
基于昇腾NPU的RaBitQ 1-bit向量检索加速方案
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161601003
背景概述
在 RAG、搜推等场景中,面对千亿千维的海量数据向量底库,实现快速精准的相似性检索是突破系统性能瓶颈的关键。传统向量检索依赖 CPU 实现,算力瓶颈使其难以在高负载场景下兼顾性能与性价比。
为此,NVIDIA 正积极部署基于 GPU 的向量检索加速技术——cuVS,构建以GPU中心的一体化向量数据底座。然而受限于显存容量约束,面对超大规模向量底库时,存储与算力匹配难度极高,规模化落地场景受限。一方面,NVIDIA 结合 SCADA 架构在千亿级规模下解决容量和成本问题。另一方面,RaBitQ[5]作为具备理论误差保证、极致压缩比与优异实战精度的 1-bit 量化算法,已在产业界大规模落地(近期因质疑 TurboQuant 的原创性受到业界广泛关注[6]),也为面向NPU的高性能向量检索方案提供了可行的技术落地路径。
本文介绍首个基于昇腾 NPU 的 RaBitQ 专用加速优化方案,通过计算流程重构、软硬件多模块协同优化、NPU 硬件深度适配、以及自适应调度机制,充分利用昇腾 NPU 硬件能力,实现极低的存储成本与极致的查询性能,可为 Agent 时代的高性能向量数据底座构建提供支撑。
算法简介
IVFRaBitQ 是一种将倒排文件(IVF)的粗粒度索引能力与 RaBitQ 先进的二进制量化技术相结合的高性能向量索引算法,通过 IVF 初筛最相关的聚类簇来缩小搜索范围,通过 RaBitQ 算法将高维浮点向量压缩为极紧凑的二进制编码,从而在保证高检索精度的前提下,显著降低内存消耗并提升查询速度。
核心优势
IVFRaBitQ 算法通过巧妙的数学理论与工程设计的结合,在提供具有理论保证的误差边界的同时实现高达 1:32 的超高压缩比,且极大提升查询时的距离计算效率,有效地解决了内存受限场景下向量检索的性能、成本、召回率三者难以兼得的难题,特别适合对内存占用敏感、追求极致查询性能同时要求高召回率的大规模(百万级至百亿级)向量检索场景。而基于昇腾 AI 处理器的 IVFRaBitQ 算法,经过专门的优化,原生适配 Ascend NPU 的 AI Core、内存带宽与数据搬运能力,支持 AI CPU 协同调度,充分发挥硬件性能。
支持的产品和版本
支持的产品包括Atlas 800I A2、Atlas 800I A3 以及 昇腾950 等系列,以下为版本配套:
| 硬件 | CANN 版本 | Index SDK 版本 | 系统推荐 |
|---|---|---|---|
| Atlas 800I A2 | 8.5.T | 7.3.T | Ubuntu 22.04 |
| Atlas 800I A3 | 8.5.T | 7.3.T | Ubuntu 22.04 |
| 昇腾950 | 8.5.T | 7.3.T | Ubuntu 22.04 |
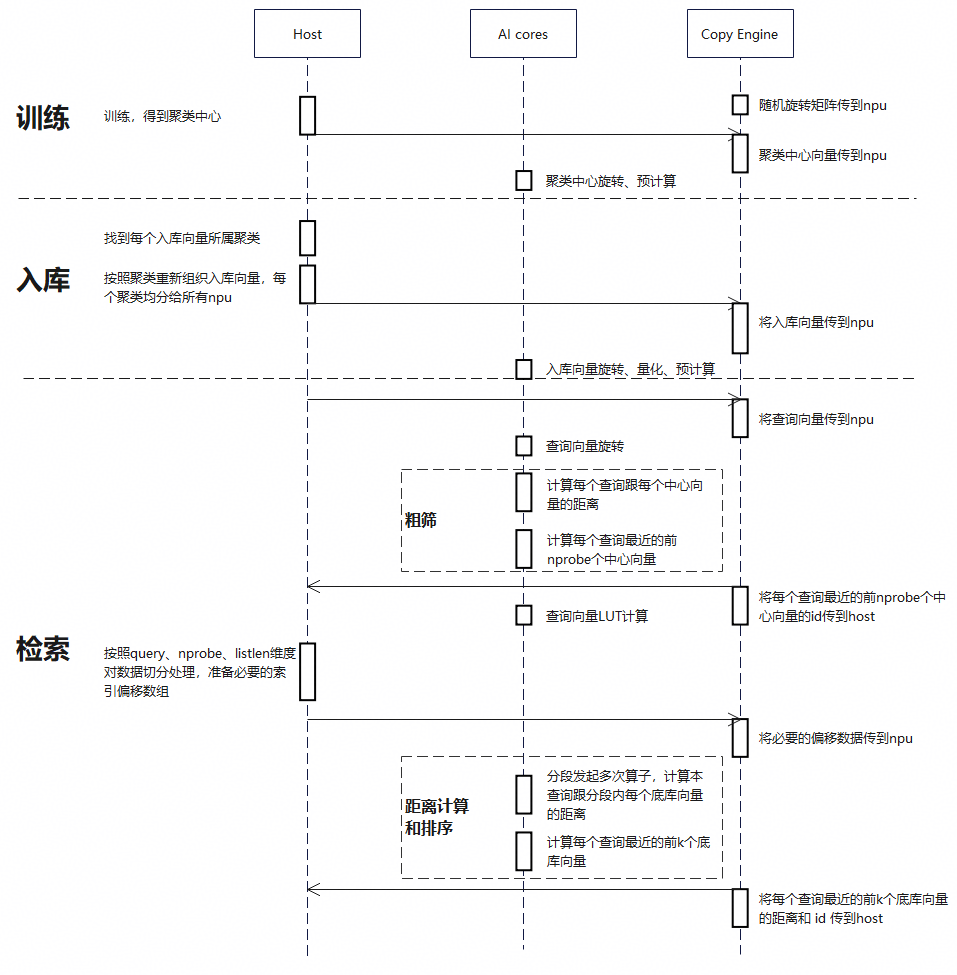
算法流程
算法流程简介
完整算法流程分为索引构建阶段和查询检索阶段两大核心环节。
第一阶段:索引构建
-
训练阶段:聚类中心训练和预计算
- 对数据库中的原始向量集进行聚类,形成索引的一级筛选结构。
- 对聚类中心进行随机正交旋转及相关预计算。
-
入库阶段:RaBitQ编码计算和预计算
- 对于数据库中的每一个向量 xi,将其加入最近的聚类中心对应的倒排列表。
- 对入库向量进行随机正交旋转、量化及相关预计算。
第二阶段:查询检索
-
IVF 粗筛和 LUT 预计算:
- 给定查询向量 q,筛选出距离最近的 nprobe 个聚类中心,大幅缩小搜索范围。
- 计算每个查询向量的 LUT。
-
RaBitQ 距离计算和排序:
- 对每个查询向量,计算出查询向量跟筛选出的每个底库向量编码的距离。
- 从所有候选距离中筛选出与查询向量最相似的 k 个结果,作为最终的最近邻返回。
流程架构图
算法优化点
为了充分利用 NPU 的算力提升检索效率,本实现做了很多硬件适配的优化。
优化一(计算流程重构):重构预计算与查询向量距离计算流程以减少检索计算量、适配硬件特性。一是 拆分 L2 距离计算项,利用Vector 与 Cube 并行计算掩盖时延,提升效率;二是 LUT 拆分,适配 Cube 算力,同步计算以掩盖时延。
优化二(LUT粒度优化):8位一算降低计算量,且适配昇腾硬件。
优化三(距离计算方案硬件适配):A5 服务器的 SIMT 新特性 A2/3 服务器不支持,考虑到这种差异,本实现为距离计算设计了两种实现方案,适配不同的硬件。
优化四(Topk与距离计算流水):使用 AI Core 做距离计算,AI CPU 做 Topk 排序,流水线化两个阶段,充分利用 NPU 算力。
优化五(自适应调度机制):本实现采用了一种针对不同检索参数的自适应调度机制,不打破每个倒排列表的完整性,且实现距离算子下发的负载均衡,以充分利用 AI Core 资源。
检索测试结果
性能测试
当前 IVFRaBitQ 检索算法基于客户预设场景进行性能测试,统计单次查询的检索时间,将NPU 环境下的检索速度与 CPU 环境对比,在不同参数场景下均远优于 CPU。单次查询的时间在毫秒级别。
| ntotal | dim | nlist | nprobe | batch | topk | NPUA2(ms) | NPUA5 | CPU |
|---|---|---|---|---|---|---|---|---|
| kw | 128 | 1024 | 32 | 1 | 300 | 2.3364 | 1.5630 | 178 |
| kw | 128 | 1024 | 32 | 2 | 300 | 2.6312 | 1.6047 | 188 |
| kw | 128 | 1024 | 32 | 4 | 300 | 2.9560 | 1.6451 | 189 |
| kw | 128 | 1024 | 32 | 8 | 300 | 3.5108 | 2.5997 | 191 |
| kw | 128 | 1024 | 32 | 16 | 300 | 5.4249 | 3.5611 | 200 |
| kw | 128 | 1024 | 32 | 32 | 300 | 8.6999 | 5.7517 | 222 |
| kw | 128 | 1024 | 32 | 64 | 300 | 15.4063 | 10.2001 | 243 |
| kw | 128 | 1024 | 64 | 1 | 300 | 2.6001 | 1.6812 | 345 |
| kw | 128 | 1024 | 64 | 2 | 300 | 2.8711 | 1.7290 | 359 |
| kw | 128 | 1024 | 64 | 4 | 300 | 3.7074 | 1.8086 | 366 |
| kw | 128 | 1024 | 64 | 8 | 300 | 5.1756 | 2.6870 | 367 |
| kw | 128 | 1024 | 64 | 16 | 300 | 8.6747 | 4.1435 | 382 |
| kw | 128 | 1024 | 64 | 32 | 300 | 15.4345 | 7.1646 | 402 |
| kw | 128 | 1024 | 64 | 64 | 300 | 28.4849 | 12.6846 | 469 |
准度测试
准度测试时为保证索引构建和检索过程中无随机性引入,均使用单位矩阵作为正交矩阵,聚类中心训练均使用cpu进行,且训练时使用相同的配置。在相同的底库向量和测试向量集下,
将 NPU 的检索结果和 faiss CPU 的检索结果进行比对,TOPK300一致性不低于95%。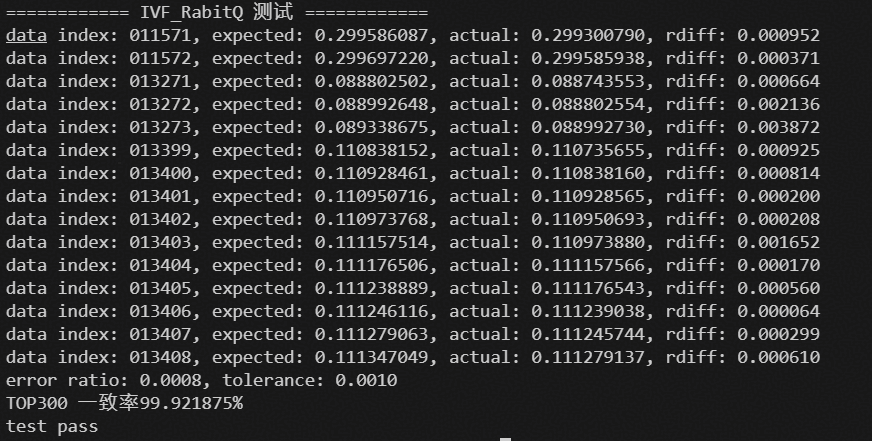
未来优化方向
- Topk 排序优化:A5 版本的距离计算算子性能明显优于 AI CPU 的 Topk 排序,此时 Topk 的计算延迟无法跟距离计算相互掩盖,Topk 排序成为检索阶段的瓶颈,后续会针对 Topk 排序做进一步优化。
- IP 距离开关:当前 IVFRaBitQ 算法仅支持 L2 距离计算,后续开发 IP 距离作为计算方式,拓展更多场景。
- HNSW图类索引支持:后续预计使用 NPU 加速图类索引的构建和检索。
- 类似于 TurboQuant,在 KVCache 量化场景,探索 NPU 亲和的量化加速技术。
下载与部署
[ IndexSDK 开源项目下载](https://IndexSDK:基于华为昇腾平台 Index SDK 实现了一个高效的向量特征检索引擎,用户可以在此引擎上实现面向应用场景的检索系统 - AtomGit | GitCode)
[ IVFRaBitQ 检索算法快速部署](https://Wiki: 快速部署基于 Index 的 IVFRaBitQ 检索算法,灵活处理海量数据)
参考链接
[1] 美团外卖基于GPU的向量检索系统实践:https://tech.meituan.com/2024/04/11/gpu-vector-retrieval-system-practice.html
[2] 腾讯在微信大规模推荐系统中用 GPU 加速向量检索:https://mp.weixin.qq.com/s/HY4uf9_WS7TULgEye–Oiw
[3] cuVS 官方文档:https://developer.nvidia.com/cuvs?sortBy=developer_learning_library%2Fsort%2Ftitle%3Aasc&ncid=no-ncid;github链接:https://github.com/rapidsai/cuvs
[4] GPU 结合 SCADA 架构突破 PB 级数据处理内存墙):https://mp.weixin.qq.com/s/37ZHV_syXe1cVhDeLrm7_Q
[5] RaBitQ 论文:https://arxiv.org/abs/2405.12497
[6] RaBitQ 原作者质疑TurboQuant:https://zhuanlan.zhihu.com/p/2020969476166808284

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)