序列,分辨率为 H/16×W/16(ImageNet 标准)或 H/4×W/4(CIFAR10)。
- 线性投影:将每个补丁的像素值映射为高维嵌入向量(embed_dim=256)。
- CLS 令牌:通过自注意力机制聚合所有补丁的信息,作为图像的全局表示。
- 位置编码:由于 Transformer 本身是排列不变的,位置编码是学习空间结构的关键。
与 CNN 的对比:CNN 通过卷积核的局部连接和权值共享内置归纳偏置,而 ViT 依赖数据驱动的学习,在小数据集上泛化能力较弱。
考虑到这些组件,在下面实现完整的视觉 Transformer:
class VisionTransformer(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_channels, num_heads, num_layers, num_classes, patch_size, num_patches, dropout=0.0):
"""
Inputs:
embed_dim:输入特征向量和注意力特征向量的维度
hidden_dim:前馈网络中隐藏层的维度
num_channels:输入的通道数
num_heads:多头注意力模块中使用的头数
num_layers:要在Transformer中使用的层数
num_classes:预测的类别个数
patch_size:图像块每个维度的像素数
num_patches:一个图像所拥有的图像块的最大数量
dropout:在前馈网络中应用的dropout概率
"""
super().__init__()
self.patch_size = patch_size
self.input_layer = nn.Linear(num_channels*(patch_size**2), embed_dim)
self.transformer = nn.Sequential(*[AttentionBlock(embed_dim, hidden_dim, num_heads, dropout=dropout) for _ in range(num_layers)])
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, num_classes)
)
self.dropout = nn.Dropout(dropout)
self.cls_token = nn.Parameter(torch.randn(1,1,embed_dim))
self.pos_embedding = nn.Parameter(torch.randn(1,1+num_patches,embed_dim))
def forward(self, x):
x = img_to_patch(x, self.patch_size)
B, T, _ = x.shape
x = self.input_layer(x)
cls_token = self.cls_token.repeat(B, 1, 1)
x = torch.cat([cls_token, x], dim=1)
x = x + self.pos_embedding[:,:T+1]
x = self.dropout(x)
x = x.transpose(0, 1)
x = self.transformer(x)
cls = x[0]
out = self.mlp_head(cls)
return out
最后,将所有内容放入一个 PyTorch Lightning 模块中。使用 torch.optim.AdamW 作为优化器,它是一种带有修正的权重衰减实现的 Adam 优化器。由于使用的是预层归一化(Pre-LN)Transformer 版本,因此不再需要使用学习率预热阶段。将 ViT 模型与训练逻辑分离,定义训练、验证、测试步骤及优化器配置。AdamW 优化器是Adam 的变种,将权重衰减与梯度更新解耦,防止过拟合。学习率调度使用MultiStepLR 在第 100 和 150 轮训练时将学习率衰减为原来的1/10。
class ViT(pl.LightningModule):
def __init__(self, model_kwargs, lr):
super().__init__()
self.save_hyperparameters()
self.model = VisionTransformer(**model_kwargs)
self.example_input_array = next(iter(train_loader))[0]
def forward(self, x):
return self.model(x)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(), lr=self.hparams.lr)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100,150], gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode="train"):
imgs, labels = batch
preds = self.model(imgs)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(f'{mode}_loss', loss)
self.log(f'{mode}_acc', acc)
return loss
def training_step(self, batch, batch_idx):
loss = self._calculate_loss(batch, mode="train")
return loss
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode="val")
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode="test")
1.4 CIFAR10数据集在Vision Transformers上的验证
通常情况下,视觉 Transformer 被应用于大规模图像分类基准测试(如 ImageNet)以发挥其全部潜力。然而,视觉 Transformer 也能在经典的小型基准测试(如 CIFAR10)上取得成功吗?为了找出答案,可以在 CIFAR10 数据集上从头开始训练一个视觉 Transformer。首先创建一个用于 PyTorch Lightning 模块的训练函数,如果之前下载了预训练模型,该函数也会加载它。
def train_model(**kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH,"ViT"),
accelerator="npu" if str(device).startswith("npu") else "cpu",
devices=1,
max_epochs=180,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),
LearningRateMonitor("epoch")])
trainer.logger._log_graph = True
trainer.logger._default_hp_metric = None
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ViT.ckpt")
if os.path.isfile(pretrained_filename):
print(f"Found pretrained model at {pretrained_filename}, loading...")
model = ViT.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42)
model = ViT(**kwargs)
trainer.fit(model, train_loader, val_loader)
model = ViT.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
val_result = trainer.test(model, val_loader, verbose=False)
test_result = trainer.test(model, test_loader, verbose=False)
result = {"test": test_result[0]["test_acc"], "val": val_result[0]["test_acc"]}
return model, result
Out:
ViT results {‘test’: 0.809999942779541, ‘val’: 0.6800000071525574}
现在已经可以开始训练模型了。有一些超参数需要设置。在创建这个实验时,对超参数进行了一个小范围的网格搜索,并在下面的单元格中列出了最佳的超参数。
首先,考虑图像块的大小。当图像块做得越小,输入到 Transformer 的序列就越长。虽然一般来说,这允许 Transformer 建模更复杂的函数,但由于其在注意力层中二次方的内存使用,这需要更长的计算时间。此外,小的图像块可能会使任务变得更加困难,因为 Transformer 必须学习哪些图像块是相邻的,哪些是远离的。本课程尝试了大小为 2、4 和 8 的图像块,这分别提供了长度为 256、64 和 16 的输入序列。发现大小为 4 的图像块能够获得最佳性能,因此在下面选择了它。
接下来,嵌入维度和隐藏维度对 Transformer 的影响与对 MLP 的影响类似。维度越大,模型越复杂,训练所需的时间也越长。然而,在 Transformer 中,还需要考虑一个额外的方面:多头注意力层中的查询-键大小。每个键的特征维度为 embed_dim/num_heads。考虑到有长度为 64 的输入序列,键向量的最小合理大小为 16 或 32。更低的维度可能会过多地限制可能的注意力图。同时也观察到,对于 Transformer 来说,超过 8 个头是不必要的,因此本课程选择嵌入维度为 256。前馈网络中的隐藏维度通常比嵌入维度大 2-4 倍,因此本课程选择 512。
最后,Transformer 的学习率通常相对较小,在论文中,常用的值是 3e-5。然而,由于本课程处理的是一个较小的数据集,并且可能有一个更简单的任务,可以将学习率提高到 3e-4 而没有任何问题。为了减少过拟合,本课程使用了 0.2 的 dropout 值。在训练过程中还使用了小的图像增强作为正则化。
学员可以通过更改下面的值来自己探索超参数。一般来说,视觉 Transformer 在 CIFAR10 数据集上并没有显示出对超参数选择的过度敏感性。
import torch_npu
from torch_npu.contrib import transfer_to_npu
model, results = train_model(model_kwargs={
'embed_dim': 256,
'hidden_dim': 512,
'num_heads': 8,
'num_layers': 6,
'patch_size': 4,
'num_channels': 3,
'num_patches': 64,
'num_classes': 10,
'dropout': 0.2
},
lr=3e-4)
print("ViT results", results)
Vision Transformer 实现了约 81% 的测试性能和68%的验证性能。
1.5 实验结论
在本课程中,从头开始实现了自己的Vision Transformer,并将其应用于图像分类任务。Vision Transformer通过将图像分割成一系列较小的图像块,并将这些图像块作为输入传递给标准的Transformer编码器来工作。尽管Vision Transformer在大规模图像识别基准测试(如ImageNet)上取得了出色的结果,但在从头开始训练的小规模数据集(如CIFAR10)上,其表现明显不如卷积神经网络(CNN)。原因在于,与CNN不同,Transformer没有平移不变性和特征层次结构(即较大的模式由许多较小的模式组成)的归纳偏差。然而,当提供足够多的数据,或者模型已经在其他大规模任务上进行了预训练时,这些方面是可以学习到的。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)