
CANN-Bench设计解读-如何构建一个Agent-Native的算子评测体系
AI大模型和Harness 工程快速发展的今天,模型+Agent的组合使得复杂系统级代码开发任务门槛进一步降低,昇腾CANN作为算力基础设施的一部分,也迎来了从古法编程到AI编程的关键转折,CANN领域中的算子开发效率出现了数量级的提升,但选择什么样的模型,使用哪个Agent能够产出高质量的算子,成了开发经常遇到的问题。数据层是整个评测体系的基础,CANN-Bench通过“算子定义+测试用例+真值
AI大模型和Harness 工程快速发展的今天,模型+Agent的组合使得复杂系统级代码开发任务门槛进一步降低,昇腾CANN作为算力基础设施的一部分,也迎来了从古法编程到AI编程的关键转折,CANN领域中的算子开发效率出现了数量级的提升,但选择什么样的模型,使用哪个Agent能够产出高质量的算子,成了开发经常遇到的问题。
为此,我们专为昇腾CANN平台量身打造一套标准化、自动化的Agent Native评测体系开源项目CANN-Bench(https://gitcode.com/cann/cann-bench)。
CANN-Bench是什么
CANN-Bench提供了一套覆盖“标准评测任务-Agent-Native的评测框架-Leaderboard榜单”的全流程的基准测试体系。提供标准化的任务和工程,易扩展易使用;联合学界和社区一起建立覆盖精度、泛化、性能多维度评测标准和框架,保障评测的科学性和公正性;建立Leaderboard榜单,结果可以横向对比。
CANN-Bench构建了数据层、评测层、平台层三层架构,兼顾稳定性与灵活性,可满足各类场景的评测需求,以下为大家详细拆解CANN-Bench的核心设计思想。
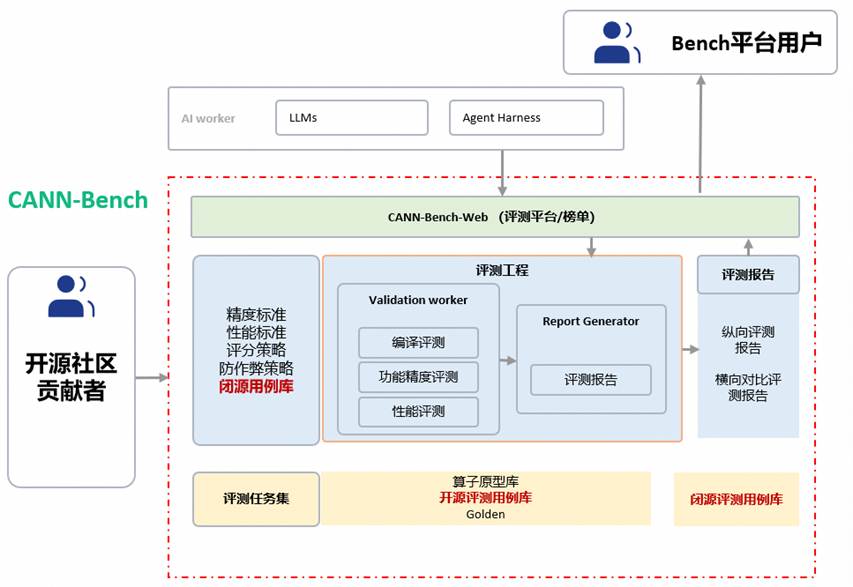
数据层是整个评测体系的基础,CANN-Bench通过“算子定义+测试用例+真值脚本+工程样例”的标准化组合,保障评测的公平性与可复现性,同时为开源社区贡献者制定统一的评测任务定义范式。
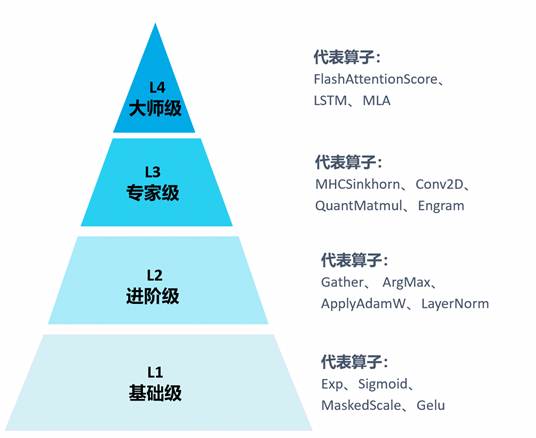
初始算子评测集由53个覆盖典型开发范式的算子组成,根据计算流、计算模式,定义了L1~L4四个难度等级,实现从简单向量算子,到复杂张量&向量融合算子全场景覆盖。
|
等级 |
分类原则 |
数量 |
|
L4 |
复杂CV融合算子:如Attentions、Transformer-block等 |
8 |
|
L3 |
张量&简单融合算子:如矩阵乘/卷积、初阶CV融合等 |
21 |
|
L2 |
进阶向量算子:MIMO(多输入输出)、归约类、索引类等 |
16 |
|
L1 |
简单向量算子:例如SISO(单输入单输出)、Element-wise、激活函数等 |
8 |
每个待评测的算子任务均包含以下三个标准文件和一个markdown说明。
proto.yaml:明确算子接口、参数类型及约束条件等结构化算子原型信息;

cases.csv:规范化算子用例标准格式,包含shape、dtype、value_range和基准性能;

golden.py:算子标杆实现,避免文档中对公式语义描述歧义;

为了统一待评测算子的交付件,项目提供aclnn_launch、direct_launch两种标准工程样例。整体目录结构如下:

待评测算子工程核心交付件为build.sh, 目的是在dist目录打包出待评测算子whl包和自定义算子run包(可选),其他文件和目录结构为参考。
CANN-Bench不仅仅局限于单一误差评测,它构建了覆盖编译、精度、性能的多维度评测体系,所有标准均贴合工业实际应用场景进行设计。
- 编译正确性(权重20%):优先检验算子代码编译可行性,对编译失败的算子自动屏蔽,编译维度的评测用于衡量模型/Agent对昇腾算子语法的基础理解程度。
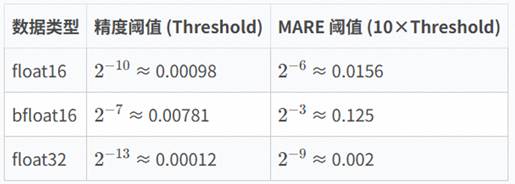
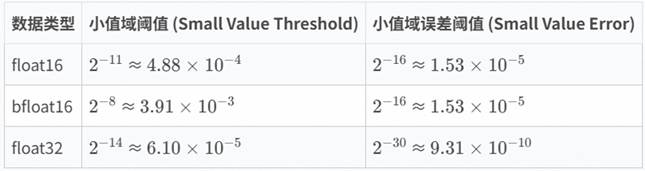
- 精度正确性(权重30%):采用工业级精度标准,设计了“基础误差+场景化误差”的多维度对比体系。基于ULP误差分析,覆盖正常阈值、小值域、相消位置及Inf/Nan值等特殊场景,确保算子计算结果精准可靠,且具备可行性。对于浮点类型的比对,标杆采用更高精度数据类型(一般为FP64)计算。
正常值域下的数据采用平均相对误差(MERE)+最大相对误差(MARE),MERE阈值为待评测数据类型下1ULP误差,MARE则为10倍MERE:

算子输出结果为极小值(接近0)时,相对误差计算可能不稳定,采用小值域误差标准:
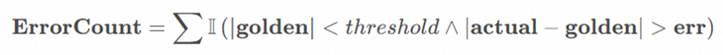
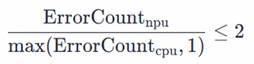
对于量化、Inf/Nan等特殊场景下,无法直接使用相对误差进行比对,采用特殊值标准:

- 性能优化性(权重50%):以“官方基线+硬件理论极限”为双标杆,通过升频预热、L2清理等底层手段,保证硬件在相同的初始状态下运行,利用Profiler工具精准采集NPU内核运行时间,排除Host环境差异干扰。
官方基线采用算子仓中现有算子运行在NPU上采集到的性能数据,或基于Golden小算子运行在NPU上到的性能数据。
硬件理论极限假设NPU各执行单元跑到 spec 峰值、完美 overlap、无 launch 开销。
硬件理论极限公式:![]()
K = { Cube, Vector, MTE1, MTE2, MTE3, FixP } 是NPU上的六个并发执行单元;
tk(δ) 是单元 k 在实现配置 δ 下的工作时间。
性能评分公式:
Tcand 是 AI 提交(待评测算子实现)的实测时间
Tbaseline 是官方提供的该算子当前算子仓的性能基准
公式将 Tbaseline 对齐到 0.5,THW 对齐到 1.0,衰减到 0。
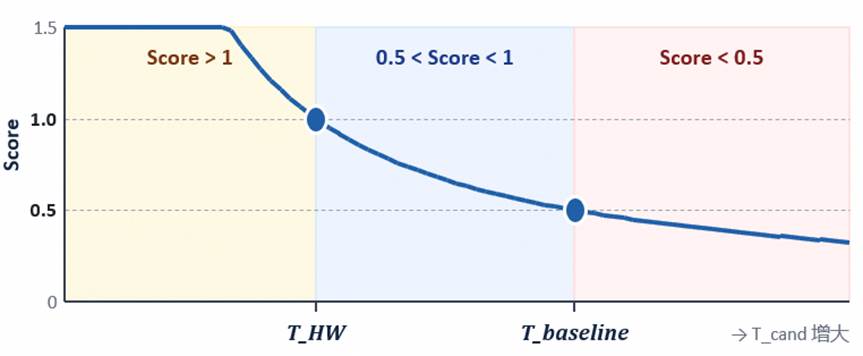
Score < 0.5 : 待评测的算子实现的比参考实现还慢
0.5 < Score < 1 :在原算法范围内做出了实质优化,Score 越接近 1,越逼近硬件极限
Score > 1 : 实现了算法层面的创新,超出了原算法实现的理论极限
CANN-Bench提供评测报告查看和在线榜单系统,实现“提交-评测-榜单展示”全链路自动化。CANN-Bench的在线榜单平台预计6月份正式上线。
CANN-Bench的开源,不仅为开发者提供了高效的算子评测工具,更搭建了开放的交流平台,推动AI能力在CANN领域的持续演进。无论你是CANN领域的开发新手,还是资深的生态开发者,都能在这个项目中获得支持:
- 快速入门:查看docs目录的quick_start指南,快速搭建评测环境,完成第一个算子的评测;
- 进阶了解:参考docs中的评测体系设计文档、性能设计方案、精度设计方案、更深入的了解评测体系的构建思路;
- 生态贡献:参与项目共建,参考docs中的contributing指南了解贡献流程,提交新的评测任务,新的评测方法。
📌 项目地址:https://gitcode.com/cann/cann-bench
📖 详细文档:https://gitcode.com/cann/cann-bench/tree/master/docs
每一次评测标准的完善,每一个评测集任务的加入,都在推动昇腾生态的进步。CANN-Bench始终秉持“开放易用”的愿景,期待你的参与,一起构筑根深叶茂、跨产业协同共享共赢的CANN生态,让AI算力绽放更大价值!

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)