
【MindSDK】HSTU融合算子在昇腾平台实现4倍加速突破
当前HSTU已在多个大型互联网平台部署,支持数十亿日活用户的推荐服务。其创新性不仅在于技术架构的改进,更在于为推荐系统领域带来了类似LLM的扩展定律,被业界视为推荐系统的"ChatGPT时刻"。
作者:昇腾实战派
1. 摘要
当前HSTU已在多个大型互联网平台部署,支持数十亿日活用户的推荐服务。其创新性不仅在于技术架构的改进,更在于为推荐系统领域带来了类似LLM的扩展定律,被业界视为推荐系统的"ChatGPT时刻"。
昇腾平台的CUBE和VECTOR分离架构,其强大的CUBE算力与L2Cache互联融合,混合精度计算,为我们提供了国产化实现该算子的硬件底座,在该底座上在结合硬件的特点,并参考已有的一些昇腾优化算法,在该HSTU融合算子上实现负载均衡的序列并行,L2Cache友好,Bank冲突小,根据掩码省略部分计算等融合优化策略到达相比非融合的4X性能提升,并相比国外竞品从算力规格上达到一定的性价比优势。
2. 技术背景
HSTU(Hierarchical Sequential Transduction Unit,分层序列转导单元)是Meta公司提出的一种针对推荐系统优化的高效注意力机制,代表了生成式推荐系统领域的重要突破。
arXiv链接:https://arxiv.org/abs/2402.17152
其结构如下图所示:
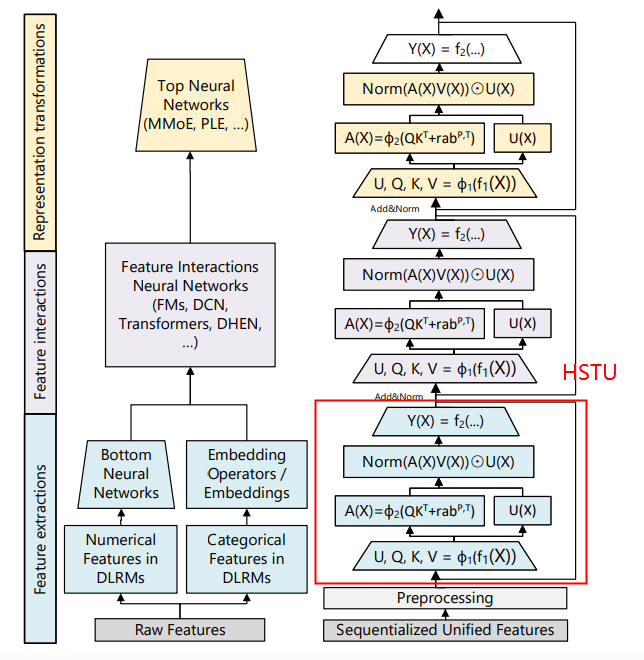
图1 HSTU BLOCK
2.1 业界痛点:HSTU融合算子是GR模型效率的核心瓶颈
在目前主流的推荐(GR)模型中,HSTU融合算子已非普通组件,而是承载了模型核心记忆与泛化能力的基石。其痛点主要体现在:
- 极高的计算消耗占比
在典型的GR模型推理过程中,HSTU融合算子及其相关计算,往往占据了端到端计算耗时/算力消耗的40%以上。这意味着,该算子的性能直接决定了整个推荐系统的服务吞吐与延迟上限,是其最关键的性能热点。
- 随模型扩展而急剧放大的瓶颈
遵循推荐系统的扩展定律,模型效果随参数与数据规模提升而显著增强。然而,HSTU算子的计算复杂度通常以近平方级 随序列维度增长。这导致了一个严峻矛盾:模型越大,效果越好,但HSTU算子的计算瓶颈也越突出,成为制约模型规模与效果继续提升的“天花板”
结论:
因此,攻破HSTU算子的性能瓶颈,就等于抓住了GR模型降本增效的“牛鼻子”。我们在昇腾平台上实现的4倍性能提升,不仅仅是单点算子的飞跃,更是将整个GR模型的推理效率提升到了一个全新高度
3. 昇腾平台上高性能实现
3.1 从公式映射到算力芯片
整体的HSTU Attention部分如下图所示:
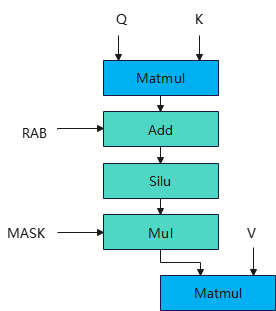
图2 HSTU ATTN公式
通过Hstu的计算图我们可以发现该算子存在2个Matmul ,3个矢量计算,因此可以参考FlashAttention的融合思路进行CV融合,昇腾微架构如下,可以发现参与Matmul运算的Cube核和参与矢量运算的Vector相互隔离,中间通过L2Cache进行互通,这为我们实现Cube流水和Vector流水互相掩盖带来了可能。
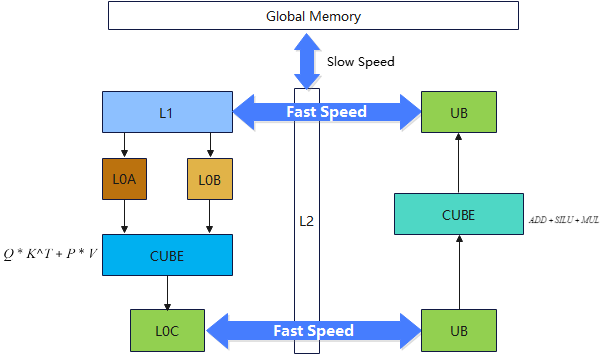
图3 昇腾微架构
并且得益于昇腾AscendC提供了强大的高阶Matmul API和Silu高阶API的运算接口,方便我们开发者快速开发验证。
昇腾社区Matmul 高阶API:
Matmul使用说明-CANN社区版9.0.0-beta.2-昇腾社区 (hiascend.com)
昇腾社区Silu 高阶API:
Silu-CANN社区版9.0.0-beta.2-昇腾社区 (hiascend.com)
3.2 TILE追求更好的局部性
3.2.1 什么是TILE块,为何要进行切分?
在这里我们首先要解释为什么要对输入的q,k,v矩阵进行分块处理,主要是由以下几个方面来考虑:
L1,L0片上资源不够
如下图所示 CUBE的L1资源只有512Kbyte,因此在输入Q,K,V很大的时候无法放入整个大的矩阵,因此我们需要对输入的Q,K,V进行分块处理,这一个过程叫做tilling,分的块也叫做tile。
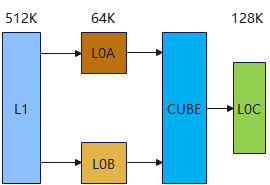
图4 CUBE 数据通路
L2Cache局部性原则
根据存储器体系结构中原理越靠近芯片的部分内存越贵但是速度越快资源也越少,越远离芯片的部分内存越便宜但是速度较慢有足够的存储内存。因此在很多算子的设计上,都会把会频繁访问的内存尽可能的让他常驻在L0, L1, L2 存储上,比如在FA算子会把中间过程放在SRAM上。
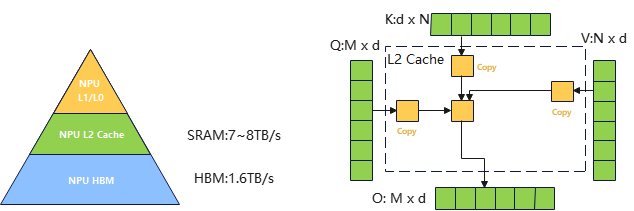
图5 缓存亲和设计
如上图所示通过将矩阵乘法的中间过程结果存放在L2Cache中,可以减少对HBM的访问,提升算子的Cache命中率,从而提升算子的性能。
3.2.2 如何选取合适的TILE块?
在TILE块选取时,主要考虑以下几个因素:
3.2.2.1 L1/L0的资源大小
由于L1/L0的资源是有限的,因此我们在不同的级别做TILING,比如在L1上做L1的tile切分,L0上做L0的tile 切分,本质就是在不同级别的物理存储上,根据其物理资源的大小切片,保证不会超过其物理资源上限,同时为了保证计算密度,我们的TILE也要尽可能用满L1/L0的物理资源,因此我们可以得到多级tiling。
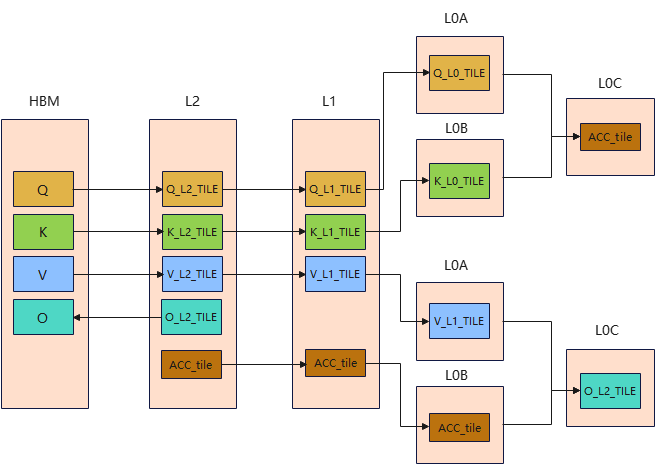
图6 多级tiling
L1 tiling:
L1 大小为512KB,但是我们会考虑跟L2Cache做double buffer,掩盖部分L2搬运的时延,则L1 可以使用的buffer大小为256KB。
L0 tiling:
L0A和L0B大小为64KB,同样我们也会考虑跟L1搬运做double buffer,掩盖L1搬运的时延,则L0可以使用的buffer大小为32KB。
L0C tiling:
同样对于L0C来说,L0C一共有128KB,但是也要考虑跟mmad做double buffer,因此可以使用的buffer大小为64KB
通过以上硬件约束对于FP16/BF16的数据类型来说,我们可以得到如下的公式:
L1 – (M_L1 * K + N_L1 * K + M_L1 * N_L1 + N_L1 * K) * 2 <= 256KB
L0A – (M_L0 * K) * 2 <= 32KB
L0A --(M_L0 * N_L0) * 2 <=32KB
L0B – (N_L0 * K) * 2 <= 32KB
L0C – (M_L0 * N_L0)* 4 <= 64KB
并且考虑到L2Cache的CacheLine是128B,因此M_L1,N_L1最好是(128/2)=64的整数倍。假设K=64
| 组编号 | L1 TILE | L0 TILE |
|---|---|---|
| 0 | [128, 128] | [128, 128] |
| 1 | [256, 256] | [128, 128] |
| 2 | [128, 256] | [128, 128] |
3.2.2.2 计算访存比
因为L1是L2的入口,因此同样从L1的视角去考虑搬运和计算的计算访存比。
同样假设Q矩阵的TILE块为[M_L1,K], KV矩阵的TILE块为[N_L1, K],数据类型为FP16/BF16。
CUBE 计算量:
QK+PV = 4 * M_L1 * N_L1 * K
CUBE 搬运量:
QK+PV = (M_L1 * K + N_L1 * K + M_L1 * N_L1 + N_L1 * K) * 2
则计算访存比:
R = 2 / (1 / N_L1 + 1 / M_L1 + 1 /K)
从上面公式看出,当K固定时,N_L1,M_L1越大则计算访存比越大,计算越能掩盖搬运的内存时延。
在确定峰值算力(PeakFlops)前提下,可以计算出最低的带宽要求B:
B = (PeakFlops) / R
在已知硬件规格缓存带宽B_cache, HBM带宽B_hbm前提下可以计算出最低需要的缓存命中率N:
B = N * B_cache + (1 – N) * B_hbm
可以计算出候选的TILE对应需求最低缓存命中率:
| 组编号 | B_cahe | B_hbm | 最低要求B | 最低要求N | TILE组 |
|---|---|---|---|---|---|
| 0 | 7.8T | 1.6T | 5.5T | 63% | [128,128] |
| 1 | 7.8T | 1.6T | 4.1T | 41% | [256,256] |
| 2 | 7.8T | 1.6T | 4.8T | 52% | [128,256] |
因此在L1/L0缓存资源足够的前提下选择[256,256]作为TILE块。
3.3 序列长度维度进行并行
3.3.1 非序列并行调度
用户的输入序列是[totalSeqs, head, dim]进行组织,也叫做jagged格式是为了节省显存从[batch, seqs, head, dim]去掉padding之后的格式。其中totalSeqs = batch_size * seqs(去掉padding)之后的长度,如下图所示。
dense格式:
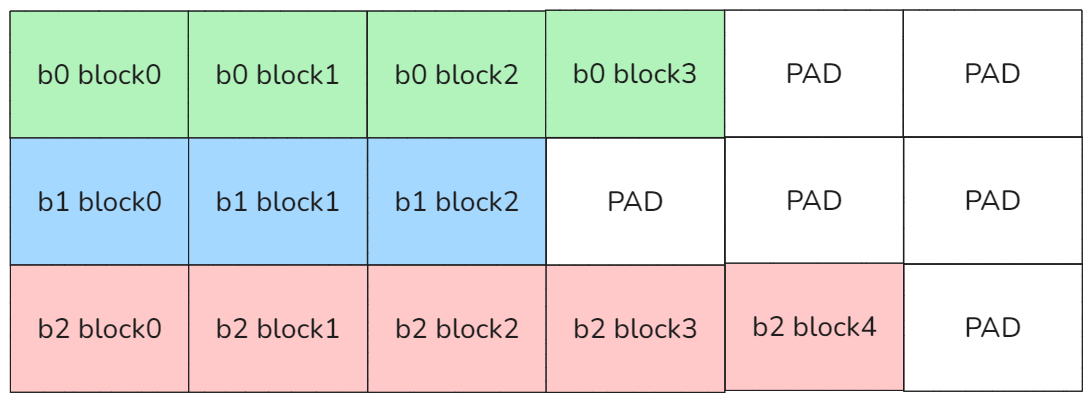
图7 dense格式
jagged格式: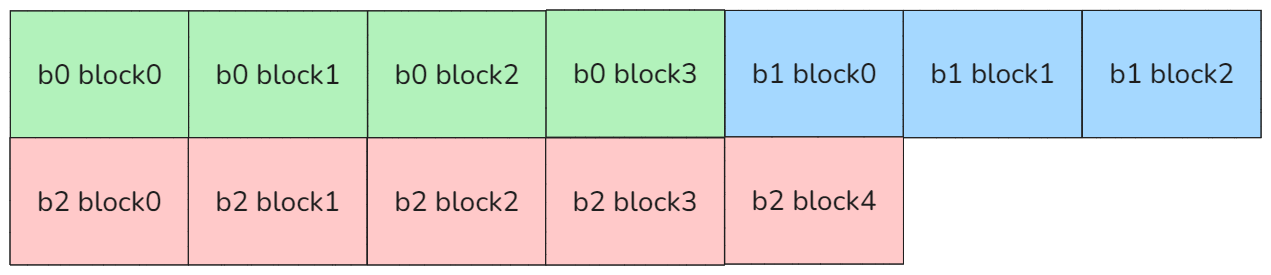
图8 jagged格式
在dense格式下序列进行分核可以简单按照batch * heads进行不需要进行序列并行就可以保证核间负载均匀,但是如果在jagged格式依然按照这种方式分核,容易导致比较严重的Long Tail Effect 问题,如下图所示:
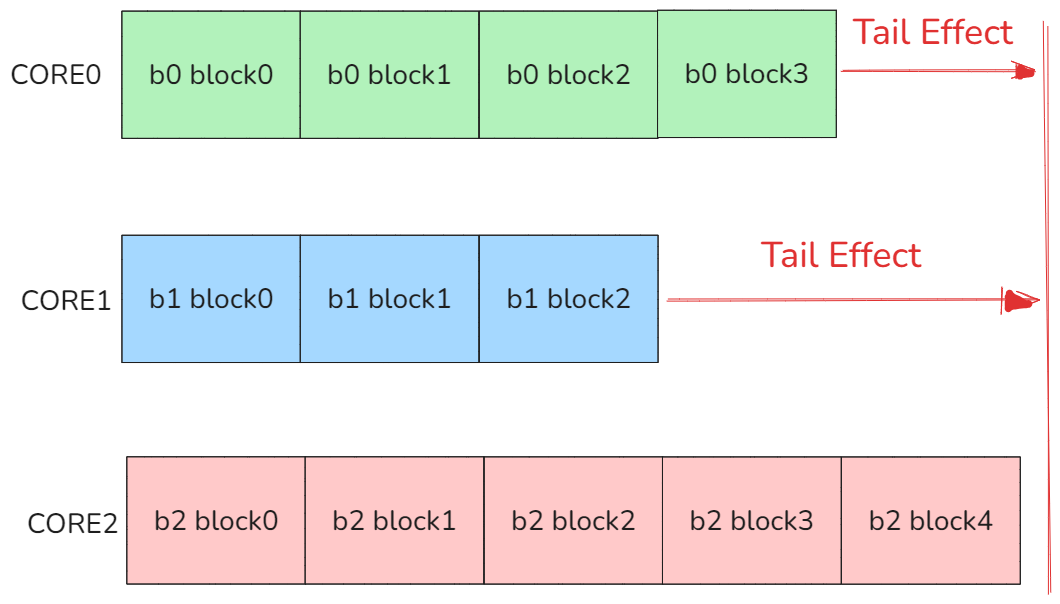
图9 Long Tail Effsect
3.3.2 Naive 序列并行调度
因此在jagged分核就必须在token,序列维度上进行分核,比较naive的想法就是将整个seqs都展开,根据(seqs + block_size - 1) / block_size的方式计算block个数,然后让block在多核之间进行均分,如下图所示: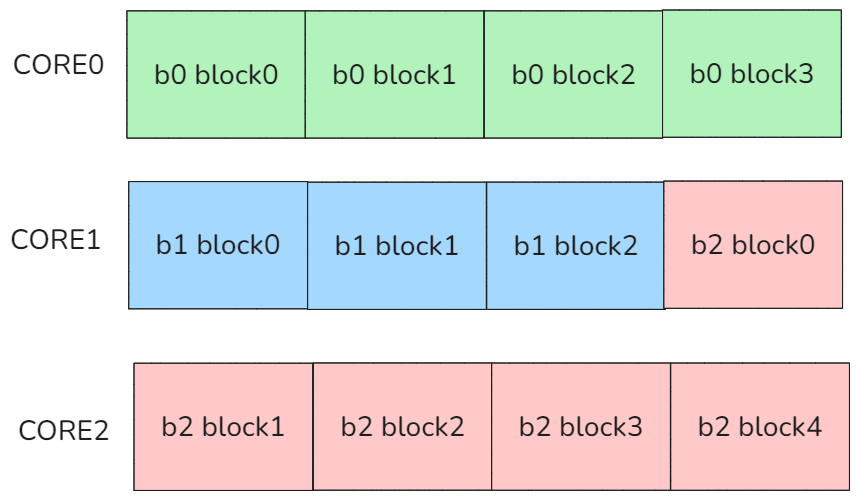
图10 Token均分调度
但是这种方式在长序列场景下,容易导致core与core之间相隔很远导致cache无法放下因此必然会频繁导致cache evict,进而引发性能下降的问题,如下图所示:
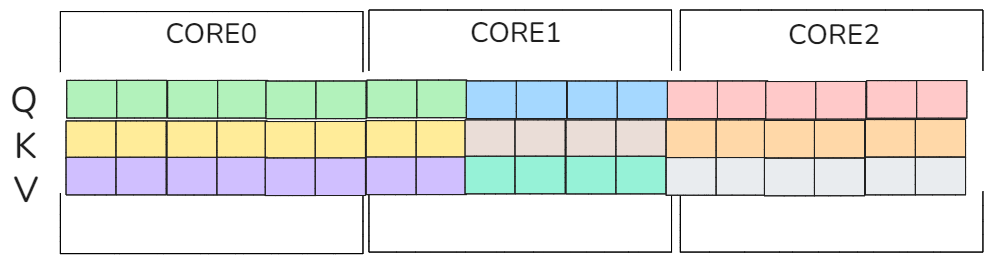
图11 Core均分分布
由于每个序列都很长因此展开后,每个core之间相隔很远,core与core之间很可能跨序列,比如上图中core1横跨了b1,b2的序列,这样导致L2Cache中不得不存放下所有的KV矩阵,假设L2Cache只能访问b0,b1的KV矩阵那么core2访问b=2的kv矩阵的时候就不得不淘汰部分L2Cache数据导致严重的cache evict。
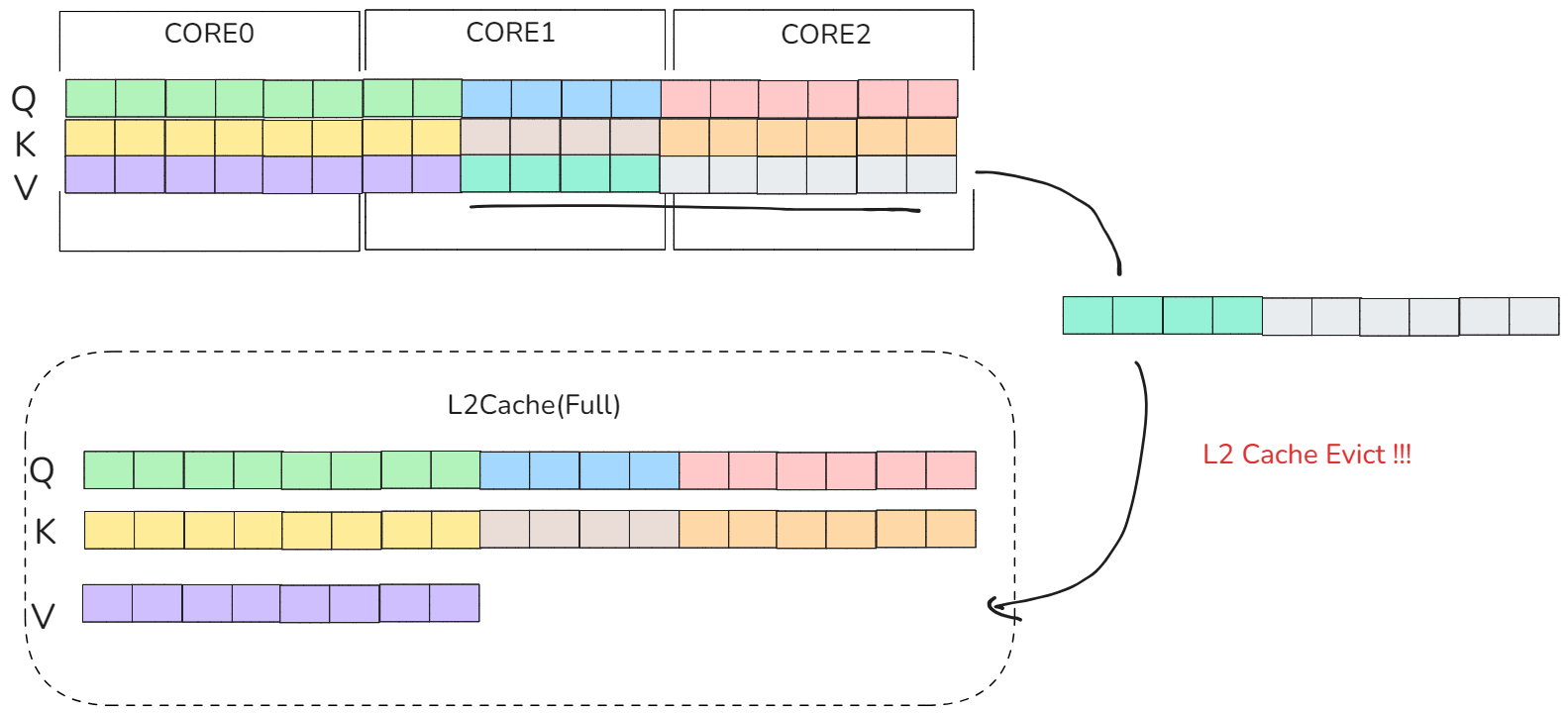
图12 Cache Evict
3.3.3 RoundRobin 序列并行调度
为了解决这个问题,我们需要再次衡量我们分核序列并行策略,其主要原因是把整个序列都拉通来分核,导致core与core之间share的KV缓存不够,因此我们这次参考LPT(longest processing time)的任务分配思想,首先将序列长度进行排序,从最长的序列开始按照RoundRobin的思想进行公平调度,这样可以尽可能保证多核在Cache中共享KV矩阵,如下图所示:
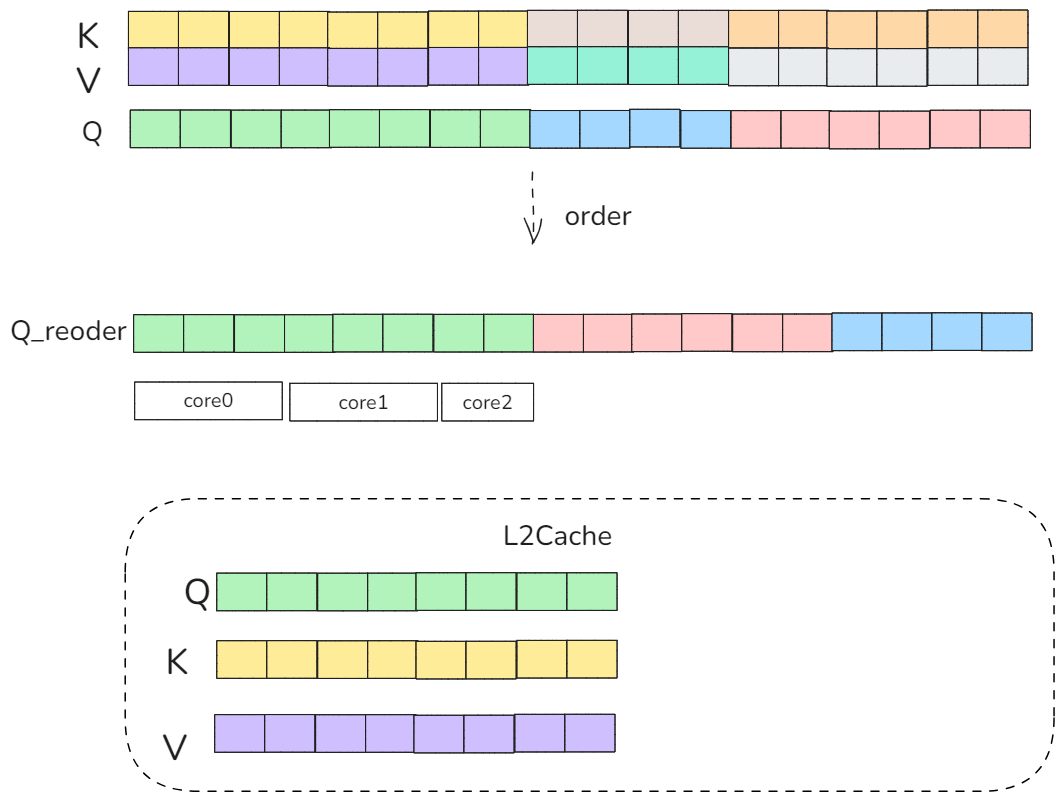
图13 RoundRobin调度
但是这样实现也会有一个问题,那就是我们必须保证序列的长度足够长,序列BLOCK数必须大于我们核数,不然必然有核出现空闲,导致物理核用不满出现资源浪费,如下图所示:
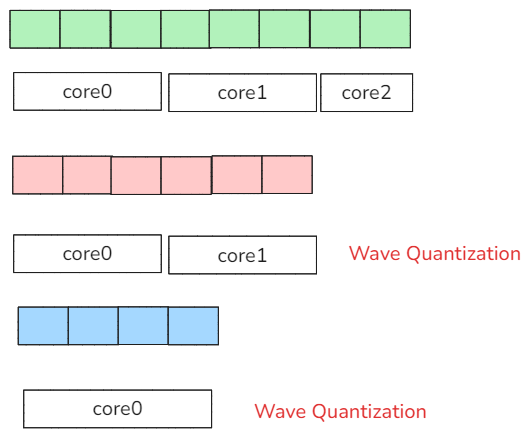
图14 Wave Quantization调度
第一个batch的序列可以完全分配给3个核,第二个batch的序列只能分配给2个核,最后一个batch的序列只能分配给一个核,导致core间分配不均匀。
3.3.4 Dynamic 序列并行调度
上述的问题引入本质是静态调度无法解决core间负载均衡的问题,因此解决该问题我们需要引入一个动态调度器(Dynamic Scheduler),该调度器会给每个core分配一个任务描述符队列(task descriptor queue),还会维护一个最小堆,该最小堆会记录每个core负载,每次分配新的BLOCK给负载最小的core,同时还考虑到aicore的scalar标量运算比较慢,因此我们会采用AICPU作为动态调度器的部署硬件,通过AICPU/AICORE协同的方式进行并行。
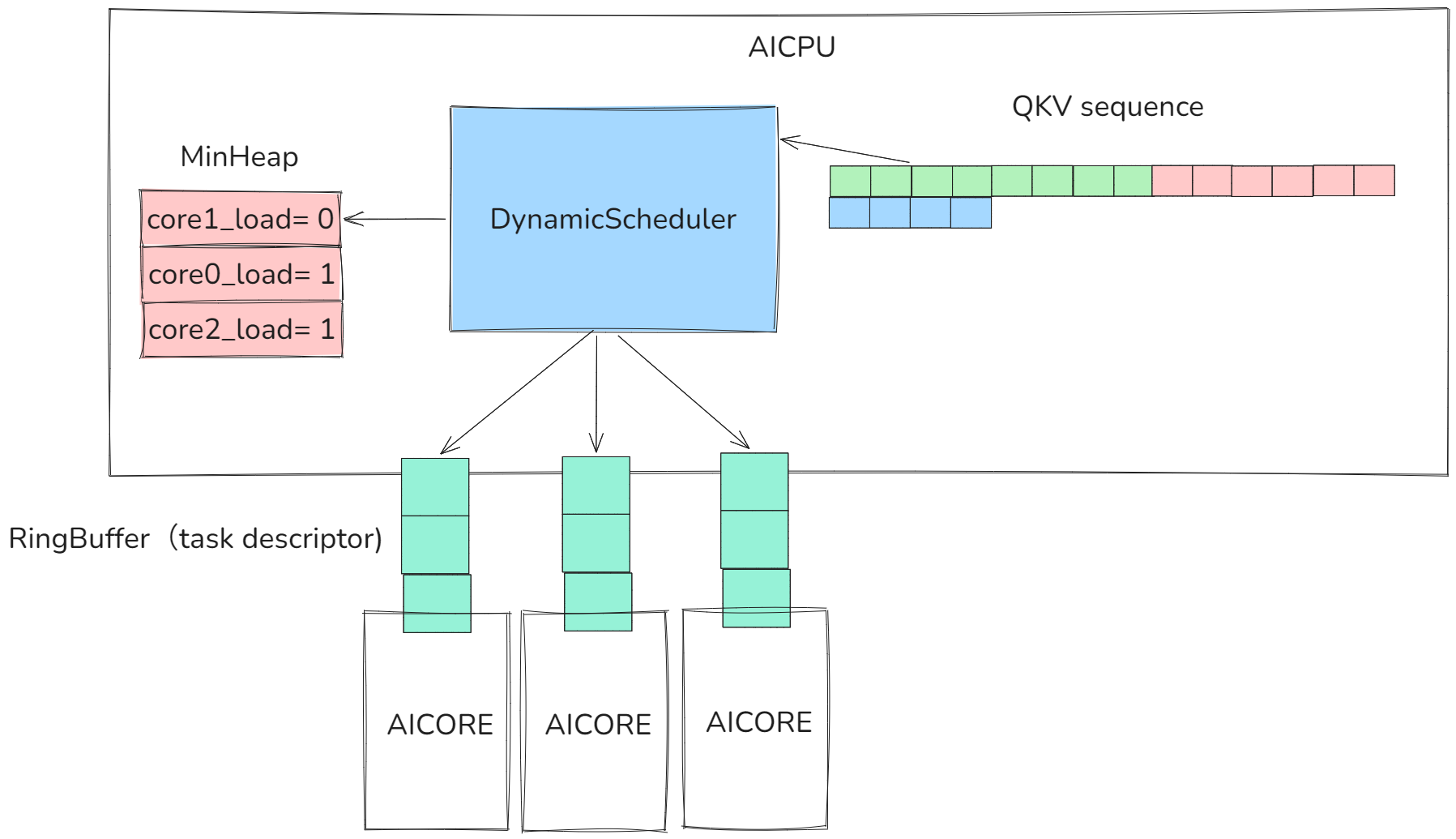
图15 Dynamic Scheduler
这样我们可以在NPU解决上述静态调度带来的,long Tail Effect,load balance,wave quantization等问题。
3.4硬件亲和的方式去实现
3.4.1 BLOCK块常驻和复用
对于foward来说,我们是固定Q BLOCK来遍历KV矩阵,因此工程落地的时候为了减少片外的访问我们会在core内对Q BLOCK在外循环进行L1常驻。
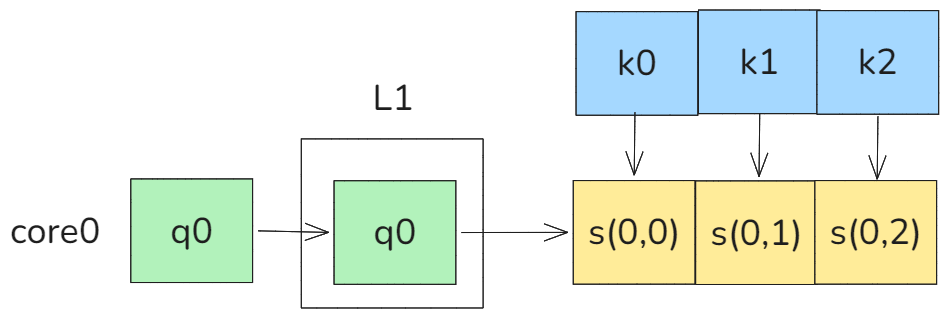
图15 L1固定Q 遍历KV
对于反向我们当前实现采用的是固定KV BLOCK来遍历Q矩阵,因此KV BLOCK块可以缓存在L1 BUFFER 中,同样我们可以看看一轮计算反向MATMUL的公式。
SCORE = Q_TILE * K_TILE – mm 1
DRAB = GRAD_TILE * V_TILE – mm 2
V_GRAD = SCORE * GRAD_TILE – mm 3
K_GRAD = DRAB * Q_TILE – mm 4
Q_GRAD = K_TILE * DRAB – mm 5
因此完整的一轮反向计算,一共有5个Matmul,因此如果按照Native的实现一共需要读取10次输入,可以观察发现如下L1复用的机会,mm1的Q_TILE和mm4的Q_TILE可以复用,mm1的K_TILE和mm5的K_TILE可以复用,mm2的GRAD_TILE和mm3的GRAD_TILE可以复用,mm4的DRAB和mm5的DRAB可以复用。
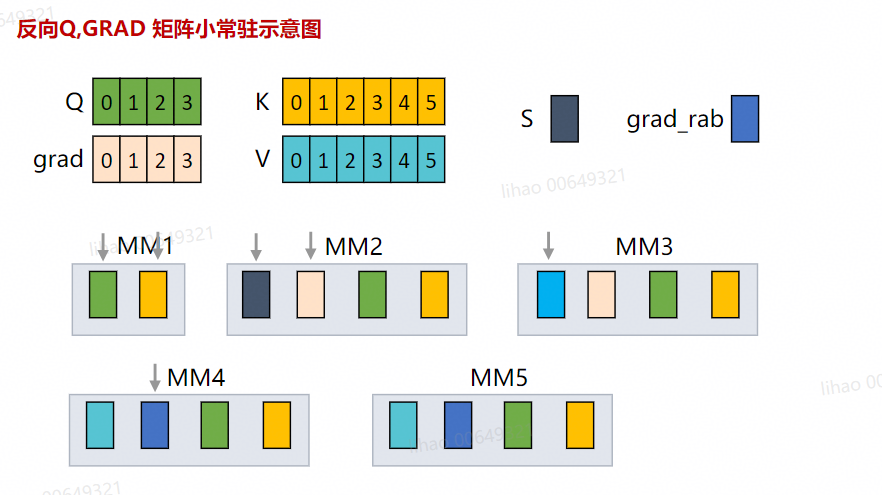
图17 L1多MM之间复用
因此对于反向来说一轮计算可以实现复用,减少0.6倍的片外访存。
3.4.2 BANK conflict 和swizzle优化
L2Cache/HBM/L1/UB是按照BANK进行组织的区别在与其BANK GROUP的大小和BANK的大小不一样,以及其影响的程度不一样。
以BANK组织的存储器大概是下面这个样子:
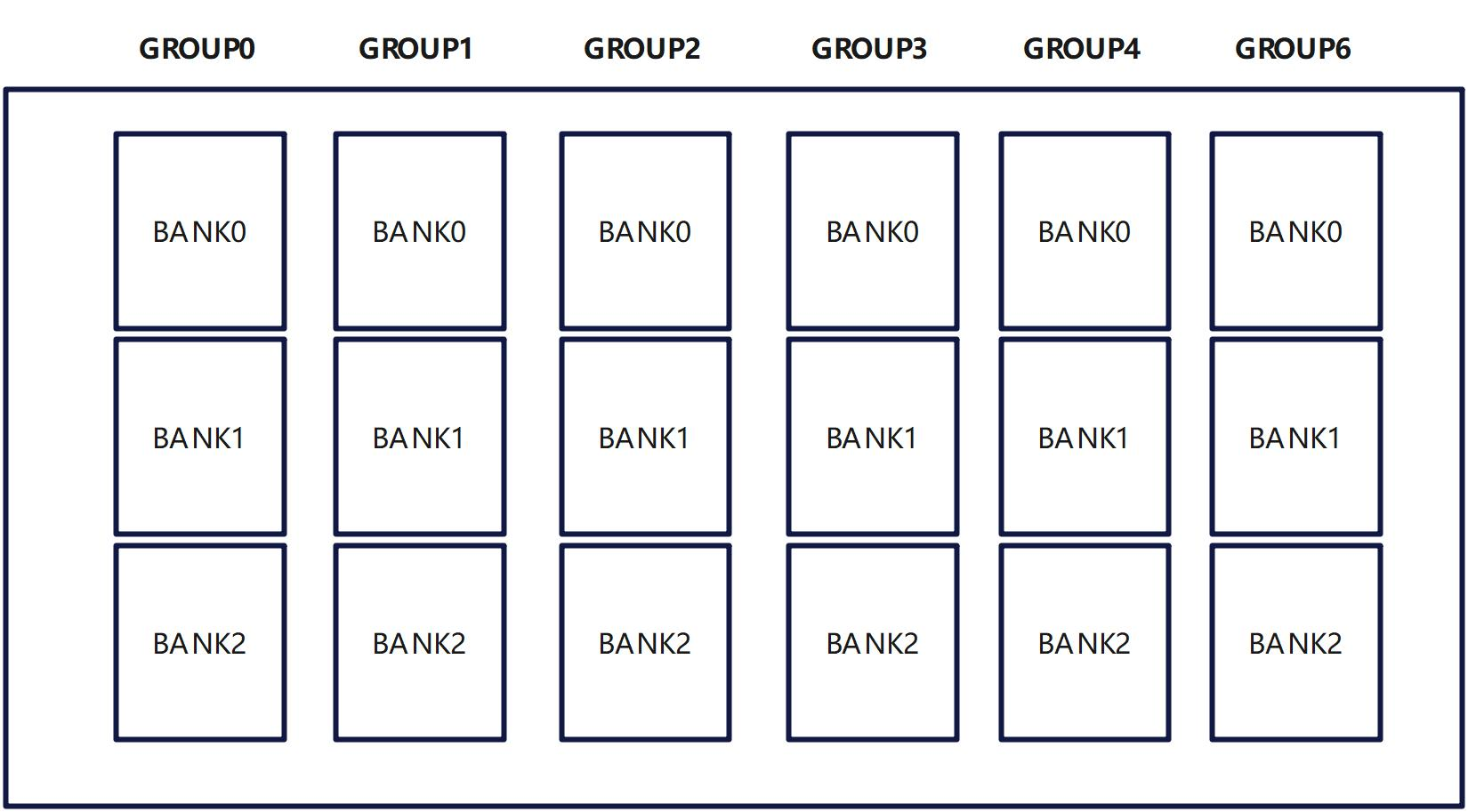
图18 BANK 存储器
其基本逻辑就是并行访问单元(同一个warp 不同thread, 不同aicore,不同的硬件单元等),
并行读写同一个GROUP的同一个BANK会串行化,并行读写同一个GROUP的不同BANK或者不同GROUP的BANK可以并行化。
比如以下的QKV访问场景就会触发HBM上的BANK冲突:
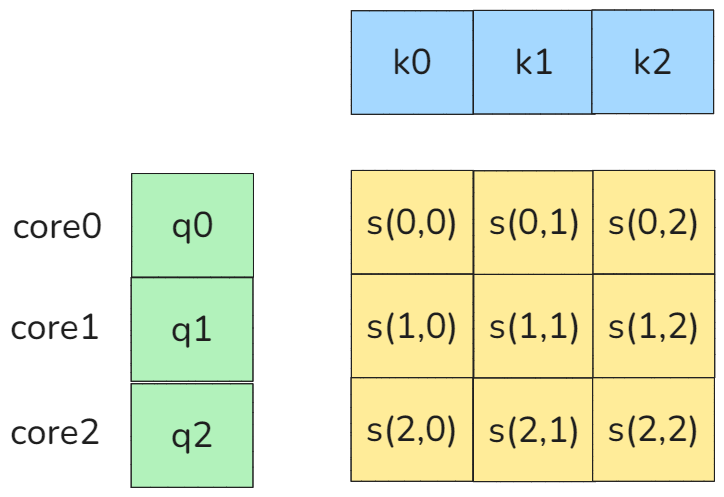
图19 order 访问
假设core0, core1, core2都按照RowMajor的形式去访问K0,K1,K2,则一开始的时候系统L2Cache并没有K0,K1,K2,则core0,core1,core2都会区HBM访问K0,K1,K2,这个时候因为多core都会访问同一个K的地址,因此会产生BANK conflict,如下图所示:
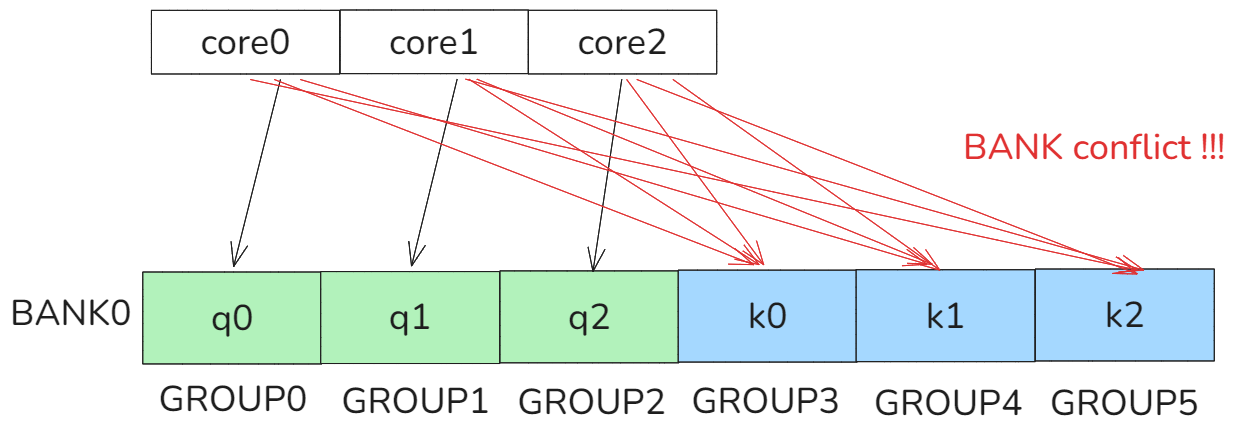
图20 bank conflict
因此我们core之间需要按照将访问顺序进行重新映射,避开bank conflict访问。
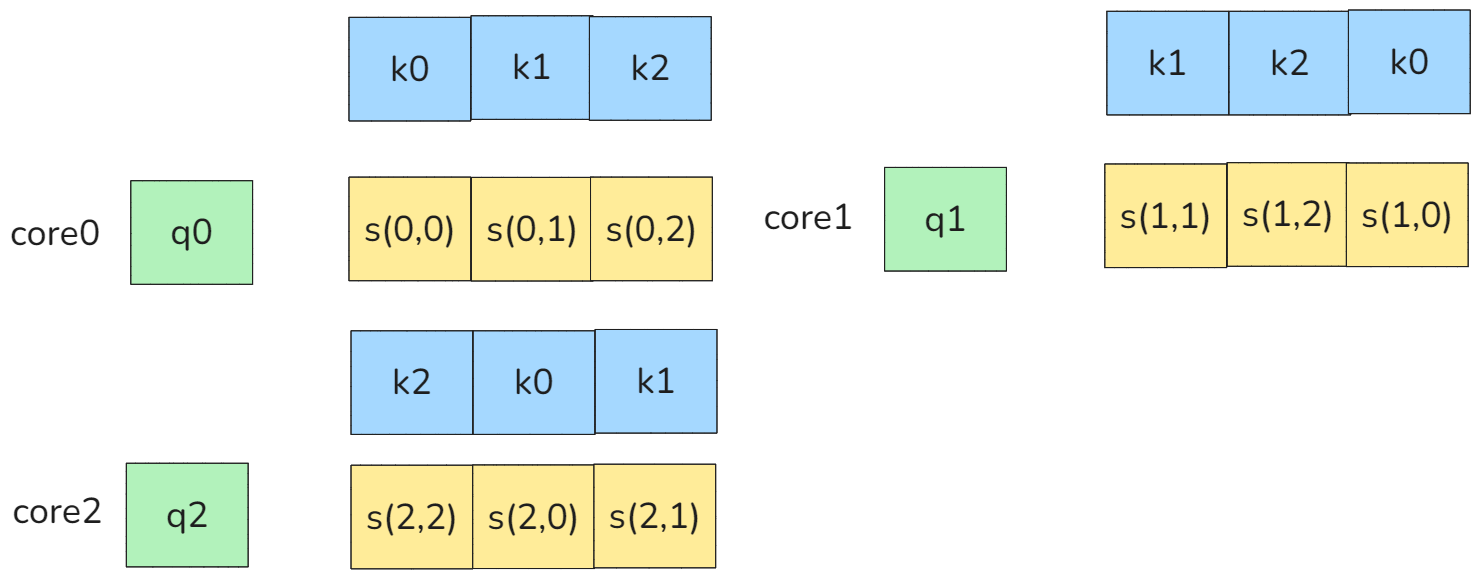
图21 reorder 访问
这样多个core访问不同的KV矩阵时可以尽可能避免bank conflict。
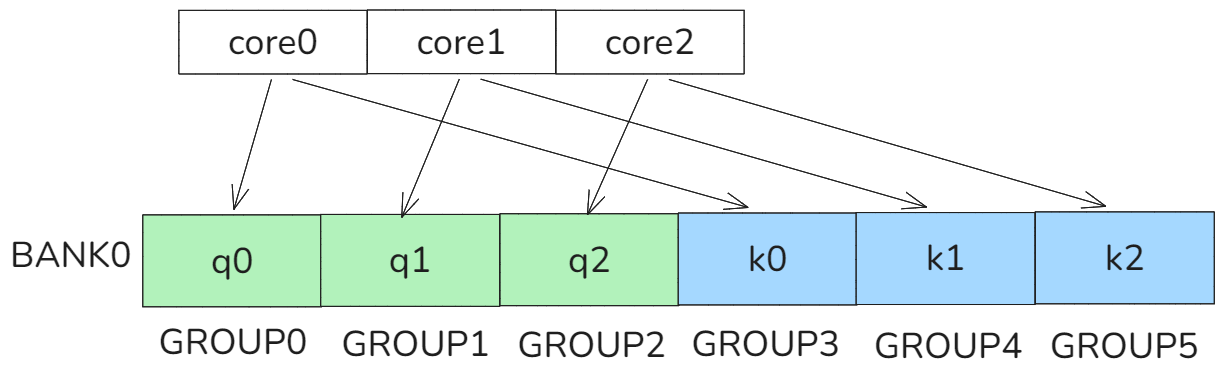
图22 no bank conflict
这种core与core之间为了bank conflict而做出的访存顺序调整就是(Bank Interleaving)。
然后再考虑一个场景,假设一个batch内被同一个core多次访问,那么这个core会重复访问同一个KV矩阵多次如下图所示:
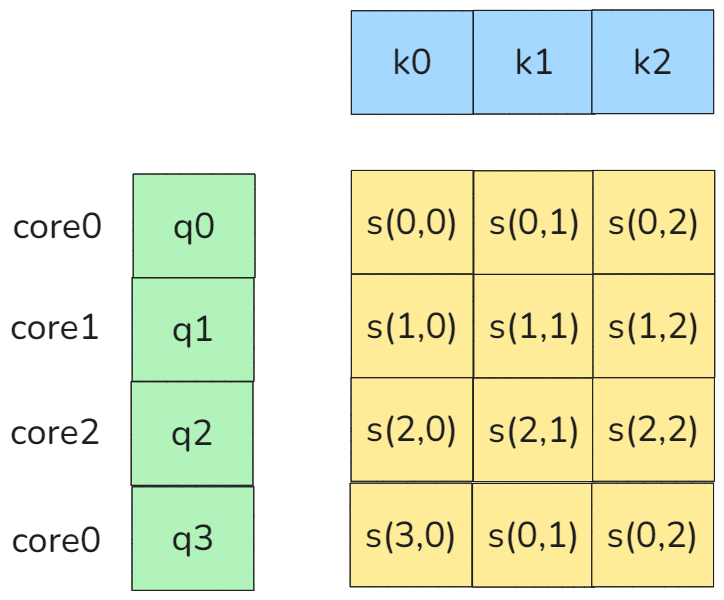
图23 core多次访问
如上图所示core0分别在同一个Q序列分配到了不同的BLOCK,那么对于这个core来说它会分别访问K0,K1,K2两次,第一次访问时在q0时,访问顺序时k0,k1,k2,第二次访问时在q3时,访问顺序依然是k0,k1,k2。
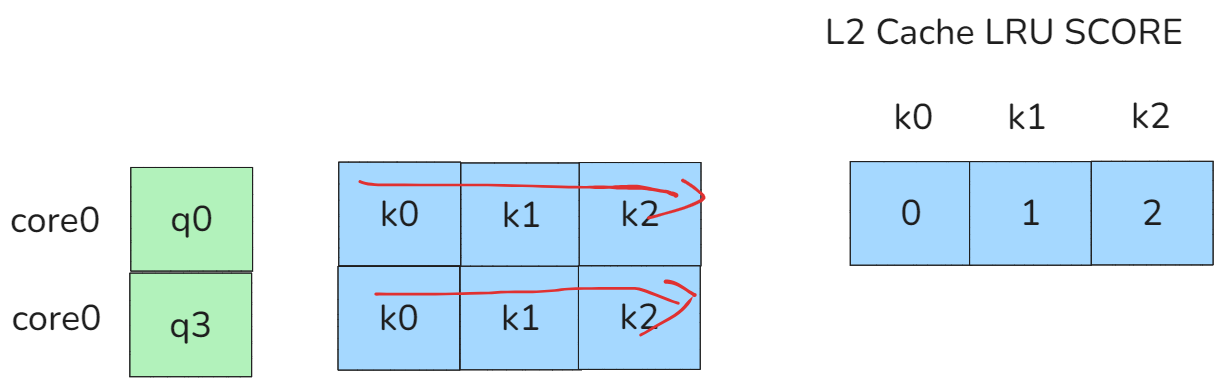
图24 no swizzle
给访问缓存进行建模,如果是按照LFU算法进行淘汰,则k0,k1,k2的分数分别为0,1,2。因此下一次再次按照k0,k1,k2进行顺序访问时其实是cache不友好的,尤其时cache比较紧张的场景,有可能其他核已经把LRU SCORE比较低的k0给淘汰了,导致下次访问k0出现了cache miss。
因此除了为了避免bank conflict而调整core与core之间的访问顺序以外,还需要调整core内部的多次访问同一个KV矩阵的顺序。因此我们可以简单的首先按照LRU SCORE的分数进行调整,如下图所示:
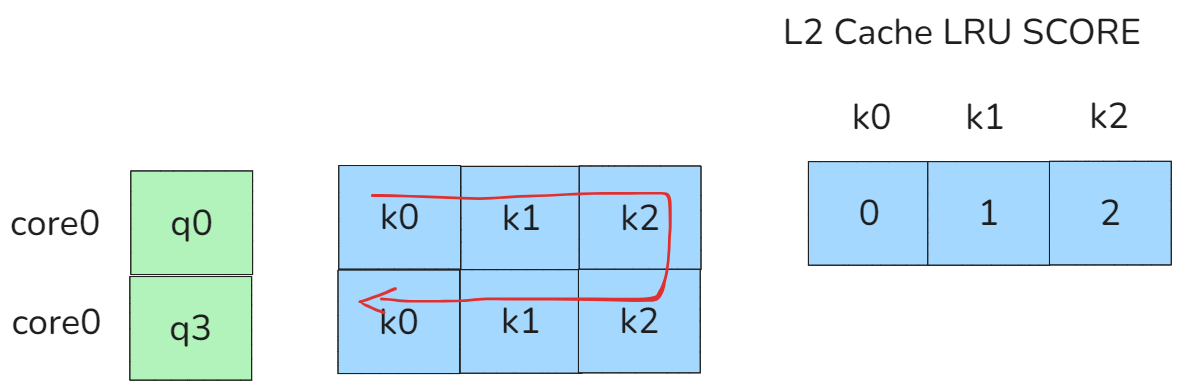
图25 swizzle
这种情况下我们首先按照K0,K1,K2进行访问,再按照K2,K1,K0进行访问,至少可以保证K2是可以再Cache中命中的。并且更加深度的优化,由于是K0,K1,K2,K2,K1,K0的访存顺序,因此可以直接考虑把K2缓存在L1里面,这样甚至都可以不用访问L2,这样对片外的访问就变成了K0,K1,K2,K1,K0,减少一次IO。
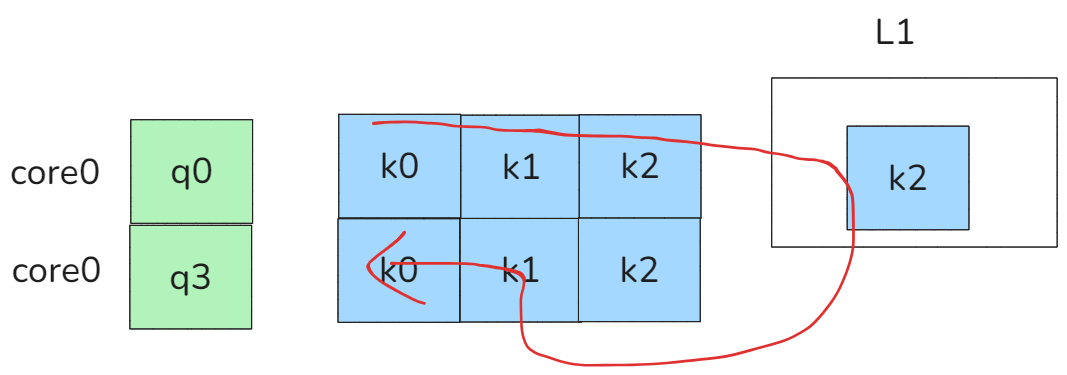
图26 swizzle + L1
这种对访问顺序的调整就是一种比较简单的swizzle。
3.4.3 使用L0C完成片内累加
对于前向完成QKV一次计算会产生一个累加块,对于反向完成一轮计算会产生K_GRAD,V_GRAD,Q_GRAD累加块,这里就只讨论对于前向的情况。
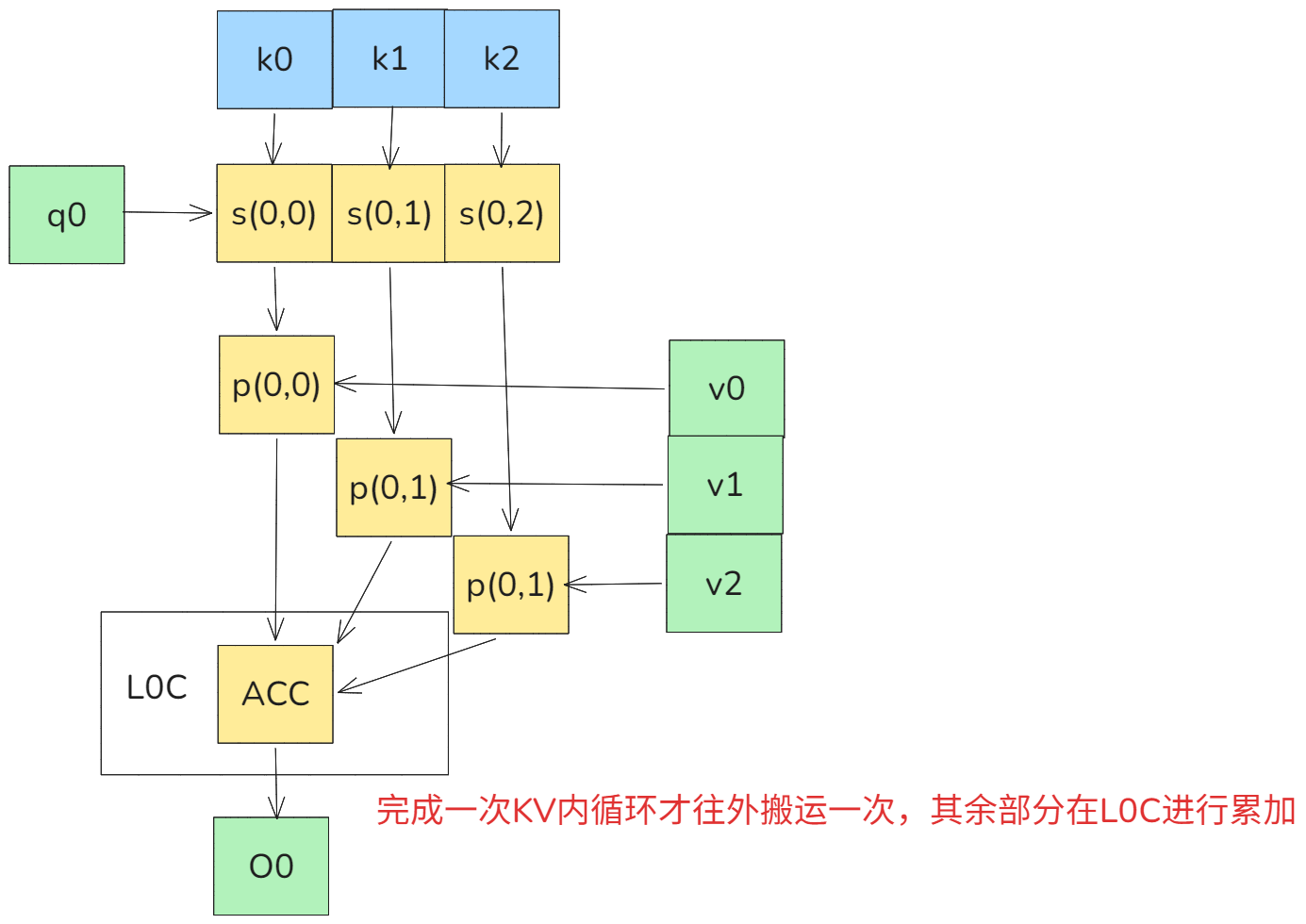
图27 L0C累加
3.4.4 使用NZ格式进行融合
不同于FA的softMax是Row-wise类型的计算,silu激活层是一种Point-wise计算,因此如果不考虑RAB和MASK的前提下,纯Attention计算部分可以不关心任何数据格式,在昇腾硬件上,矩阵的输入是NZ格式,矩阵的输出也是NZ格式,因此在进行QK->S->P->PV->O这种计算时,我们中间过程的S和P都按照NZ格式进行计算,对于QK来说L0C少一次NZ2ND转换,对于PV来说少一次ND2NZ的转换。提升CUBE计算效率。
原始方案,中间过程按照ND格式进行计算一次NZ2ND+ND2NZ。
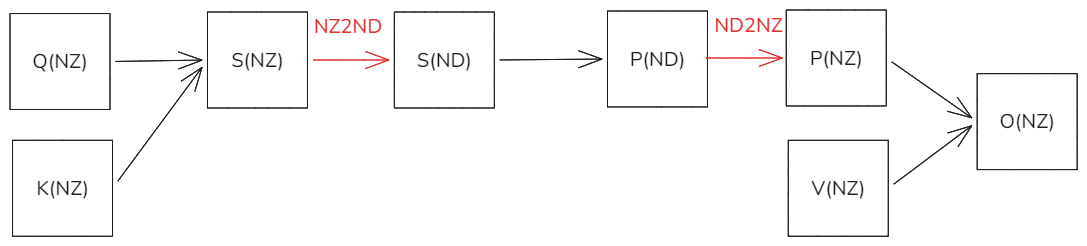
图28 ND格式融合
优化方案,中间过程直接按照NZ格式进行计算,CUBE更加高效。
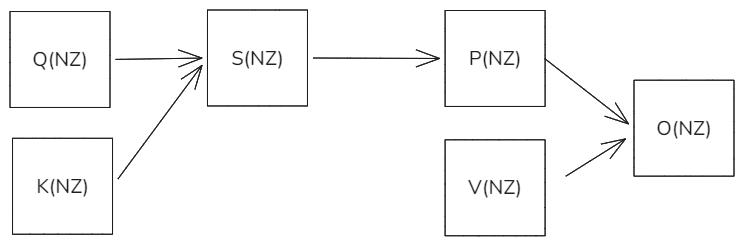
图29 NZ格式融合
3.5 流水并行掩盖计算时延
通过Atlas 800I A2的硬件参数可以发现其CUBE FP16 PeakFlops = 354TFlops,VECTOR FP16
PeakFlops = 22TFlops,假设一次计算的BLOCK块为M,N,K,则:
CUBE计算时间:
t_cube = (4 * M * N * K) / 354(这里要考虑QK和PV)
VEC 计算时间:
t_vector = (2 * M * N * 8) / 22(乘以2是因为要按照FP32进行计算,乘以8是因为需要按照 add + mul + silu进行cycles补偿,实际值需要测量或者的参考ISA硬件手册)。
衡量CV并行程度肯定是尽可能保证VECTOR时间小于CUBE时间,不阻塞CUBE执行,因此理论上我们是追求,CUBE完全掩盖VEC,即t_cube > t_vector。
因此可以得到t_cube >= (K / 64) * t_vector
因此,当K(head dim)小于64时是vector的时间比cube更长,此时是vector bound,当k 大于等于64之后 都是cube bound,即cube执行的时间更长。
假设当K = 32的时候,t_cube只有0.5X t_vector,因此在流水线的设计上cube双发。

图30 little dim
假设当K = 128的时候,t_cube有2X t_vector,此时完全处于cube bound。
图31 large dim
3.6 掩码跳过不必要的计算
在不实际参与运算的部分,可以直接跳过,省去运算量和搬运量,如下图所示:
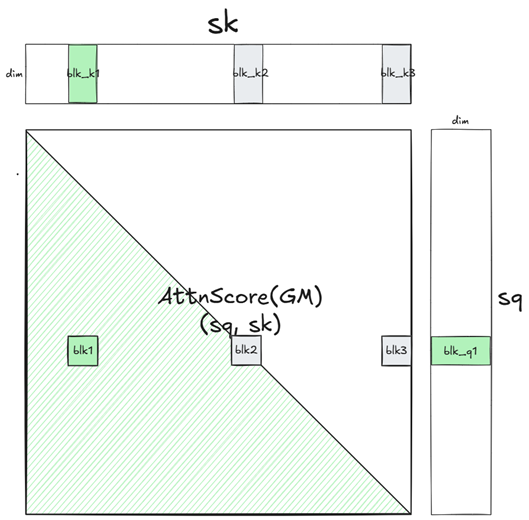
图 32 causal mask
4. 实操部署
参考:
总结和展望
NPU OPS相比NPU NATIVE的性能提升4~5X
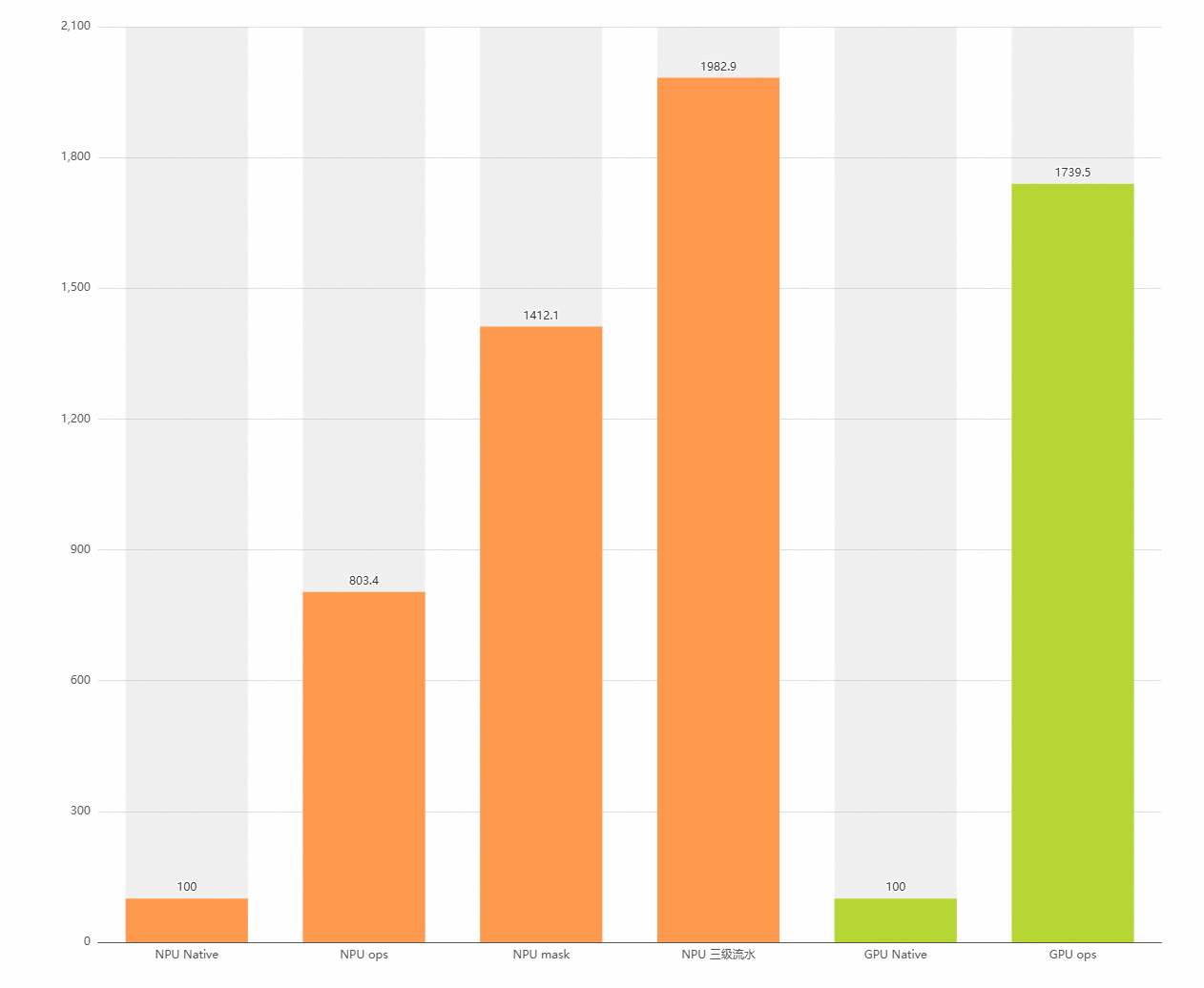
图33 NPU OPS VS NPU NATIVE VS GPU OPS VS GPU NATIVE
后续规划:
1、后续结合昇腾新硬件继续深挖性能
2、结合catlass 昇腾高性能计算模板库实现HSTU_V2

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)