
MindCluster故障诊断工具全新发布,实现集群智能化故障分析
MindCluster故障诊断工具全新发布,实现集群智能化故障分析
AI大模型时代的运维挑战
昇腾AI集群凭借强劲算力,已在大模型训练与推理场景中实现广泛应用。其中,MindCluster作为核心支撑平台,全面使能集群全流程运行,涵盖作业调度、运维监控、故障恢复等关键功能,为集群高效运转筑牢基础。
然而,随着集群规模持续扩大、设备类型日趋多样,加之日志数据分散等问题凸显,日常巡检的全面性与故障分析的精准性面临巨大挑战。据统计,AI训练任务中约30%的中断源于硬件或网络故障,单次故障平均造成4–6小时训练停滞,带来显著的算力损耗与时间成本。
为破解这一痛点,昇腾正式推出MindCluster Ascend FaultDiag Toolkit故障诊断工具,以智能化诊断能力革新运维模式。本文将基于该工具,为您提供全面指导,助力快速完成昇腾 AI集群的常态化巡检与突发故障分析,实现运维效率升级。
MindCluster故障诊断工具 Ascend FaultDiag Toolkit
MindCluster Ascend FaultDiag Toolkit是一款专为昇腾AI集群设计的交互式巡检与故障分析工具,支持在线采集与离线分析两种模式,助力完成集群异常的快速识别与分析。包括多源数据采集、智能日志解析、自动化巡检报告生成等核心功能。
MindCluster Ascend FaultDiag Toolkit核心功能包括:
- 多源数据采集框架,支持Host主机、BMC带外管理、交换机三类设备的信息采集,兼容SSH在线采集与离线日志导入两种方式。
- 自动化巡检分析,基于规则引擎对采集的数据进行巡检分析,自动识别异常现象,并给出处理建议。
- 交互式命令行界面,提供友好的CLI交互体验,支持向导式操作,降低使用门槛。
Ascend FaultDiag Toolkit巡检流程示意图如下:
MindCluster Ascend FaultDiag Toolkit能在、以下三个关键场景发挥工具化能力,一键闭环,攻克运维难题:
-
场景一:大模型训练中断应急排查
训练任务突发中断时,传统运维需逐节点登录、逐日志筛查,耗时数小时且易遗漏关键信息。使用 MindCluster Ascend FaultDiag Toolkit,仅需执行 auto_collect_diag 命令,即可快速聚合分散日志与设备数据,3 分钟内精准识别故障,大幅缩短故障恢复时间,保障训练任务连续性。 -
场景二:跨网络平面集群统一诊断
当跨多个网络平面部署集群时,传统工具难以突破组网限制实现全域管理。该工具支持在不同网络平面分别采集数据,通过跨平面汇总与统一诊断,彻底解决复杂组网下的数据割裂问题,实现集群全域运维可视化。 -
场景三:集群定期健康巡检
从 “事后救火” 转向 “事前预防”,本工具提供 auto_inspection 常态化巡检命令,可对集群硬件状态、网络链路、软件配置等进行全面健康体检,提前识别潜在风险点,将故障扼杀在萌芽阶段,降低运维成本。
集群巡检实操指南
案例背景
在大规模集群中,光模块故障可能会导致集群训练中断——光链路故障可能是部件、CDR、光模块、光纤等各部位问题,根因难定位,且集群节点分散,人工收集日志繁琐、分析低效,运维成本高。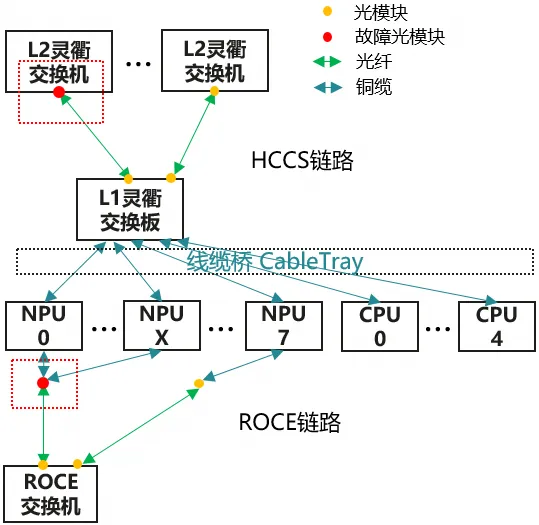
本案例将排查昇腾集群L1交换机与L2交换机间、NPU与RoCE交换机间光链路故障场景,演示如何快速上手使用MindCluster Ascend FaultDiag Toolkit工具,一站式解决故障排查痛点。
工具安装
# 安装工具包(Linux)
pip install ascend-faultdiag-toolkit
启动工具
# 启动交互式命令行
ascend-fd-tk
启动后回显如下: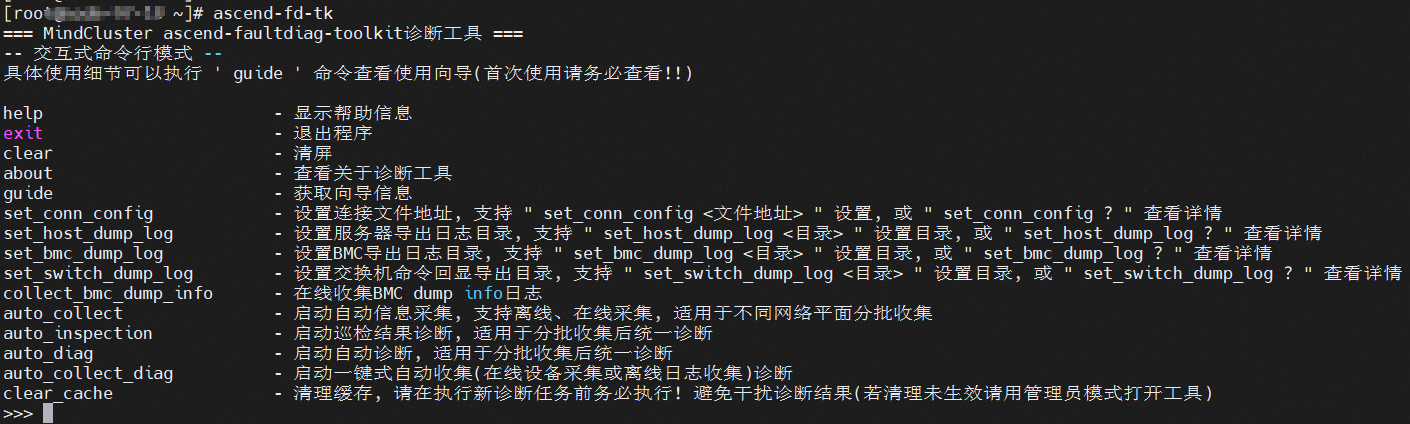
配置数据源
该工具提供在线信息采集和离线信息分析能力,实现自动化、多场景的诊断能力。支持Windows和Linux环境。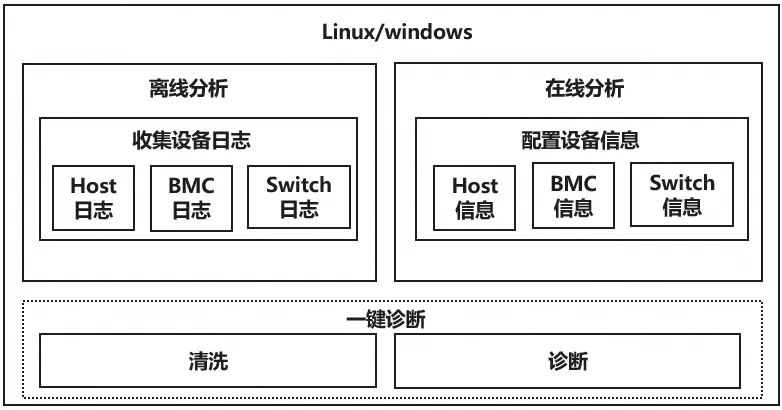
- 在线采集模式(需配置SSH连接)
用户输入待访问设备的连接信息(账号、密码/密钥/免密),工具访问设备采集信息。
# 设置连接配置文件
>>> set_conn_config /path/to/conn.ini
conn.ini配置文件内容结构样例:
# 设置连接配置文件
>>> set_conn_config /path/to/conn.ini
conn.ini配置文件内容结构样例:
[host]
# port指定端口,不写默认为22, username指定用户名, password指定密码, private_key指定私钥文件
xxx.xxx.1.10 port="22" username="user_name" private_key="~/.ssh/your_private_key"
xxx.xxx.1.11 port="22" username="user_name" password="your_password"
[bmc]
xxx.xxx.1.12 username="user_name" password="your_password"
[switch]
# 支持ip段方式填写(需保证账号密码相同)
xxx.xxx.1.20-xxx.xxx.1.30 step=2 username="user_name" password="your_password"
[config]
# 支持设置全局的私钥文件
private_key="~/.ssh/your_private_key"
- 离线分析模式(需设置日志目录)
用户将已采集的日志放入指定目录,来分析关键信息。
# 设置Host服务器日志目录
>>> set_host_dump_log /path/to/host_logs
# 设置BMC日志目录
>>> set_bmc_dump_log /path/to/bmc_logs
# 设置交换机日志目录
>>> set_switch_dump_log /path/to/switch_logs
执行巡检
一键式巡检(推荐):
# 自动完成采集+巡检
>>> auto_collect_diag
分步巡检 (适用于分批采集场景):
# 第一步:采集信息(可多次执行,汇总多次采集结果)
>>> auto_collect
收集完成, 若完成全部收集请使用 " auto_diag " 进行巡检
# 第二步:执行巡检
>>> auto_diag
巡检完成
客户定制化巡检 :
# 执行特定客户类型的巡检
>>> auto_inspection <客户类型>
查看巡检报告
巡检完成后,报告自动生成至~/.ascend-faultdiag-toolkit/report/目录:
# 查看报告目录
ls ~/.ascend-faultdiag-toolkit/report/
# 输出示例
diag_report_20260303_201835.csv # 巡检分析报告
inspection_errors.csv # 客户定制化巡检报告
巡检报告内容示例:
- 诊断报告

- 主机NPU<->交换机端口光模块信息

- 交换机间端口连接光模块信息
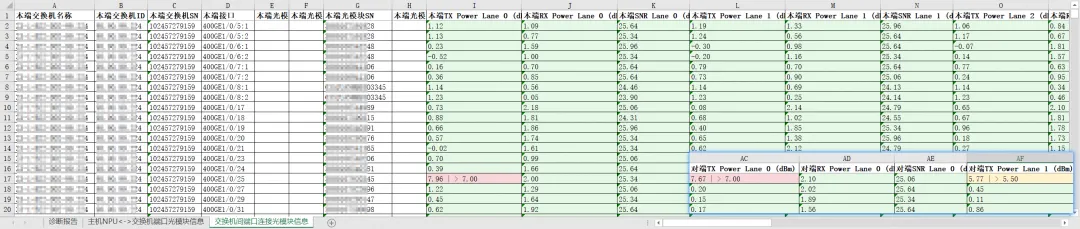
结合本案例覆盖的L1-L2交换机间、NPU-RoCE交换机间光链路故障场景,用户仅需配置采集设备信息,故障诊断工具即可实现大规模集群日志的批量自动收集——相较于人工手动采集,大幅缩短采集耗时;同时工具会自动解析“本端 XPU<->XPU Chip<->XPU marco<-> 光模块 <-> 对端设备…”的完整端口映射关系,无需定位人员手动梳理,显著降低分析工作量,提升故障定位效率。
清理缓存
完成巡检任务后,建议清理缓存,避免影响下次巡检:
>>> clear_cache
清理完成
总结
本文介绍了昇腾AI基础软硬件平台中的MindCluster Ascend FaultDiag Toolkit故障诊断工具的巡检与故障分析方法,该工具致力于打造昇腾AI集群的高效、易用巡检解决方案,提供端到端的巡检支持,助力企业实现AI集群的稳定运行。
MindCluster Ascend FaultDiag Toolkit已完成开源,欢迎访问主页,参与到社区开发和成长。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)