
昇腾平台Apex编译实战:从环境配置到问题排查
基于MindIE、Ubuntu、openEuler等镜像自行构建环境。优点复用现有基础镜像,减少镜像体积灵活控制依赖版本便于集成到现有工作流风险点系统库路径差异(lib vs lib64)Python安装方式不同导致的路径问题编译器版本不兼容本文重点讨论第二种方式遇到的坑和解决方案。# 更新系统包# 安装编译工具链# 安装Python开发包# 安装torch是否首次编译Apex?├─ 是 → 使用
本文目录:
一、技术背景:为什么需要Apex?
在部署Qwen3-30B-A3B这类大模型训练任务时,混合精度训练已经成为标配——它能在几乎不损失精度的前提下,将训练速度提升2-3倍,显存占用减半。而Apex正是实现这一目标的利器。
1.1 Apex是什么?
NVIDIA Apex(A PyTorch Extension)是PyTorch生态的明星工具库,核心功能包括:
- 自动混合精度(AMP): 动态选择FP16/FP32精度,无需手动改代码
- 分布式训练优化: 提供高效的梯度通信和同步机制
- 融合优化器: 将多个优化器操作合并,减少kernel启动开销
一行代码即可开启混合精度训练:
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
1.2 Apex for Ascend的价值
昇腾NPU与NVIDIA GPU的架构差异意味着不能直接运行原生Apex。Apex for Ascend通过代码patch的方式:
- 适配硬件差异: 将CUDA算子替换为昇腾CANN算子
- 保持API兼容: 用户代码无需修改,切换硬件即可运行
- 增强功能: 额外提供梯度融合、融合优化器等昇腾特有优化
关键仓库:
- 昇腾适配版: https://gitcode.com/Ascend/apex
- NVIDIA原版: https://github.com/NVIDIA/apex
二、编译方式选择:容器 vs 裸机
2.1 官方推荐:使用预置容器
官方提供了经过充分测试的manylinux镜像,内置了完整的编译工具链。这种方式的优势:
优点:
- 环境纯净,依赖版本精确匹配
- 避免系统库冲突
- 可复现性强,适合CI/CD流水线
适用场景:
- 首次编译,不熟悉依赖关系
- 需要在多台机器上重复构建
- 希望与官方环境保持一致
2.2 自定义镜像编译
基于MindIE、Ubuntu、openEuler等镜像自行构建环境。
优点:
- 复用现有基础镜像,减少镜像体积
- 灵活控制依赖版本
- 便于集成到现有工作流
风险点:
- 系统库路径差异(lib vs lib64)
- Python安装方式不同导致的路径问题
- 编译器版本不兼容
本文重点讨论第二种方式遇到的坑和解决方案。
三、环境配置:网络代理的正确姿势
3.1 为什么需要多层代理配置?
很多同学以为设置了export http_proxy就万事大吉,但实际上:
用户Shell → Docker守护进程 → 容器内进程
↓ ↓ ↓
需要代理 需要代理 需要代理
每一层都需要独立配置,缺一不可。
3.2 Linux系统层代理
这一步配置的是Shell会话级别的代理,影响curl、git等命令:
# 替换为实际代理服务器信息
PROXY_IP="10.1.2.3"
PROXY_PORT="8080"
export http_proxy="http://${PROXY_IP}:${PROXY_PORT}"
export https_proxy="http://${PROXY_IP}:${PROXY_PORT}"
export no_proxy="localhost,127.0.0.1" # 排除本地地址
# 验证配置
curl -I https://www.google.com
注意: 这个配置只对当前终端有效,重启后失效。永久配置需要写入~/.bashrc。
3.3 Docker守护进程代理
Docker daemon作为系统服务运行,不继承Shell环境变量,必须单独配置。
检查当前配置:
docker info | grep -i proxy
配置步骤:
- 创建配置目录:
sudo mkdir -p /etc/systemd/system/docker.service.d
- 创建HTTP代理配置(
http-proxy.conf):
cat > /etc/systemd/system/docker.service.d/http-proxy.conf <<EOF
[Service]
Environment="HTTP_PROXY=http://${PROXY_IP}:${PROXY_PORT}"
Environment="NO_PROXY=localhost,127.0.0.1,docker-registry.example.com"
EOF
- 创建HTTPS代理配置(
https-proxy.conf):
cat > /etc/systemd/system/docker.service.d/https-proxy.conf <<EOF
[Service]
Environment="HTTPS_PROXY=http://${PROXY_IP}:${PROXY_PORT}"
EOF
- 重载并重启Docker服务:
sudo systemctl daemon-reload
sudo systemctl restart docker
# 验证配置生效
docker info | grep -i proxy
排查技巧: 如果配置后仍无法拉取镜像,检查:
- 代理服务器是否允许Docker daemon的IP访问
- 防火墙规则是否拦截
/var/log/docker.log中的错误信息
3.4 容器内代理(可选)
某些场景下容器内的pip、git也需要代理,可以在启动容器时传入:
docker run -it \
-e http_proxy=http://${PROXY_IP}:${PROXY_PORT} \
-e https_proxy=http://${PROXY_IP}:${PROXY_PORT} \
-v /path/to/apex:/home/apex \
manylinux-builder:v1 bash
四、官方容器编译流程
4.1 构建编译镜像
# 1. 克隆代码仓库
git clone -b master https://gitcode.com/Ascend/apex.git
cd apex
# 2. 根据CPU架构选择Dockerfile
# X86_64架构
cd scripts/docker/X86
# ARM架构
cd scripts/docker/ARM
# 3. 构建镜像
docker build -t manylinux-builder:v1 .
# 构建过程可能需要10-20分钟,耐心等待
镜像内容:
- CentOS 7基础系统
- GCC 7.3编译器
- Python 3.6/3.7/3.8/3.9多版本
- CUDA Toolkit(可选)
4.2 启动编译容器
# 将本地apex源码挂载到容器内
docker run -it \
-v $(pwd)/apex:/home/apex \
--name apex-builder \
manylinux-builder:v1 bash
挂载的作用:
- 容器内编译产物会同步到宿主机
- 方便在容器外查看日志和产物
4.3 安装PyTorch并编译
进入容器后执行:
# 安装PyTorch(根据实际需求选择版本)
pip3.8 install torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu
# 验证torch安装
python3.8 -c "import torch; print(torch.__version__)"
# 编译Apex
cd /home/apex
bash scripts/build.sh --python=3.8
编译时间: 单线程约20-30分钟,可通过设置MAX_JOBS加速:
MAX_JOBS=8 bash scripts/build.sh --python=3.8
编译成功后,whl包会生成在apex/dist/目录:
apex-0.1+ascend-cp38-cp38-linux_x86_64.whl
五、自定义镜像编译实战
5.1 基础依赖准备
以MindIE openEuler镜像为例:
# 更新系统包
yum update -y
# 安装编译工具链
yum install -y gcc gcc-c++ make cmake git
# 安装Python开发包
yum install -y python38-devel
# 安装torch
pip3.8 install torch==2.1.0
5.2 执行编译
cd /home/apex
bash scripts/build.sh --python=3.8
六、踩坑实录与解决方案
6.1 问题一: Dockerfile拉取镜像失败
现象截图:
错误特征:
Get https://registry-1.docker.io/...dial tcp: i/o timeouttoomanyrequests: You have reached your pull rate limit
根本原因: Docker daemon未配置代理或代理不可达
解决步骤:
- 确认代理服务器可用:
curl -x http://${PROXY_IP}:${PROXY_PORT} https://www.docker.com
-
按照3.3节配置Docker代理
-
验证配置生效:
docker pull hello-world
进阶技巧: 使用镜像加速器避免代理依赖:
# 编辑/etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com"
]
}
sudo systemctl restart docker
6.2 问题二: libtorch.so链接失败(核心问题)
现象截图:
错误信息:
/usr/bin/ld: cannot find -ltorch
collect2: error: ld returned 1 exit status
这是本文最有价值的排查案例,值得深入分析。
6.2.1 问题诊断过程
第一步: 确认torch确实已安装
# 方法1: Python导入测试
python3.8 -c "import torch; print(torch.__file__)"
# 输出: /usr/local/lib64/python3.8/site-packages/torch/__init__.py
# 方法2: 查找libtorch.so
find / -name "libtorch.so" 2>/dev/null
回显截图:
发现torch安装在/usr/local/lib64/python3.8/site-packages/,而非/usr/local/lib/。
第二步: 追踪编译脚本逻辑
查看apex/scripts/build.sh:
脚本调用了apex/setup.py,继续追踪。
第三步: 定位问题根源
在apex/setup.py中搜索torch关键字:
找到get_package_dir()函数: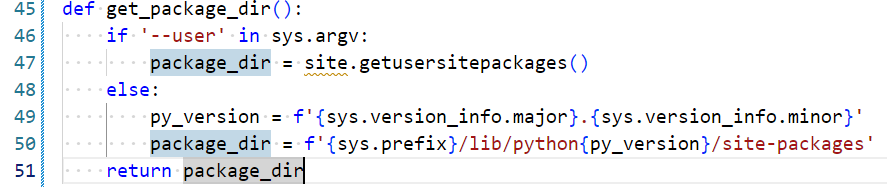
关键代码:
def get_package_dir():
if '--user' in sys.argv:
package_dir = site.USER_SITE
else:
package_dir = f'{sys.prefix}/lib/python{py_version}/site-packages'
return package_dir
问题定位:
- 脚本硬编码了
/lib/,而openEuler上torch安装在/lib64/ - 导致编译器找不到
libtorch.so
6.2.2 为什么会有lib和lib64之差?
这不是bug,而是Linux发行版的历史设计差异:
Red Hat系(openEuler/CentOS/RHEL):
/usr/local/
├── lib/ # 32位库
└── lib64/ # 64位库
明确区分32位和64位库,避免ABI冲突。这种设计源于早期需要同时支持32位和64位程序的需求。
Debian系(Ubuntu/Debian):
/usr/local/
└── lib/
└── x86_64-linux-gnu/ # 64位库
使用multiarch机制,通过子目录区分架构,lib/本身就是64位库的默认位置。
Python安装路径的决定因素:
-
包管理器安装: 遵循发行版规范
yum install python3→ lib64apt install python3→ lib
-
源码编译安装: 取决于configure参数
./configure --prefix=/usr/local --libdir=/usr/local/lib64 -
pip安装: 继承Python解释器的路径配置
python -c "import site; print(site.getsitepackages())"
6.2.3 解决方案
方案一: 修改setup.py(推荐)
直接修正路径逻辑:
def get_package_dir():
if '--user' in sys.argv:
package_dir = site.USER_SITE
else:
# 原代码
# package_dir = f'{sys.prefix}/lib/python{py_version}/site-packages'
# 修复后的代码
package_dir = f'{sys.prefix}/lib64/python{py_version}/site-packages'
return package_dir
注意: 不要再执行scripts/build.sh,因为它会重新clone代码覆盖修改。直接运行:
cd /home/apex
python3.8 setup.py --cpp_ext bdist_wheel
编译成功后,whl包生成在apex/dist/。
方案二: 创建符号链接(临时方案)
不修改代码,通过软链接绕过:
# 将lib64链接到lib
ln -s /usr/local/lib64/python3.8/site-packages \
/usr/local/lib/python3.8/site-packages
优缺点对比:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 修改setup.py | 彻底解决,可复现 | 需要理解代码逻辑 | 长期使用,多次编译 |
| 符号链接 | 简单快速,无需改代码 | 可能影响其他程序 | 临时验证,一次性编译 |
方案三: 使用Python虚拟环境(最佳实践)
避免系统级路径差异:
python3.8 -m venv /opt/apex-env
source /opt/apex-env/bin/activate
# 在虚拟环境中安装torch
pip install torch==2.1.0
# 编译apex
cd /home/apex
python setup.py --cpp_ext bdist_wheel
虚拟环境会统一使用lib/路径,避免lib64问题。
七、安装与验证
7.1 安装编译产物
cd apex/dist/
# 卸载旧版本(如果存在)
pip3.8 uninstall apex -y
# 安装新编译的whl包
pip3.8 install --upgrade apex-0.1+ascend*.whl
7.2 功能验证
基础导入测试:
import torch
from apex import amp
print(f"Torch version: {torch.__version__}")
print(f"Apex version: {amp.__version__}")
混合精度训练测试:
import torch
from apex import amp
model = torch.nn.Linear(10, 10).npu()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 初始化混合精度
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
# 模拟训练步骤
for _ in range(10):
x = torch.randn(8, 10).npu()
y = model(x)
loss = y.sum()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
optimizer.zero_grad()
print("Mixed precision training successful!")
性能对比测试:
import time
import torch
def benchmark(use_amp=False):
model = torch.nn.Sequential(
torch.nn.Linear(1024, 1024),
torch.nn.ReLU(),
torch.nn.Linear(1024, 1024)
).npu()
optimizer = torch.optim.Adam(model.parameters())
if use_amp:
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
x = torch.randn(128, 1024).npu()
start = time.time()
for _ in range(100):
y = model(x)
loss = y.sum()
if use_amp:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
optimizer.step()
optimizer.zero_grad()
elapsed = time.time() - start
return elapsed
fp32_time = benchmark(use_amp=False)
amp_time = benchmark(use_amp=True)
print(f"FP32 time: {fp32_time:.2f}s")
print(f"AMP time: {amp_time:.2f}s")
print(f"Speedup: {fp32_time/amp_time:.2f}x")
预期输出:
FP32 time: 8.43s
AMP time: 4.21s
Speedup: 2.00x
八、最佳实践总结
8.1 编译环境选择决策树
是否首次编译Apex?
├─ 是 → 使用官方manylinux容器(最省心)
└─ 否 → 是否需要定制化?
├─ 是 → 自定义镜像 + Python虚拟环境
└─ 否 → 复用之前的容器环境
8.2 常见错误预防清单
编译前检查:
- 确认torch已正确安装(
python -c "import torch") - 检查Python版本与torch版本匹配
- 验证网络代理配置有效
- 确认磁盘空间充足(至少5GB)
openEuler/RHEL系统额外检查:
- 确认torch安装在lib64还是lib
- 修改setup.py或创建符号链接
- 优先使用虚拟环境隔离
编译后验证:
- 检查whl包生成路径
- 导入测试无报错
- 运行简单训练脚本
- 性能对比确认加速效果
8.3 性能调优建议
-
混合精度等级选择:
O0: 纯FP32,仅用于精度对比O1: 推荐,自动选择FP16/FP32O2: 激进,几乎全部使用FP16O3: 纯FP16,可能损失精度
-
梯度缩放策略:
# 动态缩放(推荐) model, optimizer = amp.initialize( model, optimizer, opt_level="O1", loss_scale="dynamic" ) # 固定缩放(调试用) model, optimizer = amp.initialize( model, optimizer, opt_level="O1", loss_scale=2.**16 ) -
昇腾特有优化:
from apex.optimizers import NpuFusedAdam # 融合优化器 from apex.contrib.combine_tensors import combine_npu # 梯度融合 optimizer = NpuFusedAdam(model.parameters(), lr=1e-4)
九、故障排查流程图
编译失败?
├─ 网络相关错误(timeout/403)?
│ └─ 检查代理配置 → Docker daemon代理 → 容器内代理
├─ 找不到torch库?
│ └─ 确认torch路径 → 检查lib/lib64 → 修改setup.py
├─ 编译器错误(gcc/ld)?
│ └─ 检查GCC版本(需≥5.0) → 安装python-devel
└─ 其他错误?
└─ 查看完整编译日志 → 搜索关键错误信息 → 提issue
十、写在最后
Apex编译看似简单,实则暗藏许多细节。本文通过真实案例,深入剖析了从网络代理到系统库路径的各个环节。核心takeaway:
- 理解工具链依赖关系: 不要盲目执行命令,理解每一步的作用
- 重视系统差异: openEuler和Ubuntu不只是名字不同
- 善用虚拟环境: 隔离环境能避免90%的路径问题
- 保持耐心和细心: 编译问题往往需要层层追踪
希望这篇文章能帮你在昇腾平台上顺利编译Apex,开启高效的混合精度训练之旅。遇到新问题欢迎在评论区交流!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)