
一天一个昇腾 Agent-Skills 小技巧:实现 SAM 3.1 模型的 Ascend OM 路线适配
背景概述
SAM 3.1 是一个典型的经典深度学习模型系统,其推理链路涉及文本、视觉、目标定位(Grounding)、视频追踪以及记忆(Memory)更新等多个模块。针对这类模型的昇腾推理适配,关键不仅在于生成单个 ONNX 或 OM 模型文件,更在于梳理真实的业务入口,识别具有实际价值的高效子图,并确保生成的产物能够稳定地接回原有的处理流程。
本文介绍的昇腾 Agent Skills 主要面向经典深度学习模型的适配需求,提供了一套完整的工作流程,涵盖从源码分析、候选识别、ONNX 与 ATC 转换,到最终接回验证的各个环节。借助这一工作流,针对 SAM 3.1 模型成功开展了 Ascend OM 路线的适配实践,顺利打通了基于文本提示的视频分割主路径,并在此基础上沉淀出一条可复用、且能够持续演进的智能化部署路径。
SAM 3.1 官方结构图
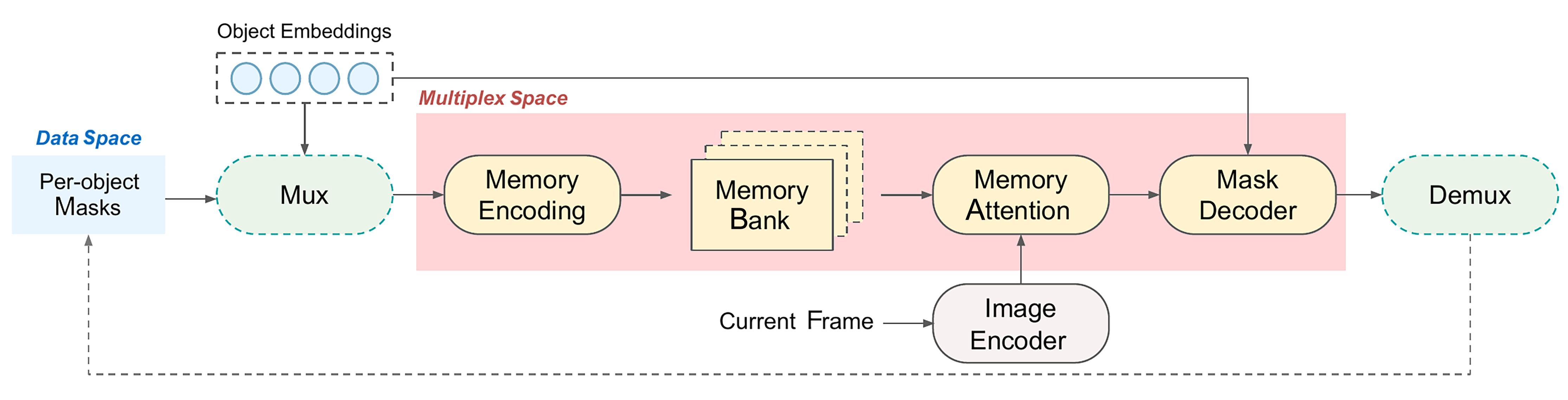
图 1 SAM 3.1 掩码预测流程(Pipeline)概述
该图展示了一种用于处理给定输入中目标嵌入的模型架构。整体流程被划分为两个主要空间:数据空间与复用空间。
- 数据空间:在该空间中,逐目标掩码被应用于目标嵌入,并将处理后的结果传递至下一阶段。
- 复用空间:该空间包含多个协同工作的组件,具体说明如下:
- 复用器(Mux):将目标嵌入与逐目标掩码进行组合,以供后续处理使用。
- 记忆编码模块:对记忆信息进行编码,并存储由此产生的相关数据表征。
- 记忆库:用于存放上一阶段编码所得到的记忆表征。
- 记忆注意力机制:根据当前上下文,有选择地关注记忆库中的相关信息。
- 图像编码器:对当前帧图像进行编码,为后续处理提供特征表示。
- 掩码解码器:对处理过程中生成的掩码信息进行解码。
- 解复用器(Demux):将系统的最终输出进行拆分,并分别传递给下游的不同任务或组件。
该系统的各组成部分按顺序协同工作,依次对目标嵌入和记忆表征进行处理与注意力建模,从而实现对视觉数据的有效编码与解码。
结构流程图清晰地展示了 SAM 3.1 在视频场景下的核心计算链路,也为本次适配过程中模块拆分、子图规划以及主路径的接回提供了直观的参考依据。
本次适配取得的主要成果如下:
- 完成了从 SAM 3.1 源码入口分析到 ONNX / OM 模型产出的完整适配流程。
- 明确了文本编码、视觉骨干网络(Backbone)、目标定位(Grounding)、特征传播(Propagation)、掩膜记忆(Mask Memory)等关键模块的部署边界。
- 形成了"多个 OM 模型 + 原始编配层(Orchestration)"的接回方案。
- 打通了基于文本提示的视频分割主路径,为后续图融合与进一步性能优化工作奠定了良好基础。
核心主线:基于 Agent Skills 的端到端适配实践
针对上述挑战,本次适配不再采用传统的手工切图摸索,而是基于 Agent Skills 提供的一套完整工作流。我们将复杂的适配过程抽象为四个核心阶段,通过 deployer、adapter 和 atc-pipeline 三个核心 Skill 的协同工作,沿着 SAM 3.1 的真实推理路径,逐步完成端到端的昇腾 OM 迁移。
阶段 1:全局入口盘点与候选拆解(核心介入:ascend-om-deployer)
功能定位与核心能力
作为主编排 Skill,ascend-om-deployer 负责梳理 SAM 3.1 的目标功能范围、明确真实的推理入口,并整理候选子图集合。它能够识别模型的真实推理入口(而非仅关注单个模块的 forward() 方法),并将庞大的模型拆分为可供分阶段推进的候选单元,形成可持续推进的适配闭环。
迁移实践落地:确认输入场景与圈定优先模块
适配工作从 predictor 入口出发,我们首先梳理用户实际调用的业务主路径,明确本次需优先覆盖的核心流程。以下以官网 dog.gif 连续视频样例作为验证案例,展示主路径输入与多帧传播输出之间的对应关系。构建流程为:predictor → 初始化视频状态 → 添加文本提示 → 初始化目标掩码 → 多帧传播 → 输出逐帧目标掩码。
主路径确认后,进一步梳理共享主干(Backbone)、Grounding、传播解码等关键模块,从中优先选取边界清晰、复用度高、对主路径打通价值最大的部分,纳入首批适配范围。

图 2 左侧为官网 dog.gif 第 20 帧原始输入(含原视频自带字幕),右侧为同一帧的 OM 连续跟踪结果。
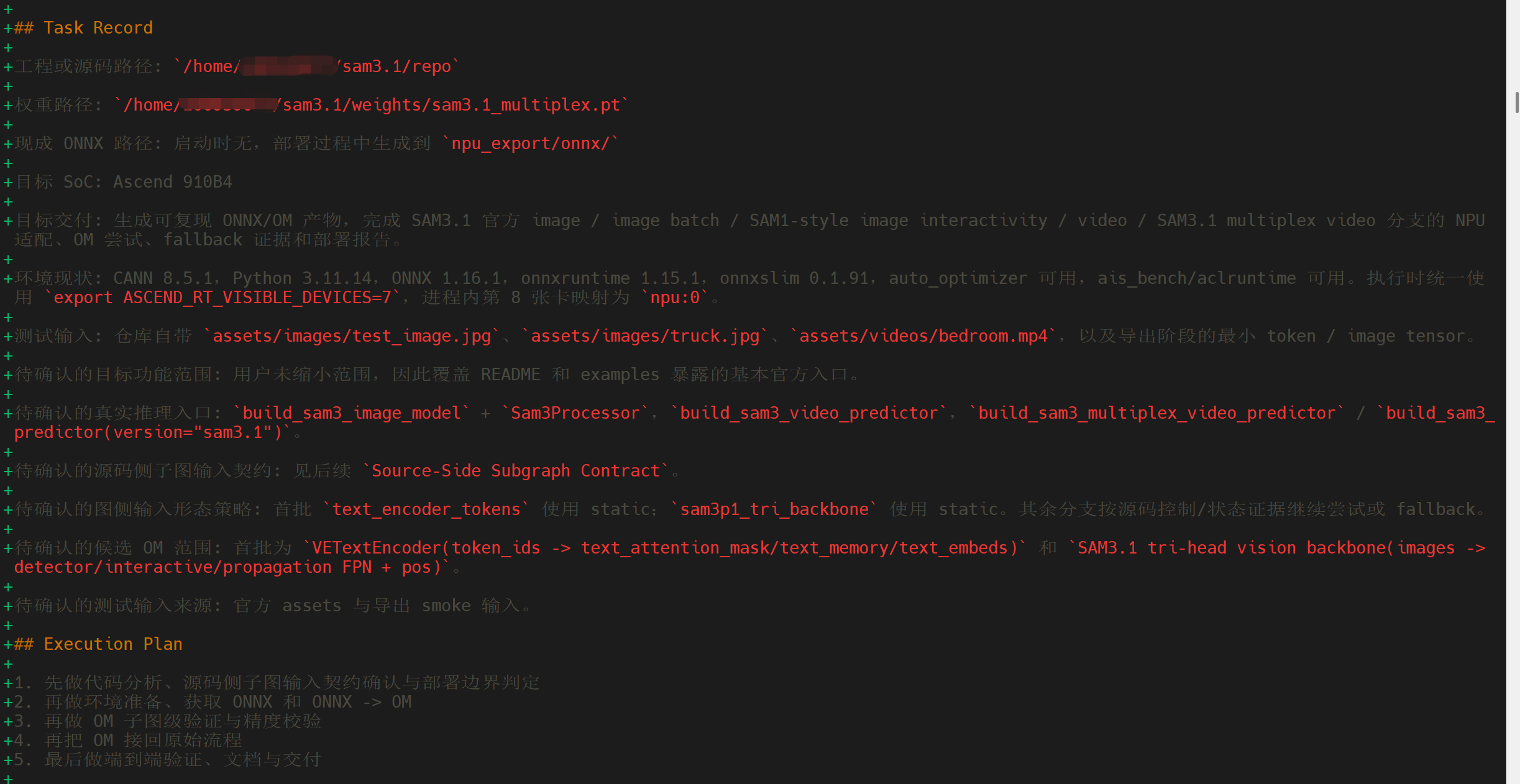
图 3 Task Record 中记录了权重、测试输入、目标 SoC 以及执行计划,有助于后续定位适配边界与生成产物。
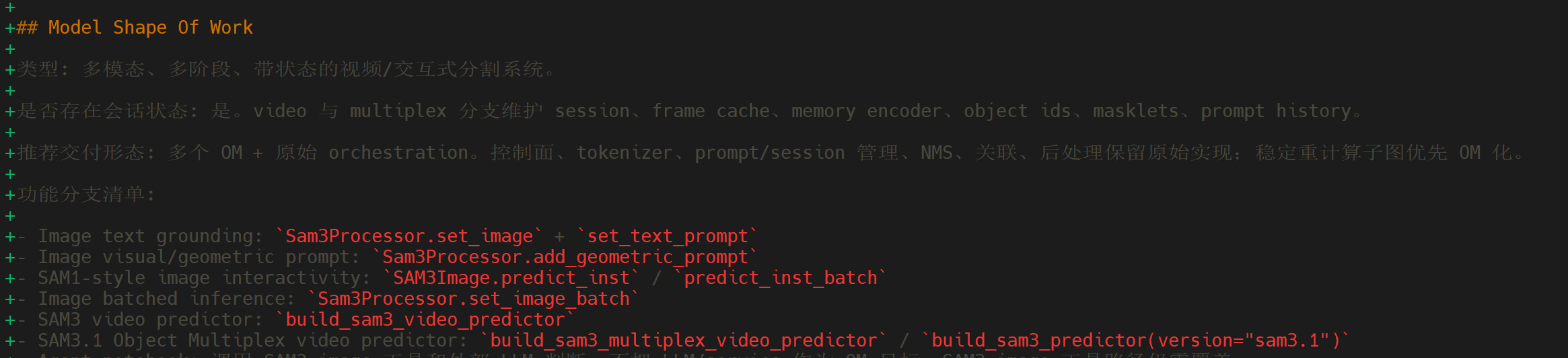
图 4 对模型功能入口进行全面盘点,明确本次适配聚焦的主路径范围。
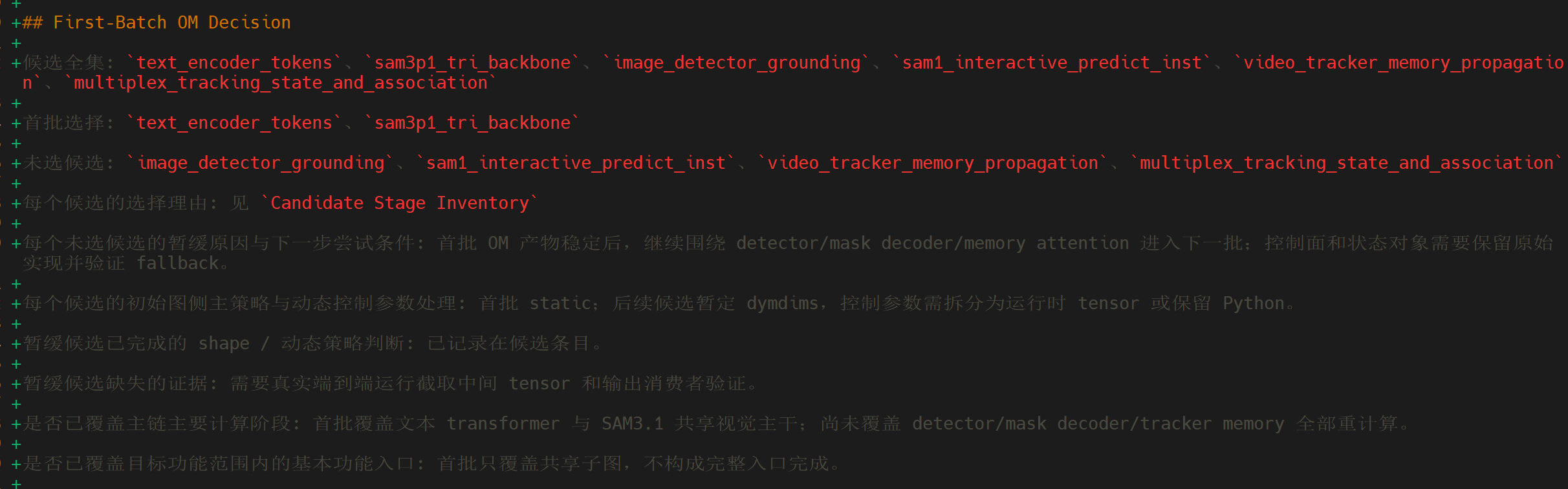
图 5 对候选模块进行分批决策,优先推进对主路径打通贡献最大的部分。
阶段 2:源码契约识别与边界划分(核心介入:ascend-om-pipeline-adapter)
功能定位与核心能力
该阶段主要负责从源码层面梳理每个候选子图的真实输入输出契约、替换点及其下游依赖关系。ascend-om-pipeline-adapter 能够精准识别用户实际调用的入口路径,判断各类输入的来源(Prompt、图像特征或状态对象),并区分哪些逻辑属于可重计算的子图,哪些属于 Python 控制面部分,输出具有可导图、可接回、可验证特性的候选边界。
关键适配范围与边界界定
在本次适配中,我们做出了以下关键的软硬件边界判断:tokenizer、session、frame cache、object id 以及 prompt 管理等功能继续保留在原始 Python 环境中实现。而以下模块优先作为稳定重计算的候选模块进入图计算:
- Text Encoder(文本编码):负责将 tokenizer 处理后的 token_ids 转换为后续 Grounding 所需的文本特征。将字符串处理留在 Python 侧,张量计算走 ONNX/OM。这样输入输出边界清晰,避免了图内复杂字符串操作的潜在问题,也为将来评估"文本特征前置缓存"留有余地。
- Tri Backbone(视觉主干):采用 TriHead ViTDet 视觉骨干网络,为后续多条路径提供共享的视觉特征。作为计算最密集的视觉重计算部分,优先纳入 OM 模型候选。
- Detector / Grounding(目标定位):根据文本提示在图像特征上完成目标检测与分割。本次优先聚焦于纯文本引导的主场景,打通最核心业务路径,暂不一次性覆盖所有交互模式。
- Propagation Decoder(传播解码器):依据当前帧特征与前一阶段目标信息预测掩码。作为视频主路径的关键候选推进适配,优先保证其能顺利接回 predictor 并支持多帧传播。
- Mask Memory Encoder(掩码记忆编码器):负责将当前帧的预测结果写回记忆库。本次保留了外层的会话与状态管理,仅将其中重计算部分作为候选导出,降低对原始控制逻辑的侵入。
核心能力
- 识别用户实际调用的入口路径,理清执行流程。
- 判断各类输入的来源:哪些来自文本提示(Prompt),哪些来自图像特征,哪些来自状态对象。
- 区分哪些逻辑属于可重计算的子图,哪些属于 Python 控制面部分。
- 输出具有可导图、可接回、可验证特性的候选边界。
本次适配中的关键判断
- tokenizer、session、frame cache、object id 以及 prompt 管理等功能继续保留在原始 Python 环境中实现。
- 文本编码、视觉骨干网络、传播解码器(Propagation Decoder)以及掩码记忆编码器(Mask Memory Encoder)优先作为稳定重计算的候选模块。
- Grounding 模块以纯文本主场景为切入点,先完成一版基础适配,暂不一次性覆盖所有交互模式。
- 其他交互方式及扩展分支,将作为后续演进方向继续记录和规划。
阶段 3:从 ONNX 到 OM 的工具链闭环(核心介入:ascend-onnx-atc-pipeline)
功能定位与核心能力
本阶段负责对阶段二圈定的每个候选子图完成 ONNX 导出、优化、ATC 转换以及基本正确性验证,形成完整的工具链闭环。它能够执行 ONNX 完整性检查与最小化探针测试,使用 onnxslim、auto_optimizer 等工具进行图结构修补,并完成 ATC 转换。
迁移实践落地:生成 ONNX / OM 产物
针对首批候选模块,我们按照统一流程依次完成 ONNX 导出、图优化、ATC 转换与基础验证。通过这套标准流水线,不仅将工具链相关问题、模型边界条件分层记录,还生成了稳定可复用的 ONNX / OM 产物,为后续集成奠定稳定基础。
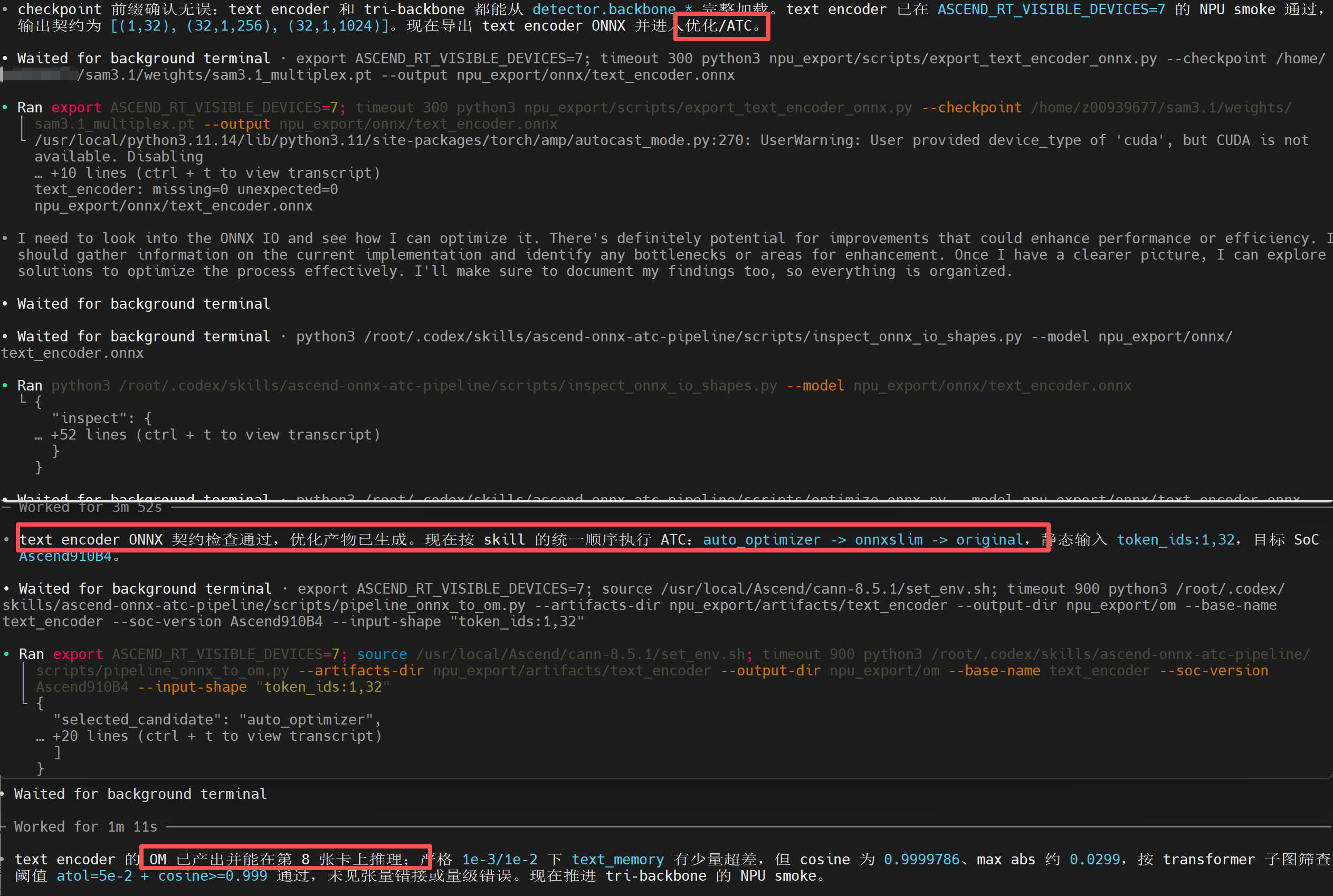
图 6 以首批模块为例,展示从 ONNX 导出到 OM 生成的完整流程及基础验证结果。
阶段 4:接回原始推理流程与主路径闭环验证(核心协同)
迁移实践落地:制定接回策略与最终验证
获得 OM 产物后,将其逐步接回原始 predictor 推理流程。接回过程严格遵循在阶段二中确认的契约原则:
- Python 负责控制面与状态管理:保持灵活的流程编排与数据流转能力。
- OM 负责计算密集型模块:将稳定的重计算部分卸载至昇腾硬件执行,充分利用 NPU 算力。
- 适配边界保持清晰可追踪:便于后续按需扩大覆盖范围。
在主路径接回后,我们进一步对官网 dog.gif 连续视频样例进行验证,确认文本提示能够稳定传导到多帧传播阶段,并持续输出对应的目标掩码。至此,输入、关键运行过程和目标输出效果形成完整闭环。

图 7 官网 dog.gif 连续视频样例的多帧传播跟踪结果示例:左图、中图、右图分别为第 20、40、60 帧的 OM 输出,可见场景中的多只 dog 在后续帧中均被持续保留,目标掩码与检测框的对应关系清晰。
总结与展望
目前,这套基于 Agent-Skills 的工作流已经可以为 SAM 3.1 这类经典深度学习模型提供从入口梳理、候选识别、ONNX/ATC 转换到主路径接回的完整适配路径,为传统模型在昇腾(Ascend)OM 环境下的部署提供了一条可复用的参考方案,使适配效率从周级提升至天级。
本次实践的另一个重要意义在于,通过 Agent Skills 将复杂的适配工作拆解为可执行、可复用、可持续演进的工作流程,帮助开发者更快地完成模型适配。在此基础上,后续还可以围绕子图合并、边界优化以及整体运行效率进行更深入的优化,为进一步提升部署效果提供参考。
社区共建:欢迎开发者贡献 skills,共同完善昇腾生态。开源地址:https://gitcode.com/Ascend/agent-skills

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)