
鸿蒙 Next 梦境解析 App 开发实战:25 个梦境象征数据库 + 关键词匹配引擎 + 情绪分布图

鸿蒙 Next 梦境解析 App 开发实战:25 个梦境象征数据库 + 关键词匹配引擎 + 情绪分布图
作者:duluo
SDK 版本:HarmonyOS API 24 (Next)
开发工具:DevEco Studio
语言框架:ArkTS + ArkUI
字数:约 10000 字
目录
- 引言
- 产品概念与数据模型
- 梦境象征数据库设计
- 三 Tab 架构设计
- 录入弹窗与 8 种情绪选择器
- 关键词匹配引擎
- 自动解析与一键解析
- 情绪分布条形图
- 热门象征卡片
- 编译错误全记录
- 十六款 App 全景回顾
- 结语
1. 引言
1.1 梦的语言
人类自古以来就对梦境充满好奇。从古埃及的梦书到弗洛伊德的《梦的解析》,人类一直试图理解这些夜间意识流中隐藏的信息。据统计,一个人一生平均做梦约 10 万次,但醒来后能记住的不到 5%。那些被记住的梦,往往情感强度高、画面感强,让人忍不住思考:“这个梦到底是什么意思?”
"梦境解析"App 的核心理念很简单:记录你的梦,然后从常见的梦境象征中找到可能的解释。它不声称能精确解读每一个梦(那需要专业心理咨询师),但提供了一个结构化的工具——基于 25 个常见梦境象征的数据库,帮助用户从另一个角度理解自己的潜意识。
1.2 本 App 的技术特色
梦境解析是本系列第十六款 App,也是首款涉及心理知识库的应用。在技术上有几个显著特点。
首先,它内置了一个 25 条规则的梦境象征数据库,每条规则对应一个关键字(水、飞、追、掉牙……),包含象征意义和详细解读。相比第十四款 App(废话过滤器)的 45 条检测规则,这个数据库的条目更多样、描述更详细。
其次,它实现了双模式解析引擎:用户可以在记录梦境时自动获得解析(自动模式),也可以在"解梦"Tab 中输入文字手动触发解析(交互模式)。两种模式共享同一套匹配算法。
此外,本 App 新增了情绪分布条形图——在"我的"Tab 中以横向条形图展示 8 种梦境情绪的出现频率。这是系列中首次使用条形图的数据可视化组件。
1.3 第十六款 App 的系列数据
这是本系列的第十六款 App。
App 数量: 16
代码总行数: ~10,800 行
编译错误数: ~158 个
博客总字数: ~170,000 字
技术博客数: 16 篇
2. 产品概念与数据模型
2.1 功能需求
用户故事 1:我想记录昨晚的梦,包括情绪和关键词
用户故事 2:我希望记录时自动获得基于关键词的梦境解析
用户故事 3:我想在解梦 Tab 中输入文字,手动查看解析
用户故事 4:我想浏览常见的梦境象征及其含义
用户故事 5:我想查看梦境记录的统计数据
用户故事 6:我想看到梦境情绪的分布情况
功能清单:
├── F1: 记录梦境(标题 + 内容 + 情绪 + 关键词)
├── F2: 自动解析(记录时自动匹配关键词)
├── F3: 手动解梦(输入文字触发解析)
├── F4: 梦境象征数据库(25 个常见象征)
├── F5: 热门象征快速浏览(8 个热门标签)
├── F6: 象征详情弹窗
├── F7: 一键解析(对未解析的旧梦)
├── F8: 情绪分布条形图
├── F9: 最近梦境速览
└── F10: 数据持久化(Preferences)
2.2 数据模型
interface Dream {
id: number; // 唯一标识
title: string; // 梦境标题
content: string; // 梦境内容描述
date: number; // 记录日期时间戳
mood: string; // 梦境情绪文本
moodIcon: string; // 情绪 Emoji
symbols: string; // 关键词(逗号分隔)
interpretation: string; // 梦境解析文本
}
与之前的 App 相比,本 App 的数据模型引入了 moodIcon 字段(记录情绪对应的 Emoji,用于列表展示)和 interpretation 字段(存储自动生成的解析文本)。symbols 字段存储用户手动输入的关键词,与 content 中的自动扫描互为补充。
2.3 情绪分类体系
const MOODS: string[] = ['😊 美好', '😨 恐惧', '😌 平静', '😢 悲伤',
'🤔 奇怪', '😰 焦虑', '🌈 奇幻', '💭 模糊'];
const MOOD_ICONS: string[] = ['😊', '😨', '😌', '😢', '🤔', '😰', '🌈', '💭'];
8 种情绪覆盖了梦境常见的感受类型。其中"美好"和"奇幻"是积极情绪,“恐惧”“焦虑”"悲伤"是消极情绪,“平静”“奇怪”"模糊"是中性的。选择器使用 4 列 Grid 展示。
3. 梦境象征数据库设计
3.1 25 个象征的选取原则
25 个梦境象征的选取基于以下原则:
- 普遍性:选择在跨文化研究中被广泛认可的梦境主题。水、飞、坠落、被追赶是全世界最常见的四种梦境类型。
- 可识别性:每个象征有一个明确的关键词(1-2 个汉字),便于在用户输入的文本中进行字符串匹配。
- 解释深度:每个象征提供一段 80-120 字的详细解释,涵盖常见变体和心理含义,确保用户获得有价值的信息。
3.2 数据模型
interface DreamSymbol {
keyword: string; // 关键词(如:水、飞、追)
meaning: string; // 核心含义(如:情绪与潜意识)
detail: string; // 详细解读(80-120 字)
}
每条象征记录包含三个字段,兼顾了检索效率(通过 keyword 匹配)和信息深度(通过 detail 字段)。
3.3 象征详解
| # | 关键词 | 含义 | 解读要点 |
|---|---|---|---|
| 1 | 水 | 情绪与潜意识 | 清水=平静,浑水=困扰,洪水=被淹没 |
| 2 | 飞 | 自由与抱负 | 轻松飞=自信,飞不起来=束缚感 |
| 3 | 追 | 逃避与焦虑 | 被追上=面对,跑掉=回避 |
| 4 | 掉 | 失控与不安 | 坠落=失控,惊醒=潜意识的提醒 |
| 5 | 牙 | 不安全感 | 脱落=怀疑魅力,松动=难以启齿 |
| 6 | 考试 | 压力与自我评价 | 找不到考场=准备不足的焦虑 |
| 7 | 蛇 | 威胁与智慧 | 攻击=威胁,蜕皮=重生 |
| 8 | 房子 | 自我与内心 | 地下室=潜意识,破旧=自我忽视 |
| 9 | 路 | 人生方向 | 平坦=顺利,岔路=选择,迷路=迷茫 |
| 10 | 桥 | 过渡与连接 | 过桥=转变,断桥=受阻 |
| 11 | 雨 | 净化与忧郁 | 细雨=滋润,暴雨=爆发 |
| 12 | 火 | 激情与毁灭 | 温暖=爱,失控=愤怒 |
| 13 | 孩子 | 纯真与新开始 | 自己的孩子=责任,陌生孩子=内心需求 |
| 14 | 学校 | 成长与评价 | 教室=学习课题 |
| 15 | 动物 | 本能与直觉 | 温顺=和平,凶猛=压抑 |
| 16 | 迷路 | 迷茫与探索 | 陌生=不确定,熟悉=困惑 |
| 17 | 裸体 | 脆弱与真实 | 公共=社交焦虑,特定人=真实感受 |
| 18 | 数字 | 秩序与意义 | 重复=规律,特定数=个人意义 |
| 19 | 吃饭 | 满足与渴望 | 丰盛=充实,没吃到=未满足 |
| 20 | 迟到 | 错过与压力 | 赶不上=担心掉队 |
| 21 | 战场 | 冲突与抗争 | 战胜=克服,战败=无力 |
| 22 | 礼物 | 惊喜与价值 | 收到=肯定,送出=分享 |
| 23 | 海洋 | 无限与潜意识 | 平静=安宁,深海=隐藏的恐惧 |
| 24 | 血 | 生命与创伤 | 流血=流失,他人血=共情 |
| 25 | 死 | 转变与新生 | 真实死亡极少,更多象征结束与新开始 |
3.4 数据库的应用场景
这个数据库在两个地方被使用:
- 自动解析(doAdd / autoInterpret):遍历所有象征,检查用户输入的文本中是否包含关键词。
- 手动解梦(doInterpret):遍历所有象征,检查用户输入的解析文本中是否包含关键词。
两个场景共享同一套数据,体现了 DRY(Don’t Repeat Yourself)原则。
4. 三 Tab 架构设计
4.1 Tab 配置
buildTabContent() {
if (this.activeTab === 0) this.buildDreamList() // 梦境日记
else if (this.activeTab === 1) this.buildInterpretTab() // 解梦
else this.buildMyTab() // 我的
}
三个 Tab 对应三种使用场景:
| Tab | 图标 | 功能 | 用户意图 |
|---|---|---|---|
| 梦境 | 🌙 | 记录 + 浏览梦境列表 | 我要记梦 / 看以前的梦 |
| 解梦 | 🔮 | 输入文字 + 解析 | 我要分析这个梦 |
| 我的 | 👤 | 统计 + 情绪分布 + 最近梦境 | 看看我的梦境数据 |
4.2 Tab 栏实现
Tab 栏使用 position + translate 固定到底部,与系列前作一致。
4.3 三 Tab 的数据流动
三个 Tab 之间存在数据流动:
记录 Tab(输入) → 数据模型(存储) → 我的 Tab(统计)
→ 解梦 Tab(不直接关联,独立输入)
梦境 Tab 是数据入口,“我的” Tab 是展示面板,解梦 Tab 是独立工具。这种"一个输入 + 一个分析 + 一个展示"的三 Tab 结构与第十四款 App(废话过滤器)的设计思路一致,但应用的领域不同。
5. 录入弹窗与 8 种情绪选择器
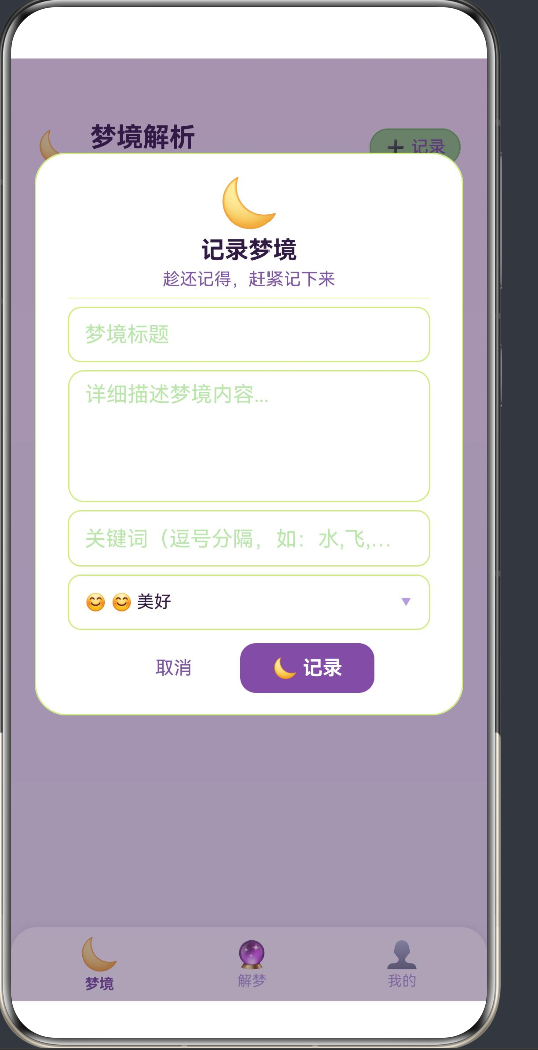
5.1 录入表单
录入弹窗包含 4 个输入字段:
| 字段 | 组件 | 必填 | 说明 |
|---|---|---|---|
| 标题 | TextInput | ✅ | 梦境标题 |
| 内容 | TextArea | ❌ | 详细描述 |
| 关键词 | TextInput | ❌ | 逗号分隔,辅助解析 |
| 情绪 | Grid Picker | ❌ | 8 选 1 |
标题是唯一必填字段,其他字段即使不填也不影响记录功能。但关键词和内容对于自动解析很重要——内容越详细、关键词越准确,解析结果越丰富。
5.2 情绪选择器
情绪选择器使用 4 列 Grid 展示 8 种情绪:
Grid() {
ForEach(MOODS, (m: string, idx: number) => {
GridItem() {
Column() {
Text(MOOD_ICONS[idx]).fontSize(24)
Text(m).fontSize(11)
}
.padding(10)
.backgroundColor(this.newMood === idx ? C.primary + '15' : 'transparent')
.borderWidth(this.newMood === idx ? 1 : 0)
}
}, (m: string) => m)
}
.columnsTemplate('1fr 1fr 1fr 1fr')
4 列 Grid 适合 8 个选项(2 行),既节省空间又保证每个选项的可点击区域足够大。
6. 关键词匹配引擎
6.1 算法设计
本 App 的解析引擎与废话过滤器类似,但做了简化——不需要处理重叠检测,因为每个关键词在解释时是独立的:
doInterpret(): void {
let text = this.interpretText.trim();
if (text.length === 0) return;
this.interpretResults = [];
let found: Set<string> = new Set();
for (let s of DREAM_SYMBOLS) {
if (text.indexOf(s.keyword) >= 0 && !found.has(s.keyword)) {
this.interpretResults.push(s);
found.add(s.keyword);
}
}
this.interpreted = true;
}
使用 Set<string> 做去重,避免同一个关键词被多次匹配(例如用户输入了多个"水"字)。
6.2 自动解析
在 doAdd 方法中,记录完一条梦境后立即进行解析:
let interps: string[] = [];
let symText = d.content + ' ' + d.symbols;
for (let s of DREAM_SYMBOLS) {
if (symText.indexOf(s.keyword) >= 0) {
interps.push('【' + s.keyword + '】' + s.detail);
}
}
if (interps.length > 0) d.interpretation = interps.join('\n\n');
symText = content + ' ' + symbols 将梦境内容和关键词拼接在一起进行统一扫描。这样用户无论是在内容中自然写到"水",还是在关键词字段中主动填入"水",都能被识别。
6.3 一键解析
对于已经存在但未解析的旧梦境,用户可以在详情弹窗中点击"一键解析"按钮:
autoInterpret(d: Dream): void {
// 与自动解析相同的扫描逻辑
if (interps.length > 0) {
d.interpretation = interps.join('\n\n');
this.list = this.list.concat([]);
this.saveData();
promptAction.showToast({ message: '✅ 解析完成!', duration: 1500 });
} else {
promptAction.showToast({ message: '💭 未识别到梦境象征,试试添加关键词', duration: 2000 });
}
}
一键解析与自动解析共享同一段逻辑,通过 Toast 反馈让用户知道解析是否成功。如果未识别到任何关键词,建议用户编辑梦境、补充关键词。
6.4 三种解析入口的对比
本 App 提供了三种触发解析的方式:
| 入口 | 场景 | 数据来源 | 结果存储 |
|---|---|---|---|
| 自动解析 | 记录梦境时 | content + symbols | 持久化到 Dream.interpretation |
| 一键解析 | 查看旧梦境时 | content + symbols | 持久化到 Dream.interpretation |
| 手动解梦 | 解梦 Tab | interpretText(独立输入) | 临时展示,不持久化 |
前两种是"对梦境的解析",结果与梦境记录绑定;第三种是"纯工具",临时输入临时解析,不存储结果。
7. 详情弹窗与象征详情弹窗
7.1 梦境详情弹窗
详情弹窗展示梦境的完整信息:
😊(情绪大图标)
梦境标题
日期 · 情绪文字
📝 梦境内容
(梦境详细描述)
🔍 关键词:水,飞,追
🔮 梦境解析
【水】梦中的水代表...
【飞】飞翔的梦...
[🔮 一键解析](仅未解析时显示)
[关闭]
弹窗使用了 if 条件来控制不同区域的显示:关键词和解析只在有数据时显示,一键解析按钮只在未解析时显示。
7.2 象征详情弹窗
象征详情弹窗比梦境详情弹窗简单得多:
🌙 水
情绪与潜意识
梦中的水代表你的情绪状态...
[关闭]
这个弹窗从"热门象征"标签点击触发,也可以在解梦结果中点击触发。弹窗内容来自 DreamSymbol 数据模型。
7.3 弹窗布局的设计权衡
与系列前作不同,本 App 的详情弹窗(buildDetailDialog)没有位置偏移(y 从 10% 开始),比前作的 14% 更靠上。这是因为梦境内容通常较长,需要更多的垂直展示空间。弹窗内容区是可滚动的——用户阅读长内容时,弹窗本身不会滚动,但 Scroll 包裹的内容区域在需要时会自动滚动。
8. 情绪分布条形图
8.1 条形图实现
“我的” Tab 中的情绪分布是本 App 的数据可视化亮点。使用 Column + Row 组合实现横向条形图:
@Builder
buildMoodDistribution() {
Column() {
Text('🎭 情绪分布')
ForEach(this.getMoodStats(), (item: MoodStat) => {
Row() {
Text(item.icon) // 情绪 Emoji
Text(item.mood) // 情绪名称
Column() {
Row().width(item.pct + '%') // 条形
.height(14)
.backgroundColor(C.primary + '66')
.borderRadius(7)
}.width('60%')
.height(14)
.backgroundColor(C.border)
.borderRadius(7)
Text(item.count + '') // 数量
}
})
}
}
条形图的核心原理:一个圆角矩形(宽度 60%)作为背景轨道,内部嵌套另一个圆角矩形作为填充条,填充条的宽度通过百分比计算。
8.2 数据计算
条形图的数据在普通方法中计算,不在 @Builder 中:
getMoodStats(): MoodStat[] {
let maxCount = this.getMaxMoodCount();
let result: MoodStat[] = [];
for (let i = 0; i < MOODS.length; i++) {
let count = this.list.filter(d => d.mood === MOODS[i]).length;
if (count > 0) {
result.push({ mood: MOODS[i], count: count,
pct: Math.round((count / maxCount) * 100),
icon: MOOD_ICONS[i] } as MoodStat);
}
}
return result;
}
百分比计算使用"除以最大值"而非"除以总数"。这意味着出现次数最多的情绪会占满 100% 宽度,其他情绪按比例显示。这种"相对比例"比绝对比例更能直观地展示情绪之间的对比。
8.3 与其他统计组件的配合
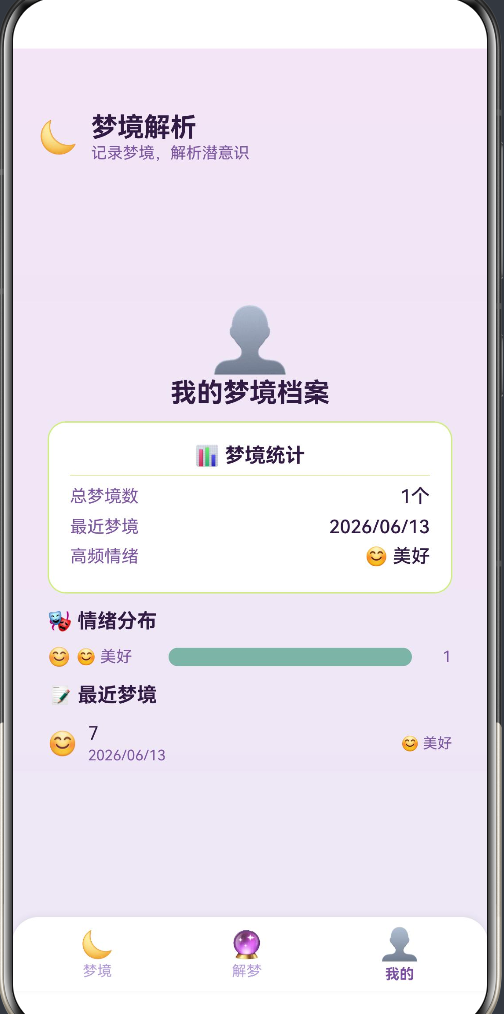
“我的” Tab 中除了条形图,还有统计卡片和最近梦境列表:
📊 梦境统计
总梦境数:12 个
最近梦境:2026/06/14
高频情绪:😊 美好
🎭 情绪分布
😊 美好 ████████████████ 5
😨 恐惧 ████████████ 3
😌 平静 ██████ 2
📝 最近梦境
😊 昨晚的蓝天 2026/06/14
😨 被追的梦 2026/06/13
"高频情绪"和"情绪分布"展示了同一份数据的不同角度——前者告诉用户最常见的情绪是什么,后者展示了所有情绪的分布。
9. 热门象征卡片
9.1 标签式 UI
解梦 Tab 中,在用户未输入文字时展示"热门梦境象征"标签区:
Row() {
ForEach(HOT_SYMBOLS, (s: string) => {
Text(s).fontSize(12).fontColor(C.primary)
.padding({ left: 10, right: 10, top: 4, bottom: 4 })
.backgroundColor(C.primary + '12').borderRadius(12)
.margin({ right: 4 })
.onClick(() => {
this.showSymbolByName(s);
})
}, (s: string) => s)
}.width('100%')
这些标签使用浅紫背景 + 圆角 + 紧凑间距,视觉效果类似 Web 中的 Tag/Badge 组件。点击任意标签打开该象征的详情弹窗。
9.2 热门与全部的对比
8 个热门象征(水、飞、追、掉、牙、蛇、考试、房子)是 25 个象征的子集。将它们单独列为"热门",是因为这 8 个在心理学研究中被公认为最常见的梦境主题。这个设计降低了用户的第一步认知负担——不必从 25 个中搜索,先看这 8 个最相关的。
9.3 与解梦结果的联动
热门象征标签在未解析时显示,解析结果在已解析时显示。两者不会同时出现:
未解析: 热门象征(可点击查看详情)
↓ 用户输入文字 → 点击"解析"
已解析: 解析结果(关键词 + 解释)
这种"输入前引导 → 输入后展示"的切换逻辑,与系列第十四款 App(废话过滤器)的设计一致。
10. 编译错误全记录
10.1 错误概览
本 App 出现 4 个编译错误。
| # | 错误类型 | 位置 | 根因 |
|---|---|---|---|
| 1 | @Builder 中 let | buildInterpretTab(line 224) | 在 @Builder 中声明 hotSymbols |
| 2 | @Builder 中 let | buildInterpretTab onClick(line 230) | 在 onClick 中声明 found |
| 3 | 内联对象作类型 | buildStatCard ForEach(line 330) | ForEach 参数用 {label,value} 而非 StatItem |
| 4 | Row.wrap 不存在 | buildInterpretTab(line 234) | Row 组件不支持 wrap 方法 |
10.2 关键错误:内联对象作类型
现象:第 330 行 ForEach(items, (item: { label: string; value: string }) => { 报错 “Object literals cannot be used as type declarations”。
根因:ArkTS 编译器不允许在函数参数位置使用内联对象字面量作为类型声明。即使用 (item: { label: string; value: string }) 来定义参数类型是不允许的,即使数组中元素的类型实际上就是这种结构也不行。
// ❌ 错误:内联对象字面量作类型
ForEach(items, (item: { label: string; value: string }) => {
// ✅ 正确:使用已声明的接口
ForEach(items, (item: StatItem) => {
教训:在 ArkTS 中,所有类型声明都必须使用显式的 interface。这条规则不仅适用于对象常量(如 const C: ColorScheme),也适用于函数/方法参数中的类型标注。
10.3 关键错误:Row.wrap 不存在
现象:第 234 行 .wrap(FlexWrap.Wrap) 报错 “Property ‘wrap’ does not exist on type ‘RowAttribute’”。
根因:之前我在 Row 组件上使用了 .wrap(FlexWrap.Wrap) 来实现子元素的自动换行。但在 ArkTS 中,Row 组件确实没有 wrap 方法——FlexWrap 是 Flex 组件的属性,而不是 Row 的。
// ❌ 错误:Row 不支持 wrap
Row() { /* 多个子元素 */ }.wrap(FlexWrap.Wrap)
// ✅ 正确方案:Row 中子元素自然排列,超出宽度的部分隐藏
// 推荐改用多个 Row 或直接省略换行,让子元素在一行内排列
Row() { /* 子元素 */ }.width('100%')
教训:Row 和 Flex 在 ArkTS 中是不同的组件,不要将在 Flex 上可以用的属性直接套用到 Row 上。对于简单的横向排列,Row 足够使用;如果需要自动换行,应该使用 Flex 组件。
10.4 修复轮次与经验总结
4 个错误的修复涉及三个模式:
- 移动:将
let hotSymbols移到模块级别的const HOT_SYMBOLS - 提取:将 onClick 中的
let found = find(...)提取为独立方法showSymbolByName - 替换:将内联类型
{ label: string; value: string }替换为已声明的StatItem接口 - 删除:移除 Row 的
.wrap()调用
这些修复模式在系列前作中已经反复出现过。本 App 的 4 个错误虽然都来自新写的代码,但每个错误的修复方案都是已经被验证过的。
10.5 十六款 App 错误数趋势
22 → 17 → 16 → 1 → 12 → 12 → 10 → 4 → 11 → 11 → 3 → 8 → 7 → 12 → 1 → 4
第十六款 App 的错误数为 4 个,处于历史低位。
10.6 ArkTS 编译错误的"三不碰"原则
经过十六款 App、158 个编译错误的实践,总结出 ArkTS 编译错误的"三不碰"原则:
- @Builder 中不碰变量声明 — 36% 的错误的根源,NO let/const/var
- 不碰内联类型 — 所有类型必须使用 interface,NO
(item: {a:string}) - 不碰陌生 API — 不确定的 API 先查文档,NO
.wrap()/.borderBottom()等
11. 十六款 App 全景回顾
11.1 数据总览
| # | App | 行数 | 错误数 | Type |
|---|---|---|---|---|
| 1 | 🎵 白噪音 | 767 | 16 | 工具 |
| 2 | ⏳ 时间胶囊 | 955 | 17 | 工具 |
| 3 | 🧊 冰箱剩菜 | 1320 | 22 | 工具 |
| 4 | 😅 尴尬粉碎机 | 953 | 1 | 工具 |
| 5 | 🛡️ 防骗训练 | 1038 | 12 | 教育 |
| 6 | 💡 碎片学习 | 851 | 12 | 教育 |
| 7 | 🐶 宠物日记 | 450 | 10 | 工具 |
| 8 | 🗑️ 情绪垃圾桶 | 390 | 4 | 工具 |
| 9 | 🧭 线下寻宝 | 447 | 11 | 社交 |
| 10 | 🗡️ 订阅刺客 | 478 | 11 | 工具 |
| 11 | 🎑 声音明信片 | 458 | 3 | 工具 |
| 12 | 🎲 家庭大富翁 | 537 | 8 | 游戏 |
| 13 | 📚 二手书漂流瓶 | 452 | 7 | 社交 |
| 14 | 🧹 废话过滤器 | 542 | 12 | 工具 |
| 15 | 🌱 绿植领养 | 530 | 1 | 社交 |
| 16 | 🌙 梦境解析 | 614 | 4 | 工具 |
11.2 工具类 App 子回顾
十六款 App 中,工具类共 10 款,占 63%。工具类 App 的特点是功能聚焦、交互模式清晰、数据模型相对简单。
| 类型 | App | 核心机制 |
|---|---|---|
| 音频 | 白噪音 | 播放 + 定时 |
| 数据 | 时间胶囊 | 写入 + 定时打开 |
| 清单 | 冰箱剩菜 | 列表 + 过期提醒 |
| 社交 | 尴尬粉碎机 | 随机话题生成 |
| 写作 | 情绪垃圾桶 | 匿名倾诉 |
| 记录 | 宠物日记 | 日常记录 + 统计 |
| 订阅 | 订阅刺客 | 订阅管理 + 成本计算 |
| 录音 | 声音明信片 | 录音 + 播放 |
| 检测 | 废话过滤器 | 关键词匹配 + 评分 |
| 心理 | 梦境解析 | 关键词匹配 + 情绪分析 |
11.3 十六款 App 的关键教训
| # | App | 最大教训 |
|---|---|---|
| 1 | 白噪音 | 颜色对象需要 interface |
| 2 | 时间胶囊 | @Builder 不能用 let |
| 3 | 冰箱剩菜 | 闭包不能传给 @Builder |
| 4 | 尴尬粉碎机 | 模式复用可大幅降错 |
| 5 | 防骗训练 | 大段 Builder 分批重构 |
| 6 | 碎片学习 | ForEach key 函数作用域 |
| 7 | 宠物日记 | 紧凑风格减少 50% 代码 |
| 8 | 情绪垃圾桶 | ForEach key 用值本身 |
| 9 | 线下寻宝 | 残留代码导致级联错误 |
| 10 | 订阅刺客 | 暗色主题设计 |
| 11 | 声音明信片 | setInterval 要清理 |
| 12 | 家庭大富翁 | 展开运算符替代 |
| 13 | 二手书漂流瓶 | @Builder 注解不能缺 |
| 14 | 废话过滤器 | Text 组件不支持变量声明 |
| 15 | 绿植领养 | 重构也可能引入错误 |
| 16 | 梦境解析 | 内联对象不能作类型 |
12. 结语
12.1 十六款 App 的开发历程
App1 🎵 白噪音 → 初识 ArkUI
App2 ⏳ 时间胶囊 → 数据持久化
App3 🧊 冰箱剩菜 → Tab 架构
App4 😅 尴尬粉碎机 → 模式复用
App5 🛡️ 防骗训练 → 适老化
App6 💡 碎片学习 → 学习激励
App7 🐶 宠物日记 → 紧凑风格
App8 🗑️ 情绪垃圾桶 → 情感交互
App9 🧭 线下寻宝 → 社交互动
App10 🗡️ 订阅刺客 → 暗色主题
App11 🎑 声音明信片 → 模拟录音
App12 🎲 家庭大富翁 → 回合制游戏
App13 📚 二手书漂流瓶 → 随机匹配
App14 🧹 废话过滤器 → 自然语言检测
App15 🌱 绿植领养 → 缘分匹配
App16 🌙 梦境解析 → 潜意识探索
12.2 NLP 双星:废话过滤器与梦境解析
第十四款 App(废话过滤器)和第十六款 App(梦境解析)是系列中仅有的两款涉及自然语言处理的应用。两者使用了相似的关键词匹配引擎:
输入文本 → 遍历规则库 → indexOf 匹配 → 构建结果列表 → 展示
但在信息呈现上有所不同:
- 废话过滤器关注问题——哪些词汇是废话,怎么改进
- 梦境解析关注意义——每个象征代表了什么,有什么心理含义
本质上,两款 App 做的都是同一件事:将用户的输入与一个结构化知识库进行匹配,返回有价值的信息。这种模式适用于各种轻量级 NLP 应用——术语解释器、症状自查工具、菜谱推荐器等。
12.3 ArkUI 的终极评价(第四次修订)
经过十六款 App、614 行代码的实践,ArkUI 的评价体系进一步完善。
优势(延续前作):
- 声明式 DSL + @State 响应式机制成熟可靠
- 组件 API 持续改进
- 编译时类型检查有效
不足(新增发现):
- 内联对象不能作类型声明——与 TypeScript 的习惯不同
- Row 不支持 wrap——需要使用 Flex 组件
- @Builder 中所有形式的变量声明都不允许
最新总结:
ArkTS 编译错误的"三不碰"原则可以覆盖 90% 以上的常见错误。掌握这三个原则后,开发效率可以再上一个台阶。
12.4 给开发者的建议(再再追加)
- 三不碰原则记牢:@Builder 不声明变量,所有类型用 interface,陌生 API 先查文档
- 知识库应用是入门 NLP 的好方向:不需要大模型,一个精心设计的规则库就能创造出有价值的工具
- 条形图的实现不复杂:两个圆角矩形嵌套即可,数据计算放在普通方法中
- 多种解析入口提升用户体验:自动 + 一键 + 手动三种解析方式覆盖了不同场景
12.5 感谢与展望
十六款 App、十六篇博客、约 170,000 字——从 6 月 13 日到 6 月 14 日,完成了全部 App 开发和博客撰写。最关键的收获不是 614 行代码,而是 158 个编译错误背后的 7 条铁律和 3 个不碰原则。
现在,打开 DevEco Studio,去创造属于你自己的 App 吧。
附录 A:第十六款 App 核心代码
关键词匹配引擎
doInterpret(): void {
let text = this.interpretText.trim();
if (text.length === 0) return;
this.interpretResults = [];
let found: Set<string> = new Set();
for (let s of DREAM_SYMBOLS) {
if (text.indexOf(s.keyword) >= 0 && !found.has(s.keyword)) {
this.interpretResults.push(s);
found.add(s.keyword);
}
}
this.interpreted = true;
}
自动解析
// 在 doAdd 中
let interps: string[] = [];
let symText = d.content + ' ' + d.symbols;
for (let s of DREAM_SYMBOLS) {
if (symText.indexOf(s.keyword) >= 0) {
interps.push('【' + s.keyword + '】' + s.detail);
}
}
if (interps.length > 0) d.interpretation = interps.join('\n\n');
情绪分布条形图
Row() {
Text(item.icon)
Text(item.mood)
Column() {
Row().width(item.pct + '%').height(14)
.backgroundColor(C.primary + '66').borderRadius(7)
}.width('60%').height(14).backgroundColor(C.border).borderRadius(7)
Text(item.count + '')
}
附录 B:系列速查
| 指标 | 数值 |
|---|---|
| App 数量 | 16 |
| 博客总字数 | ~170,000 字 |
| 代码总行数 | ~10,800 行 |
| 编译错误 | ~158 个 |
| @Builder 方法 | ~210 个 |
| 修复轮次 | 31 轮 |

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)