
MindCluster集群调度实践-通用超节点调度算法
作者:昇腾实战派
一、超节点的重要性
随着模型参数量的上升,训练任务运行所需的芯片数量也达到了万卡、十万卡级别。如何将如此庞大的芯片链接起来,并且做到通信带宽和成本的平衡,成为硬件层面的一大难题。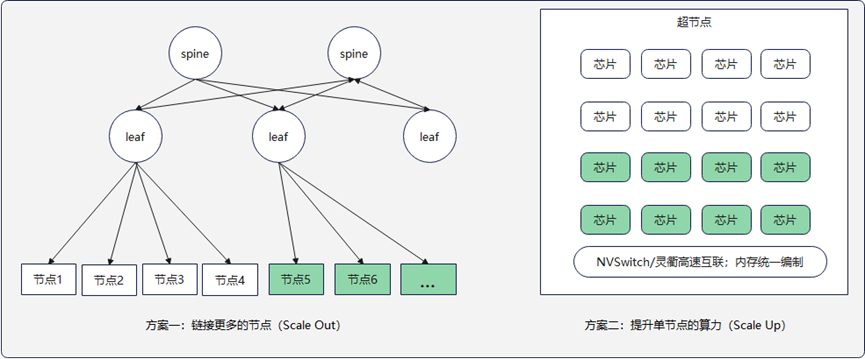
图1.资源扩展方式示意图
超节点(方案二)有以下几点优势:
必要性:Leaf交换机需要与所有的Spine交换机互联,才能组成扁平的Spine-Leaf网络。因此Spine-Leaf网络的横向扩展并不是无止境的,它受限于交换机的接口数量。
成本:Spine-Leaf网络的带宽提升,需要整个网络一起提升,成本巨大。而训练场景其实只是局部TP、EP、SP对网络要求高,局部带宽升级性价比更高。
性能:超节点可以实现超低时延,超大带宽,统一内存编址,极大提升训练推理性能。
二、亲和性调度的必要性
通过超节点优化局部网络,可以在成本和性能之间找到一个平衡点。而面对一个不对等的网络,任务如何部署就显得尤为重要。一个错误的部署,可能导致网络带宽降级,集合通信建链失败,网络资源更优但是网络性能下降等问题
网络带宽降级原因:HCCL集合通信在跨超通信时,会进行自适应的算法选择,当任务在各超节点中的服务器数量不一致时,会默认启用最大公约数算法(NHR Highest Common Factor),该算法通过计算超节点间服务器数的最大公约数,将通信域切分为多个对称分布的逻辑超节点,依次保证网络的对称性。逻辑超节点间只能走Spine-Leaf网络,因此可能出现图2的情况,节点1和节点4虽然在同一个超节点网络中,但是只能走Spine-Leaf网络:
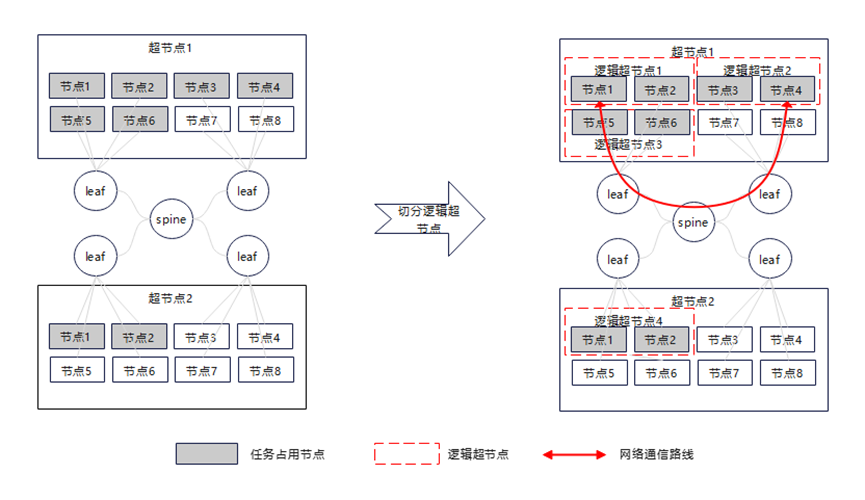
图2.网络通信方式示意图
集合通信建链失败原因:在昇腾社区的通信域管理文档中,明确要求了同一个超节点内的服务器信息需要配置在一起,也就是同一超节点内的rankId是连续的,不支持两个超节点下的服务器的rankId交叉配置。
网络资源更优但是网络性能下降的原因:训练任务通过各种并行策略,将任务分解到了多张芯片上,一般来说,TP、EP、SP的流量是TB级别,而DP、PP流量是GB级别。假设任务的TP是8,EP是2,DP是5。一台服务器的芯片数量是8,则该任务一共需要10台服务器。如图3所示:
场景一的调度方案,虽然将任务平均的调度到了两个超节点中,但是有一部分EP流程跑在了Spine-Leaf网络上。
场景二的调度方法,虽然将任务不平均的调度到了三个超节点,但是所有的TP\EP流量都跑在了灵衢网络上。场景二网络性能更优。
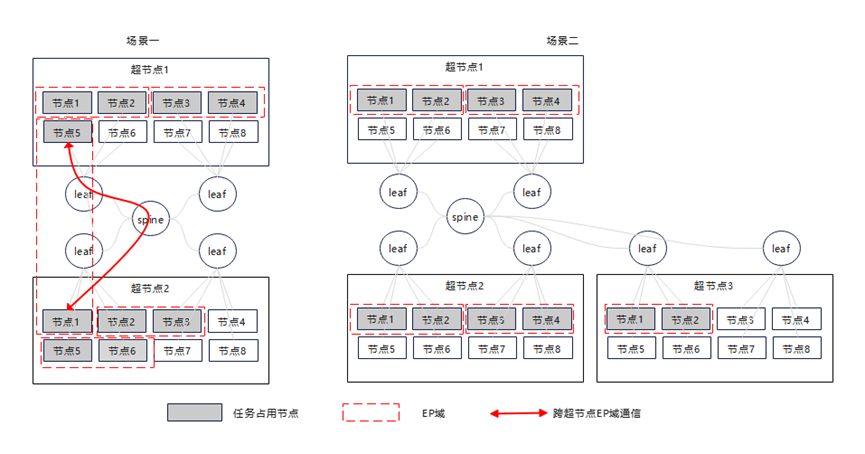
图3.网络通信方式示意图
三、通用亲和性调度的必要性及MindCluster内部实现逻辑
在第二章节中,我们已经了解了超节点网络中,必须要配合亲和性调度算法,才能最大化的释放超节点算力。而超节点的形态随着客户的需求、产品的迭代在不断的变化,定制化开发会浪费大量人力。因此需要一个通用的亲和性算法,可以在多种超节点网络拓扑下保证网络的亲和性,并且做到资源碎片的最小化。
(1) 确定数据结构
要想实现通用的亲和性算法,首先要将超节点网络拓扑、任务网络诉求抽象成通用的数据结构。如图4所示:
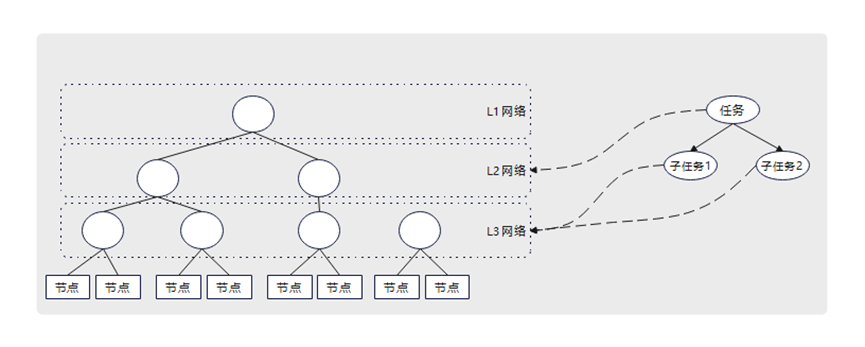
图4.节点树与任务树匹配方式示意图
超节点网络拓扑:超节点的网络,都是一个多层结构,层级越低,节点数量越少,网络越优,因此可以使用一个多层的树来表示。叶子节点就是AI服务器,节点的层级代表网络的层级,两个叶子节点之间的最短连线,就是这两台服务器间通信的最优网络路线。
l 一个集群中可能有多棵树。造成多棵树的原因可能是有多种不同的超节点,也有可能原本是一棵树,因为网络故障导致服务器被孤立成了一颗新的树。
l 树的层级和超节点网络的层级有关,但是会基于算法复杂度设置上限。
任务网络诉求:一个训练任务,因为不同并行策略对网络的诉求不一样,因此可以基于并行策略将任务看成多层的子任务。每一层子任务可以配置自己所需的网络层级。一个推理任务,也会因为PD分离,被看成多个子任务,每个子任务可以配置自己所需的网络层级。
l 子任务实际部署的层级可能比配置的网络层级更低(实际网络比配置网络优),但是不能更高(实际网络比配置网络差)。
l 任务的层级和任务的切分策略和网络诉求有关,但是会基于算法复杂度设置上限。
(2) 如何生成数据结构
通过第(1)步,我们已经确定了数据结构,MindCluster会通过自有的Ascend Device Plugin、Volcano、Ascend Operator实现数据结构的自动生成。
Ascend Device Plugin组件上报了节点的所属超节点ID、所属框ID等节点基础信息,Volcano组件通过监听ConfigMap,感知到了网络拓扑配置。通过这两个信息,就能在Volcano的内存中维护出多棵硬件的拓扑树。
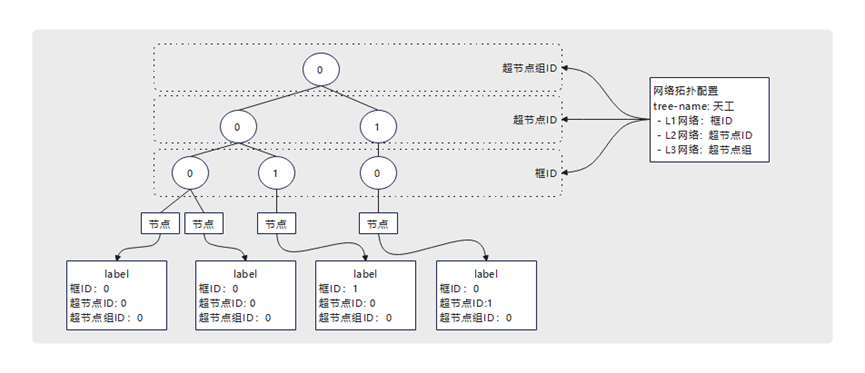
图5.节点树生成方式示意图
Ascend Operator定义了标准的任务创建接口,通过接口字段校验,要求任务新增超节点网络亲和配置。如图6所示,该配置表示任务一共使用8个节点,第一层子任务大小为8,个数为1,该子任务必须部署到一个超节点中,第二层子任务大小为2,个数为4,每一个子任务必须部署到一个框中,且这些框同属一个超节点。
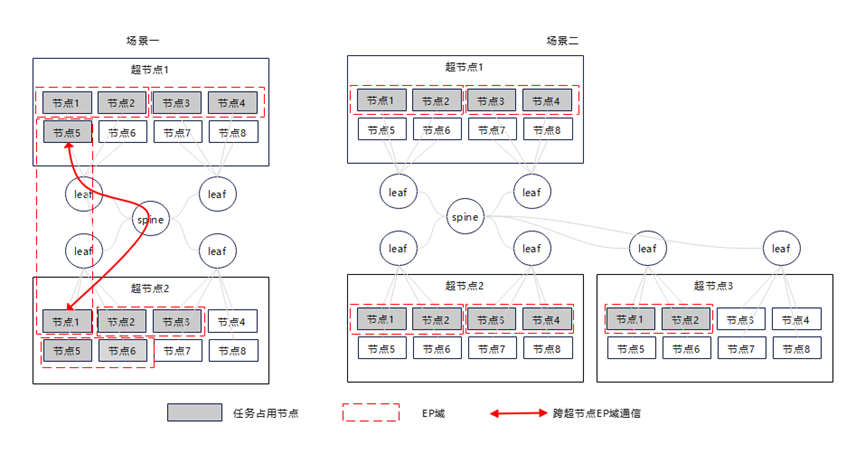
图6.任务树生成及绑定关系示意图
(3) 如何基于数据结构实现算法
当复杂的网络问题被抽象成了两个基本的数据结构,Volcano就可以通过算法实现通用的亲和性调度,算法逻辑如图7所示:

图7.超节点通用亲和性调度算法示意图
关键步骤解释如下:
调度函数:从根节点递归遍历服务器资源,经服务器过滤、服务器排序,构建出任务树。构建遵循五大原则:
- 深度优先构建任务树,首先保障资源分配满足任务网络诉求。
- 资源利用率最优,以碎片分数为首要排序键。
- 网络带宽最优,碎片分数相同时按照网络带宽优劣排序。
- 支持优先网络带宽最优,其次资源利用率最优,覆盖不同调度场景。
- 资源不足时允许使用预留服务器,兼顾资源利用率与关键作业的故障恢复效率。
计算碎片得分规则:该规则用于评估同一颗树内节点选择的优先级,也用于多棵树选择的优先级。碎片分数的计算是一个递归的过程,从叶子节点开始向上聚合:
- 叶子节点的碎片得分 = (该节点的父节点下的所有叶子节点 / 该节点的父节点下的被使用叶子节点)
- 非叶子节点的碎片得分 = 下一层的子节点的碎片得分 * 10 + (该节点的父节点下的所有叶子节点 / 该节点的父节点下的被使用叶子节点)
四、MindCluster超节点亲和性调度算法效果
- 保证了任务的超节点网络最优。
- 减少了资源碎片,提升资源利用率。
- 使用一套MindCluster服务,零代码适配后续的超节点形态。
- 调度问题变成了单纯的算法问题,可以快速演进至DRL等全局调度算法。

作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)