
2026年GPU算力平台选型避坑指南:4个维度帮你省下30%隐性成本
2026年的GPU算力市场,早已不是"有卡就能卖"的草莽阶段。随着RTX 50系、H20、昇腾910B等新老卡型同台竞技,以及裸金属、容器化、Serverless等交付模式不断细分,选平台的逻辑变了——比单价更重要的,是匹配你的业务阶段。
作为从业者,见过太多团队因为"每小时便宜两块钱"选了平台,结果环境配了两天、卡型不对路、扩容还要走采购流程。这篇从实际交付经验出发,总结4个最该关注的维度。
一、卡型覆盖:别只看4090/5090,要看全周期
很多开发者第一次租GPU,直奔RTX 5090。但2026年的AI业务往往是跨场景的:
- AI绘画/视频生成/图形渲染:RTX 5090(32GB)或RTX 6000D(84GB)性价比最高,单卡小时成本2-4元区间;
- 模型推理与微调:H20(96GB)或A100(80GB)更适合,显存带宽和精度支持更稳;
- 大模型训练/分布式计算:需要A100 8卡集群,月租模式更划算;
- 信创/政企项目:昇腾910B2(64GB)或真武810E(96GB)是硬门槛。
选型建议:优先选卡型全的平台。业务从推理切到训练,或从国际主流切到国产替代,不用迁移数据、重建环境。
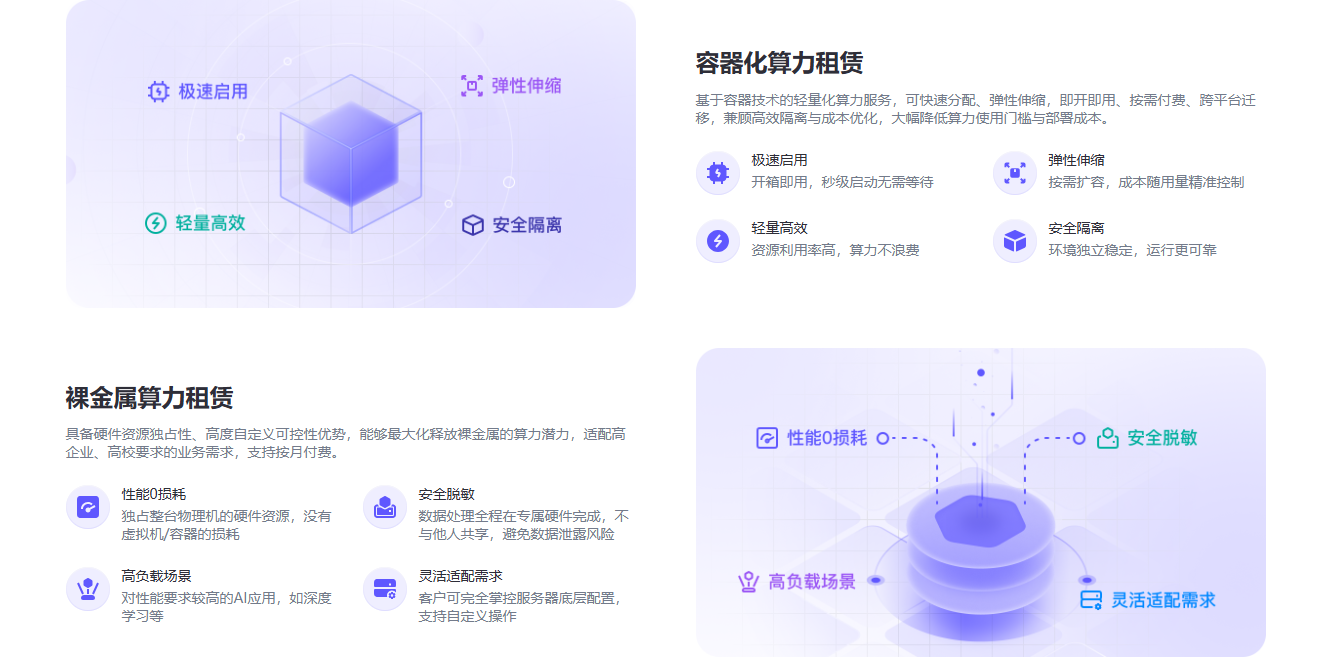
二、交付模式:裸金属 vs 容器化,不是二选一
2026年还在纠结"要不要独占物理机"的团队,往往是没想清楚业务阶段。
|
交付方式 |
适用场景 |
核心优势 |
单价特点 |
|
裸金属 |
大模型训练、企业级部署、数据敏感型业务 |
硬件独占、0虚拟化损耗、安全隔离 |
月租为主,长期摊薄更划算 |
|
容器化 |
开发测试、推理服务、轻量级训练 |
分钟级启动、弹性伸缩、按量付费 |
按时/包周,试错成本极低 |
一个常见误区:训练阶段用容器化省钱,结果多租户争抢带宽,训练任务跑了三天崩了。反过来,推理业务包月租裸金属,业务低谷期卡在那儿吃灰。
正确姿势:选支持双模式切换的平台。训练期上裸金属,推理期切容器化,同一家平台内完成,不用导数据。
三、环境配置:隐性时间成本比租金更贵
这是2026年最该被重视、却最容易被忽略的维度。
租完卡,配CUDA、装PyTorch、调网络、解决驱动冲突——这套流程吃掉你半天是常态。如果团队没有专职运维,可能两天都搞不定。
省时间的核心指标:镜像市场成熟度。
看平台是否预置了:
- 系统镜像:Ubuntu/Debian/CentOS开箱;
- 框架镜像:PyTorch、TensorFlow、DeepSeek等;
- 应用镜像:ComfyUI、Stable Diffusion、LLM推理框架等。
分钟级启动 vs 半天配环境,按研发人力成本折算,后者可能比租金还贵。
四、计费透明:别只看"每小时多少钱"
2026年主流计费模式已经分化得很细:
- 按时计费:适合短期试错、突发任务,灵活但单价略高;
- 包周/包月:适合中长期项目,折扣明显;
- 存储/流量费:部分平台低价引客,但数据进出、云盘扩容另收费,月底账单翻倍。
避坑建议:注册前先看价格页是否完整列出"算力+存储+网络"三项费用。只标算力单价、存储另议的平台,后期对账会很痛苦。
五、2026年选型实战:一张表对号入座
|
你的现状 |
推荐策略 |
关注重点 |
|
个人开发者/小团队,验证想法 |
容器化按时计费,先跑通 |
镜像市场、按量付费 |
|
中小模型推理,7B-70B参数 |
单卡/双卡容器或裸金属 |
显存大小、网络带宽 |
|
大模型训练,A100集群 |
裸金属月租,8卡集群 |
裸金属性能、RDMA网络 |
|
政企/信创项目 |
昇腾910B裸金属 |
国产卡型、合规资质 |
|
需要同时调用云端模型API |
算力+模型API组合 |
平台生态整合能力 |
关于立方云
“立方云”平台致力于为企业及政府客户提供全栈标准化云算力服务。依托覆盖广泛的边缘算力节点,平台将 AI 推理与训练算力无限贴近用户侧部署,提供 GPU 实例、GPU 集群、云存储、AI 大模型市场及低延时专线等核心能力,助力客户快速构建安全、高性能的 AI 基础设施,实现大模型应用从开发到业务落地的全链路敏捷交付。

价格与卡型以各平台实时页面为准。如有选型疑问,欢迎评论区交流。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)