
【昇腾950 cv融合算子体验】L0C Buffer到UB的单向数据通路
1 背景
昇腾950在架构上做了更新,参考文档如下:220x到351x架构变更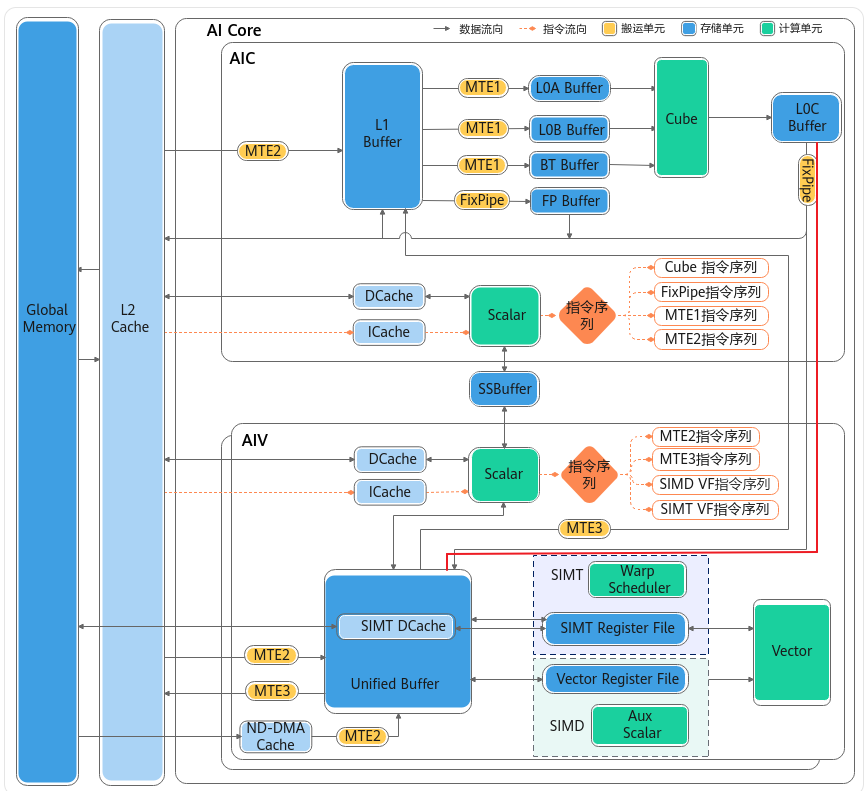
如上图红色线段所示,新增通过LOC->Unifiled Buffer的数据通道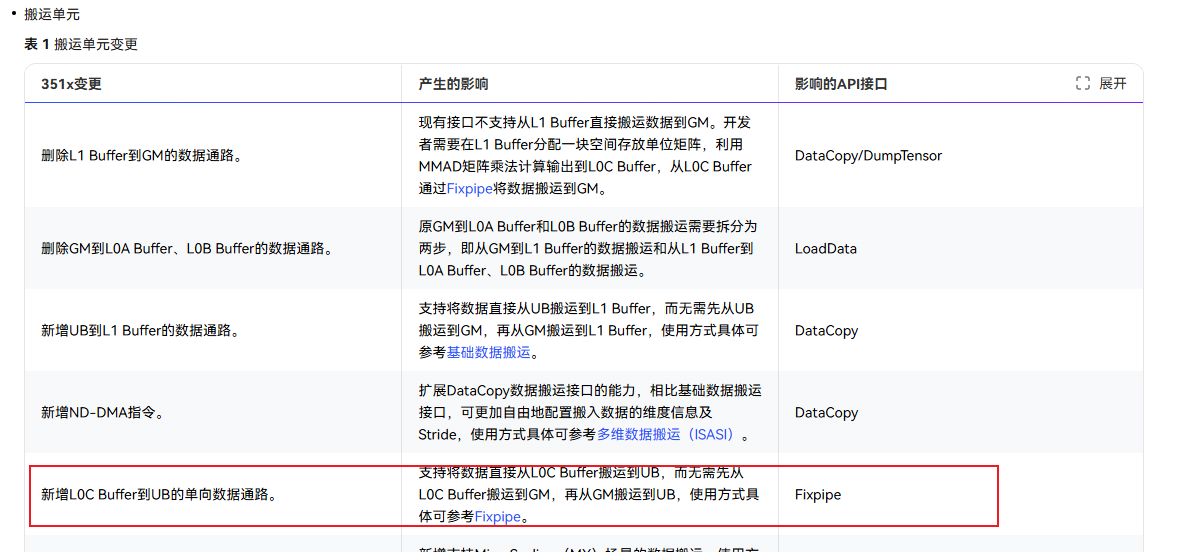
按照之前A2/A3上的数据搬运通路,cv融合算子需要通过GM作为中转站,典型通路如:L0C → FixPipe → GM → DataCopy → UB。既然950提供了相关硬件支持,那么就可以测试下,新的通路是否有性能(少一层GM数据中转)提升。
2 环境准备
2.1 950硬件环境
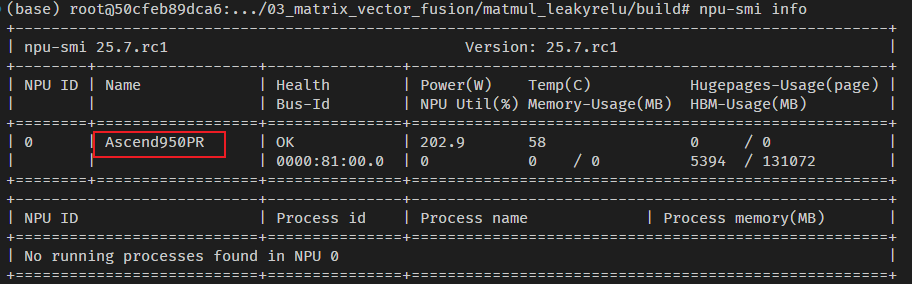
2.2 CANN版本环境
CANN安装的是9.0.0版本。
2.3 测试代码
昇腾社区资料(关于cv融合):CV融合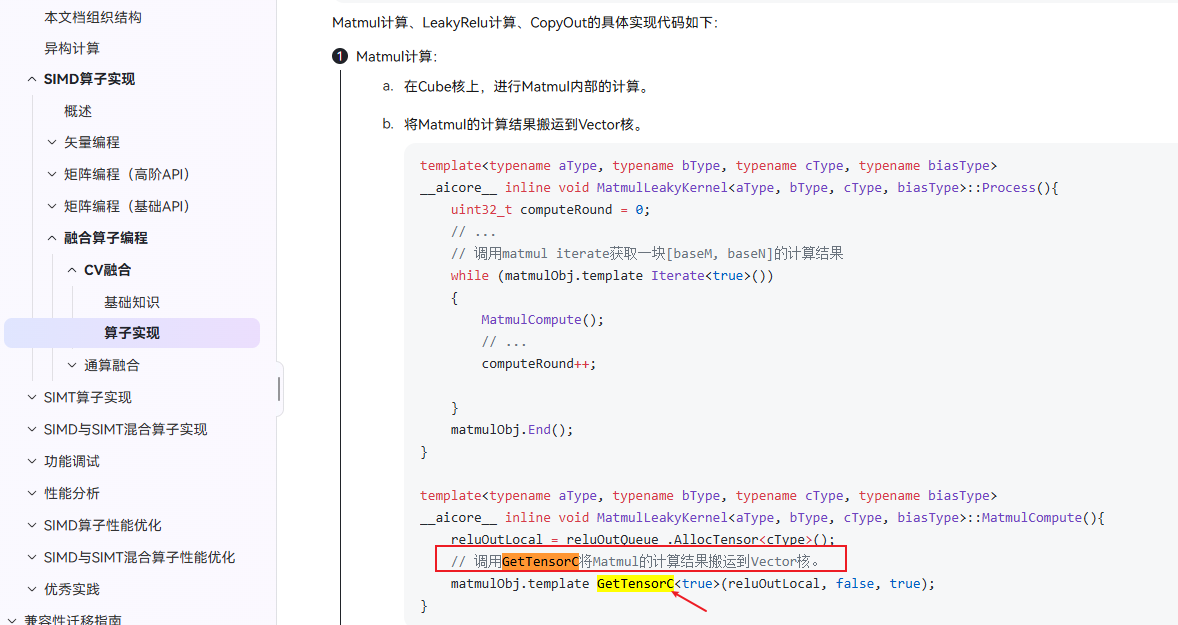
通过阅读上述代码注释和流程,容易猜想新的搬运通路是通过GetTensoC接口进行调用的。完整代码文档中也有进行说明,如下:
代码路径(v9.0.0版本):
https://gitcode.com/cann/asc-devkit/tree/9.0.0/examples/01_simd_cpp_api/00_introduction/03_matrix_vector_fusion/matmul_leakyrelu
3 通道路径确认
本次选了一个搓而有效的办法进行验证,就是在代码的关键路径上加打印。“对,就是那个万能的printf”。
3.1 CANN安装
开发者可以按照自己当前的硬件环境,按照编译构建的文档一步步准备环境。如果CANN已经安装好,请跳过此部分。
CANN环境安装已经做易用性升级,提供一键式安装命令,比如通过如下:
点击链接后,显现的下载界面如下所示:
以上命令全部复制执行即可。

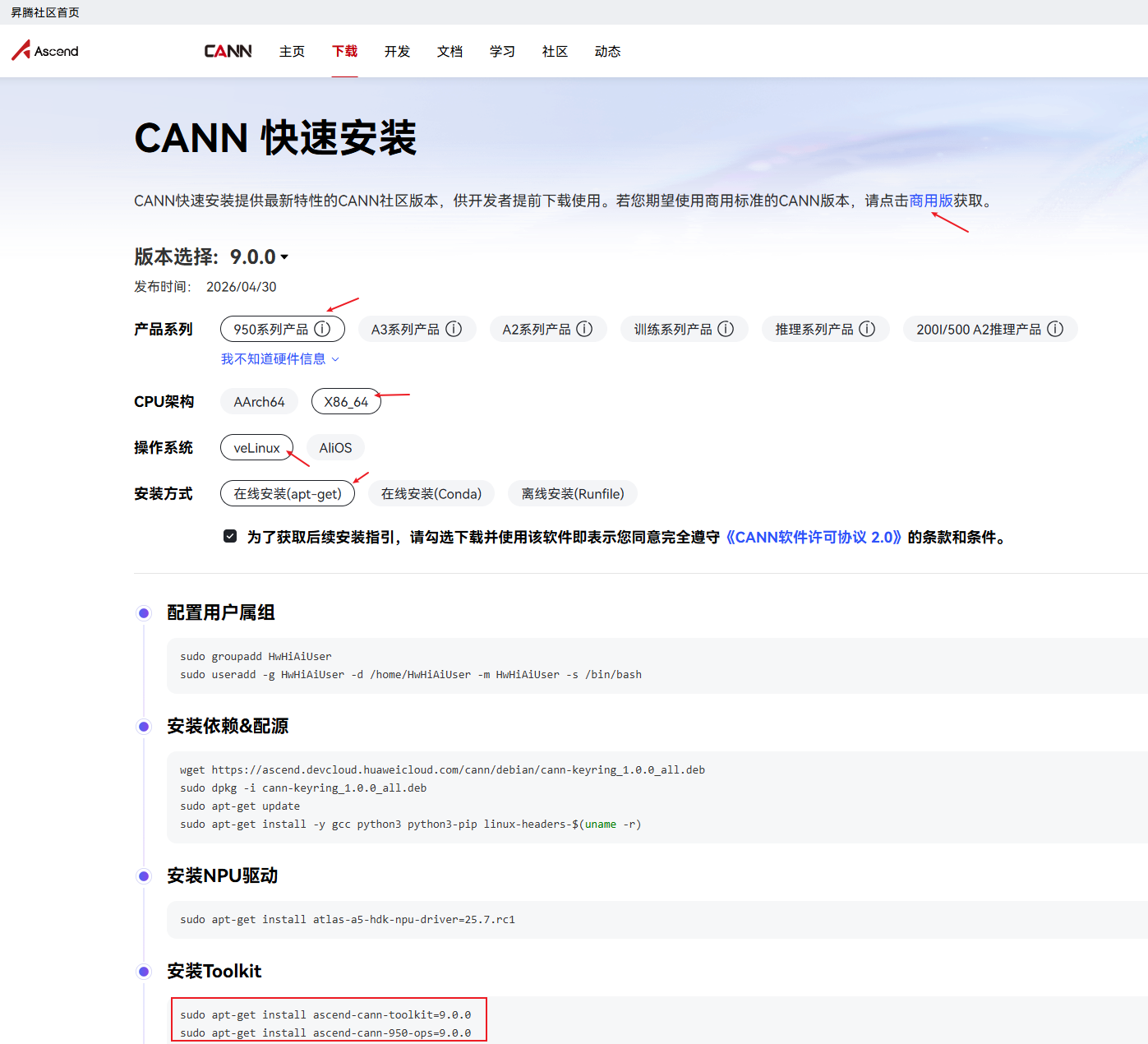
如有问题:欢迎大家在昇腾社区提工单(网页右下角耳机图标)。
3.2 找到GetTensorC的代码实现位置
阅读代码,发现GetTensorC的代码路径:adv_api/detail/matmul/matmul_impl_base.h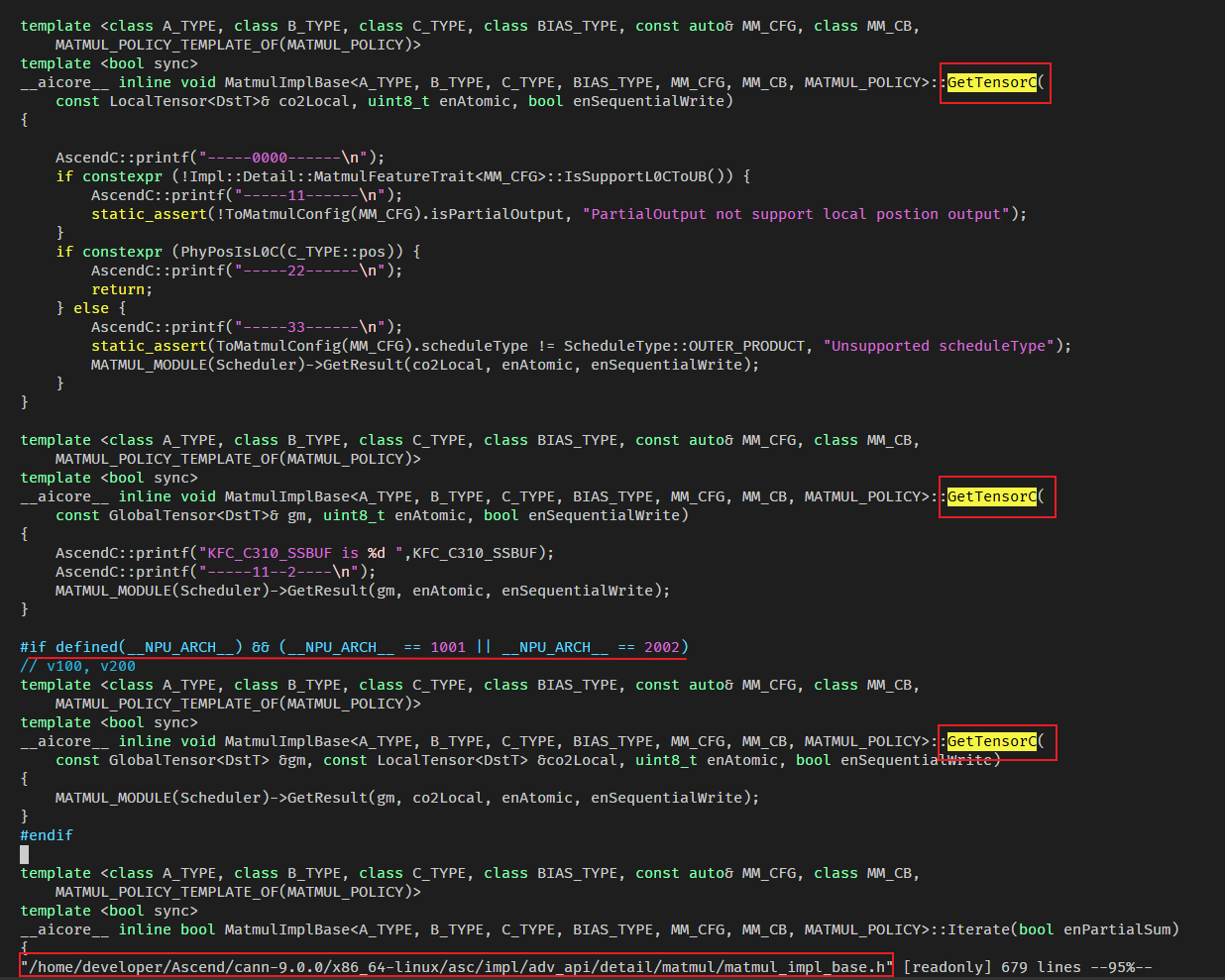
GetTensorC从上往下有3个实现,最后一处实现,明显可以排除,因为是针对_NPU_ARCH__ == 1001 || __NPU_ARCH__ == 2002,所以在上述2个加了打印。2个GetTensorC的代码差别如下:
可以明显看到,第1个GetTensorC的第1个入参是LocalTensor(AICore),第2个GetTensorC的第1个入参是GlobalTensor(GM上)。
理论上,我们要进入的是第1个GetTensorC,因为本次验证的特性就是LocalTensor的。我们先记住这个结论。
PS:代码中IsSupportL0CToUB这个在950上是支持的(可以参考issue:https://gitcode.com/cann/asc-devkit/issues/563),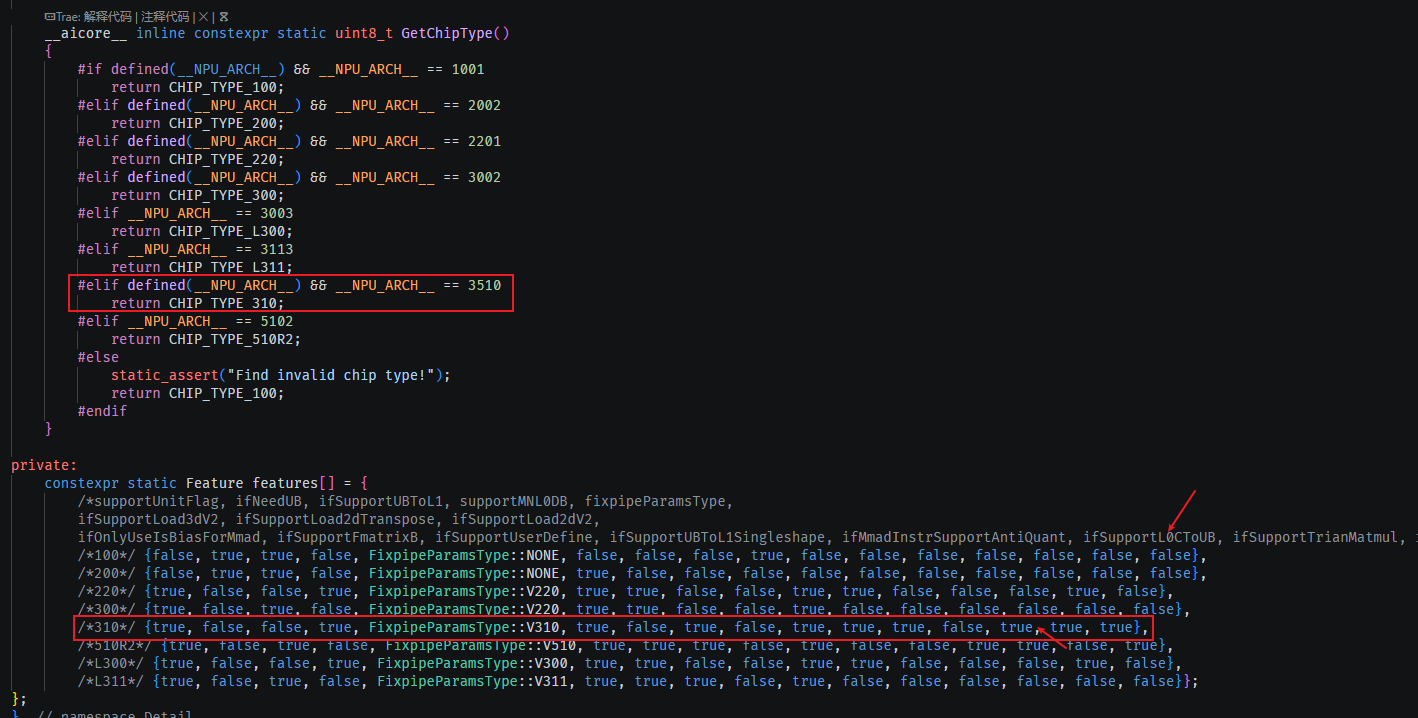
另外这里记住:3510的芯片类型是CHIP_TYPE_310。
问题:950的_NPU_ARCH__ 是啥?答案是:3510(351X)
参考:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/910beta1/programug/Ascendcopdevg/docs/guide/%E5%85%BC%E5%AE%B9%E6%80%A7%E8%BF%81%E7%A7%BB%E6%8C%87%E5%8D%97/351x%E6%9E%B6%E6%9E%84%E8%BF%81%E7%A7%BB%E6%8C%87%E5%AF%BC/220x%E5%88%B0351x%E6%9E%B6%E6%9E%84%E5%8F%98%E6%9B%B4.md
3.2.1 踩坑1:日志打印方式
刚开始,不知道如何在matmul_impl_base.h中添加打印,借鉴源码中的打印日志方式,如:
方式1:KERNEL_LOG(KERNEL_LOG,"xxxx")
方式2:ASCENDC_ASSERT(false, { KERNEL_LOG(KERNEL_ERROR, "transMode is %d , which should only be 0 / 1", transMode); });
发现日志都没打印出来。后面在社区提Issue(https://gitcode.com/cann/asc-devkit/issues/902)咨询后,发现可使用AscendC::printf()方式打印。但是KERNEL_LOG打印日志的,需要继续追问。
关于如何使用KERNEL_LOG打印日志的,在issue中继续追问,欢迎大家一起跟踪该Issue进展。
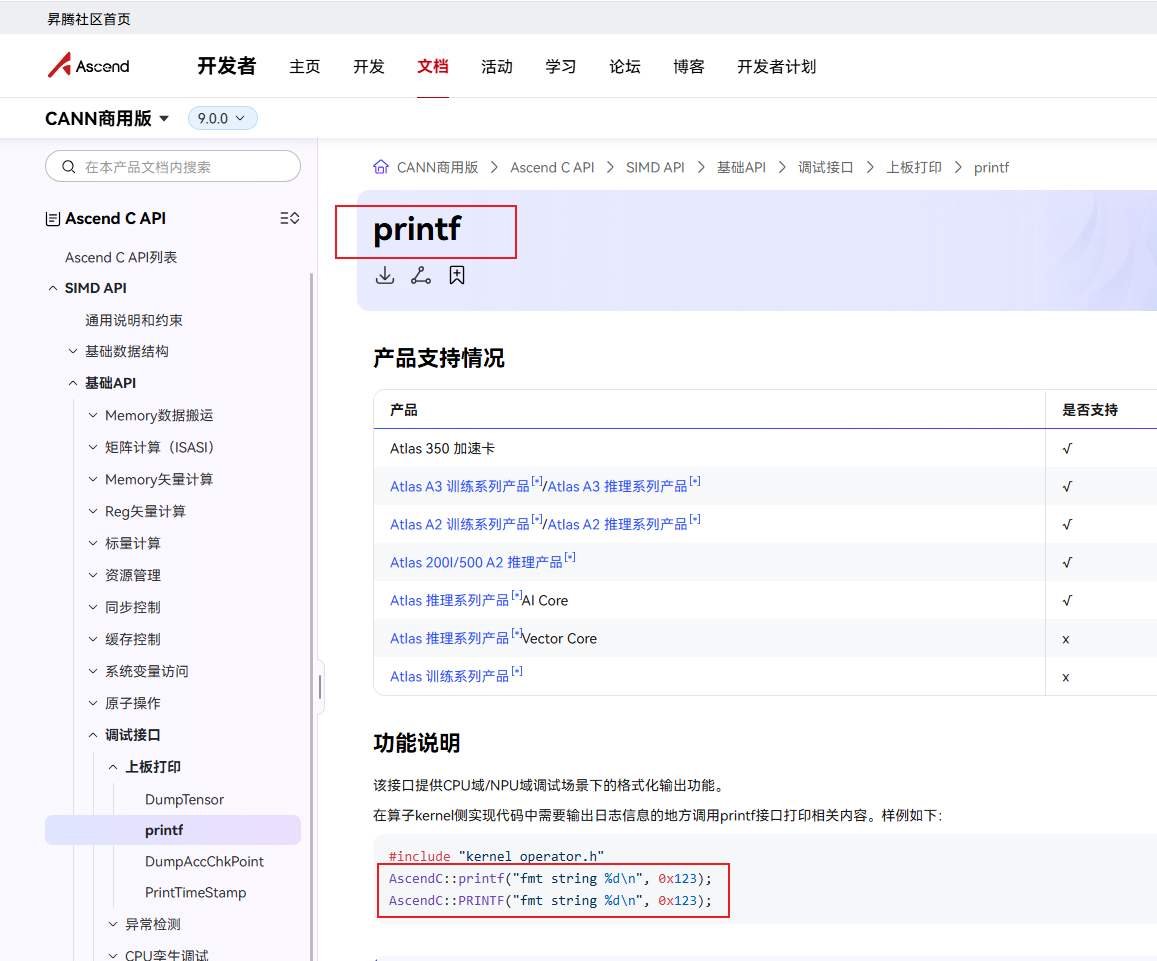
3.3 asc-devkit编译
接下来,进入asc-devkit源码编译环节。代码版本记得与CANN版本相匹配,本次选择的是v9.0.0。
首先设置下环境变量。小编的环境上install-path是/home/developer/Ascend/。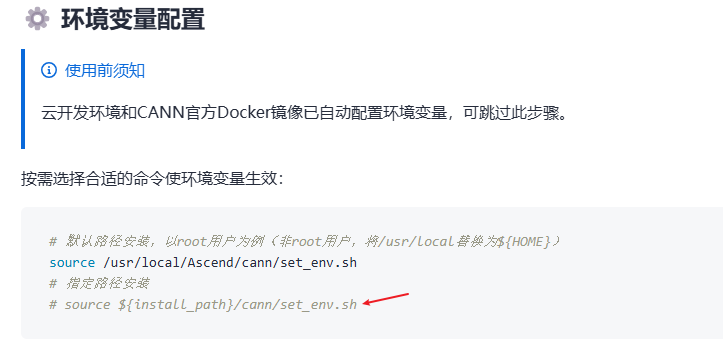
然后,就开始源码编译安装。这里我选择的是方式二,主要就是为了提醒大家如何放置第三方软件makeself源码包。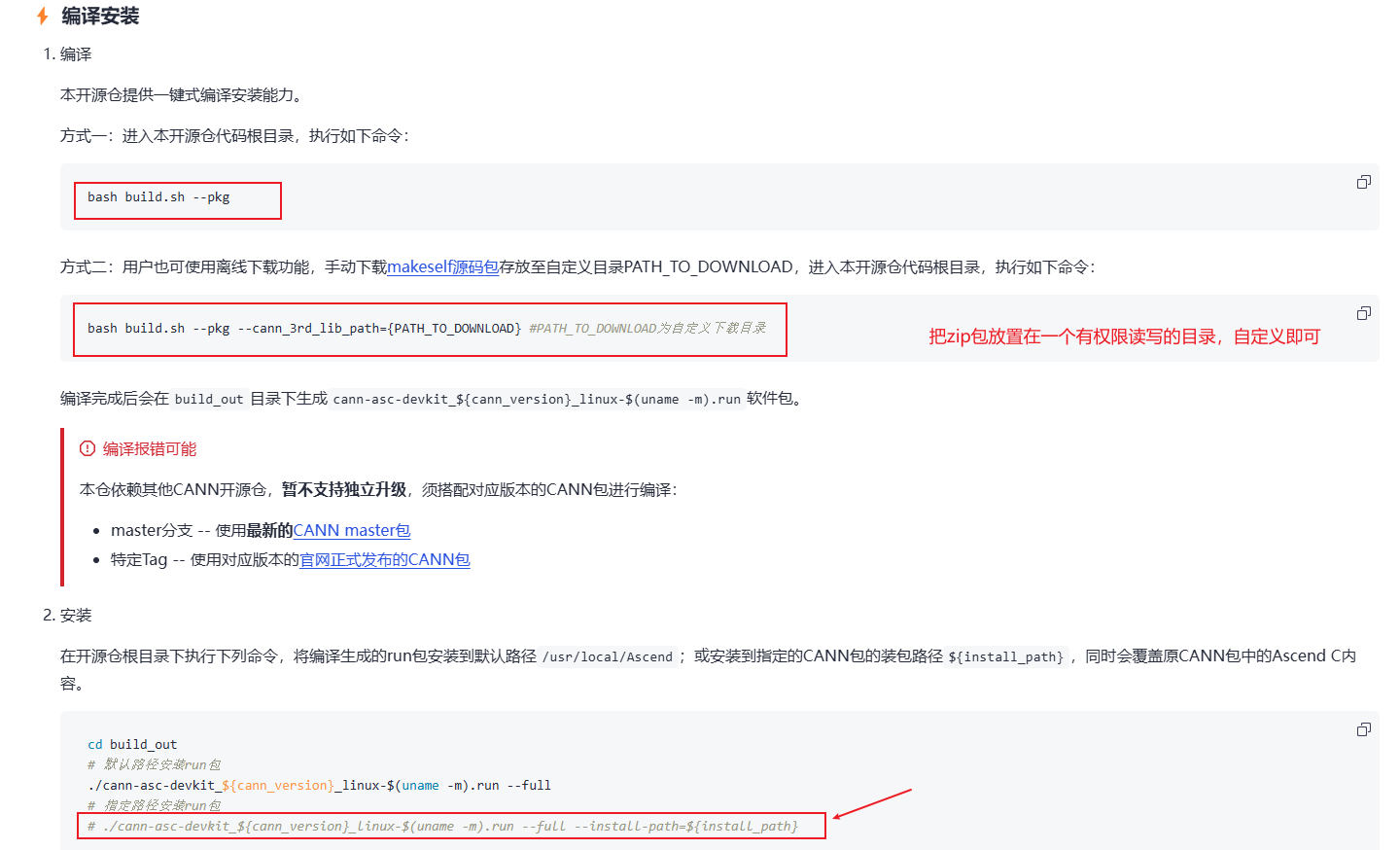
然后再安装环境,注意下install-path路径,完整编译、安装命令如:
# 编译
bash build.sh --pkg --cann_3rd_lib_path=/workspace/tmp/
# 安装
root@50cfeb89dca6:/workspace/asc-devkit/build_out# ./cann-asc-devkit_9.0.0_linux-x86_64.run cann-asc-devkit_9.0.0_linux-x86_64.run --full --install-path=/home/developer/Ascend/
3.3.1 踩坑2:asc-devkit编译只是文件拷贝?
在代码仓/workspace/asc-devkit/中改adv_api/detail/matmul/matmul_impl_base.h文件后,执行上述编译,新改的内容并不会直接通过编译器进行编译,就算如下这样写,都不会报错。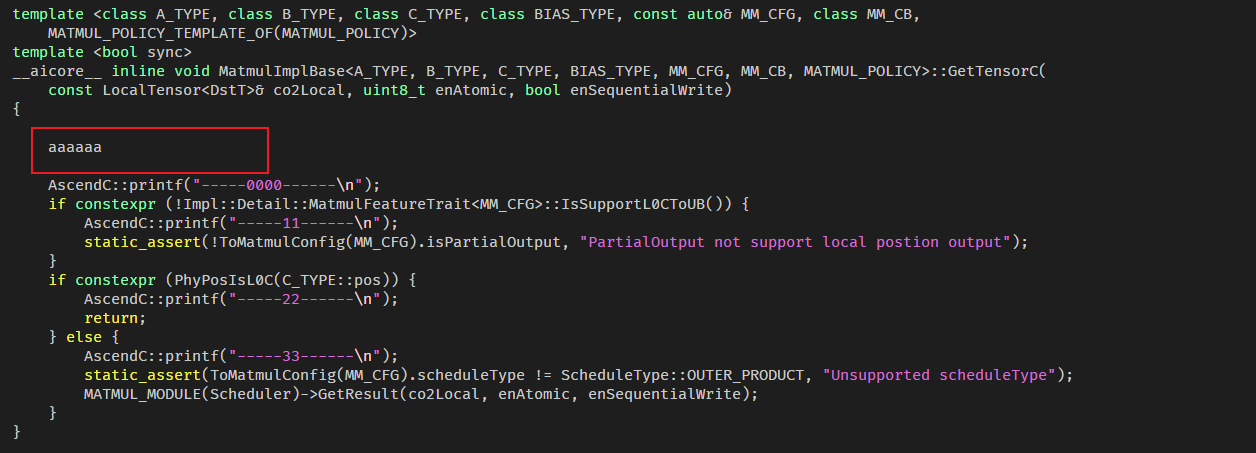
刚开始我都懵了,我改的可是.h文件,居然都没有编译报错。后面摸索了下,asc-devkit的编译和安装做的事情大概如下: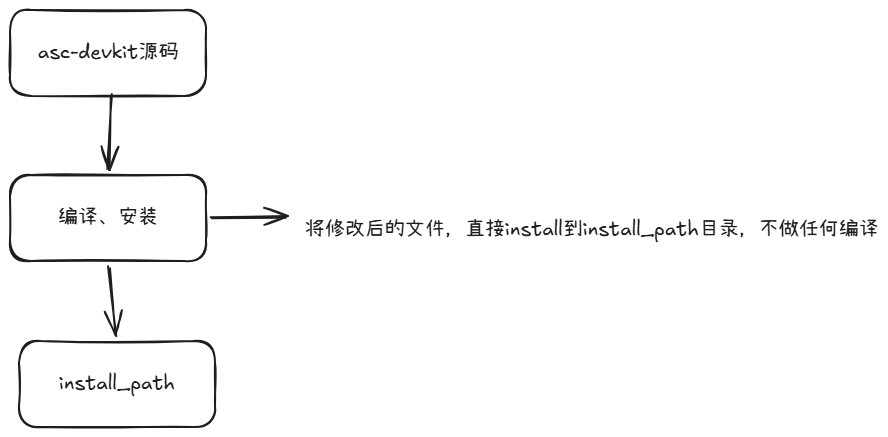
比如在小编环境上,修改后的文件会被安装到:
home/developer/Ascend/cann-9.0.0/x86_64-linux/asc/impl/adv_api/detail/matmul/matmul_impl_base.h
那具体什么时候进行编译呢?继续往下看。
3.4 matmul_leakyrelu编译运行
按照matmul_leakyrelu提供的readme文档:编译运行
mkdir -p build && cd build; # 创建并进入build目录
cmake ..;make -j; # 编译工程
python3 ../scripts/gen_data.py # 生成测试输入数据
./demo # 执行编译生成的可执行程序,执行样例
python3 ../scripts/verify_result.py output/output.bin output/golden.bin # 验证输出结果是否正确,确认算法逻辑正确
这里如果matmul_leakyrelu编译失败,请检查2处:
1、代码的版本是不是v9.0.0
2、编译传的参数是否是–npu-arch=dav-3510。
如果是v9.0.0的版本,请修改如路径下的CMakeLists文件。
修改内容是添加dav-3510的编译选项:


如果是master版本(2026.6.10),在cmake编译命令中已经添加CMAKE_ASC_ARCHITECTURES编译选项,如下:
mkdir -p build && cd build; # 创建并进入build目录
cmake -DCMAKE_ASC_ARCHITECTURES=dav-3510 ..;make -j; # 编译工程(默认npu模式)
python3 ../scripts/gen_data.py # 生成测试输入数据
./demo # 执行编译生成的可执行程序,执行样例
python3 ../scripts/verify_result.py output/output.bin output/golden.bin # 验证输出结果是否正确,确认算法逻辑正确
此时就不用改CMakeLists文件。master代码参考路径:master代码
不出意外的话,马上就要出意外了。执行到./demo后,终端上会显示如下红框中的内容: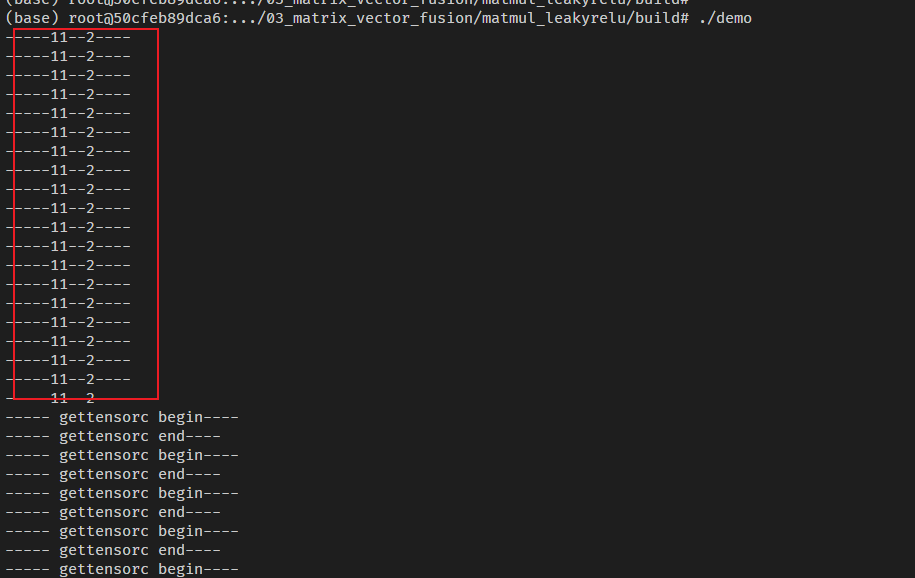
咦,不对,为啥打印的是
-----11--2----
这个可是GlobalTensor的分支,应该是要打印:
-----0000------
才对啊,为什么呢? 是样例代码中写错了吗?回看代码,定义的就是LocalTensor,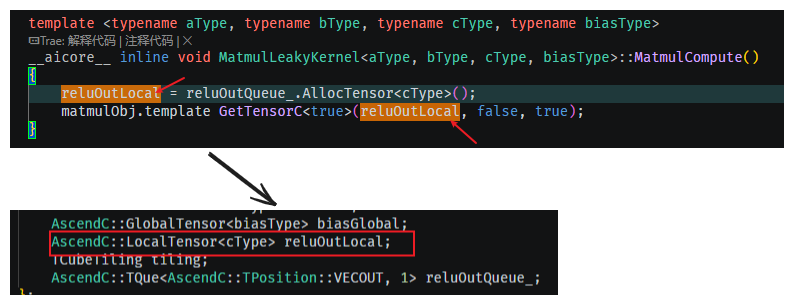
为什么呢? 为什么呢? 为什么呢? 先给GitCode社区上一单(https://gitcode.com/cann/asc-devkit/issues/923)。
3.5 问题定位
作为一个合格的开发者,要尝试自己定位问题,于是请坐好,准备出发。。。
大模型时代,不能猛的一下子就扎到实际代码中去,效率太低,可以先问大模型给你点指示。
于是,我就通过Trae给GLM 5.1大模型问了一嘴:
它酝酿了半天,给我一个总结: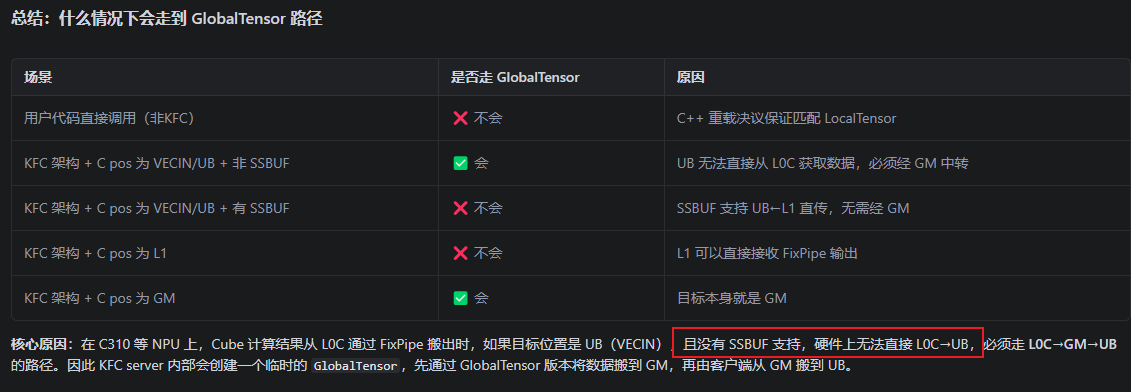
这里明显注意到一个核心信息,没有SSBUF支持,硬件上无法直接L0c->UB。这里说的C310的平台,C310?咦,好熟悉,950芯片不就是310系列的么?SSBUF是支持的呀(参考资料),是什么导致没有呢?
KFC(Kernel Function Call)架构(C310/C220 平台)
带着3510,以及310,以及SSBUF等关键信息,结合大模型,快速找到了如下代码片段:
/home/asc-devkit/impl/adv_api/detail/matmul/utils/matmul_utils.h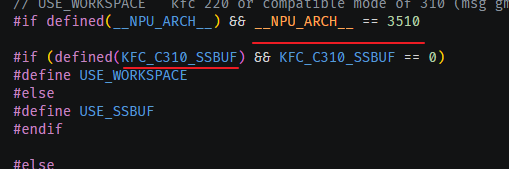
这里出现了USE_WORKSPACE和USE_SSBUF,这里USE_WORKSPACE和USE_SSBUF都是干什么的?问大模型呗。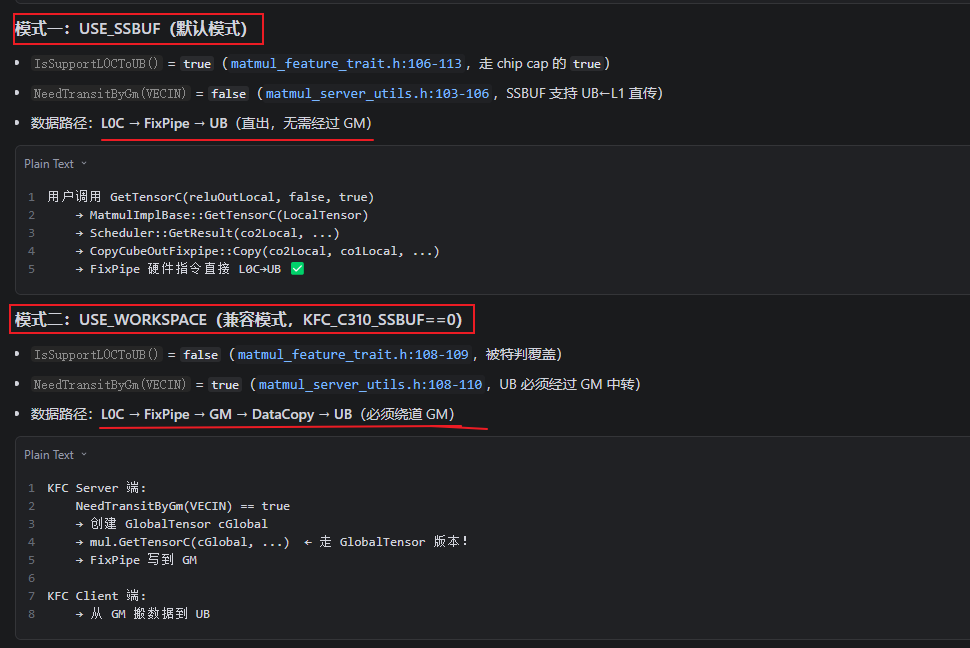
好像摸到边了,此处应该走的是USE_SSBUF。那就去看下宏定义的条件:
#if (defined(KFC_C310_SSBUF) && KFC_C310_SSBUF == 0)
于是,在代码中加上打印,先确认下KFC_C310_SSBUF的值。
重新编译运行: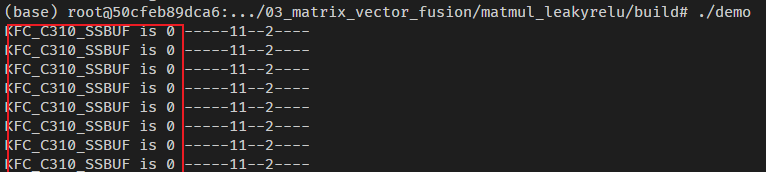
确认KFC_C310_SSBUF的值是0。那KFC_C310_SSBUF 是哪里设置的呢?
一番操作后,又找到如下代码:
/home/asc-devkit/impl/basic_api/kernel_utils.h
需要2个条件才能将KFC_C310_SSBUF设置为1,这2个条件又是什么?ENABLE_CV_COMM_VIA_SSBUF这个是通过CMakeLists.txt文件传入的。__MIX_CORE_AIC_RATION__在950上是true的(分离设计)
那原因就是ENABLE_CV_COMM_VIA_SSBUF没有传入吗?看看仓库中是否有其他的样例,做个参考?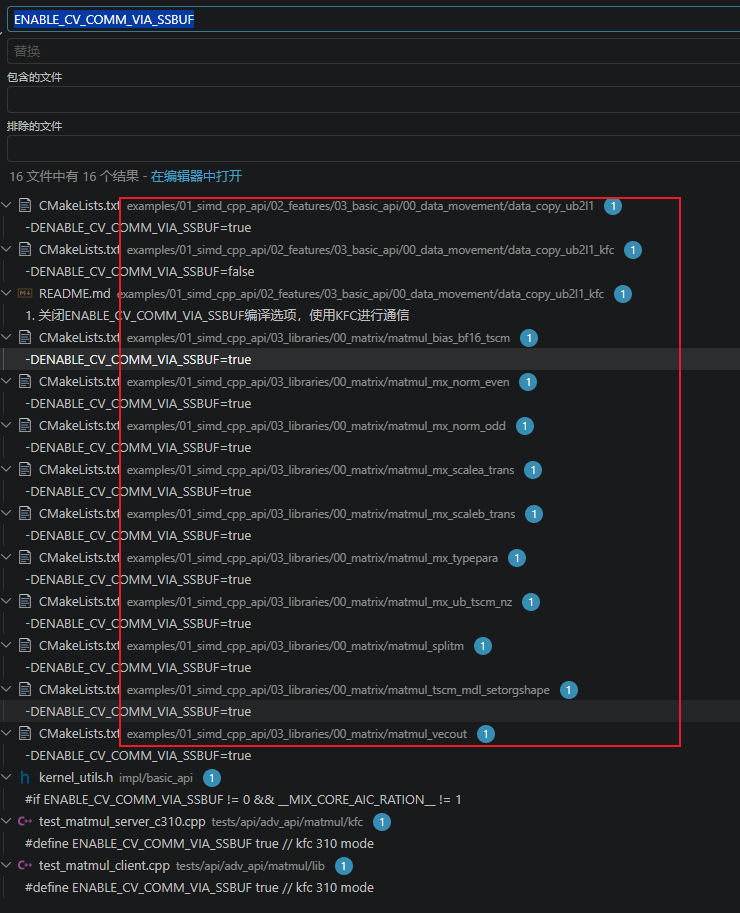
到这里,99.9…%原因知道了。那就改matmul_leakyrelu的CMakeLists.txt文件,添加ENABLE_CV_COMM_VIA_SSBUF编译选项。
重新编译运行,成功进入了正确的GetTensorC函数,函数走入的分支也是正确的。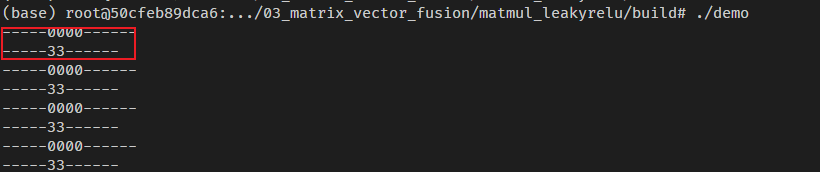
阿弥陀佛,终于对了。
到这里还没完,还要进一步确认是不是走了FixPipe的专有通道,顺着GetResult继续走下去:
这里分析过程,大模型可以继续出马,直接贴结论:
用户代码: matmulObj.GetTensorC<true>(reluOutLocal, false, true)
│
▼
MatmulImplBase::GetTensorC(LocalTensor) [matmul_impl_base.h:609]
│ 检查 IsSupportL0CToUB(),检查 C pos 不是 L0C
▼
MatmulSchedulerBase::GetResult(LocalTensor) [scheduler_base.h:204]
│ 转发到 GetResultImpl
▼
MatmulSchedulerBase::GetResultImpl(LocalTensor) [scheduler_base.h:369]
│ ① CubeOutBuffer::GetTensor() → 从 L0C buffer 取 co1Local
│ ② EnQue / DeQue → 解决流水线依赖
│ ③ 判断是否三角矩阵
▼
CopyCubeOutFixpipe::Copy(co2Local, co1Local) [copy_cube_out_fixpipe.h:84]
│ 转发到 CopyOutImpl
▼
CopyCubeOutFixpipe::CopyOutImpl [copy_cube_out_fixpipe.h:94]
│ C format=ND → CopyOutNZ2ND
▼
CopyCubeOutFixpipe::CopyOutNZ2ND [copy_cube_out_fixpipe.h:152]
│ 构建 FixpipeAdaptor,设置参数
▼
CopyCubeOutFixpipe::CopyTensor [copy_cube_out_fixpipe.h:287]
│ SetCastMode()(float→float 无转换)
▼
FixpipeAdaptor::FixpipeOut [copy_cube_out_utils.h:155]
│ ┌─────────────────────────────────────────────┐
│ │ 关键分支:IsSupportL0CToUB() && PhyPosIsUB │
│ └─────────────────────────────────────────────┘
├── KFC_C310_SSBUF=1 (SSBUF模式):
│ Fixpipe<DstT, SrcT, CFG_ROW_MAJOR_UB>(dst, co1Local, params_)
│ → 硬件 FixPipe 指令:L0C ──→ UB 直出 ✅
│
└── KFC_C310_SSBUF=0 (WORKSPACE模式):
Fixpipe<DstT, SrcT, CFG_ROW_MAJOR>(dst, co1Local, params_)
→ 硬件 FixPipe 指令:L0C ──→ GM
→ 随后还需 DataCopy:GM ──→ UB ❌ 多绕一次
注意到,最后一层调用的是FixpipeAdaptor::FixpipeOut 函数,在copy_cube_out_utils.h:155。
继续加上日志,按照分析应该进入的是--- fixpipe--- 11分支,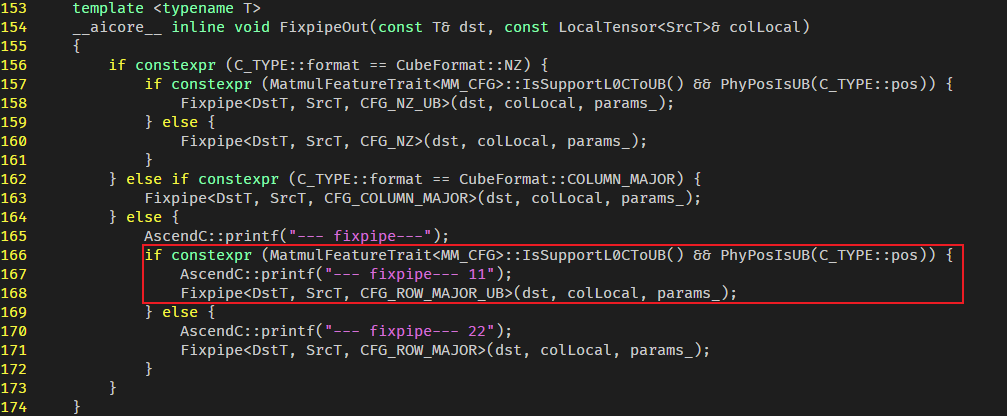
编译运行后,确实是按照预想的路线走的,代码逻辑上已经通了。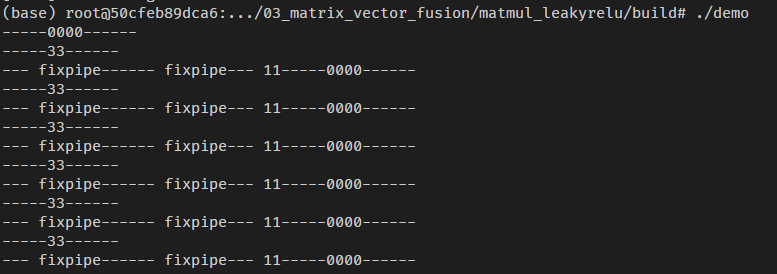
3.6 性能提升如何
终于,代码按照我们预想的路径跑进去了,但是最终效果可不是验证路径,而是验证该新特性对cv融合的算子性能有没提升。于是,性能对比实现开始。
思路:
去掉所有打印,只保留CMakeListstxt中
ENABLE_CV_COMM_VIA_SSBUF的配置
1、保留ENABLE_CV_COMM_VIA_SSBUF,走新特性:L0C → FixPipe → UB 直出;
2、去掉ENABLE_CV_COMM_VIA_SSBUF,走老路:L0C → FixPipe → GM → DataCopy> →UB(必须绕道 GM)
3、测试./demo执行时间,取3次数据平均。
3.6.1 使用linux的time命令进行端到端测试
real:实际流逝的时间(从命令开始到结束的墙上时间) 就像用秒表计时的总时间,包括了程序运行、等待I/O、被其他进程抢占等所有时间。
user:用户态CPU时间(程序在用户空间执行代码所消耗的CPU时间) 程序自己的逻辑代码(如循环、计算、函数调用)占用CPU的时间总和。
sys:内核态CPU时间(程序在内核空间执行系统调用所消耗的CPU时间) 程序申请内核服务(如文件读写、内存分配、网络通信)时,内核为你工作的时间。
3.6.1.1 保留ENABLE_CV_COMM_VIA_SSBUF(新特性)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.216s
user 0m0.305s
sys 0m0.395s
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.015s
user 0m0.299s
sys 0m0.418s
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.022s
user 0m0.300s
sys 0m0.401s
主要关注在real时间,去平均耗时6.084s:
3.6.1.2 去掉ENABLE_CV_COMM_VIA_SSBUF(老路径)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.217s
user 0m0.294s
sys 0m0.433s
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.015s
user 0m0.296s
sys 0m0.408s
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# time ./demo
real 0m6.213s
user 0m0.297s
sys 0m0.428s
主要关注在real时间,平均耗时6.148s:
3.6.1.3 结论
性能就提升1%?
性能数据测试出来,提升很少,猜测是不是host开销时间占比太大。要不就只看设备侧的时间?
3.6.2 打印设备侧执行时间
首先,对代码进行如下修改:
(base) root@50cfeb89dca6:.../00_introduction/03_matrix_vector_fusion/matmul_leakyrelu# git diff matmul_leakyrelu.asc
diff --git a/examples/01_simd_cpp_api/00_introduction/03_matrix_vector_fusion/matmul_leakyrelu/matmul_leakyrelu.asc b/examples/01_simd_cpp_api/00_introduction/03_matrix_vector_fusion/matmul_leakyrelu/matmul_leakyrelu.asc
index 7a2f330fb..0faf1e264 100644
--- a/examples/01_simd_cpp_api/00_introduction/03_matrix_vector_fusion/matmul_leakyrelu/matmul_leakyrelu.asc
+++ b/examples/01_simd_cpp_api/00_introduction/03_matrix_vector_fusion/matmul_leakyrelu/matmul_leakyrelu.asc
@@ -21,6 +21,7 @@
#include "acl/acl.h"
#include "kernel_operator.h"
#include "lib/matmul_intf.h"
+#include <chrono>
__aicore__ inline uint32_t Ceiling(uint32_t a, uint32_t b)
{
@@ -112,7 +113,9 @@ template <typename aType, typename bType, typename cType, typename biasType>
__aicore__ inline void MatmulLeakyKernel<aType, bType, cType, biasType>::MatmulCompute()
{
reluOutLocal = reluOutQueue_.AllocTensor<cType>();
+ // AscendC::printf("----- gettensorc begin----\n");
matmulObj.template GetTensorC<true>(reluOutLocal, false, true);
+ // AscendC::printf("----- gettensorc end----\n");
}
template <typename aType, typename bType, typename cType, typename biasType>
@@ -297,10 +300,15 @@ int32_t main(int32_t argc, char *argv[])
uint8_t *workspaceDevice;
aclrtMalloc((void **)&workspaceDevice, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
+ auto start = std::chrono::high_resolution_clock::now();
matmul_leakyrelu_custom<<<numBlocks, nullptr, stream>>>(inputADevice, inputBDevice, inputBiasDevice, outputCDevice,
workspaceDevice, tiling);
aclrtSynchronizeStream(stream);
+ auto end = std::chrono::high_resolution_clock::now();
+ auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);
+ std::cout << "执行时间: "
+ << duration.count() / 1000.0 << " 毫秒 (ms)" << std::endl;
aclrtFree(inputADevice);
aclrtFreeHost(inputAHost);
@@ -318,4 +326,4 @@ int32_t main(int32_t argc, char *argv[])
aclrtResetDevice(deviceId);
aclFinalize();
return 0;
-}
\ No newline at end of file
+}
在matmul_leakyrelu_custom算子调用前后统计时间,重新编译代码。
3.6.1.1 保留ENABLE_CV_COMM_VIA_SSBUF(新特性)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.536 毫秒 (ms)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.557 毫秒 (ms)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.553 毫秒 (ms)
取平均耗时0.549ms:
3.6.2.2 去掉ENABLE_CV_COMM_VIA_SSBUF(老路径)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.586 毫秒 (ms)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.694 毫秒 (ms)
(base) root@50cfeb89dca6:.../03_matrix_vector_fusion/matmul_leakyrelu/build# ./demo
执行时间: 0.604 毫秒 (ms)
取平均耗时0.628ms:
3.6.2.3 结论
性能提升12%。从端到端的时间看,确实是有提升的。
估计在大shape下面,性能提升会更多。
好了,本次体验到此结束,下次再见。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)