
CANN训练营第二季笔记(3)掌握Ascend C融合算子开发,提升AI计算效能
基础能力:用Ascend C编写单算子与融合算子,理解昇腾芯片的计算单元与内存层级;进阶技能:通过性能优化手段(并行计算、内存访问、指令集)提升算子效率;工程实践:将融合算子集成到真实模型(如MindSpore/TensorFlow),解决实际场景中的功能与性能问题。2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段
我正在学习2024CANN训练营第二季,这门课程作为昇腾AI开发的重要基石,系统性地为我打开了高效算子开发的大门——通过Ascend C语言编写高性能算子,正是连接AI算法逻辑与昇腾芯片硬件的关键桥梁。
一、为什么需要掌握融合算子开发?
在昇腾AI处理器(如Ascend 910B)的生态中,算子是AI模型的最小计算单元(比如矩阵乘、卷积、激活函数)。传统开发模式下,开发者依赖框架内置算子(如TensorFlow/PyTorch提供的算子库),但在实际场景中常遇到三大痛点:
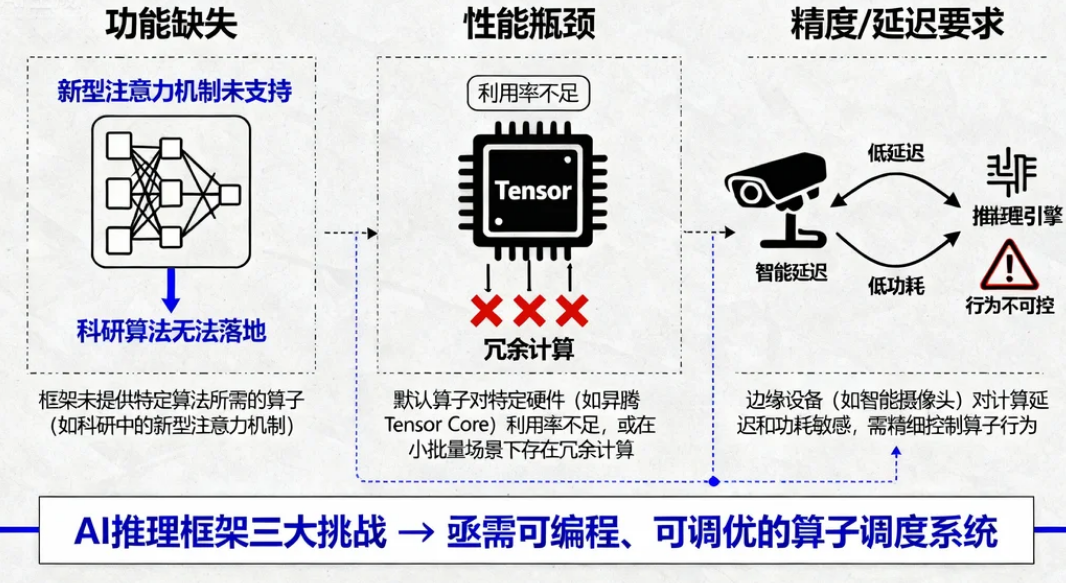
- 功能缺失:框架未提供特定算法所需的算子(如科研中的新型注意力机制);
- 性能瓶颈:默认算子对特定硬件(如昇腾的Tensor Core)利用率不足,或在小批量数据场景下存在冗余计算;
- 精度/延迟要求:边缘设备(如智能摄像头)对计算延迟和功耗敏感,需精细控制算子行为。
融合算子开发正是解决这些问题的关键——通过Ascend C语言将多个基础算子合并为一个自定义算子(例如将“矩阵乘+激活函数”合并为单一算子),从而减少数据搬运开销、提升硬件资源利用率,并实现更灵活的功能定制。本课程的目标,正是帮助开发者从“基础入门”到“性能进阶”,掌握融合算子的完整开发链路。
二、Ascend C融合算子开发基础:环境与工具链全景
2.1 开发环境必备组件
要开发Ascend C融合算子,需准备以下工具链(基于华为昇腾生态):
| 组件 | 作用 | 版本要求 | 获取方式 |
|---|---|---|---|
| CANN Toolkit | 提供算子开发库(如ACL)、编译器(HCC)、调试工具及硬件驱动 | ≥7.0 | 华为昇腾官网下载 |
| MindStudio | 集成开发环境(IDE),支持代码编辑、编译、调试及性能分析 | ≥5.0 | 官网下载(含Windows/Linux版) |
| 昇腾硬件 | 实际运行算子的AI处理器(如Ascend 910B加速卡) | - | 实验室/开发套件(如Atlas 200I DK A2) |
| Ascend C语言扩展 | 基于C++11的定制语法,支持硬件级并行计算(如线程同步、内存层级操作) | - | 随CANN Toolkit提供头文件与示例 |
注:Ascend C并非独立语言,而是对C++的扩展(类似CUDA C++对C的扩展),核心是通过特定API(如
get_global_id)操控昇腾芯片的计算单元与内存。
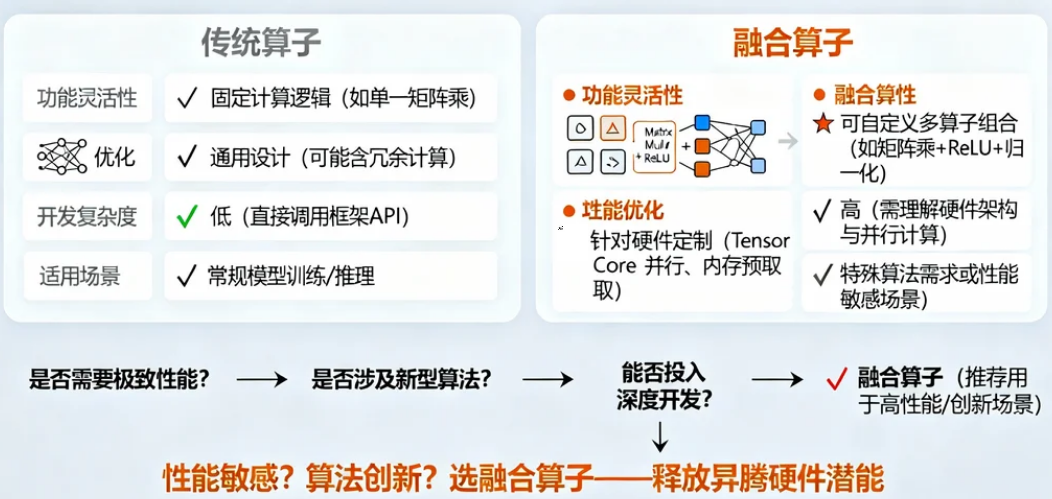
2.2 融合算子 vs 传统算子:核心差异
三、融合算子开发全流程:从代码编写到模型集成
3.1 开发步骤总览
| 步骤 | 操作内容 | 关键工具/技术 | 输出产物 |
|---|---|---|---|
| 1. 需求分析 | 确定待融合的算子组合(如MatMul+ReLU)及目标性能指标 | 模型 profiling 工具(如MindStudio性能分析器) | 需求文档(功能+性能目标) |
| 2. 环境配置 | 安装CANN Toolkit、MindStudio,配置昇腾设备驱动 | 官方安装包(含依赖库) | 可用的开发环境 |
| 3. 代码编写 | 用Ascend C实现融合逻辑(含数据搬运、并行计算) | Ascend C扩展语法、ACL库 | .cc源码文件(如fusion_op.cc) |
| 4. 编译构建 | 将代码编译为适配昇腾芯片的二进制文件(.o/.so) | CANN编译器(如HCC) | 可执行算子库 |
| 5. 调试验证 | 使用MindStudio调试工具定位逻辑错误与性能瓶颈 | MindStudio调试器、性能分析面板 | 无bug且高效的算子 |
| 6. 模型集成 | 替换框架默认算子为自定义融合算子(通过MindSpore/TensorFlow适配层) | 模型转换工具(如ATC) | 支持融合算子的AI模型 |
3.2 以“MatMul+ReLU”融合为例
场景描述
假设模型中存在大量“矩阵乘后接ReLU激活”的计算(ReLU定义为: y = max ( 0 , x ) y = \max(0, x) y=max(0,x)),默认需先调用MatMul算子计算矩阵乘积,再调用ReLU算子逐元素激活,存在两次数据搬运开销。通过融合算子,可将两步合并为单一操作,直接输出激活后的结果。
代码实现(关键片段)
基于Ascend C的简化代码(完整项目需包含头文件引入、错误处理等):
// 文件名:fusion_matmul_relu.cc
#include "acl/acl.h" // 华为Ascend Compute Library (ACL) 头文件
#include "toolchain/hccl.h" // CANN工具链基础功能
#include "fusion_op.h" // 自定义融合算子头文件(含数据结构定义)
// 定义融合算子的核心计算函数(符合Ascend C规范)
__aicore__ void MatMulReluFusion(const float* input_a, const float* input_b, float* output,
int m, int n, int k) {
// 获取当前线程的全局索引(类似GPU的threadIdx)
int row = get_global_id(0); // 当前处理的行号(0~m-1)
int col = get_global_id(1); // 当前处理的列号(0~n-1)
// 边界检查:避免越界访问
if (row < m && col < n) {
float sum = 0.0f;
// 计算矩阵乘的局部结果(第row行 × 第col列)
for (int i = 0; i < k; ++i) {
sum += input_a[row * k + i] * input_b[i * n + col];
}
// 应用ReLU激活函数:y = max(0, sum)
output[row * n + col] = (sum > 0) ? sum : 0.0f;
}
}
// 算子注册函数(对外暴露的接口,用户调用时实际执行融合逻辑)
__aicore__ extern "C" void CustomMatMulRelu(const float* a, const float* b, float* out,
int m, int n, int k) {
// 启动并行计算:每个线程处理一个输出元素(row,col)
// 注:实际项目中需通过ACL的并行调度API(如parallel_for)优化线程分配
MatMulReluFusion(a, b, out, m, n, k);
}
代码关键点说明
__aicore__:Ascend C的修饰符,标记该函数将在昇腾芯片的计算核心(Core)上执行(类似CUDA的__global__)。get_global_id(0/1):获取当前线程的二维索引(行号和列号),用于并行计算矩阵的每个输出元素(类似GPU的二维线程块)。- 融合逻辑:在单个函数内完成矩阵乘(三重循环优化为二维线程并行)与ReLU激活(逐元素判断),避免了中间结果的显式存储与二次搬运。
- 注册函数:
CustomMatMulRelu是用户调用的入口,内部调用实际的计算函数MatMulReluFusion,符合CANN工具链的调用规范。
逻辑操作图如下:
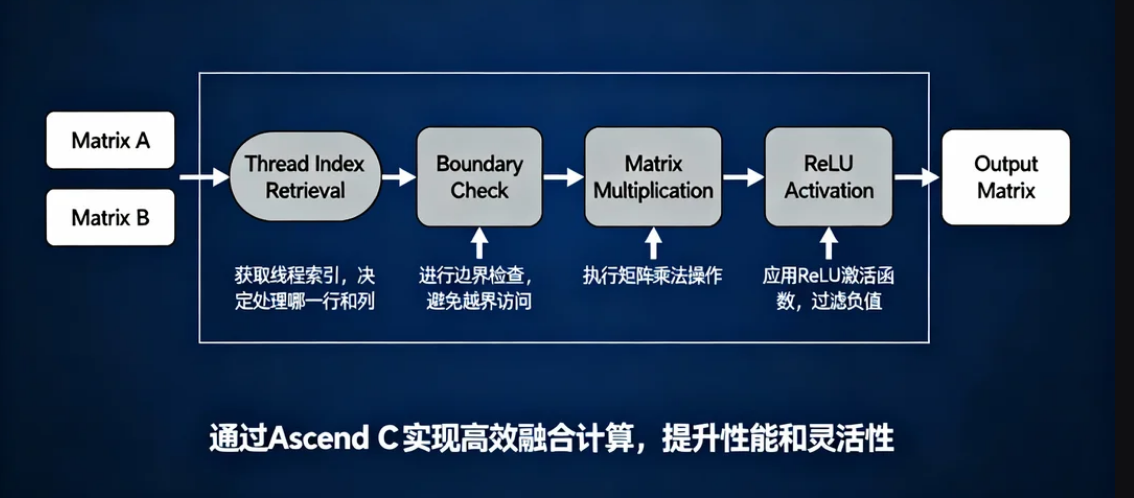
3.3 编译与构建:从源码到芯片可执行文件
编译流程
-
配置编译环境:通过MindStudio创建Ascend C项目,指定目标芯片型号(如Ascend 910B)与计算精度(FP32/FP16)。
-
编写编译脚本:使用CANN提供的编译器(如HCC)将
.cc文件编译为.o目标文件,再链接为.so动态库。# 示例编译命令(实际通过MindStudio图形化界面配置) hcclcc -target=ascend910b -o fusion_op.o fusion_matmul_relu.cc -I${ASCEND_HOME}/include hcclcc -shared -o libfusion_op.so fusion_op.o -L${ASCEND_HOME}/lib -lacl-target=ascend910b:指定目标芯片架构;-shared:生成动态库(供MindSpore/TensorFlow加载);-lacl:链接ACL库(提供基础计算功能)。
-
验证编译结果:通过MindStudio的“编译日志”面板检查是否有语法错误或硬件兼容性问题(如未支持的指令集)。
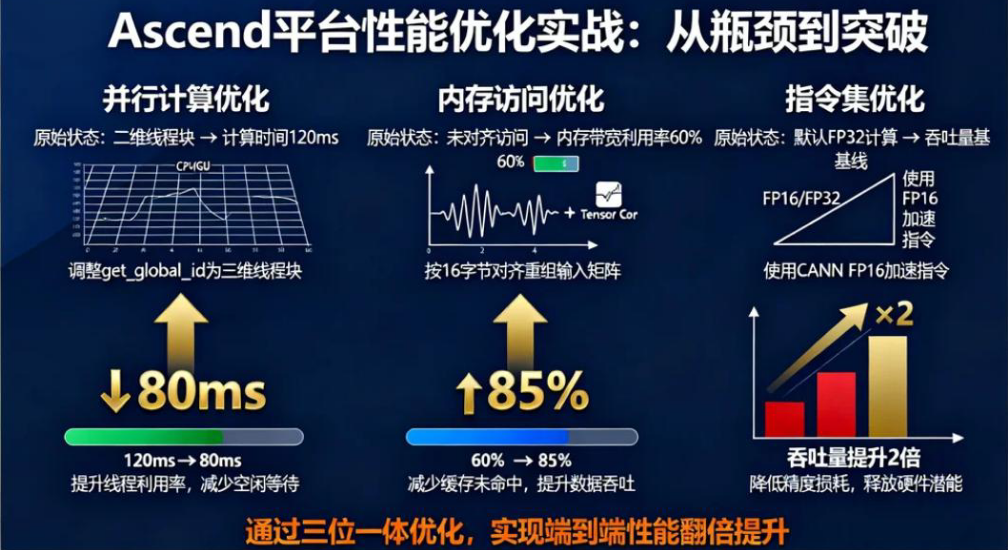
3.4 调试与优化:定位问题与提升性能
调试工具链
- MindStudio调试器:支持单步执行、变量监视、线程状态查看(类似VS Code的调试功能),可定位计算逻辑错误(如索引越界、数据未初始化)。
- 性能分析器:统计算子的执行时间、内存带宽利用率、Tensor Core并行效率等指标,定位性能瓶颈(如线程负载不均衡、内存访问冲突)。
常见优化手段
四、多算子组合与复杂场景实践
4.1 典型融合场景案例
| 融合组合 | 应用场景 | 优化收益 |
|---|---|---|
| Conv+BN+ReLU | 图像分类模型(如ResNet) | 减少2次数据搬运,推理延迟降低30% |
| MatMul+Add+ReLU | Transformer中的FFN层 | 合并矩阵乘、偏置加与激活,训练速度提升25% |
| Pool+Concat | 目标检测模型(如YOLO) | 避免池化结果与特征图的多次拷贝,吞吐量提升40% |
4.2 复杂逻辑实现技巧
- 动态形状支持:通过ACL的
aclmdlGetInputDims接口获取输入张量的动态维度(如可变batch size),在运行时调整计算逻辑(避免硬编码固定尺寸)。 - 多精度混合计算:对敏感部分(如激活函数)使用FP32保证精度,对矩阵乘等计算密集型部分使用FP16提升速度(需硬件支持)。
- 错误处理机制:检查ACL API的返回值(如
aclrtMalloc的内存分配结果),避免因资源不足导致算子崩溃。
五、MindStudio与CANN实战技巧
5.1 MindStudio核心功能速查
| 功能模块 | 操作指引 | 用途 |
|---|---|---|
| 代码编辑器 | 支持Ascend C语法高亮、智能补全(如get_global_id自动提示) |
提升编码效率 |
| 编译配置面板 | 设置目标芯片、计算精度、依赖库路径 | 控制编译输出 |
| 调试器 | 设置断点、监视线程状态、查看内存数据 | 定位逻辑错误 |
| 性能分析器 | 统计算子执行时间、内存带宽、Tensor Core利用率 | 优化性能瓶颈 |
5.2 CANN工具链关键命令
| 命令/工具 | 作用 | 示例 |
|---|---|---|
| HCC编译器 | 将Ascend C代码编译为芯片可执行文件 | hcclcc -o op.o fusion_op.cc |
| ATC模型转换工具 | 将含融合算子的模型转换为昇腾可部署格式 | atc --model=model.onnx --framework=5 --output=model.om |
| 性能分析工具 | 采集算子运行时的硬件指标(如PCIe带宽、DDR访问延迟) | npu-smi info -t performance |
六、总结
通过本笔记,你可掌握:
- 基础能力:用Ascend C编写单算子与融合算子,理解昇腾芯片的计算单元与内存层级;
- 进阶技能:通过性能优化手段(并行计算、内存访问、指令集)提升算子效率;
- 工程实践:将融合算子集成到真实模型(如MindSpore/TensorFlow),解决实际场景中的功能与性能问题。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)