
基于VeRL GPT-OSS-20B MoE模型 DAPO 强化学习训练适配流程
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
随着大语言模型在工业场景的深度应用,GPT-OSS作为一款开源模型,通过创新的注意力机制设计实现掀起了一股新的浪潮,但在昇腾AI平台部署时面临注意力机制适配、显存优化等技术挑战。
本文聚焦GPT-OSS在昇腾平台的高效实现,分享核心技术创新与模型适配实践,为该系列大模型部署提供技术参考。
具体软硬件信息如下:
| 组件 | 版本 |
|---|---|
| vLLM | 0.14.0 |
| vLLM-Ascend | 0.14.0 |
| torch | 2.8.0 + cpu |
| torch-npu | 2.8.0.post2 |
| transformers | 4.57.6 |
| veRL | main |
| CANN | 8.5.0 |
| 设备 | Atlas 800T A2 |
核心技术特性
模型架构总览
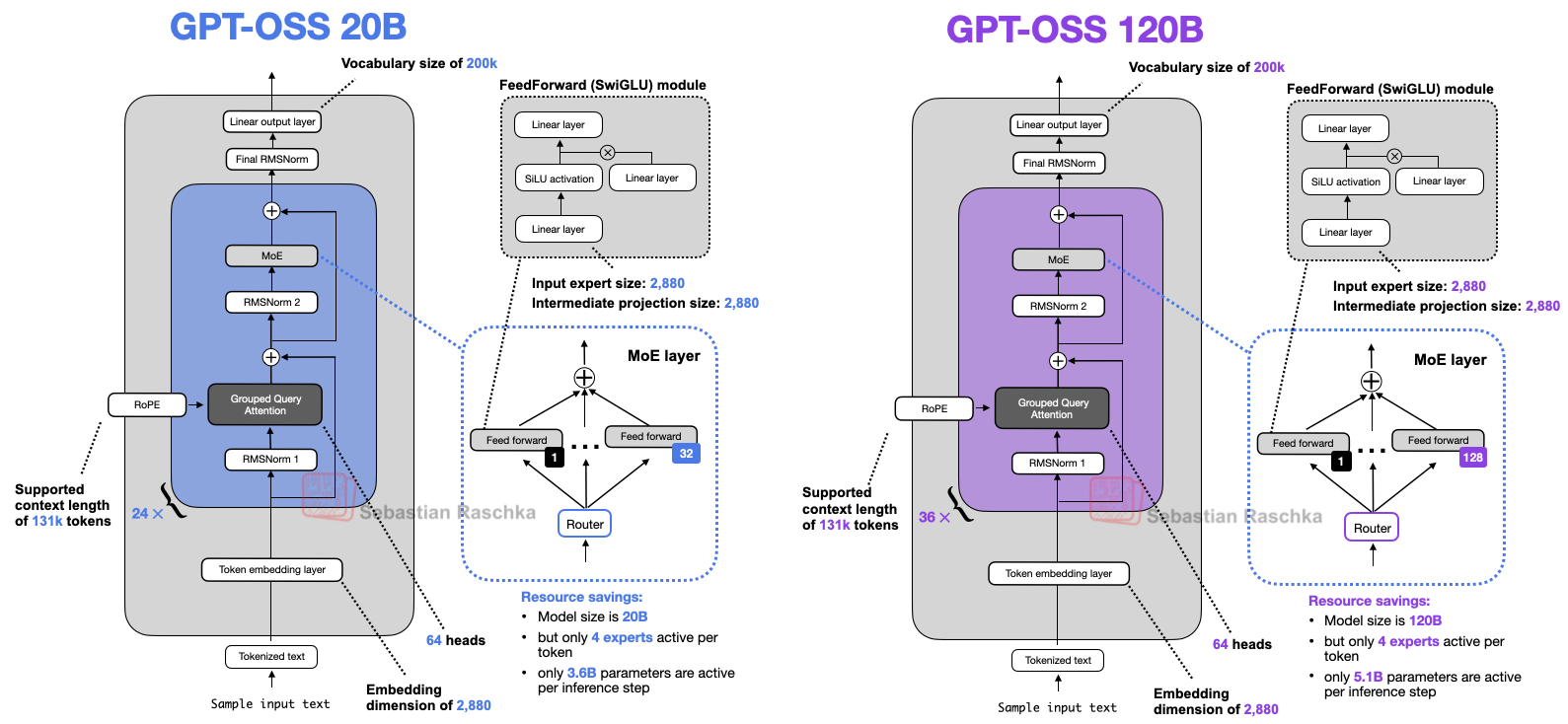
Attention 机制设计
GPT-OSS 采用交替使用分组查询注意力(GQA)与滑动窗口注意力(SWA)的策略,确保关键全局信息有效整合与高效传递,实现模型能力与推理性能的动态平衡。
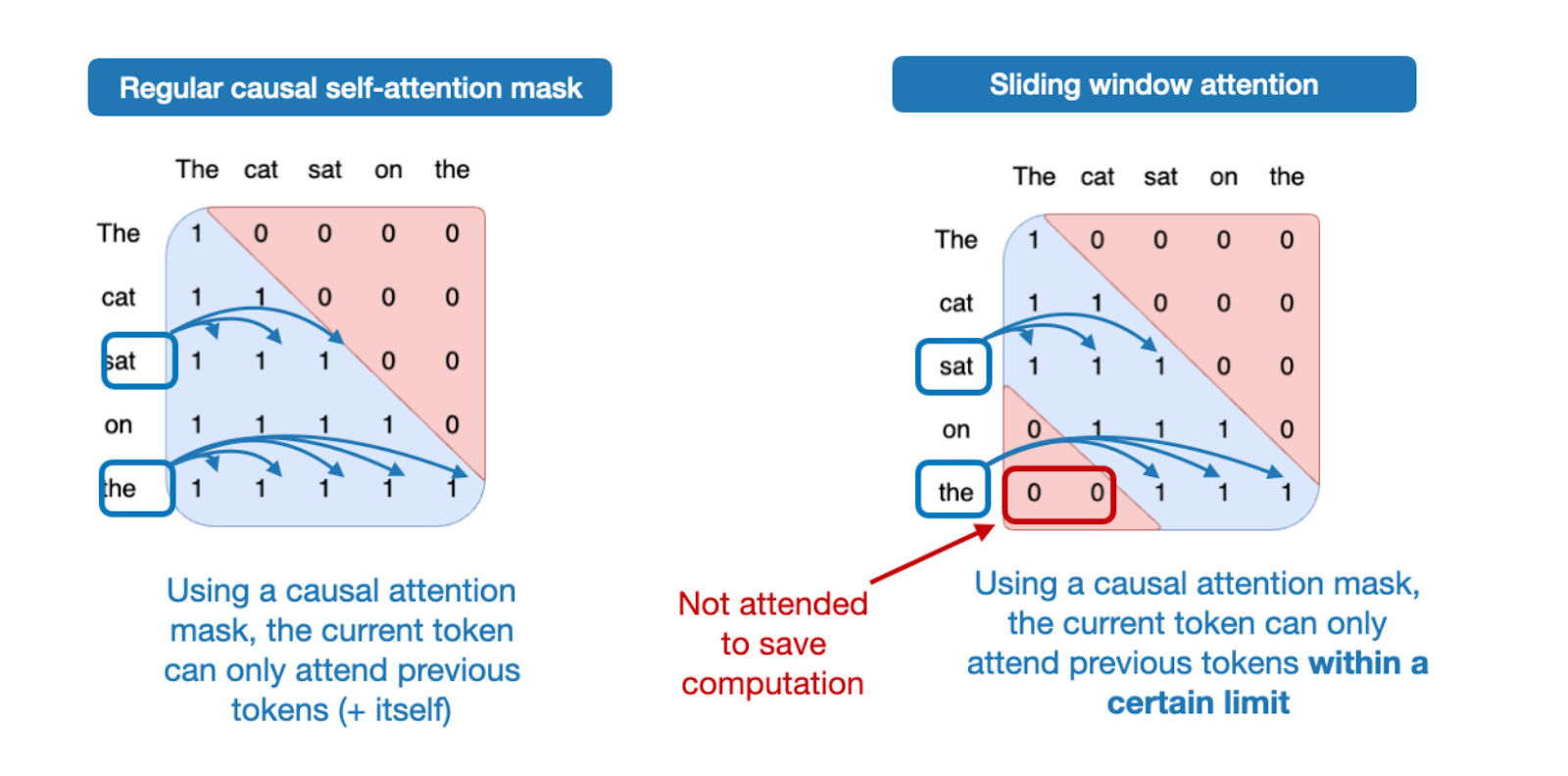
滑动窗口注意力(SWA)
针对长序列上下文,在标准掩码自注意力机制中,每个标记可“查看”自身及所有前面的标记,对于标记的输入序列,会生成一个的注意力矩阵(LLM 的上下文长度越长,该矩阵的计算成本和内存占用越难以承受)
SWA 是稀疏注意力机制的一种,其会限制“回看”的范围(即注意力窗口),对于每个 query token,只允许它看到最近的 W 个 key token,并 mask 掉更早的 token,此外原始的 attn_mask(例如padding mask、global mask)也要保留,在 GPT-OSS 中这个窗口长度为 128,这种方法可以显著减少计算复杂度和内存消耗。
计算复杂度从: O ( n 2 ) → O ( n ⋅ w ) O(n^2) \rightarrow O(n \cdot w) O(n2)→O(n⋅w),其中 n 为序列长度,w 为注意力窗口大小
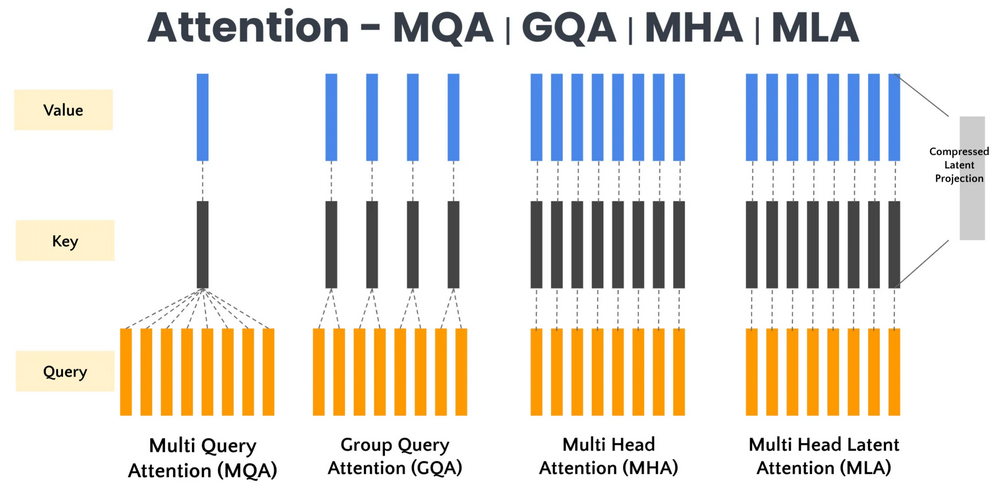
分组查询注意力(GQA)
在 GPT-OSS 中,每个注意力层包含 64 Q 头 + 8 KV 头,即 8 个 Q 一组,这种分组减少了键和值计算的总数,从而降低了内存使用量并提高了效率,同时不会显著影响建模性能。
Sink Attention
Sink Attention 通过引入可学习的 sink token(注意力汇点)增强注意力稳定性:
- 保留固定数量的虚拟token(通常为序列开头)
- 为每个注意力头配置可学习偏置,动态调整锚点强度
- 短序列阶段增强锚点吸引力,长序列阶段自动弱化,避免干扰自由注意力
该机制有效解决早期生成阶段注意力分布不稳定问题,提升模型输出一致性。
Off-by-one Attention
Off-by-one Attention 和 Attention sink 都是改进注意力机制的稳定性、效率或上下文感知而提出的概念。
解决的问题
原始的 softmax 计算中会给每个类别分配一个概率,并强制让所有概率和为1。
当所有类别的预测都是极小值时,softmax 后对其分配的概率为 1 / n 1/n 1/n
改进方式
Off-by-one Attention 对 Attention 的公式做了如下改变,就是在分母+1,同时对首 token 添加一定的注意力:
( softmax 1 ( x ) ) i = exp ( x i ) ∑ j exp ( x j ) \left(\operatorname{softmax}_1(x)\right)_i = \frac{\exp(x_i)}{\sum_j \exp(x_j)} (softmax1(x))i=∑jexp(xj)exp(xi) -> ( softmax 1 ( x ) ) i = exp ( x i ) 1 + ∑ j exp ( x j ) \left(\operatorname{softmax}_1(x)\right)_i = \frac{\exp(x_i)}{1 + \sum_j \exp(x_j)} (softmax1(x))i=1+∑jexp(xj)exp(xi)
这时当 attention 中所有位置的都趋于极小值,所有位置被分配的概率也趋于0,允许无意义的注意头可以保持静默,不代入无意义的噪声影响模型训练
Sink Attention in GPT-OSS
在本模型中使用的特性,可以看作是对 off-by-one attention 的一种可学习推广,让 sink token 的“吸力”可学习,每个 head 对应一个可学习的偏置,替换了 Off-by-one Attention 中整数 1 的部分
off-by-one attention:
- sink token 的 bias 固定为 1
Sink attention:
-
**让 bias 变成可学习参数 $b_{\text{sink}} $,**使其能够根据上下文动态的调整,为注意力机制提供了一个关注和不关注的开关
-
除了gpt-oss采用的方案,阿里通义团队也是提出了一个gated门控,去过滤token无意义的噪声流入下一层
-
模型可以自动调整“吸引力”的强弱:
- 对短序列:bias 大一些(模型还没语义上下文,需要强锚点)
- 对长序列:bias 小一些(模型已有语义依赖,锚点会妨碍自由注意力,因此 bias 自动减弱)
为每个 attention head 分配了一个可学习的 sink score,其仅参与 softmax 计算,所以当所有 token 都没有价值时,sink score 的存在就可以缓解强制输出的问题
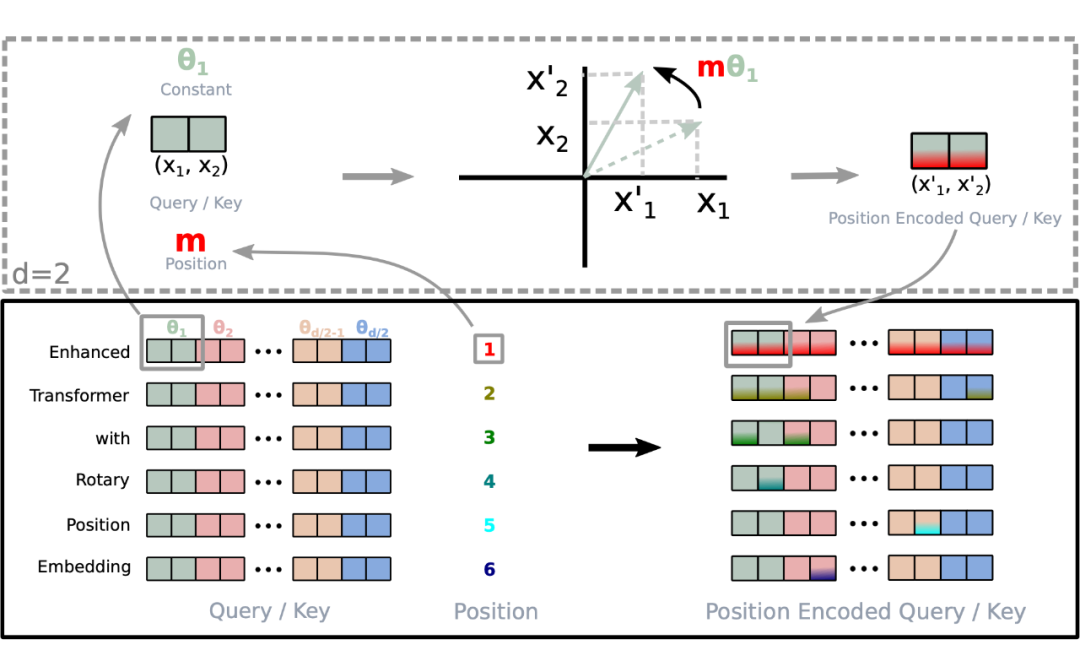
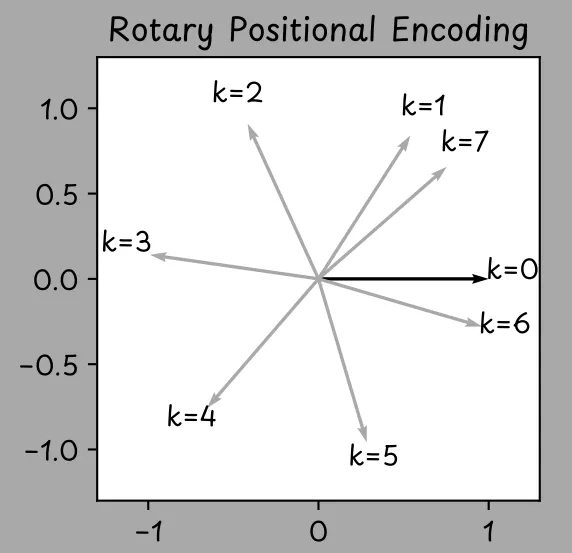
旋转位置编码(RoPE)
RoPE 通过为每个 token 位置计算旋转角度,将位置信息融入向量表示。对query和key向量按元素两两分组应用旋转变换,实现位置信息的高效编码。
 |
 |
|---|
其他优化
舍弃 Dropout
Dropout 是一种传统技术,通过在训练期间随机“丢弃”(即设为零)一部分层激活值或注意力分数(图3)来防止过拟合。但在现代 LLM 的训练过程中,通常在海量数据集上只训练一个轮次,过拟合的风险很小。
Harmony Chat Format
Harmony Chat Format 是一种统一的 chat 格式协议,用于把对话类训练数据变成模型能直接理解的 structured prompt,简单讲 —— 是一套规范化的“对话转文本模板”,对于agentic对话可能涉及的元素更加友好
MXFP4
GPT-OSS 做了 MXFP4,它是一种智能混合的 4bit 浮点权重量化方式,配合 FP8 激活和 FP16 累加,能在保持模型精度的同时,把显存和计算成本降到极低,更小的20B模型甚至能装入 16GB 的显存中
目前对于 A2 而言,不支持该精度,可以从 modelscope 上下载进行过反量化的 bf16 精度权重,从而使用模型
模型适配实践
开源社区信息
当前推理部分的 PR 已经合入 vLLM-Ascend 主线
问题1:transformers 库版本不匹配
问题详情
Gpt-OSS 需要 transformers 库版本 >=4.56.x
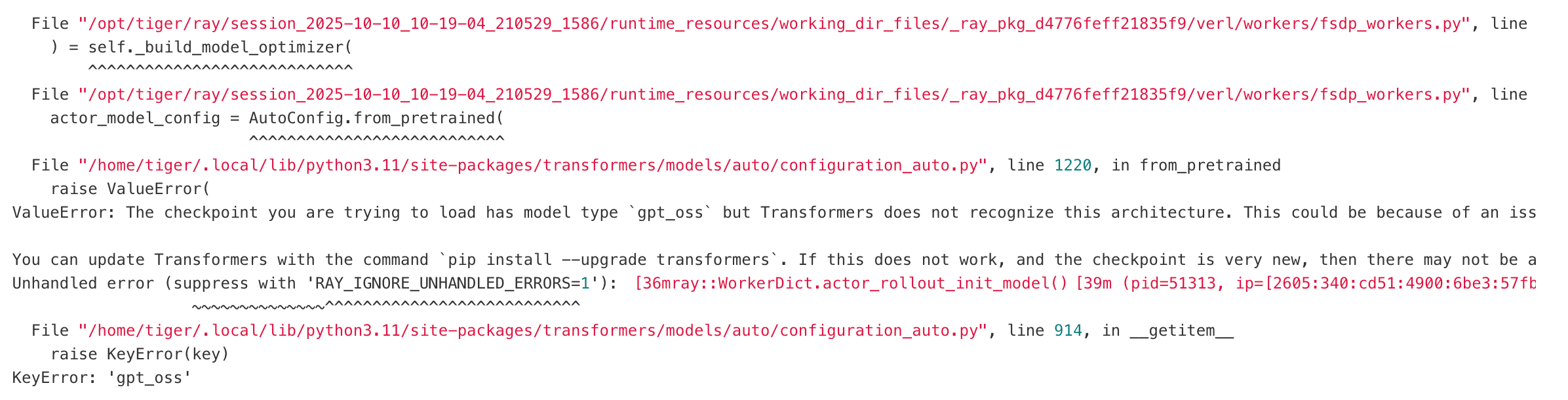
升级transformer后 出现如下问题:

升级 tokenizers = 0.22.0,出现以下问题:

解决方案:
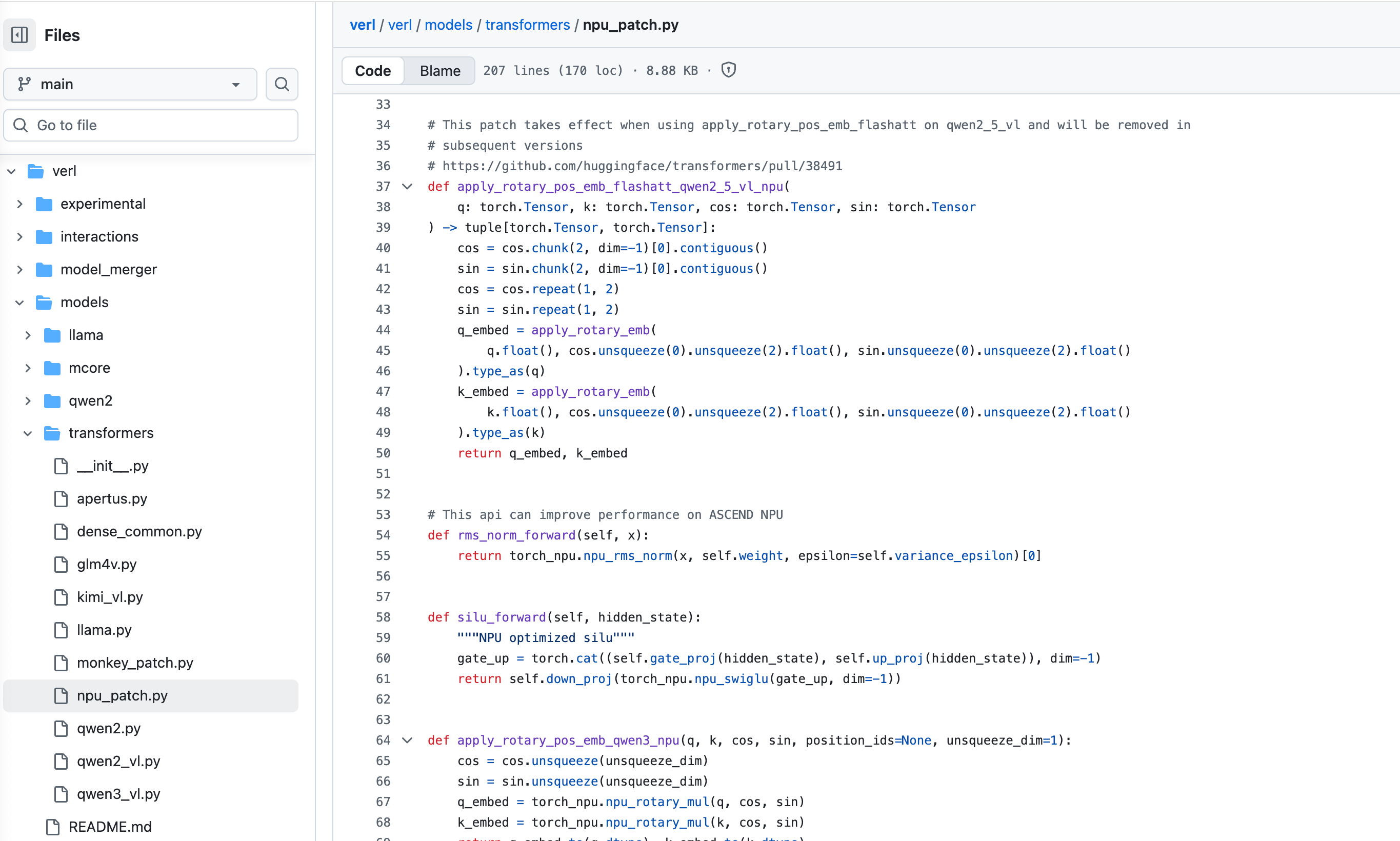
- 升级 transformers 和 tokenizers 包:4.53.3 -> 4.56.2、0.22.0
- 在woker节点的 verl/workers/actor/dp_actor.py 中引用的npu_flash_attention.py 中做如下修改,从老版本中将缺失模块 copy 过来
问题2:可分配的显存不够
问题详情:

解决方案:
在启动脚本中修改
问题3:推理阶段长时间无法终止
问题详情:
推理一个小时都没结束
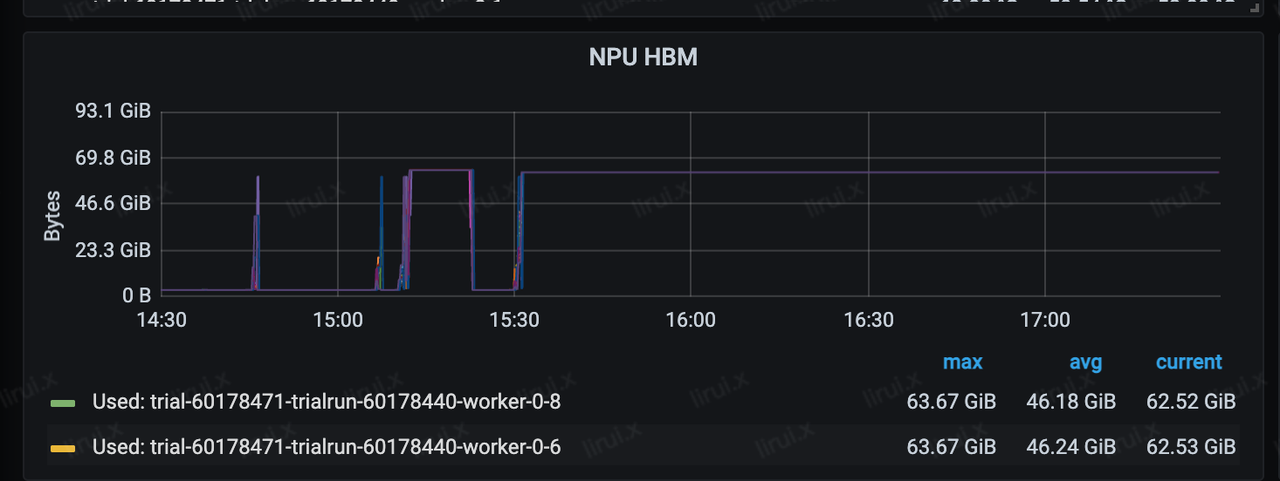
**解决方案:**参考 2572PR
问题4:缺失cudagraph
问题详情:
**解决方案:**升级 vLLM 包 0.10.0+empty -> 0.10.1
总结
GPT-OSS在昇腾平台的高效推理实现,通过创新的注意力机制设计(GQA+SWA+Sink Attention)、精准的库版本协同与关键算子优化,成功解决了长上下文模型部署的核心挑战。本实践验证了昇腾平台在大语言模型推理场景的高效性,为超长上下文模型的工业级应用提供了可复用的技术方案。后续将持续优化算子性能,探索更高效的量化策略,进一步提升模型推理效率。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)