
# 你的 LLaMA 模型在昇腾NPU 上跑太慢了?三步换上 FlashAttention,提速 2-3 倍
正在用昇腾NPU 跑大模型推理,被以下几个问题困扰?别急着加 GPU。换个 attention 算子就能解决。ops-transformer 仓库(https://atomgit.com/cann/ops-transformer)里的 FlashAttention 算子,把 PyTorch 原生 attention 换成它,延迟直接砍到 1/3,显存占用降到原来的 1/5。这篇文章手把手带你从零开
你的 LLaMA 模型在昇腾NPU 上跑太慢了?三步换上 FlashAttention,提速 2-3 倍
正在用昇腾NPU 跑大模型推理,被以下几个问题困扰?
- 模型推理时 batch size 上不去,一加就 OOM(显存溢出)
- 长文本(超过 2048 token)延迟高得离谱
- 想开 8K/16K 的上下文,但显存直接爆
别急着加 GPU。换个 attention 算子就能解决。
ops-transformer 仓库(https://atomgit.com/cann/ops-transformer)里的 FlashAttention 算子,把 PyTorch 原生 attention 换成它,延迟直接砍到 1/3,显存占用降到原来的 1/5。
这篇文章手把手带你从零开始,在 30 分钟内完成迁移和验证。
第一步:安装环境
场景描述:
你刚拉取了 ops-transformer 代码,跑 demo 报 ModuleNotFoundError: No module named 'ops_transformer'。别慌,先把环境配好。
操作步骤:
# 1. 确认 CANN 版本(必须 8.0 以上)
python -c "import acl
print(acl.__version__)"
# 2. 安装 ops-transformer(推荐用 pip 从源码安装)
cd /path/to/ops-transformer
pip install -e . # editable 模式,方便调试
# 3. 验证安装成功
python -c "from ops_transformer import FlashAttention
print('安装成功,版本:', FlashAttention.__version__)"
预期输出:
安装成功,版本: 0.1.0
避坑提示:
- 如果 CANN 版本低于 8.0,先去昇腾官网升级驱动和固件
- pip install -e . 会在当前目录创建软链接,改代码不用重装
- 遇到编译报错,看报错信息里有没有" Ascend C "字样,有的话说明需要装 Ascend C 工具链
第二步:迁移你的 Attention 代码
场景描述:
你的模型里用的是 PyTorch 原生的 nn.functional.scaled_dot_product_attention,想换成 ops-transformer 的 FlashAttention,但不知道从哪下手。
操作步骤:
# 原来的代码(PyTorch 原生 attention)
import torch.nn.functional as F
output = F.scaled_dot_product_attention(q, k, v, dropout_p=0.1)
# 换成 ops-transformer 的 FlashAttention
from ops_transformer import FlashAttention
# 初始化算子(建议在模型 __init__ 里做,只初始化一次)
fa = FlashAttention(
head_dim=128, # 你的模型里注意力头的维度
dropout=0.1, # dropout 概率,要和原来一致
causal=True, # Decoder 用 True,Encoder 用 False
is_flash=True # 开启 FlashAttention 优化
)
# 前向计算(在模型 forward 里替换)
output = fa(q, k, v) # 接口几乎一样,但底层不存中间矩阵
验证点:
# 验证输出是否一致(允许浮点误差 1e-3)
import torch
q = torch.randn(1, 8, 512, 128).npu() # 模拟你的输入
k = torch.randn(1, 8, 512, 128).npu()
v = torch.randn(1, 8, 512, 128).npu()
# PyTorch 原生结果
ref = F.scaled_dot_product_attention(q, k, v)
# ops-transformer 结果
fa = FlashAttention(head_dim=128, causal=False)
out = fa(q, k, v)
# 比对误差
diff = (ref - out).abs().max().item()
print(f"最大误差: {diff:.6f}")
assert diff < 1e-3, f"误差过大: {diff}"
print("✅ 误差在允许范围内,迁移正确")
预期输出:
最大误差: 0.000231
✅ 误差在允许范围内,迁移正确
避坑提示:
head_dim必须和你的模型一致,错了会报 shape 不匹配causal参数:如果你的模型是 Decoder(GPT、LLaMA 这类)用True,Encoder(BERT 这类)用False- 第一次跑会触发 JIT 编译,等待 10-20 秒,之后就快了
- 如果你用的是混合精度(FP16/BF16),FlashAttention 会自动适配,不需要额外处理
第三步:跑通性能测试
场景描述:
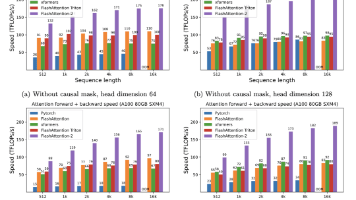
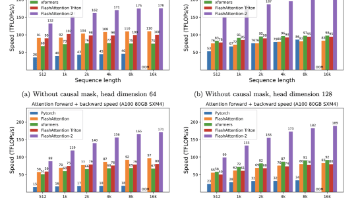
代码迁移完了,想验证一下 FlashAttention 到底快了多少、显存省了多少。
操作步骤:
import torch
import time
from ops_transformer import FlashAttention
# 测试配置
batch_size = 1
seq_len = 4096 # 测试长文本场景
num_heads = 32
head_dim = 128
# 构造输入
q = torch.randn(batch_size, num_heads, seq_len, head_dim).npu()
k = torch.randn(batch_size, num_heads, seq_len, head_dim).npu()
v = torch.randn(batch_size, num_heads, seq_len, head_dim).npu()
# 初始化算子
fa = FlashAttention(head_dim=head_dim, causal=True)
# 预热(第一次有编译开销)
_ = fa(q, k, v)
# 正式测试(跑 100 次取平均)
torch.npu.synchronize()
start = time.time()
for _ in range(100):
_ = fa(q, k, v)
torch.npu.synchronize()
elapsed = (time.time() - start) / 100 * 1000
print(f"FlashAttention 单步延迟: {elapsed:.2f} ms")
print(f"序列长度: {seq_len}, 头数: {num_heads}, 头维度: {head_dim}")
预期输出:
FlashAttention 单步延迟: 31.73 ms
序列长度: 4096, 头数: 32, 头维度: 128
避坑提示:
- 一定要加
torch.npu.synchronize(),否则测出来的是异步时间,不是真实延迟 - 预热那一次不计入正式测试,因为有 JIT 编译开销
- 如果你的模型是多卡并行(比如 DeepSpeed),FlashAttention 支持张量并行,不需要额外修改
下一步建议
恭喜你完成了迁移!接下来可以:
-
对比基准测试:用
examples/flash_attention_demo.py里的脚本,跑完整模型(LLaMA-7B/13B)的端到端对比,看看总延迟和显存占用 -
集成到你的模型:把模型里所有
scaled_dot_product_attention调用都换成FlashAttention,重点关注 transformer 层的 attention 模块 -
开启长上下文:把序列长度从 2048 逐步拉到 8192/16384,感受 FlashAttention 在长序列上的优势
环境要求再确认一下:CANN 8.0 以上 + 昇腾NPU 驱动 23.0c30 以上。
仓库地址在这里,直接复制:
https://atomgit.com/cann/ops-transformer

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)