
Qwen3-Omni多模态推理性能优化实践:基于昇腾的P99时延与QPS双提升
本文基于Atlas 800I A2部署Qwen3-Omni全模态大模型,针对多模态AI分析系统的性能瓶颈展开优化。Qwen3-Omni支持文本、图像、音频、视频的统一处理,在多项基准测试中表现优异。通过分析发现MoE路由和CUMSUM算子存在性能瓶颈,采用Ascend原生算子替换和数据类型转换优化方案,显著提升推理效率。关键优化包括:替换MoE路由算子为Ascend原生实现,将CUMSUM算子的I
作者:昇腾实战派
一、背景介绍
在构建高并发、低延迟的多模态AI分析系统时,L1阶段的初筛环节对推理性能提出严苛要求。系统需在1分钟内完成音频与视频输入的联合理解,输出初步判定结果。
本文基于Atlas 800I A2部署Qwen3-Omni原生全模态大模型,围绕关键算子瓶颈展开深度优化,实现性能突破。
版本环境
- vLLM-Ascend: v0.13.0
- CANN: 8.3.RC1
- 模型:Qwen3-Omni
二、Qwen3-Omni模型架构与核心能力
Qwen3-Omni于2025年9月发布,是新一代原生全模态大模型,支持文本、图像、音频、视频的统一处理,并可实现端到端的流式响应。其核心能力包括:
- 原生全模态:在多模态数据上联合预训练,避免模态降智。
- 卓越性能:在36项音频与音视频基准测试中斩获32项开源SOTA,22项总体SOTA,超越Gemini-2.5-Pro、GPT-4o-Transcribe等闭源模型。
- 多语言支持:支持119种文本语言、19种语音理解语言与10种语音生成语言。
- 低延迟响应:纯模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms。
- 长序列支持:可处理长达30分钟的音频输入。
- 个性化与工具调用:支持system prompt定制、function call集成,增强系统可扩展性。
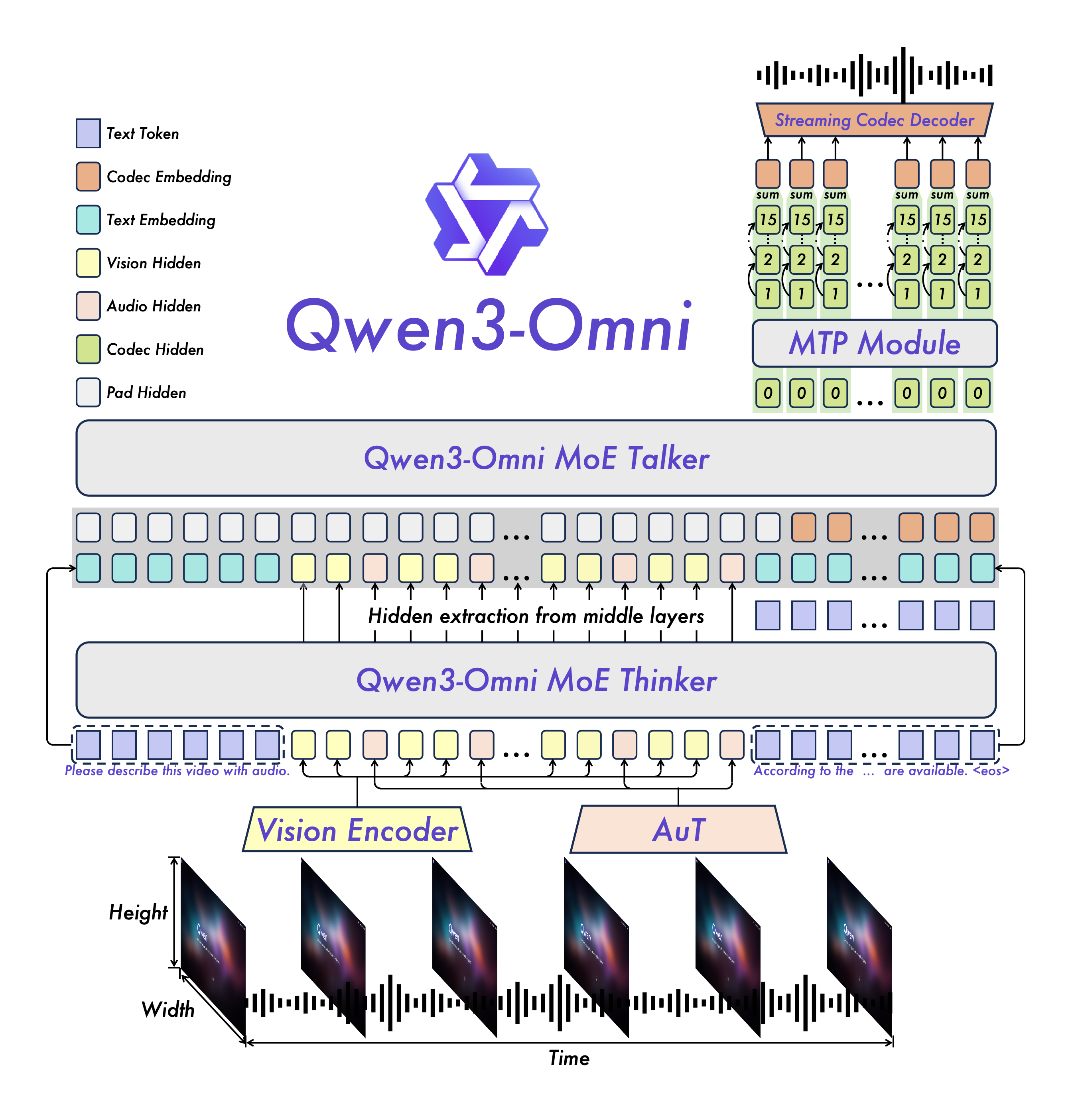
2.1 Audio Transformer(AuT)
Audio Transformer(AuT)是一种注意力编码器‑解码器架构(如图 2 所示),在2000 万小时的有监督音频数据上从零训练。训练过程中,音频的滤波器组特征在进入注意力层之前,通过Conv2D 模块进行 8 倍下采样,将token rate降至 12.5Hz。为学习更强大、更通用的音频表征,AuT 在大规模音频数据集上同时基于语音识别与音频理解任务进行联合训练。具体而言,训练数据包含:80% 中、英文伪标注 ASR 数据,10% 其他语言 ASR 数据,以及 10% 音频理解数据。在 Qwen3‑Omni 中,AuT 编码器用作音频编码器,其参数量约为 **0.6B(6 亿)**。
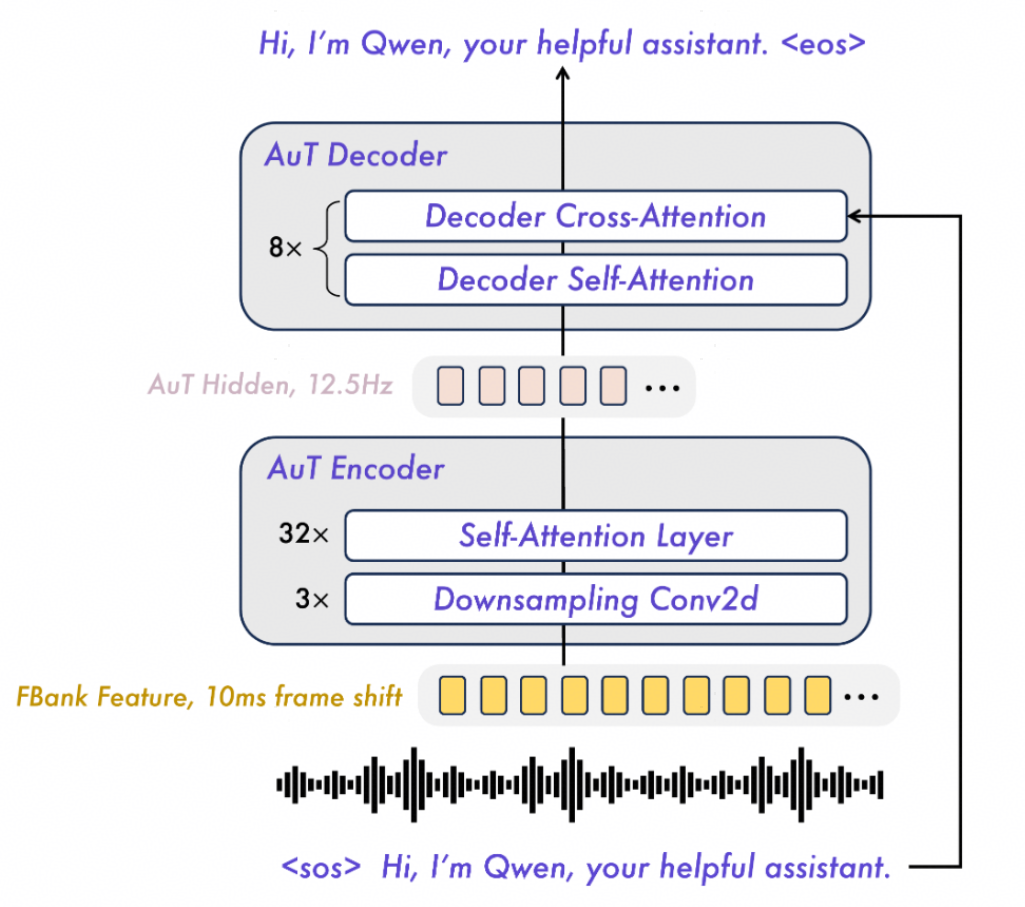
图2 Qwen3-Omni AuT结构
2.2 Thinker模块:多模态表征统一
Thinker 模块将文本、音频、图像及视频(不含音频)转换为一系列表征用于输入。
- 对于文本输入,采用 Qwen 的tokenizer(基于BBPE编码,词表量为151643),该分词器采用字节级字节对编码(byte-level byte-pair encoding, BBPE),包含 151,643 个token。
- 对于音频输入及从视频中提取的音频,将其重采样至 16 kHz,再将原始波形转换为 128 通道的梅尔频谱(mel-spectrogram),采用 25 ms 的窗口长度(window)和 10 ms 的步长(hop)。使用 AuT 编码器作为音频编码器,该编码器在 2000 万小时音频数据上从零开始训练,且每帧音频表征对应原始音频信号约 80 ms 的片段。
- 对于图片和视频(不含音频)输入,采用 Qwen3-VL 的视觉编码器(Vision Encode),该编码器基于 SigLIP2-So400m 初始化,参数量约为 5.43 亿,能够同时处理图像和视频输入。该视觉编码器在图像与视频混合数据集上训练,确保具备强大的图像理解和视频理解能力。
此外,为在与音频采样率对齐的同时,尽可能完整地保留视频信息,采用动态帧率对视频帧进行采样。
三、关键性能瓶颈分析与优化实践
在部署vLLM推理服务过程中,Profiling分析发现部分算子存在性能瓶颈。我们聚焦于MoE与CUMSUM算子,实施针对性优化。
3.1 算子融合优化
3.1.1 MoE路由算子替换
为提升MoE(Mixture of Experts)模块的执行效率,将原生PyTorch算子替换为Ascend原生优化算子:
- 替换
torch_npu.npu_moe_gating_top_k为torch.ops._C_ascend.moe_gating_top_k - 替换
torch_npu.npu_moe_init_routing_v2为torch.ops._C_ascend.npu_moe_init_routing_custom
上述替换基于vLLM-Ascend社区PR优化,显著提升MoE路由阶段的算子执行效率。
参考PR:
3.1.2 CUMSUM算子性能优化
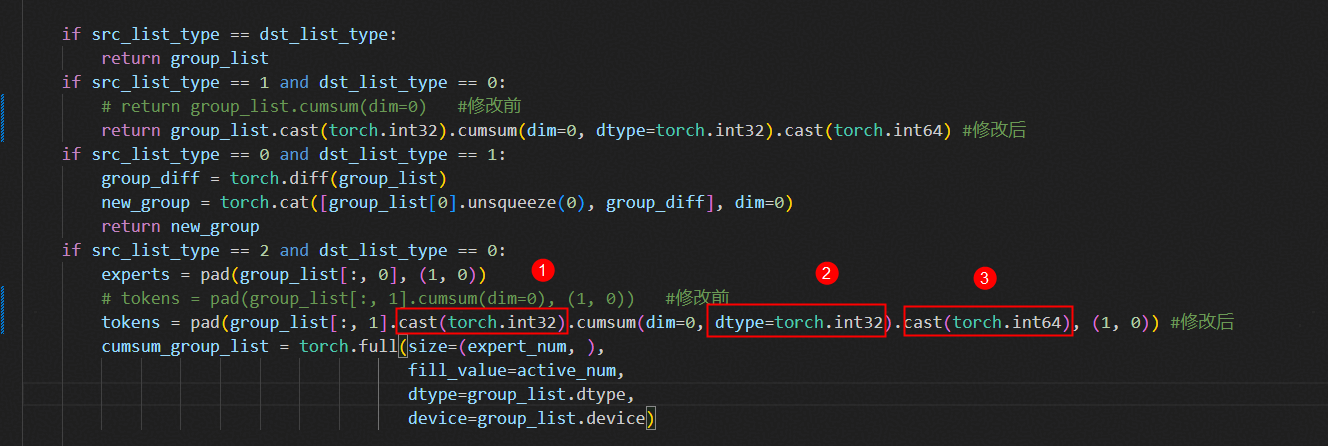
问题定位
Profiling显示CUMSUM算子耗时异常,且为AI_CPU算子。进一步分析发现,其输入数据类型为INT64,而Ascend芯片指令不支持INT64,导致算子在CPU侧执行,成为性能瓶颈。
调用栈分析
该算子位于 vllm-ascend/vllm_ascend/ops/fused_moe/moe_mlp.py,为MoE模块中路由计算的一部分。
优化方案
- 数据类型转换:在CUMSUM算子输入前,显式将INT64转换为INT32。
- 显式指定Dtype参数:CUMSUM算子默认Dtype为INT64,若不传参,即使输入为INT32,系统仍会自动提升为INT64。因此必须显式传入
dtype=torch.int32,确保算子在AI-Core上执行。
关键点:仅加
cast(torch.int32)不足以解决问题,必须同时修改算子调用参数,否则仍会因类型提升导致CPU执行。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)