
鸿蒙 PC使用ohos-pip-autosign激活自动签名工具,安装第三方库glom实现Python处理多层嵌套字典/列表/对象的工具库
欢迎加入开源鸿蒙PC社区:https://harmonypc.csdn.net/
欢迎在PC社区平台申请新建项目:https://atomgit.com/OpenHarmonyPCDeveloper
AtomGit 仓库地址:https://atomgit.com/OpenHarmonyPCDeveloper/ohos_python_numpy
1. 环境搭建:
本文介绍在鸿蒙 PC+CodeArts IDE 搭建 Python 开发环境。借助鸿蒙专属包管理器 Harmonybrew 安装适配版 Python,搭配 ohos-pip-autosign 自动签名工具,解决系统对动态库的签名限制。通过虚拟环境隔离依赖,以 NumPy 完成安装与脚本测试,成功解决权限报错,搭建出可用的 Python 开发环境。
可以参考以下文章OpenHarmony 鸿蒙 PC + CodeArts IDE 实现 Python开发完整开发环境搭建指南
glom 库完整详解 + 无报错可运行 Demo
一、glom 是什么
glom 是 Python 专门处理多层嵌套字典/列表/对象的工具库。
原生 Python 取深层嵌套数据会大量写 if 判断、多层 .get(),代码臃肿、极易报 KeyError/IndexError;
glom 用统一路径表达式一键提取、转换、重组复杂嵌套结构,自动容错、支持默认值、筛选、格式化、重构数据。
核心作用
- 安全读取多层嵌套字典/列表,不用层层判空,避免报错
- 支持数组索引、切片、过滤、循环取值
- 提取同时转换数据类型、重命名字段、拼接组合字段
- 把杂乱嵌套 JSON 扁平化、重组为自定义结构
- 接口返回复杂响应、MongoDB 嵌套文档、爬虫 JSON 专用
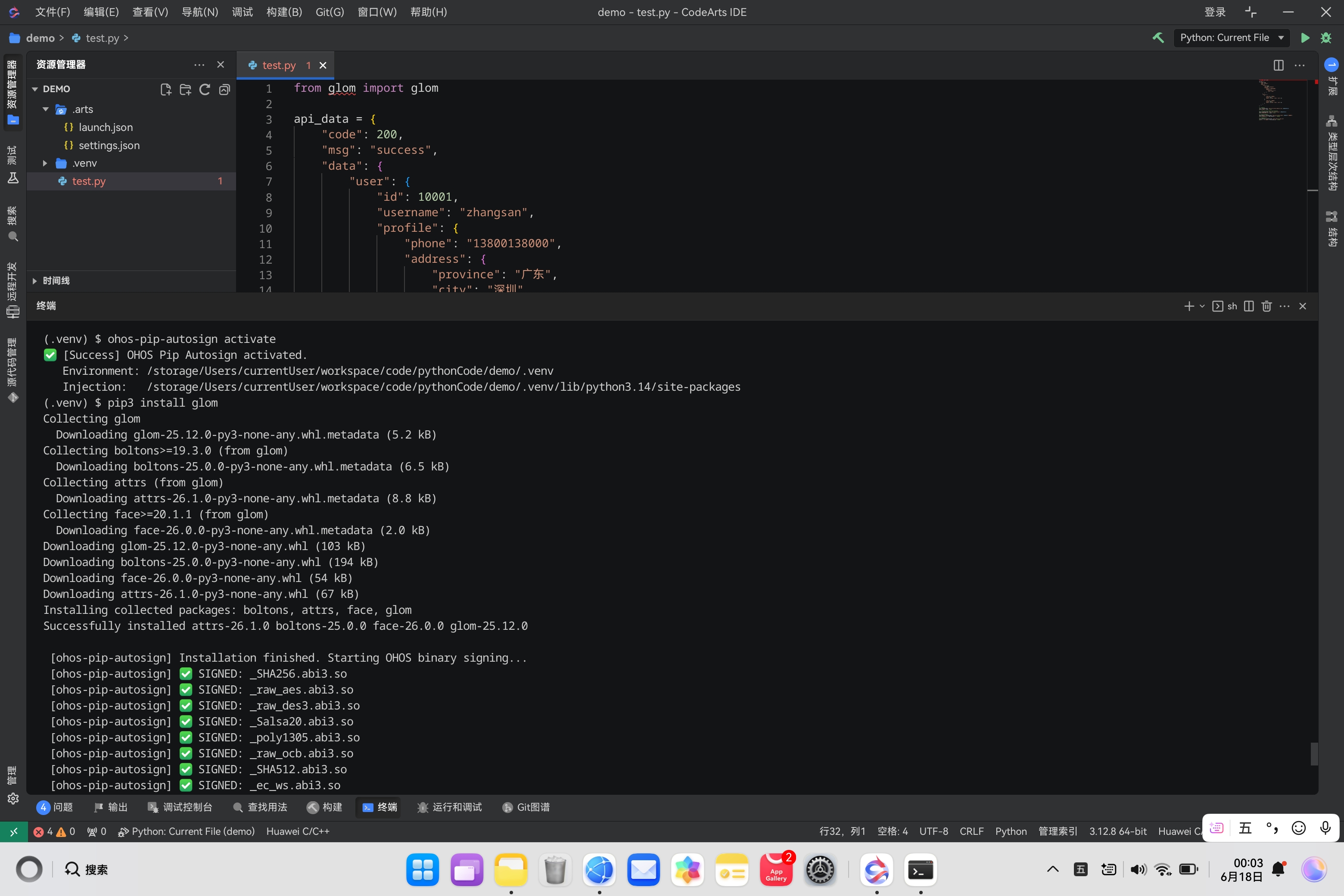
安装
pip install glom
基础语法
from glom import glom, T, Coalesce, Iter, Flatten, Assign
# glom(数据源, 提取规则, default=默认值)
result = glom(data, "a.b.c", default=None)
T:代表当前遍历对象Coalesce:多路径择优取值(第一个不为空)Iter:遍历列表批量提取字段Flatten:扁平化嵌套数组Assign:新增/覆盖字段
完整无报错 Demo 合集
准备统一测试数据(复杂嵌套字典+数组,模拟后端接口返回)
# 模拟接口返回的复杂嵌套JSON
api_data = {
"code": 200,
"msg": "success",
"data": {
"user": {
"id": 10001,
"username": "zhangsan",
"profile": {
"phone": "13800138000",
"address": {
"province": "广东",
"city": "深圳"
}
}
},
"orders": [
{
"order_id": "ORD001",
"price": 99.9,
"goods": [{"name": "手机", "num": 1}]
},
{
"order_id": "ORD002",
"price": 199.0,
"goods": [{"name": "耳机", "num": 2}]
}
]
}
}
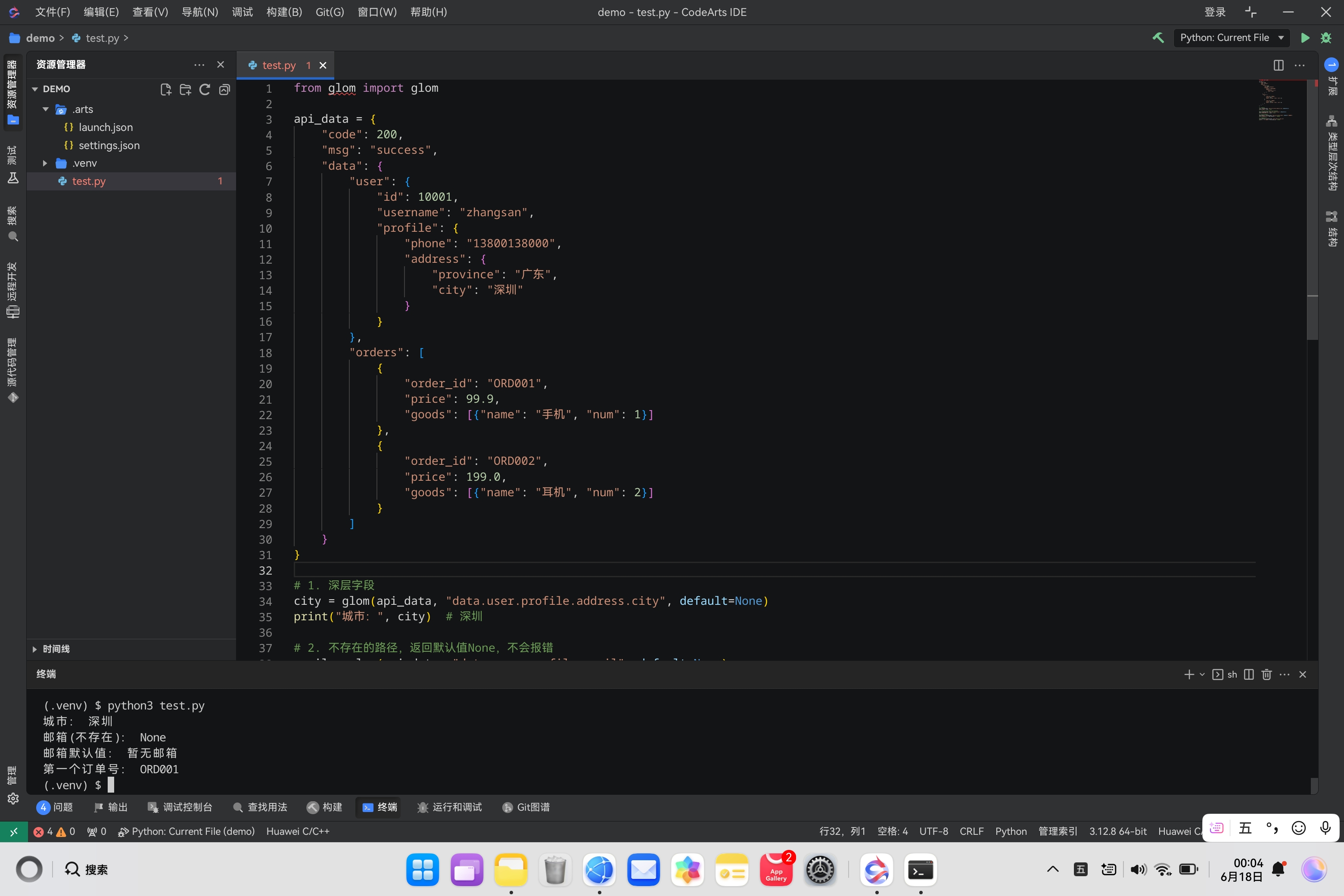
Demo1:基础多层安全取值(替代多层 get,支持默认值防报错)
原生写法又长又容易报错:
# 原生臃肿写法
data = api_data.get("data", {})
user = data.get("user", {})
profile = user.get("profile", {})
city = profile.get("address", {}).get("city")
print(city)
glom 极简写法,路径字符串直接穿透层级,缺失返回默认值不抛错:
from glom import glom
# 1. 深层字段
city = glom(api_data, "data.user.profile.address.city", default=None)
print("城市:", city) # 深圳
# 2. 不存在的路径,返回默认值None,不会报错
email = glom(api_data, "data.user.profile.email", default=None)
print("邮箱(不存在):", email) # None
# 3. 指定自定义默认值
email_default = glom(api_data, "data.user.profile.email", default="暂无邮箱")
print("邮箱默认值:", email_default) # 暂无邮箱
# 4. 取数组指定下标
first_order_id = glom(api_data, "data.orders.0.order_id")
print("第一个订单号:", first_order_id) # ORD001
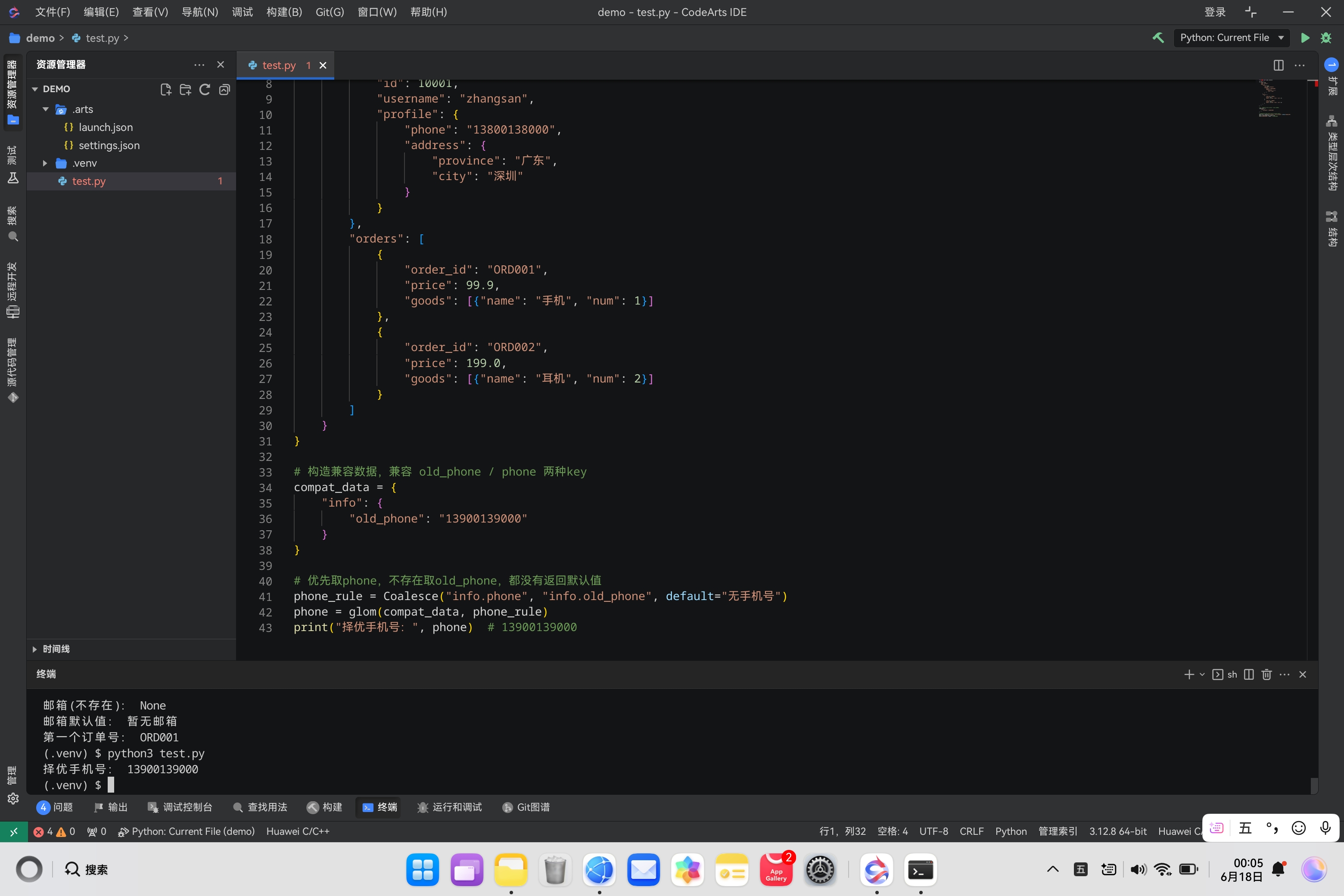
Demo2:Coalesce 多路径择优取值(多个字段任选第一个有值的)
适合同一含义字段存在多个key兼容场景
from glom import glom, Coalesce
# 构造兼容数据,兼容 old_phone / phone 两种key
compat_data = {
"info": {
"old_phone": "13900139000"
}
}
# 优先取phone,不存在取old_phone,都没有返回默认值
phone_rule = Coalesce("info.phone", "info.old_phone", default="无手机号")
phone = glom(compat_data, phone_rule)
print("择优手机号:", phone) # 13900139000
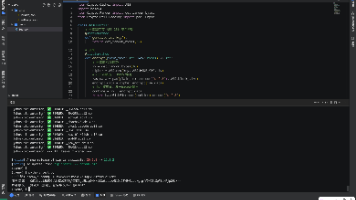
Demo3:Iter 遍历数组批量提取列表字段(爬虫/订单列表高频)
批量提取数组内每一项指定字段,自动生成列表,无需for循环:
请添加图片描述
Demo4:Flatten 扁平化多层嵌套数组
处理二维嵌套列表,摊平为一维数组:
from glom import glom, Iter, Flatten
# 提取所有商品名称,goods是子数组,需要扁平化
goods_name_rule = Flatten(Iter("data.orders").map("goods")).map("name")
all_goods = glom(api_data, goods_name_rule)
print("全部商品名(扁平化):", all_goods) # ['手机', '耳机']
Demo5:一次性重组多字段,输出自定义结构(最常用业务场景)
一次提取多个分散层级字段,直接组装成新字典,不用分步赋值:
from glom import glom
# 定义输出结构,key自定义,value写路径
user_info_rule = {
"uid": "data.user.id",
"nickname": "data.user.username",
"tel": "data.user.profile.phone",
"location": "data.user.profile.address.province + '-' + "data.user.profile.address.city"
}
user_info = glom(api_data, user_info_rule)
print("重组用户信息:")
print(user_info)
# 输出:
# {
# 'uid': 10001,
# 'nickname': 'zhangsan',
# 'tel': '13800138000',
# 'location': '广东-深圳'
# }
Demo6:T 对象动态取值、数据转换、计算
T 代表当前遍历对象,可调用方法、做简单运算、类型转换:
from glom import glom, T, Iter
# 1. 数值运算:订单价格翻倍
price_double = glom(api_data, Iter("data.orders").map(T["price"] * 2))
print("价格翻倍:", price_double) # [199.8, 398.0]
# 2. 字符串拼接
full_name = glom(api_data, T["data"]["user"]["username"].upper() + "_user")
print("拼接用户名:", full_name) # ZHANGSAN_user
# 3. 类型转换 转字符串
str_id = glom(api_data, str(T["data"]["user"]["id"]))
print("id转为字符串:", str_id, type(str_id))
Demo7:Assign 新增字段、补充数据到结果
提取原有数据同时追加自定义字段:
from glom import glom, Assign, Iter
rule = Iter("data.orders").map(
Assign({
"order_id": "order_id",
"price": "price",
"tag": "电商订单" # 新增固定字段
})
)
res = glom(api_data, rule)
print("新增tag字段:")
print(res)
# [
# {'order_id': 'ORD001', 'price': 99.9, 'tag': '电商订单'},
# {'order_id': 'ORD002', 'price': 199.0, 'tag': '电商订单'}
# ]
Demo8:空数据容错测试(完全不会抛 KeyError / IndexError)
极端缺失结构,全部返回默认值,程序稳定不崩溃:
from glom import glom
empty_data = {"code": 404, "msg": "无数据"}
# 深层不存在路径,指定默认值
none_user = glom(empty_data, "data.user.id", default=0)
print("空数据用户ID默认0:", none_user)
# 数组不存在,返回空列表
empty_order_list = glom(empty_data, Iter("data.orders").map("order_id"), default=[])
print("空订单数组:", empty_order_list) # []
业务使用场景
- HTTP 接口响应解析:后端请求第三方API,快速提取多层嵌套返回值
- 爬虫数据清洗:JSON 网页响应扁平化、提取目标字段
- MongoDB 查询结果处理:嵌套文档批量提取字段
- 配置文件读取:多层yaml/json配置安全读取
- 数据转换导出:把复杂嵌套结构重组为数据库入库字段
核心优势总结
- 彻底消灭多层
.get()嵌套,代码极简可读性高 - 内置默认值机制,不会抛出 KeyError / IndexError
- 原生支持数组遍历、扁平化、多字段重组
- 内置
T表达式支持运算、字符串方法、类型转换 - 一站式完成「取值+转换+重组」,无需分步处理
注意事项
- 路径字符串用
.分隔层级,数组下标直接.数字 - 所有场景建议加上
default=,保证缺失数据不报错 - 遍历列表必须配合
Iter,多层子数组用Flatten摊平 T对象仅在 map/循环场景用于动态操作字段- 复杂多字段组装直接传入字典作为规则,一步生成目标结构

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)