
都是生成式推荐,为什么昇腾这么快?
自Meta提出生成式推荐(GR)以来,生成式推荐成为推荐系统领域最热门的话题。GR模型核心结构HSTU亟待从耗时、显存两方面同步优化。MindSDK基于昇腾NPU融合算子,通过内置Mask、优化Tensor数据结构、NPU硬件级指令并行等手段实现显存优化$o(n^2) \rightarrow o(n)$、推理时延优化95%。相关代码仓:[https://gitcode.com/Ascend/Rec
作者:昇腾实战派
0.摘要
自Meta提出生成式推荐(GR)以来,生成式推荐成为推荐系统领域最热门的话题。GR模型核心结构HSTU亟待从耗时、显存两方面同步优化。
MindSDK基于昇腾NPU融合算子,通过内置Mask、优化Tensor数据结构、NPU硬件级指令并行等手段实现显存优化 o ( n 2 ) → o ( n ) o(n^2) \rightarrow o(n) o(n2)→o(n)、推理时延优化95%。
相关代码仓:https://gitcode.com/Ascend/RecSDK
1.引言
某日,老板曰:“Transformer甚美。”
我深以为然:“数学表达更甚。”
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt d_k}) V Attention(Q,K,V)=softmax(dkQKT)V
老板复曰:“吾听闻生成式推荐妙极,其核心结构神似Attention,名曰HSTU。”
H S T U ( Q , K , V ) = m a s k n ⋅ s i l u ( Q K T α − 1 ) V HSTU(Q,K,V)=\frac{mask}{n} \cdot silu(\frac{QK^T}{\alpha^{-1}})V HSTU(Q,K,V)=nmask⋅silu(α−1QKT)V
我:“PyTorch实现也很简洁。”
def HSTU(Q, K, V, mask, alpha=1, n=1): # (b, n, s, d) x (b, n, d, s) -> (b, n, s, s) x = torch.matmul(Q, K.permute(0, 1, 3, 2)) x *= alpha x = F.silu(x) x *= mask / n # (b, n, s, s) x (b, n, s, d) -> (b, n, s, d) x = torch.matmul(x, V) return x老板甚悦,曰:“优化之,性能翻几倍,显存用一半,何如?”
我:?
以上故事虽然是假的,但是要求是真的。自Meta推出生成式推荐(generative recommendations, GR)以来,国内各头部互联网厂商也果断跟进,可以说生成式推荐就是推荐系统领域最火的话题。而HSTU之于GR,正如self-attention之于transformer。随着GR的火爆HSTU也自然而然的成为了优化热点。各大实验室要解决的核心痛点就两条:
- 极致的性能:在千万级 QPS(每秒查询数)的推荐场景下,高延迟完全无法接受。
- 爆炸的显存:随着输入行为序列长度的增加,显存消耗呈指数级上升。
事情我听明白了,唯一有个小小疑惑,就是这么几行代码,NPU还能怎么优化??
2.融合算子:NPU架构的馈赠
2.1.为什么要融合?
昇腾NPU的架构设计中,计算核分为两类:
- Cube核:负责矩阵运算(MatMul),劲儿大、好使
- Vector核:负责向量运算(SiLU、Mul、Add等element-wise操作)
传统PyTorch实现中,每一次matmul、silu都是一次独立的核调度。这意味着:
- 中间结果需要写回GM(全局内存):QK的结果必须落显存,下一轮才能继续。
- 显存带宽成为瓶颈:中间结果在GM中来回搬运,带宽压力巨大。
融合算子的核心思想,正是利用NPU的UB(Unified Buffer)做中间数据暂存,让多个计算步骤在UB内闭环完成,最终结果才写回GM。不再需要额外创建显存,显存瞬间从 o ( s 2 ) o(s^2) o(s2)降到 o ( s ) o(s) o(s)。那么这是怎么实现的呢?
2.2.UB的分块计算魔法
NPU融合算子并不使用整个QKV数据做运算,而是分块运算。好比做100道口算题是逐个的算,不会一并出答案。放到脑子里算的部分是UB,记在草稿纸、卷子上的题目则是GM。
融合算子中,每次切的QKV大小为 ( H b l o c k , d i m ) (H_{block}, dim) (Hblock,dim)。QK矩阵乘的结果保存在 ( H , H ) (H, H) (H,H)大小的显存上,完成后续运算后输出大小为 ( H , d i m ) (H, dim) (H,dim),累加输出到结果地址上。整个过程只需要占用临时的显存 ( H , H ) (H, H) (H,H),不需要保存整个 Q K T QK^T QKT结果。
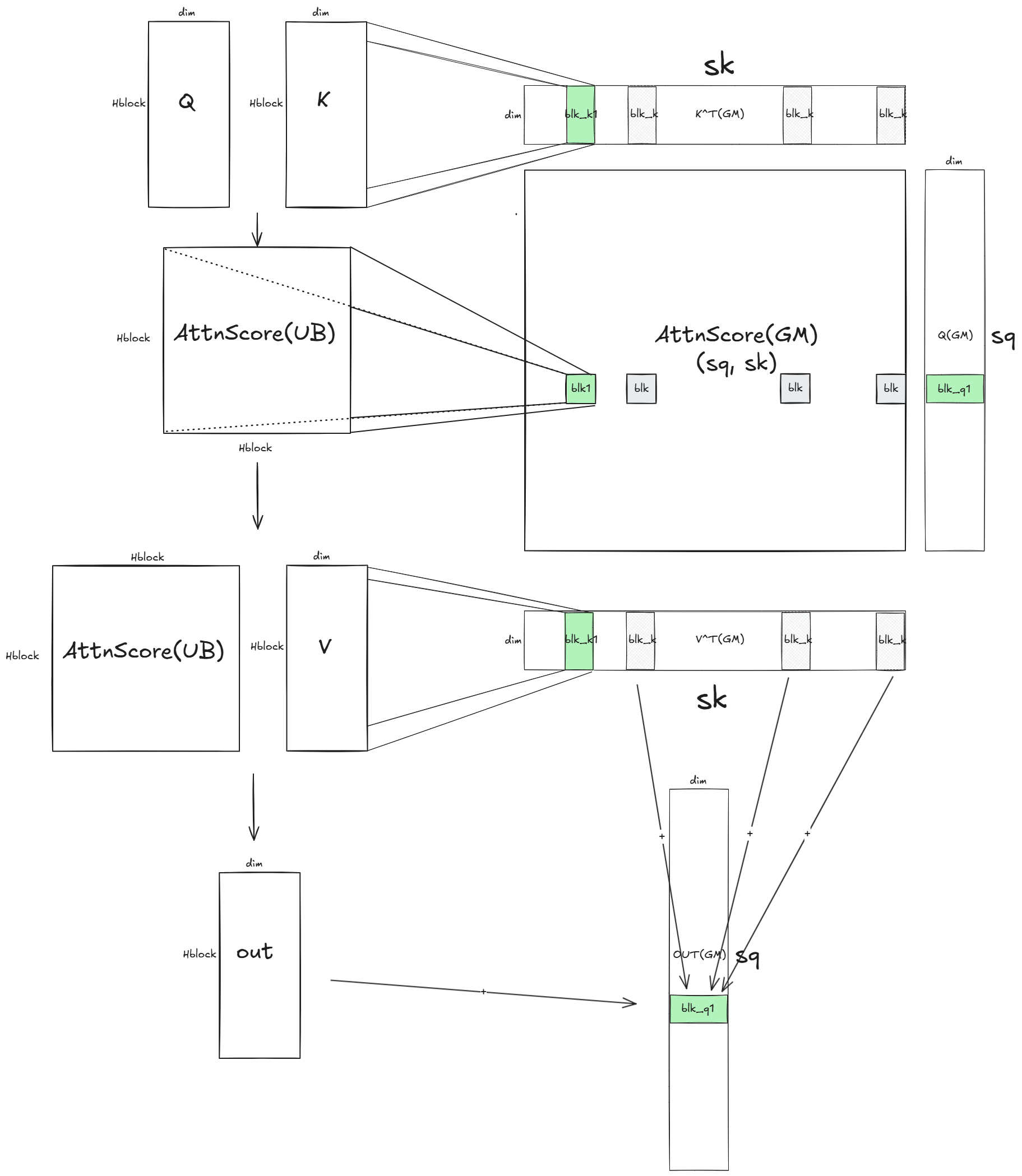
这样的分块运算策略不仅节省显存,而且性能极佳:
- UB空间有限但极快:UB是on-chip的SRAM,读写延迟远低于GM
- 中间结果不占显存: ( H b l o c k , H b l o c k ) (H_{block}, H_{block}) (Hblock,Hblock)的注意力矩阵完全在UB中完成,后续直接与V做矩阵运算
由于显著减少了GM↔UB的数据搬运次数,从而实现性能提升。以QKV(16, 4, 4096, 64)为例,torch NPU上小算子耗时均值为46.6ms,而融合算子仅5.8ms,立即提速87.5%。显存从4.125G直降到2.125G,怒省49%。
3.Mask内置:因地制宜的显存优化
3.1.问题的来源
HSTU、主流大模型都是decoder-only的结构,业界通常使用attention mask,即代码里的x *= mask / n。这个mask(b, n, s, s)长这样:
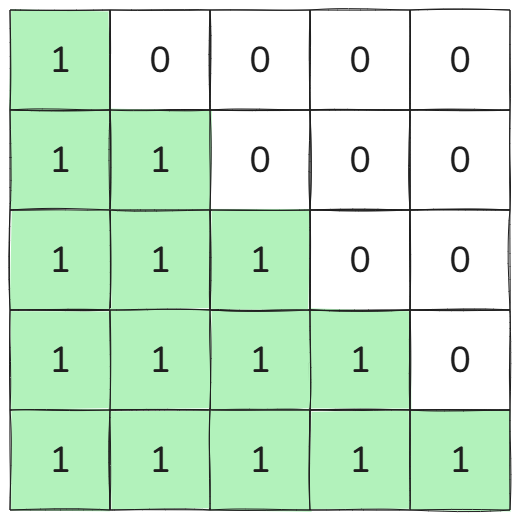
mask非常的规律,外部传入却要使用 o ( s 2 ) o(s^2) o(s2)的显存,非常浪费。因此完全可以在融合算子里生成,而节省的显存非常可观:
m e m = b × n × s × s × s i z e o f ( f p 16 ) = 16 × 4 × 4096 × 4096 × 2 = 2 G \begin{aligned} mem &= b\times n \times s \times s \times sizeof(fp16) \\ &= 16\times 4 \times 4096 \times 4096 \times 2 \\ &= 2G \end{aligned} mem=b×n×s×s×sizeof(fp16)=16×4×4096×4096×2=2G
在实际使用中,0 < s <= 20480,节省的显存更加明显。
3.2.融合算子内部创建Mask
根据QKV切片位置 ( b l k Q , b l k K ) (blk_Q, blk_K) (blkQ,blkK),创建mask可以分3种情况创建:
- b l k Q > b l k K blk_Q > blk_K blkQ>blkK。全为1 Mask
- b l k Q = b l k K blk_Q = blk_K blkQ=blkK。Tril Mask
- b l k Q < b l k K blk_Q < blk_K blkQ<blkK。全为0 Mask
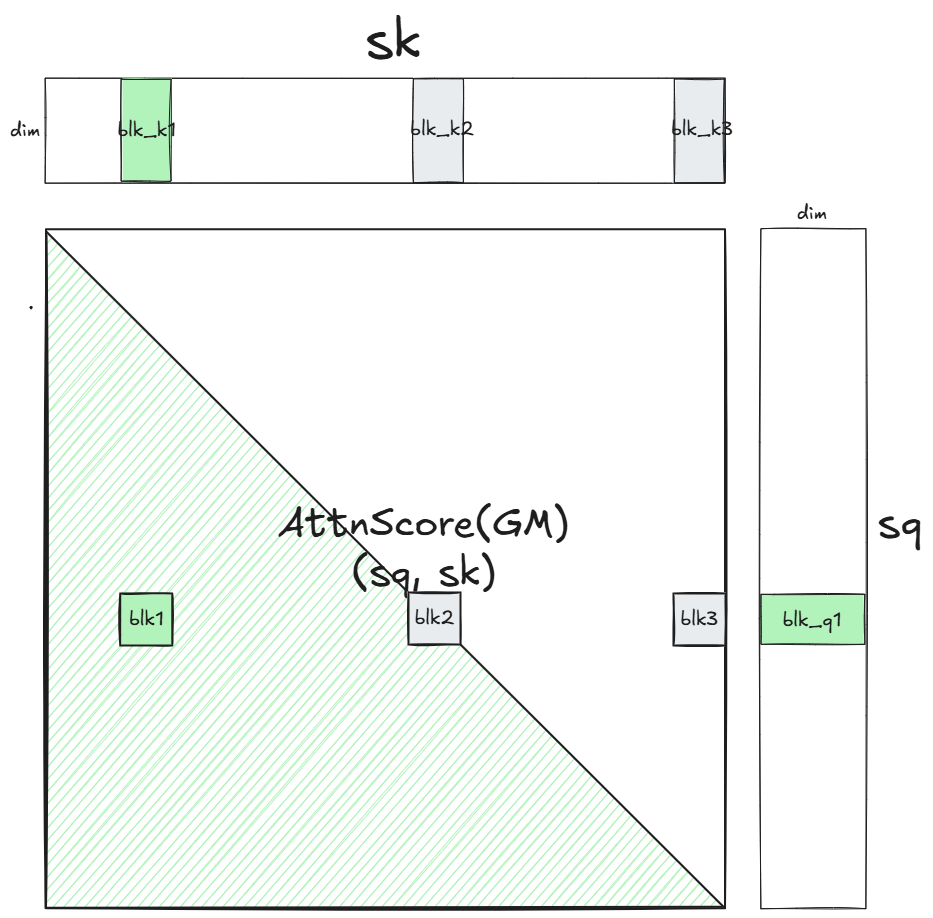
全为1的mask和不做mask运算是等价的;而blk_Q < blk_K的块mask全为0可以直接跳过!白赚一半计算量。
以QKV(16, 4, 4096, 64)为例,torch NPU原生实现耗时46.6ms,融合算子5.8ms,融合算子+内置Mask耗时3.3ms。
原本4 x (b, n, s, d) + 2 x (b, n, s, s)的显存降低到了4 x (b, n, s, d),节省97%的显存(4.125G -> 0.125G)。
4.Jagged Tensor:拒绝无效计算
4.1.Padding的浪费
由于一个batch内数据长短参差不齐,若统一padding到最大序列长度:
- 产生大量无效运算:padding的token全是0,算也是白算。
- 产生大量无效搬运:搬更是白搬。
- 显存浪费:
(batch, heads, max_seq, dim)中相当一部分是无效数据。
4.2.优雅的变长序列
原本的QKV表示为(b, n, max_s, d),在s轴padding,那么只需要把(b, s)轴给压缩合并到一起,并记录每一段s的有效长度,构成新的数据(total, n, d),其中 t o t a l = ∑ i b s i total=\sum_i^b s_i total=∑ibsi。这样用values + offsets的表示我们称之为jagged tensor。
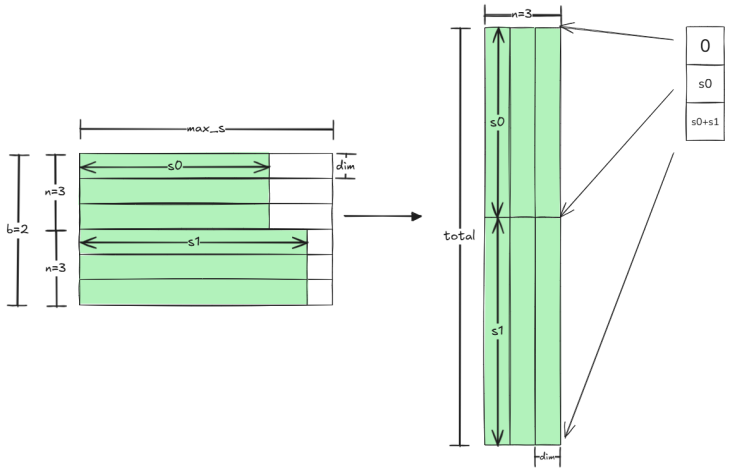
算子中使用jagged tensor作为入参:
- 显存节省: m a x S × b a t c h s i z e → ∑ S i max_S \times batchsize \rightarrow \sum S_i maxS×batchsize→∑Si
- 计算节省:不算padding的0
- 节省搬运:不搬运无效数据
- 访存优化:连续的有效数据,cache命中率更高
5.三级流水:榨干NPU算力
5.1.流水掩盖的基本原理
简单来说,流水掩盖就是让各计算单元始终有活干。好比等烧水时把碗洗了;模型在计算的时候把下一组数据预加载进HBM等等。
GPU基于SIMT架构实现并行,每个元素运算处理均为独立进行。矩阵乘法可以通过多流并发、线程调度来实现矩阵运算与element-wise计算的并行。但所有计算都在相同的计算核心上执行,可能存在瓶颈。
然而,昇腾NPU的 AIC(AI Core)与 AIV(AI Vector)是分离式架构,是硬件级并行。说人话就是:Cube核和Vector核天生就可以并行执行!
5.2.HSTU的三级流水
整个运算流程包含三个计算部分:QK Matmul -> Vector -> SV Matmul。看似必须串行,实则可以通过调度实现并行。
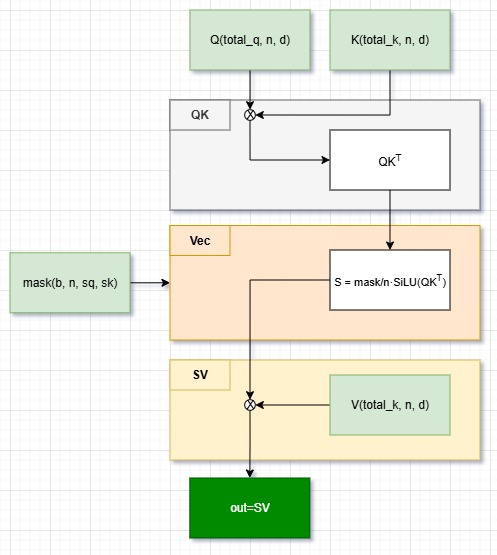
三级流水同样包含三个计算部分,区别在于每个迭代中计算QK Matmul部分、上一个循环中的Vector部分、上上个循环中的SV Matmul部分。
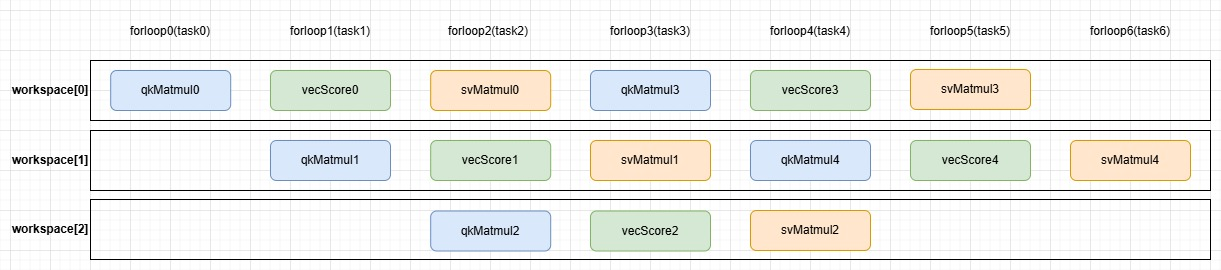
一次完整的QK Matmul -> Vector -> SV Matmul计算被拆分到3步循环中执行,这样就可以保证npu上cube、vector算力的充分利用。
采用三级流水,而非二、四级流水,主要考虑NPU cube:vector = 1:2的数值关系。且大量数据验证该流水设计能让各部分有效流转、避免等待,最大限度发挥NPU矩阵运算能力。此方案一出,耗时直接降到2.35ms,性能再次提升40%。
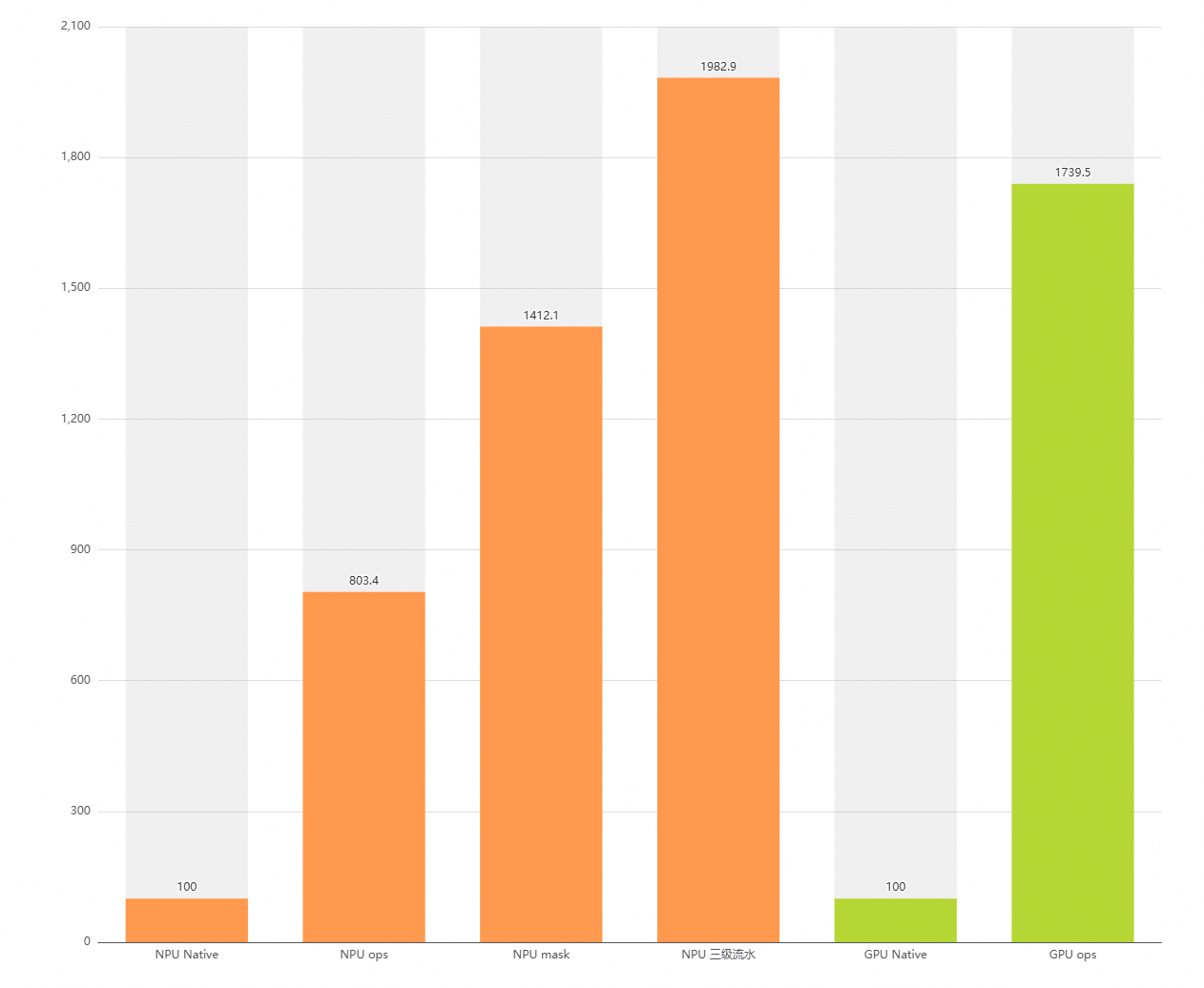
最后以NPU、GPU原生实现耗时为基准(100),取其倒数得处理能力,对比各优化的相对提升如图所示。搞定收工~
6.性能体验
- 步骤1:克隆代码仓库
git clone https://gitcode.com/Ascend/RecSDK.git
cd RecSDK
export PROJECT_DIR=$(pwd)
- 步骤2:编译安装算子
cd $PROJECT_DIR/cust_op/ascendc_op/ai_core_op/hstu_dense_forward/v220
bash run.sh
- 步骤3:编译适配层
cd $PROJECT_DIR/cust_op/framework/torch_plugin/torch_library/common
bash build_ops.sh
- 步骤4:运行测试用例
cd $PROJECT_DIR/cust_op/test/hstu_dense/torch/
pytest test_hstu_jagged_forward.py::TestHstuJaggedDemo::test_hstu_jagged_forward
更多实现细节可在代码仓库内自行探索~
repo: https://gitcode.com/Ascend/RecSDK
7.参考资料
- Ascend. 2025. RecSDK. GitCode. https://gitcode.com/Ascend/RecSDK
- Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (arxiv.org) (https://arxiv.org/pdf/2402.17152)
- 昇腾CANN, 2026. 昇腾社区. https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850/opdevg/Ascendcopdevg/atlas_ascendc_10_0049.html
- JacoCheung. 2025. recsys-examples. GitHub. https://github.com/NVIDIA/recsys-examples/blob/main/corelib/hstu/README.md

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)