
一天一个昇腾Agent-Skills小技巧:MindSpeed适配Mamba3模型,解锁SSM模型新潜能
作为基于昇腾生态的专业大模型训练框架,MindSpeed LLM已内置支持百余个业界常用稠密、MOE及SSM类模型,具备分布式预训练、微调、推理等全流程能力。此次Mamba3适配的完成,将进一步丰富框架的模型生态,为开发者提供更高效、更灵活的技术工具,助力SSM类模型在更多行业场景中快速落地,推动大模型技术从实验室走向实际应用,解锁更多技术创新与业务价值。社区共建:欢迎开发者贡献新模型支持与优化建
前沿速递:Mamba3重磅更新
近日,SSM(状态空间模型)开源仓库 state-spaces/mamba 更新迭代,新增 mamba3 block 核心结构,为Mamba系列模型架构升级奠定基础。
相较于传统Transformer架构,SSM通过"内部状态"压缩历史信息,实现线性计算与固定内存占用,在长序列处理场景中优势突出;而Mamba3秉持"推理优先"核心理念,进一步释放了SSM的技术潜力,推动SSM领域技术再升级。
适配攻坚!一周实现双维度突破
作为聚焦昇腾生态的端到端大语言模型训练框架,MindSpeed LLM 始终以高效适配、性能优化为核心目标,持续跟进前沿模型架构演进。依托FSDP2分布式训练框架,MindSpeed LLM快速完成Mamba3模块的全流程适配及核心能力升级,仅用一周便实现结构迭代与创新模块突破,为SSM类模型的训练与部署注入全新动力。
架构适配,Mamba2→Mamba3结构跨越式升级
相较于Mamba2-block,Mamba3-block基于状态空间模型(SSM)进行了架构层面的革新,引入更具表达力的递归机制与复杂状态更新规则,且内置了Triton算子,在结构设计上展现出独特的技术特性。MindSpeed LLM通过拆解这些核心升级点,逐一完成适配与优化,同时针对Mamba3内置的Triton算子,完成算子迁移及生态兼容性适配,实现其在昇腾硬件平台的高效运行。
此外,突破mamba3-block的单一应用局限,实现跨模型兼容适配,支持其他各类主流模型灵活接入mamba3-block能力,覆盖稠密、MOE等多类模型场景,大幅提升框架复用性与工程实用价值。
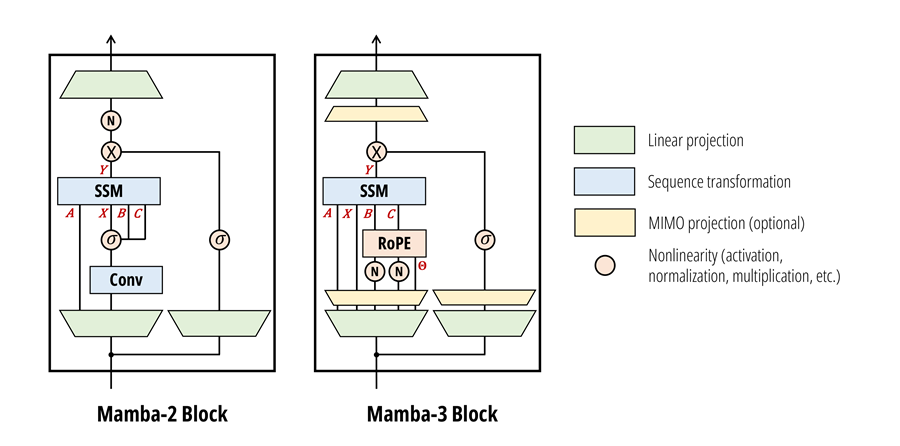
创新模块突破,完成SISO→MIMO高效落地
MindSpeed LLM同步跟进Mamba3核心创新,针对性推进SISO(单输入单输出)到MIMO(多输入多输出)的机制适配:
MIMO作为Mamba3模型的核心创新点之一,其核心价值在于打破传统SISO(单输入单输出)的序列动态限制,通过矩阵乘法替代外积进行状态更新,提升解码过程中的算力效率,更好地发挥硬件并行性能。
MindSpeed框架现已支持MIMO(多输入多输出)实现,进一步丰富了框架的功能维度,提升模型推理效率与硬件并行利用率。小算子版本的MIMO适配兼顾轻量化与高效性,无需引入外部算子库,可无缝适配昇腾生态,轻松提升模型并行输出能力。
SKILL赋能,实现Triton算子快速适配
除了Mamba3-block适配与MIMO创新突破,我们依托Agent-Skills的高效适配能力,实现了Triton算子的快速适配,进一步完善框架的算子生态,提升模型运行的兼容性与高效性。Agent-Skills凭借其灵活的算子封装与快速集成特性,无需复杂的手动开发与调试,即可快速完成Triton算子与MindSpeed-LLM框架的无缝对接,有效降低算子适配门槛,缩短适配周期,为框架的功能拓展与性能优化提供了有力支撑。
当前我们已提供相关迁移 Skill:https://gitcode.com/Ascend/agent-skills/tree/master/skills/simple-vector-triton-gpu-to-npu,该 Skill 可自动识别 GPU 配置并批量替换为 NPU 适配配置。通过使用Skill实现解决了Triton算子从 GPU 到 NPU 迁移门槛高、操作复杂、需要专业技能的痛点,具体体现在以下维度:
- 无需人工手写适配代码,零手动修改成本:技能已封装所有GPU到NPU的迁移核心逻辑,从接口替换、网格配置优化到算子硬件映射,全程无需开发者手动逐行修改代码、编写适配脚本。无论是设备接口的替换(如 torch.cuda 转 torch.npu)、网格配置的调整,还是向量算子的硬件适配,均由技能内置操作文档(architecture.md、examples.md 等)自动完成,避免人工操作带来的遗漏、错误,大幅节省迁移时间。
- 迁移门槛极低,无需具备相关迁移技能和经验:开发者无需深入了解昇腾NPU底层架构、无需掌握GPU与NPU的迁移技术、无需熟悉Triton底层适配原理,即便没有任何GPU到NPU的迁移经验,也能快速上手使用。技能已将复杂的迁移逻辑、硬件适配细节全部封装,开发者只需按照流程完成环境准备、工具调用等简单操作,即可完成迁移。
1、simple-vector-triton-gpu-to-npu采用模块化设计,将算子迁移流程分解为5个核心步骤

项目架构如下所示:
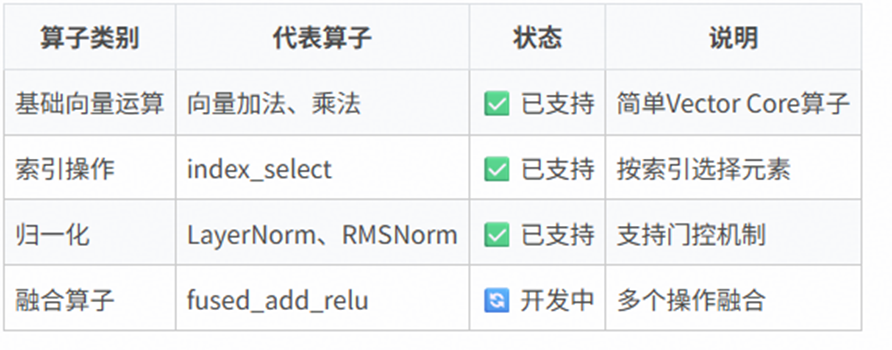
2、Skills支持范围
3、Skills在mamba3模型里算子实战表现
(1)根据Skills编排todo计划: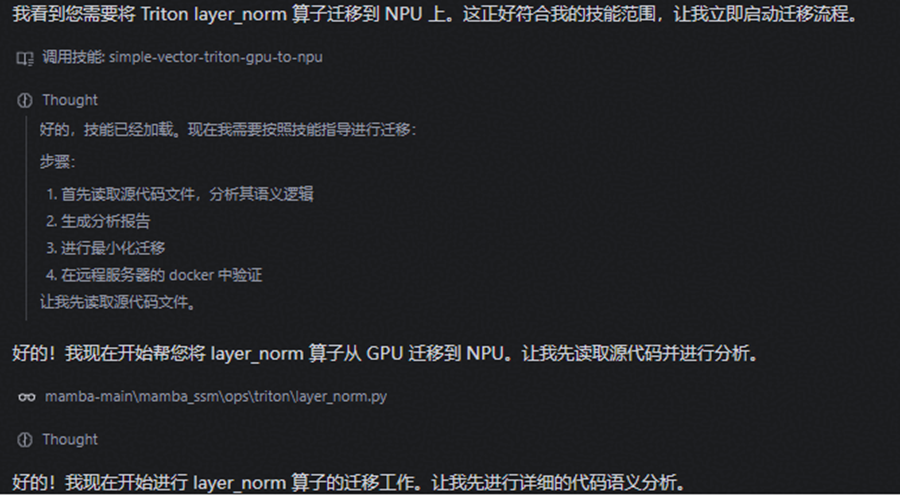
(2)输出语义分析报告
(3)迭代迁移:整体工作流为迁移→测试→定位→修改→验证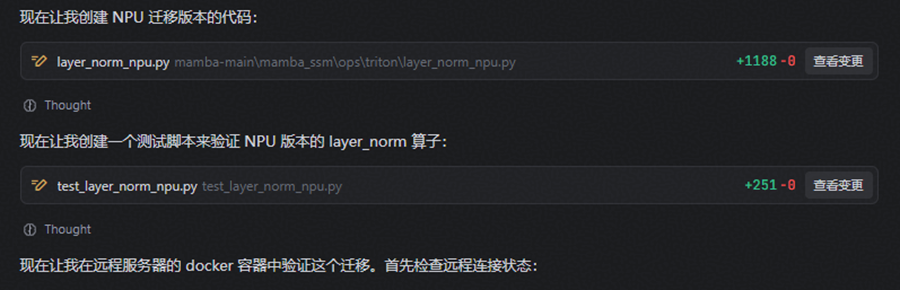
(4)测试用例无法通过,自动定位问题并修复,再重新测试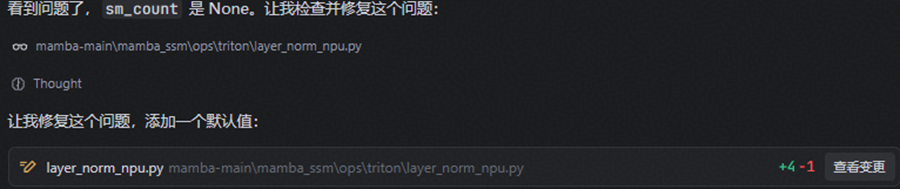
(5)任务完成,梳理任务流程
4、Skills的效率提升优势
(1)相比传统迁移方式
(2)核心价值
- 效率提升:将算子迁移时间从数天缩短至30分钟
- 降低门槛:无需深入了解NPU实现细节
- 质量保证:标准化的分析模板和验证流程确保正确性
- 可复现性:完整的工作流文档,便于团队协作
模型demo运行指导
为助力开发者快速上手、高效验证mamba3-block相关能力,我们同步配套完善的模型demo运行指导,简化全流程部署与验证操作,步骤清晰易懂、无需复杂配置,具体如下:
1、环境搭建
请参考MindSpeed LLM安装指导文档:https://gitcode.com/Ascend/MindSpeed-LLM/blob/master/docs/pytorch/install_guide.md
# 安装MindSpeed加速库
git clone https://gitcode.com/ascend/MindSpeed.git
cd MindSpeed
git checkout master
pip3 install -r requirements.txt
pip3 install -e .
cd ..
# 准备MindSpeed-LLM
git clone https://gitcode.com/ascend/MindSpeed-LLM.git
cd MindSpeed-LLM
git checkout master
pip3 install -r requirements.txt # 安装其余依赖库
2、权重与配置文件准备
Mamba3 模型目前暂未开源,仓库仅提供可运行 Demo 示例。如需运行该 Demo,请按以下方式修改模型配置文件:
-
配置文件:复用 mamba2-2.7b 的 config.json,可从HuggingFace(https://huggingface.co/state-spaces/mamba2-2.7b)下载,并做修改如下:
下载 config.json 后,将模型层数调整为1层,并新增以下配置项:
"model_type": "mamba2", "is_mimo": false其中 is_mimo 可根据实际设置为 false 或 true。
-
词表:由于mamba3暂未开源tokenizer,建议用户自行构建,也可临时选用其他模型(如qwen3-next)的tokenizer进行验证,训练效果不做保证;
-
特别说明:无需额外下载完整模型权重,因state-spaces/mamba开源仓库仅开源mamba3-block结构,未提供模型权重;
-
补充说明:上述所有涉及的模型配置文件需放置在同一文件夹下,确保框架正常调用。
3、运行demo脚本
完成环境与配置准备后,可直接通过框架内置demo脚本,一键启动mamba3 demo验证,具体命令如下:
cd MindSpeed-LLM
bash examples/fsdp2/mamba3/pretrain_mamba3_demo_1b_2K_fsdp2_A2.sh
运行脚本后,框架将自动完成mamba3-block初始化,可直观验证mamba3-block的运行效果,无需手动配置额外参数,快速开启mamba3-block相关开发与测试工作。
结语
作为基于昇腾生态的专业大模型训练框架,MindSpeed LLM已内置支持百余个业界常用稠密、MOE及SSM类模型,具备分布式预训练、微调、推理等全流程能力。此次Mamba3适配的完成,将进一步丰富框架的模型生态,为开发者提供更高效、更灵活的技术工具,助力SSM类模型在更多行业场景中快速落地,推动大模型技术从实验室走向实际应用,解锁更多技术创新与业务价值。
社区共建:欢迎开发者贡献新模型支持与优化建议,共同完善昇腾生态。
开源地址:https://gitcode.com/Ascend/agent-skills


作为“人工智能6S店”的官方数字引擎,为AI开发者与企业提供一个覆盖软硬件全栈、一站式门户。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)