
深入解析昇腾CANN:从硬件架构到Ascend C算子开发全景指南
本文旨在系统性地剖析华为昇腾(Ascend)的异构计算架构CANN,从其在AI技术栈中的战略定位,到昇腾AI处理器的微观硬件架构,再到Ascend C编程模型的核心思想与性能优化哲学,最终落地到一套完整、可复现的算子开发流程,为致力于成为AI系统核心人才的开发者,提供一份从宏观理论到微观实践的全景式技术指南。不理解硬件的脾性,就写不出真正高效的代码。算子开发者的代码最终是在物理硬件上运行的,因此,

摘要:
在人工智能技术栈中,AI框架层为算法研究与应用开发提供了前所未有的便利性。然而,这些高级API在抽象了底层复杂性的同时,也构建了一个性能与创新的“黑箱”。当面临极致的性能优化需求、需要适配前沿算法模型、或是在国产化AI计算平台上进行深度开发时,突破这一“黑箱”、深入硬件底层进行算子级开发与优化,便成为衡量高级AI工程师核心竞争力的关键标尺。本文旨在系统性地剖析华为昇腾(Ascend)的异构计算架构CANN,从其在AI技术栈中的战略定位,到昇腾AI处理器的微观硬件架构,再到Ascend C编程模型的核心思想与性能优化哲学,最终落地到一套完整、可复现的算子开发流程,为致力于成为AI系统核心人才的开发者,提供一份从宏观理论到微观实践的全景式技术指南。
第一章:CANN的宏观定位:AI计算的“中枢神经系统”
在深入任何技术的细节之前,建立一个清晰的宏观认知是至关重要的。CANN并非一个孤立的软件库,而是整个昇腾AI生态的基石。
1.1 CANN在分层AI技术栈中的角色
现代AI技术栈遵循经典的分层设计模式,以解耦复杂性:
- 应用层(Application Layer): 顶层,是面向最终用户的AI应用,如人脸识别、自然语言问答系统等。
- AI框架层(Framework Layer): 中间层,是算法工程师和应用开发者主要工作的层面,提供了如PyTorch、MindSpore、TensorFlow等高级编程接口。
- 计算架构层(Compute Architecture Layer): CANN正位于此层。它作为承上启下的核心,负责将上层框架的“意图”(表现为计算图)翻译并优化成底层硬件可以理解和高效执行的“指令”。
- 硬件层(Hardware Layer): 底层,是执行实际计算的物理实体,即昇騰AI处理器(NPU)。
AI框架使用Python等高级语言,提供了优雅且易于理解的API,但硬件只认识0和1构成的二进制指令。这两者之间存在着巨大的语义鸿沟。CANN的根本任务,就是高效、智能地跨越这道鸿沟。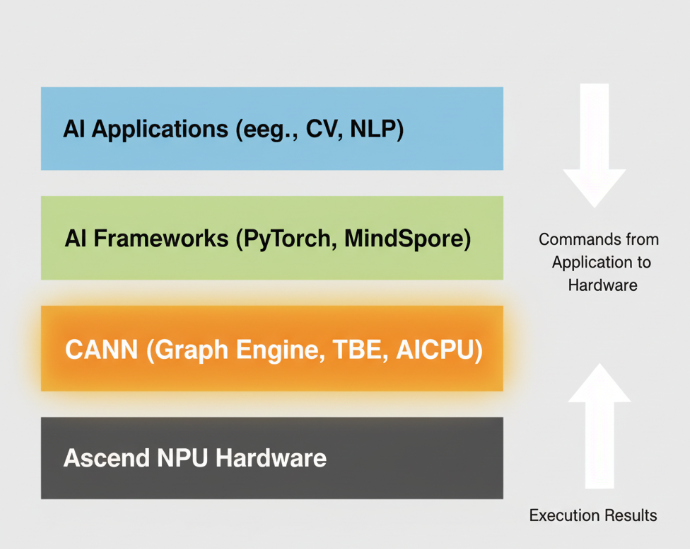
1.2 CANN的核心组件拆解
CANN并非一个单一的程序,而是一个由多个核心组件协同工作的复杂系统:
- 图引擎(Graph Engine, GE): 这是CANN的“总指挥官”。它负责接收并解析来自上层框架的计算图。GE的智能化水平极高,它会对原始计算图进行一系列的自动优化,包括但不限于:
- 算子融合(Operator Fusion): 自动识别图中可以合并的算子序列(如
Conv+BiasAdd+ReLU),将它们融合成一个单一的、更高性能的融合算子。这极大地减少了数据在内存中的冗余读写和函数调用开销,是图级优化的最重要手段。 - 内存优化: 智能地复用内存,减少不必要的内存分配和释放,降低显存占用。
- 并行分析: 分析图中的依赖关系,找出可以并行执行的部分,以最大化硬件利用率。
- 算子融合(Operator Fusion): 自动识别图中可以合并的算子序列(如
- 张量加速引擎(Tensor Boost Engine, TBE): 这是我们的主要工作平台。TBE是一个强大的算子开发工具集。当GE决定需要执行某个算子时,如果这是一个TBE算子,GE就会调用TBE来将其编译成NPU可执行的核函数(Kernel)。TBE支持**DSL(Domain Specific Language)和Ascend C(TIK模式)**两种开发方式,我们主要关注后者,因为它提供了最极致的性能控制能力。
- AI CPU引擎: 负责调度和执行那些不适合在NPU AI Core上运行的算子,通常是逻辑复杂、数据依赖不规则的控制类或数据处理类算子。
1.3 一次模型前向传播在CANN中的旅程
为了让上述概念更具体,我们追踪一次PyTorch模型的前向传播过程:
- Python层的
model(input)调用,通过torch_npu插件,将模型的计算图和输入数据传递给CANN。 - GE介入: GE捕获这张图,进行上述的算子融合等优化,生成一张更高效的“执行图”。
- 算子编译: GE遍历执行图上的每个节点(算子)。对于每个TBE算子,GE调用TBE,传入算子的输入输出信息(Shape, Dtype等)。TBE根据这些信息,即时(JIT)编译生成一个针对当前输入最优化的二进制核函数。
- 任务下发与执行: GE将编译好的核函数以及数据地址等信息,打包成任务下发给CANN的运行时(Runtime)。Runtime负责将这些任务精准地调度到NPU的AI Core或AI CPU上执行。
- 结果返回: 所有任务执行完毕后,结果通过Runtime返回给框架层,最终回到Python。
从这个流程可以看出,我们进行算子开发,正是在为TBE提供更多的“弹药”。我们开发的算子越高效、越丰富,GE在进行图优化和编译时就拥有越大的选择空间,最终整个模型的执行效率就越高。
第二章:深入物理核心:昇腾AI处理器的微观架构
不理解硬件的脾性,就写不出真正高效的代码。算子开发者的代码最终是在物理硬件上运行的,因此,对昇騰AI处理器(特别是其Da Vinci架构)的核心微观结构有一个清晰的认知,是进行性能优化的前提。
2.1 Da Vinci架构的核心计算单元
Da Vinci架构是一种高度并行的超长指令字(VLIW)架构,其核心计算资源可以分为两大类:
- AI Core: 架构的“肌肉”,负责执行绝大多数密集的数值计算任务。一个AI Core内部,又包含了三种功能高度特化的计算单元,它们在一个时钟周期内可以并行执行:
- 立方计算单元(Cube Unit): 这是AI Core的王牌,是一个规模宏大的脉动阵列,专门用于执行矩阵乘法(
A * B + C)。深度学习中超过80%的计算量都来自于矩阵乘法(如全连接层、卷积层的im2col实现),因此Cube Unit的效率直接决定了芯片的理论峰值算力。 - 向量计算单元(Vector Unit): 负责处理向量(一维数组)的计算,如逐元素加减乘除、激活函数(ReLU, Sigmoid等)、池化(Pooling)等。
- 标量计算单元(Scalar Unit): 负责处理单个数据(标量)的运算,以及整个核函数的流程控制、地址计算等。
- 立方计算单元(Cube Unit): 这是AI Core的王牌,是一个规模宏大的脉动阵列,专门用于执行矩阵乘法(
- AI CPU: 架构的“大脑”,通常是多个高性能的ARM CPU核心。负责处理那些AI Core不擅长的任务,如复杂的控制流、稀疏的计算、部分自定义算子的 হোস্ট侧逻辑等。
2.2 性能的生命线:存储金字塔(Memory Hierarchy)
这是所有高性能计算领域(包括GPU编程)都必须遵循的第一性原理。昇腾处理器的存储系统是一个典型的金字塔结构,越往上,速度越快,但容量越小,成本越高。
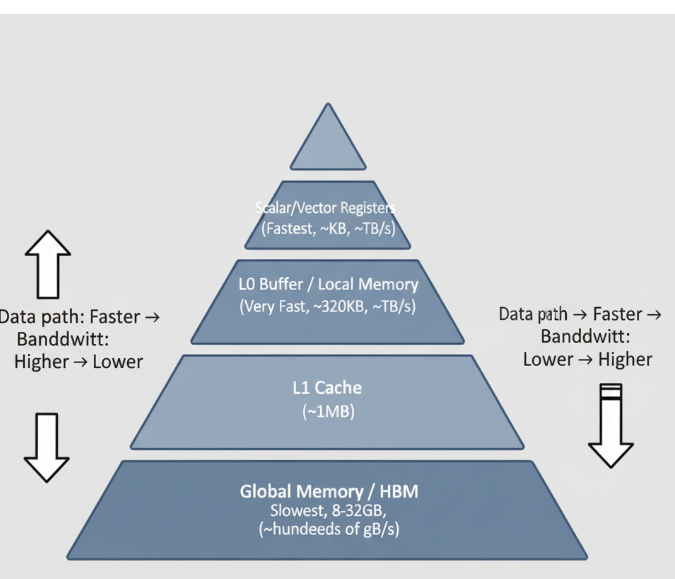
- 全局内存(Global Memory): 通常是高带宽内存(HBM)。容量巨大(GB级别),是所有模型参数和输入/输出张量的“家”。但其带宽(几百GB/s)和延迟(几百纳秒)相比于计算核心的速度,是一个巨大的瓶颈。
- L1 缓存(L1 Cache): 容量约1MB,作为全局内存的缓存,对开发者部分透明。
- 本地内存(Local Memory, L0 Buffer): 这是我们作为算子开发者必须主宰的战场。 每个AI Core都拥有自己私有的、高速的片上SRAM。它的容量极小(例如在Ascend 910中为320KB),但带宽极高(TB/s级别),访问延迟极低(~几十纳秒),与AI Core的计算速度相匹配。
- 寄存器(Registers): 金字塔的顶端,直接与计算单元相连,速度最快。
2.3 算子性能优化的核心矛盾
由此,我们推导出算子性能优化的核心矛盾:
计算必须在AI Core上进行,而AI Core的高效运转,依赖于数据必须位于其私有的、极小的Local Memory中。但我们的原始数据却存放在巨大但缓慢的Global Memory里。
因此,一个算子的性能,在很大程度上不取决于其计算有多复杂,而取决于其数据调度(Data Movement)有多高效。 一个优秀的算子,必须是一个精巧的“数据搬运工”,能够以最小的开销、最高效的流水线,将数据在Global Memory和Local Memory之间进行交换。
第三章:Ascend C编程模型:与硬件进行精妙对话的艺术
为了让开发者能够驾驭上述复杂的硬件,CANN提供了Ascend C编程语言。它是一座桥梁,让我们能用一种结构化的、接近C++的方式,来描述和控制底层的硬件行为。
3.1 Ascend C的核心设计哲学
Ascend C的设计,旨在向开发者暴露必要的硬件控制能力,同时屏蔽掉过于底层的汇编细节。它鼓励开发者将一个算子的实现,清晰地划分为数据流(Data Flow)和计算逻辑(Compute Logic)。
3.2 关键编程构件(Building Blocks)详解
__global__&__aicore__: 核函数限定符,前者声明该函数为Host-Device调用的入口,后者指定其在AI Core上执行。GlobalTensor<T>&LocalTensor<T>: 强类型的内存空间抽象。在代码中,通过这两种类型,我们可以清晰地区分数据位于哪个存储层次。TPipe: Local Memory的“内存管理器”。通过pipe.InitBuffer(local_tensor, size)来在编译时静态地在Local Memory上规划出一块空间。Ascend C的内存管理大部分是静态的,这有助于编译器进行更深入的优化。DataCopy(dst, src, num_elements): 数据搬运的“瑞士军刀”。它是一个高级抽象的内置函数,底层会调用硬件的DMA引擎,在不同内存空间之间高效地传输数据。GetBlockIdx()&GetBlockNum(): 并行编程的基石。CANN运行时会将一个大的计算任务分发给多个AI Core执行。在核函数内部,通过这两个函数,每个AI Core可以知道自己的唯一ID(BlockIdx)和参与本次任务的总AI Core数量(BlockNum),从而实现数据的并行处理(SPMD - Single Program, Multiple Data)。- 计算指令(Intrinsics): Ascend C提供了一系列与硬件计算单元直接对应的内置函数,如
Add(),Mul(),ReLU(), 以及最重要的MatMul()。调用这些函数,会被编译器直接翻译成高效的硬件指令。
3.3 性能的灵魂:Tiling与流水线化(Pipelining)
正如第二章所述,Tiling是解决核心矛盾的方法论。在Ascend C中,我们通过编程范式来实现Tiling。
标准的Tiling三段式流水线:
- Copy-In Stage: 将计算需要的下一个数据块(Tile)从Global Memory预取到Local Memory。
- Compute Stage: 对当前位于Local Memory中的数据块进行计算。
- Copy-Out Stage: 将上一个计算完成的结果数据块从Local Memory写回到Global Memory。
3.4 高级优化技术:双缓冲(Double Buffering)
为了让这三个阶段能够最大程度地重叠,隐藏数据搬运的延迟,我们通常使用双缓冲技术。
想象一下,我们在Local Memory中分配两块缓冲区,比如local_buffer_A和local_buffer_B。
- 在第N次循环中:我们在
local_buffer_A上进行计算,同时,硬件DMA开始将第N+1批数据预取到local_buffer_B中。 - 在第N+1次循环中:我们切换到在
local_buffer_B上进行计算,同时,硬件DMA将第N次计算的结果从local_buffer_A写回Global Memory,并开始将第N+2批数据预取到local_buffer_A中。
如此循环往复,计算单元总是有数据可算,而DMA总是在后台忙于搬运,两者互不等待,从而实现了计算和访存的并行,极大地提升了硬件的利用率(Occupancy)。精通双缓冲和其他流水线技术,是区分普通算子开发者和高级性能优化专家的分水岭。
第四章:全流程实战:从零构建一个功能完备的Add算子
理论的最终目的是指导实践。本章将以前述所有知识为基础,详细拆解一个Add算子的完整开发流程。
4.1 阶段一:定义与规划
- 算子分析: 确定数学逻辑
y = x1 + x2。确定支持的数据类型(如float16)、数据格式(ND)。 - 原型定义(
.proto): 创建add_custom.proto文件,用Protobuf语法清晰定义算子的接口。这是算子的“身份证”。 - 工程生成(
msopgen):msopgen gen -i add_custom.proto ...。此命令会创建出包含CMakeLists.txt、impl模板、testcases等在内的完整目录结构。
4.2 阶段二:Host侧实现 - Tiling策略的计算
算子在执行时,首先会在Host侧(CPU)运行一段逻辑,用于计算出本次任务的Tiling策略,然后将该策略传递给Device侧的核函数。
在op_AddCustom/op_proto/add_custom.cpp的TilingFunc中,我们需要编写这段逻辑。
// op_proto/add_custom.cpp
IMPLEMT_TILING_FUNC(AddCustomTilingFunc) {
// 1. 获取输入张量的总元素个数
uint32_t totalLength = op.GetInputDesc(0).GetShape().GetShapeSize();
// 2. 制定一个简单的Tiling策略:
// - 每次处理的数据块大小为2048个元素 (这个值需要根据具体硬件和数据类型考量)
// - 将这些信息打包到TilingData结构体中
TilingData tiling;
tiling.totalLength = totalLength;
tiling.blockLength = 2048; // A simple tiling strategy
// 3. 将TilingData写入到op的TilingInfo中,CANN会自动将其传递给核函数
op.SetTilingInfo(tiling);
return GRAPH_SUCCESS;
}
4.3 阶段三:Device侧实现 - Ascend C核函数
这是最核心的部分,在tbe/impl/add_custom.cpp中实现。
// tbe/impl/add_custom.cpp
#include "add_custom_tiling.h" // 引入Host/Device共享的TilingData结构体
using namespace AscendC;
class KernelAdd {
public:
// 初始化阶段:在AI Core上执行,负责内存规划
__aicore__ inline void Init(GM_ADDR x1, GM_ADDR x2, GM_ADDR y, TilingData* tiling) {
// 保存Tiling信息
this->totalLength = tiling->totalLength;
this->blockLength = tiling->blockLength;
// 映射全局内存张量
x1Gm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(x1), this->totalLength);
x2Gm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(x2), this->totalLength);
yGm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(y), this->totalLength);
// 使用TPipe在Local Memory上规划出三块缓冲区
pipe.InitBuffer(x1Local, this->blockLength);
pipe.InitBuffer(x2Local, this->blockLength);
pipe.InitBuffer(yLocal, this->blockLength);
}
// 执行阶段:实现Tiling流水线
__aicore__ inline void Process() {
int32_t loopCount = this->totalLength / this->blockLength;
int32_t blockIdx = GetBlockIdx();
int32_t blockNum = GetBlockNum();
// 多核并行处理循环
for (int32_t i = blockIdx; i < loopCount; i += blockNum) {
uint32_t offset = i * this->blockLength;
// Copy-In Stage
DataCopy(x1Local, x1Gm[offset], this->blockLength);
DataCopy(x2Local, x2Gm[offset], this->blockLength);
// Compute Stage
Add(yLocal, x1Local, x2Local, this->blockLength);
// Copy-Out Stage
DataCopy(yGm[offset], yLocal, this->blockLength);
}
}
// ... private data members ...
};
// 核函数入口
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x1, GM_ADDR x2, GM_ADDR y, GM_ADDR workspace, TilingData* tiling) {
KernelAdd op;
op.Init(x1, x2, y, tiling);
op.Process();
}
4.4 阶段四:编译、验证与部署
- 编译:
bash build.sh。此脚本会调用CANN提供的交叉编译器,将Host侧代码和Device侧Ascend C代码分别编译,并最终链接成一个.so动态库。 - 验证(ST Test): 在
testcases/st/目录下,编写st_test.py。# st_test.py pseudocode import numpy as np from cann_op_test_runner import CannOpTestRunner # 1. 定义测试用例 (shape, dtype) shape = (1, 20480) dtype = "float16" # 2. 生成输入数据 input1 = np.random.randn(*shape).astype(dtype) input2 = np.random.randn(*shape).astype(dtype) # 3. 计算CPU基准结果 (Golden) golden_output = input1 + input2 # 4. 运行NPU测试 runner = CannOpTestRunner("AddCustom", [shape, shape], [dtype, dtype]) npu_output = runner.run([input1, input2]) # 5. 精度比对 np.testing.assert_allclose(npu_output, golden_output, rtol=1e-3) print("Test Passed!") - 部署: 将编译生成的
*.so和*.json文件,按照CANN的环境变量规范,放置到指定的opp/op_impl/custom/和opp/op_proto/custom/等路径下,即可被AI框架动态加载和调用。
第五章:从“能用”到“好用”:性能优化的艺术
功能正确只是算子开发的起点,极致的性能才是其最终价值所在。
5.1 性能分析驱动的优化
优化绝非凭空猜测,而必须由性能分析工具(Profiler)驱动。昇腾提供了强大的Ascend Profiler工具,它可以:
- 可视化时间线(Timeline): 清晰地展示每个核函数的执行时间、数据搬运(DMA)的时间,以及Host与Device之间的交互。
- 硬件指标分析: 提供AI Core的利用率(Utilization)、内存带宽的占用率等底层硬件计数器信息。
通过分析Profiler的报告,我们可以精准地定位到性能瓶颈:是计算时间过长(Compute Bound),还是数据搬运延迟太高(Memory Bound)?
5.2 常用性能优化技术checklist
- 优化Tiling策略:
blockLength的选取至关重要。太小会导致DMA启动开销占比过高;太大又可能超出Local Memory的容量。需要根据具体的数据类型和硬件型号进行调优。 - 实现双缓冲: 如3.4节所述,通过使用两套
LocalTensor,实现计算和数据搬运的流水线并行。 - 数据重排与对齐: 确保数据在内存中的存放方式对硬件是最优的,例如,满足DMA搬运的对齐要求,可以显著提升带宽利用率。
- 指令级优化: 深入利用向量(Vector)指令,例如,使用
vmul一次性处理多个数据,而不是在循环中进行标量乘法。 - 减少Host-Device交互: 任何从Host到Device的调用都有开销。在图层面,算子融合是关键;在单算子层面,应避免在核函数中进行不必要的回调或同步。
结论
CANN算子开发是一项深度与广度并存的复杂工程。它不仅要求开发者对C++和并行计算有扎实的功底,更要求对AI模型、计算架构、特别是硬件的微观行为有深刻的理解。本文系统性地梳理了从宏观生态到微观硬件,再到编程模型和实战流程的完整知识图谱。
掌握这一体系,意味着你将具备解决AI工程中最具挑战性的核心问题的能力。在AI应用层日益同质化和自动化的今天,这种深入底层的、创造极致性能的硬核技能,将构成你最坚固、最稀缺、也最有价值的技术护城河。
从理论到实践的桥梁:
理论知识是根基,但唯有通过大量的实践才能真正内化。2025年昇腾CANN训练营第二季正是这样一个绝佳的实践平台。它提供了:
- 系统化的课程: 覆盖从0基础到专家的完整学习路径。
- 官方的技术支持: 活跃的社区和专业的导师为你答疑解惑。
- 权威的技能认证: Ascend C算子中级认证,是你能力的最佳证明。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你渴望深入AI技术的“水下冰山”,构建自己的硬核能力,那么,这里就是你的起点。
报名链接: https://www.hiascend.com/developer/activities/cann20252

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)