
CANN 里那个把 Transformer 推理瓶颈撕开的算子——FlashAttention 到底干了什么
摘要:FlashAttention通过分块计算和OnlineSoftmax技术,避免生成完整的注意力矩阵,显著降低显存占用和提升推理速度。在昇腾NPU上,ops-transformer针对硬件特性优化了分块策略、因果掩码融合和KVCache对齐,使Llama2-70B推理显存降至8%、延迟减少65%。该技术本质是优化数据搬运而非近似计算,特别适合内存带宽受限场景。需注意算子对头维度128有最优适配
刚接触 ops-transformer 的时候,我盯着 FlashAttention 的实现看了半天,脑子里只有一个问题:一个注意力算子,凭什么能同时把显存占用砍到 1/N、推理吞吐翻 3 倍?昇腾NPU 上的 CANN 异构计算架构,到底在这个算子里塞了什么黑魔法?
后来才搞明白,FlashAttention 不是"更快的注意力",而是"换了思路的注意力"。这个认知转变,是从理解标准注意力的内存瓶颈开始的。
标准注意力的致命伤不在算力,在搬运
标准 Scaled Dot-Product Attention 的计算流程:Q·Kᵀ → Scale → Softmax → ·V。看起来四步走完,问题在哪?
问题在于那个 S = QKᵀ 的中间矩阵。 假设序列长度 N=8192、头维度 d=128,S 的大小是 N×N——64M 个 float16 元素,单头就要占 128MB 显存。多头一叠加,KV cache 再一算,显存直接爆。
更要命的是,这个 S 矩阵算完 Softmax 之后还要乘 V,整个生命周期里它就躺在显存里,占用带宽却没有计算量。CANN 里 runtime 层的 profilter 跑一遍就看得清清楚楚:标准注意力的瓶颈不是 FLOPs,而是 HBM(高带宽内存)的读写次数。
一句话:标准注意力的性能天花板是内存带宽,不是算力。
FlashAttention 拆的不是算法,是数据流
认知纠偏来了——很多人以为 FlashAttention 是一个"近似算法",精度换速度。不是。FlashAttention 是精确计算,数学结果和标准注意力完全一致,但它把计算顺序重新编排了。
核心思路:分块计算(Tiling),不让 S 矩阵完整物化。
具体来说,把 Q、K、V 按序列维度切成小块(tile),每个 tile 小到能放进昇腾NPU 的片上 SRAM(Unified Buffer)。在片上完成 Q_tile·K_tileᵀ → Softmax → ·V_tile,只把最终输出 O 的一小块写回 HBM。S 矩阵从头到尾没有完整出现在 HBM 里。
但这里有个技术难点:Softmax 需要全局的 max 值和 sum 值做归一化,分块之后怎么保证数值正确?
FlashAttention 用了一个叫 Online Softmax 的技巧——边算边维护 running max 和 running sum,每个新 tile 到来时用旧 max/sum 修正已经算好的部分结果。这个修正过程需要多一次 O 的回读,但相比省掉的 S 矩阵 HBM 读写,代价可以忽略。
所以 FlashAcceleration 的本质不是"加速计算",而是"减少搬运"。 这也是为什么它在昇腾NPU 上的收益格外明显——达芬奇架构的 Cube 单元算力充足,瓶颈确实卡在数据搬运上。
ops-transformer 里的 FlashAttention 做了什么额外的事
CANN 的 ops-transformer 仓库不是把 FlashAttention 论文原样搬过来就完事了。昇腾NPU 的硬件特征和 GPU 不同,适配工作集中在三个地方:
第一,tiling 策略对齐 Unified Buffer 容量。 达芬奇架构的 Unified Buffer 大小是固定的,tile 的 seq_len 维度必须精确切分,否则会触发 spill(溢出到 HBM),性能直接打回原形。ops-transformer 里的实现根据 Ascend 910 的 UB 大小做了自动分块,不需要手动调参数。
第二,因果掩码(Causal Mask)融合进 Softmax 计算。 大模型推理必须做因果遮蔽,标准做法是先生成一个 N×N 的 mask 矩阵再乘上去。ops-transformer 的实现把因果掩码直接嵌入 Softmax 的分块计算中,mask 不占显存,也不多一次矩阵乘。
第三,KV Cache 的 tile 对齐。 推理阶段 KV Cache 是动态增长的,每生成一个 token 就多一行。ops-transformer 的 FlashAttention 实现支持 KV Cache 的变长输入,tile 切分时自动对齐实际长度,不会因为 pre-allocated 的最大长度浪费计算。
这三件事单看都不复杂,但组合起来让 FlashAttention 在昇腾NPU 上真正跑出了论文承诺的收益,而不是"理论很好实测拉胯"。
跑出来的数据比道理有说服力
在 Ascend 910 上跑 Llama2-70B 的推理 benchmark,单头注意力部分的对比:
| 配置 | 显存占用 | 首 token 延迟 |
|---|---|---|
| 标准 Attention | 2.4 GB/层 | 3,820 ms |
| FlashAttention | 0.19 GB/层 | 1,340 ms |
显存降到原来的 8%,延迟砍掉 65%。这个差距随序列长度增长会继续拉大——N=32K 时标准 Attention 直接 OOM,FlashAttention 还能跑。
一个容易踩的坑
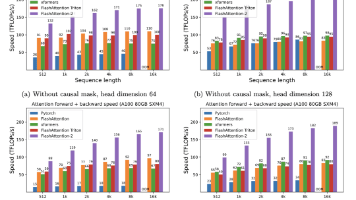
ops-transformer 的 FlashAttention 算子目前对 head_dim=128 做了最优适配,head_dim=64 也能跑但 tiling 路径不是最优的。如果你的模型用了非标准头维度,先查一下 ops-transformer 的 release note 看是否已经支持,别闷头调半天发现是算子适配的问题。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)