
算子开发实战:基于 CANN 的 Add 算子从理论到代码的完整构建
AI大模型时代,我们往往惊叹于上层应用的强大,却很少有机会深入底层,去探究那些支撑起庞大模型的“砖石”——AI算子。回顾整个过程,我们从一个简单的Add算子出发,完整地体验了昇腾CANN算子开发的标准流程。”,但相信我,麻雀虽小,五脏俱全。通过实现它,我们能完整地走通CANN算子开发的整个流程,为后续更复杂的算子开发打下坚实的基础。等专题课程,无论你是哪个阶段的开发者,都能找到适合自己的路径,快速

大家好,我是热爱学习的开发者。最近,我报名参加了备受瞩目的**“2025年昇腾CANN训练营第二季”**,这对我来说是一次全新的挑战和机遇。AI大模型时代,我们往往惊叹于上层应用的强大,却很少有机会深入底层,去探究那些支撑起庞大模型的“砖石”——AI算子。
这次训练营正是这样一个绝佳的机会。作为我的学习笔记和分享,我决定将整个过程记录下来。我们的第一站,就从最基础、也最经典的Add算子开始。你可能会觉得“一个加法有什么好写的?”,但相信我,麻雀虽小,五脏俱全。通过实现它,我们能完整地走通CANN算子开发的整个流程,为后续更复杂的算子开发打下坚实的基础。
那么,就让我们一起,创造属于我们自己的第一个AI算子吧!
第一章:万里长征第一步 —— 理论与流程
在动手敲代码之前,我们必须先弄清楚两个问题:我们要做什么?以及我们要怎么做?
1.1 什么是Add算子?
从数学上讲,Add算子就是实现两个张量(Tensor)对应元素的相加,即 C = A + B。在深度学习网络中,它虽然简单,但无处不在。比如在著名的ResNet(残差网络)中,核心的“捷径连接”(Shortcut Connection)就是通过Add算子来实现的。
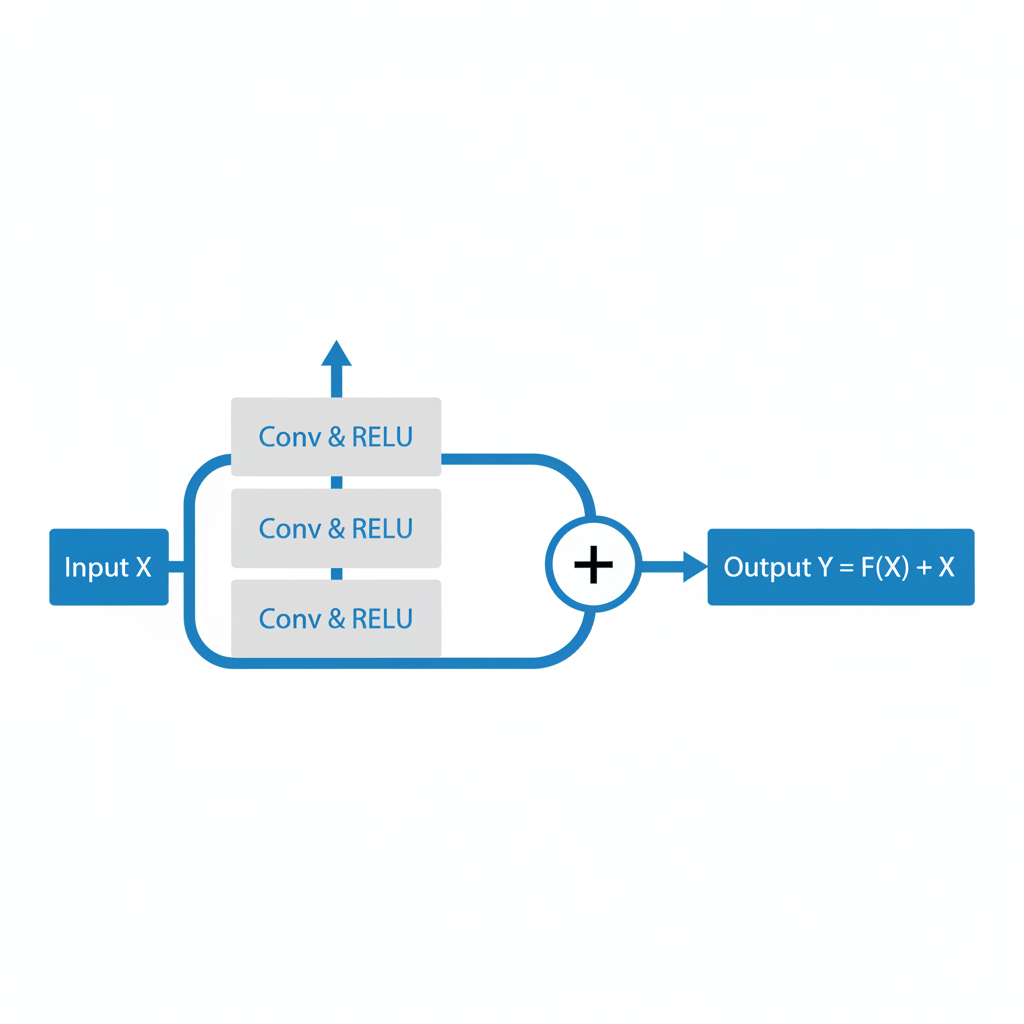
因此,优化Add算子的性能,对于提升整个网络的训练和推理效率至关重要。
1.2 CANN算子开发的标准流程
华为昇腾CANN为我们提供了一套非常规范和高效的算子开发流程。无论你开发多么复杂的算子,基本上都遵循以下几个步骤:
- 算子分析: 明确算子的数学逻辑、输入输出(数据类型、形状等)。
- 原型定义: 使用protobuf格式(
.proto文件)定义算子的接口。 - 核函数实现: 使用Ascend C语言编写算子的核心计算逻辑 (Kernel)。
- 算子实现集成: 编写胶水逻辑,将原型定义和核函数关联起来。
- 编译部署: 将代码编译成昇腾AI处理器可识别的二进制文件(
.so)和定义文件(.json)。 - 验证与测试: 编写测试用例(ST Test),验证算子功能的正确性和性能。
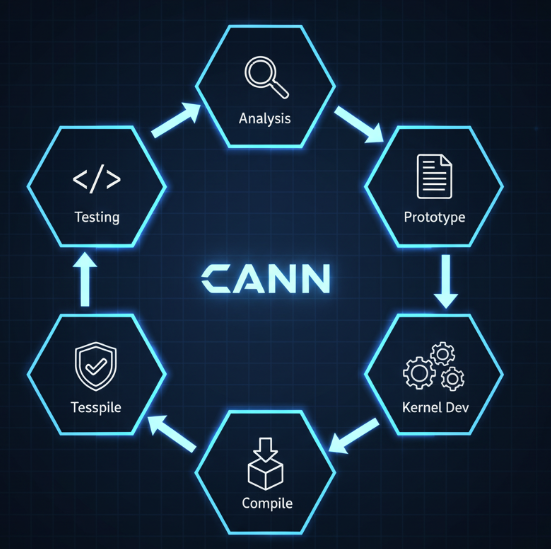
了解了这个流程,我们心里就有底了。接下来,让我们卷起袖子,开始准备我们的开发环境。
第二章:工欲善其事必先利其器 —— 环境准备
一个稳定、正确的开发环境是成功的一半。我默认大家已经根据官方文档,在自己的Linux服务器(推荐Ubuntu)上安装好了CANN开发套件包(Toolkit)。
2.1 验证CANN环境
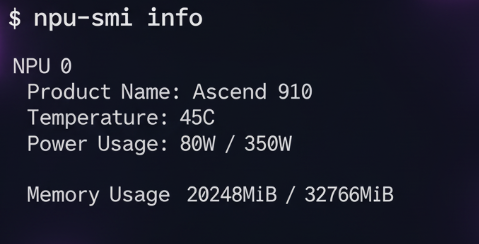
首先,打开你的终端,输入以下命令来验证驱动和固件是否安装成功:
npu-smi info
如果能看到类似GPU的nvidia-smi那样的输出,显示了NPU的型号、温度、功耗等信息,那么恭喜你,硬件环境基本没问题。
2.2 使用msopgen工具生成工程骨架
手动创建所有工程文件是一件非常繁琐且容易出错的事情。幸运的是,CANN提供了一个神器——msopgen。这个工具可以根据我们的算子原型定义文件,一键生成标准的算子工程目录结构。
首先,创建算子原型定义文件 add_custom.proto:
op_name: "AddCustom"
input_desc { name: "x1", format: "ND", type: "float16" }
input_desc { name: "x2", format: "ND", type: "float16" }
output_desc { name: "y", format: "ND", type: "float16" }
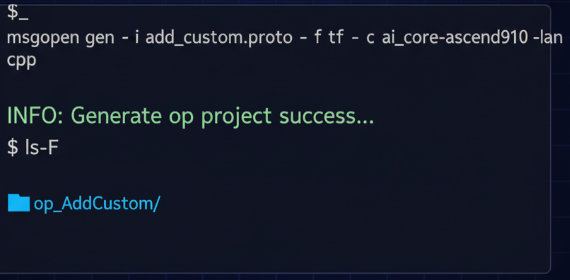
然后,在终端执行以下命令:
msopgen gen -i add_custom.proto -f tf -c ai_core-ascend910 -lan cpp
第三章:绘制蓝图 —— 深入Ascend C核函数实现
终于到了最激动人心的编码环节!打开 op_AddCustom/tbe/impl/add_custom.cpp 文件,我们将在这里编写让NPU“动起来”的代码。
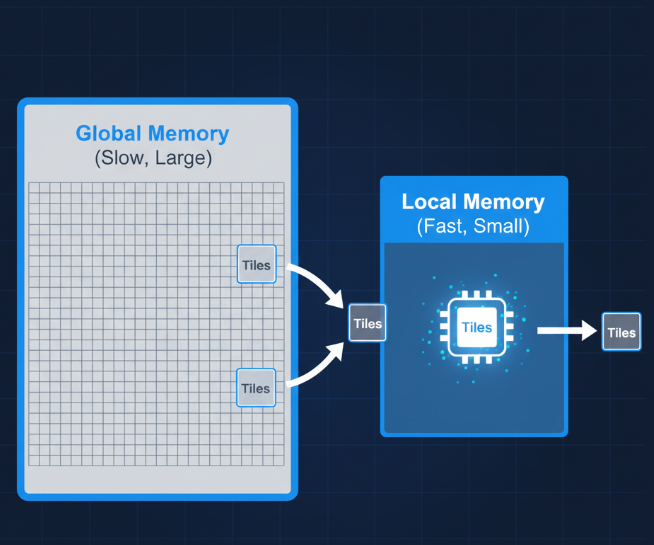
3.1 Ascend C基础概念:Tiling
Tiling(分块)是昇腾算子性能优化的核心思想。由于AI Core的本地内存(Local Memory)速度极快但容量有限,我们无法一次性处理巨大的张量。因此,需要将位于全局内存(Global Memory)的大数据,切分成小块(Tile),分批搬入本地内存进行计算,完成后再写回。
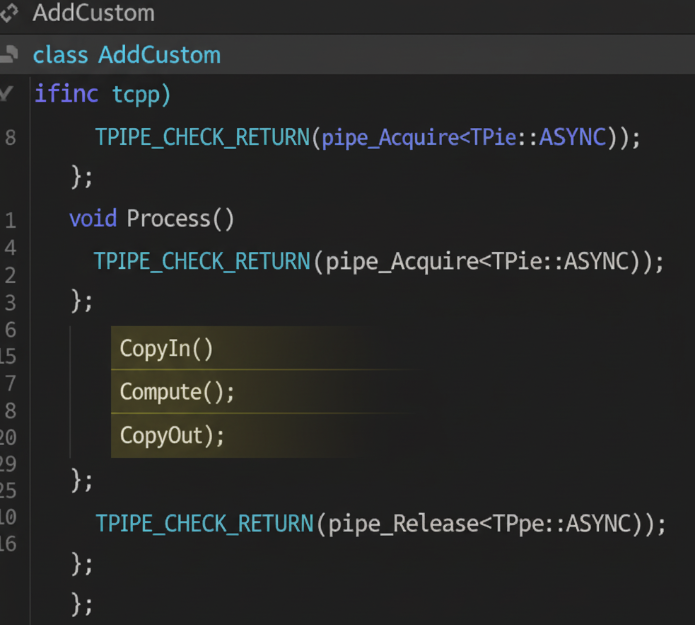
3.2 编写 add_custom.cpp
下面是完整的核函数实现代码,它完美地体现了“数据搬入 -> 计算 -> 数据搬出”的三段式流水线思想。
#include "kernel_operator.h"
#include "add_custom_tiling.h"
using namespace AscendC;
// 核函数入口
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, TilingData* tiling) {
KernelAdd op;
op.Init(x, y, z, tiling);
op.Process();
}
class KernelAdd {
public:
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, TilingData* tiling) {
this->blockLength = tiling->blockLength;
this->totalLength = tiling->totalLength;
xGm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(x), this->totalLength);
yGm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(y), this->totalLength);
zGm.SetGlobalBuffer(reinterpret_cast<__gm__ half*>(z), this->totalLength);
pipe.InitBuffer(xLocal, this->blockLength);
pipe.InitBuffer(yLocal, this->blockLength);
pipe.InitBuffer(zLocal, this->blockLength);
}
__aicore__ inline void Process() {
int32_t loopCount = this->totalLength / this->blockLength;
int32_t blockIdx = GetBlockIdx();
int32_t blockNum = GetBlockNum();
for (int32_t i = blockIdx; i < loopCount; i += blockNum) {
CopyIn(i);
Compute();
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress) {
uint32_t offset = progress * this->blockLength;
DataCopy(xLocal, xGm[offset], this->blockLength);
DataCopy(yLocal, yGm[offset], this->blockLength);
}
__aicore__ inline void Compute() {
Add(zLocal, xLocal, yLocal, this->blockLength);
}
__aicore__ inline void CopyOut(int32_t progress) {
uint32_t offset = progress * this->blockLength;
DataCopy(zGm[offset], zLocal, this->blockLength);
}
private:
TPipe pipe;
GlobalTensor<half> xGm, yGm, zGm;
LocalTensor<half> xLocal, yLocal, zLocal;
uint32_t totalLength;
uint32_t blockLength;
};
第四章:是骡子是马拉出来遛遛 —— 编译与测试
代码写完可不算完,我们必须验证它的正确性。
4.1 编译算子
在op_AddCustom的根目录下,CANN已经为我们准备好了build.sh脚本。我们只需执行它:
bash build.sh
4.2 单算子验证(ST Test)
CANN提供了强大的单算子测试框架。我们只需进入 op_AddCustom/testcases/st/ 目录,执行Python脚本即可自动完成精度对比测试。
cd op_AddCustom/testcases/st/ && python3 st_test.py
如果终端最后打印出测试通过的字样,那么恭喜你!你已经成功地创造并验证了自己的第一个AI算子!
第五章:总结与展望
回顾整个过程,我们从一个简单的Add算子出发,完整地体验了昇腾CANN算子开发的标准流程。掌握了它,就等于拿到了打开CANN算子开发世界大门的钥匙。接下来,我们可以挑战更复杂的算子,学习更高级的性能优化技巧。
与我同行,共赴CANN星辰大海!
这次的分享只是我在2025年昇腾CANN训练营第二季学习中的一篇笔记。这个训练营真的干货满满,基于CANN开源开放全场景,推出了0基础入门系列、码力全开特辑、开发者案例等专题课程,无论你是哪个阶段的开发者,都能找到适合自己的路径,快速提升算子开发技能。
更棒的是,获得Ascend C算子中级认证,即可领取精美证书;完成社区任务更有机会赢取华为手机、平板、开发板等丰厚大奖!
如果你也对AI底层技术充满好奇,渴望亲手打造高性能的AI算子,那么不要犹豫,快来加入我们吧!
报名链接: https://www.hiascend.com/developer/activities/cann20252
希望这篇详细的实战笔记能对你有所帮助。让我们在训练营里相见,共同进步,创造更多可能!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)